
- 1Jenkins自动化搭建记录
- 2深度研究报告|城市级智能网联示范区建设内容、建设路径、最新趋势及挑战
- 3ABAP subroutine 的定义和使用_abap subroutine 找不到
- 4StopWatch 类 -- 以良好的格式打印程序运行时间_stopwatch watch = new stopwatch(); watch.start();
- 5[ROS学习] 利用message_filter进行多传感器时间同步_message_filters::synchronizer
- 6@Prometheus监控数据库(MySQL)_mysql expoert 普米修斯
- 7LeetCode刷题顺序(新手入门)_leecode刷题
- 8新手如何玩转内网穿透?(非常详细)零基础入门到精通,收藏这一篇就够了
- 9uniapp自定义导航栏 获取高度的方法_uniapp 微信修改tabbar高度
- 10Hbase核心内容总结_hbase核心功能
从零开始搭建一个高可用的 Flink Standalone 集群_生产环境一个flink集群可以不用hadoop嘛?
赞
踩
一、知识体系导航
你当前所在的位置:计算引擎 - Flink - 环境部署

二、Flink 这么牛逼 它到底能干嘛
本来打算在安装好的 Flink 集群上直接修改的,这样我增加个配置,这篇文章就完成了,考虑到大家可能对 Flink 不太了解,也不一定有兴趣从 0 开始装个 Linux 环境,所以我索性就从0开始配置一整套的环境。
然后简单的描述一下什么是 Flink,它能干嘛。
现在的互联网公司,数据呈指数级增长,大部分公司都会成立大数据部门,一开始会搭建一个离线的数据仓库,一般会使用 Hadoop + Hive + 调度工具 + Hue 构建一个离线数仓,为公司其他部门提供数据报表,数据决策。但有时候离线的数据往往满足不了实时性的要求,比如下面的需求:
- 小张,你看能不能做个监控大屏实时查看促销活动销售额(GMV)?
- 小李,搞促销活动的时候能不能实时统计下网站的 PV/UV 啊?
- 小孙,我们现在搞促销活动能不能实时统计销量 Top5 啊?
- 小王,我们 1 元秒杀促销活动中有件商品被某个用户薅了 100 件,怎么都没有风控啊?
我们归纳一下需求,大致就是下面的图

初看一下是不是挺难的?但我们把问题剖开,主要有下面三个小问题
(1)数据实时采集 - 数据从哪来
(2)数据实时计算
(3)数据实时下发 - 告警 或者 直接存储(消息队列、数据库、文件系统)

那么 Flink 就是一款实时计算引擎,它可以针对批数据和流数据来进行分布式计算,代码主要由 Java 实现,提供了 Scala、Python、Java 接口供调用。
对 Flink 而言,其主要的处理场景就是流式处理,批处理也是流处理的一个极限特例了,所以 Flink 也是一款真正意义上的流批统一的处理引擎。
三、基础环境准备
大家可以参考《Linux就该这么学》的那本书中,在Windows上安装Linux虚拟机,一定要按照步骤操作
再自己依次安装好基础环境、java 1.8 环境、zookeeper 环境
四、Flink 集群环境准备
(1)单机模式体验
https://flink.apache.org/downloads.html#apache-flink-191
下载完后,使用 xshell 工具把包上传到服务器 hadoop001 上

先 cd /usr/local
输入 put,然后选择刚下载的 flink 文件
解压缩 tar -zxvf flink-1.9.1-bin-scala_2.11.tgz
进入 flink 目录 cd /usr/local/flink-1.9.1
先体验一下 单机模式,什么都不用做
cd /usr/local/flink-1.9.1/bin
./start-cluster.sh
它会在本地启动 JobManager 和 TaskManager
然后在浏览器上访问:
http://192.168.193.128:8081/
可以看到它启动了一个 TaskManager ,一个 Task Slot

(2)集群模式体验
首先 kill 掉 hadoop001 的 进程

kill -9 4182
kill -9 4617
首先
进入到 hadoop001 机器
cd /usr/local/flink-1.9.1/conf
vi flink-conf.yaml
修改几个配置:
jobmanager.rpc.address: hadoop001
jobmanager.rpc.port: 6123
jobmanager.heap.size: 1024m
taskmanager.heap.size: 1024m
taskmanager.numberOfTaskSlots: 3
vi slaves
修改为:
hadoop001
hadoop002
hadoop003
vi masters
hadoop001:8081
然后把整个 flink 目录使用 scp 拷贝到其他机器上
scp -r flink-1.9.1 root@hadoop002:/usr/local/
scp -r flink-1.9.1 root@hadoop003:/usr/local/
启动集群,在hadoop001上
cd /usr/local/flink-1.9.1/bin
./start-cluster.sh
再次访问:
http://192.168.193.128:8081/

可以看到,现在启动了 3 个 TaskManager,9 个 Task Slots
已经是集群模式了
(3)高可用集群搭建
我们现在的集群就只有一个 JobManager,是单点的,高可用就是增加一个 JobManager 作为备用,当主 JobManager 宕机之后,备用 JobManager 顶上,等宕机的 JobManager 恢复之后,又变成备用


修改配置文件
vi /usr/local/flink-1.9.1/conf/flink-conf.yaml
high-availability: zookeeper
high-availability.zookeeper.quorum: 192.168.193.128:2181,192.168.193.129:2181,192.168.193.130:2181
high-availability.storageDir: file:///usr/local/flink-1.9.0/ha-dir
(注意,这里应该配置为 hdfs ,但我们没有装,所以暂时配置为本地,不然没法启动集群)
vi /usr/local/flink-1.9.1/conf/masters
hadoop001:8081
hadoop002:8081
修改好的配置发送到其他两台机器
scp flink-conf.yaml root@hadoop002:/usr/local/flink-1.9.1/conf/
scp flink-conf.yaml root@hadoop003:/usr/local/flink-1.9.1/conf/
scp masters root@hadoop002:/usr/local/flink-1.9.1/conf/
scp masters root@hadoop003:/usr/local/flink-1.9.1/conf/
启动集群
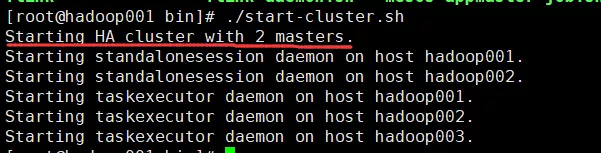
浏览器上打开:
http://192.168.193.128:8081/
发现 JobManager 在 hadoop001 上启动了
现在我们 kill 掉 hadoop001 上的 JobManager 进程
kill -9 15107
他应该会在 hadoop002 上把备用的 JobManager 变成 主 JobManager,我们再在浏览器上访问一下
hadoop001 上的 JobManager 已经无法访问了

hadoop002 上的 JobManager 可以访问到了

说明高可用已经ok了
到此为止,我们已经从零开始搭建了一个 Flink 高可用集群,后续案例都会提交到集群上演示,有兴趣的可以在自己电脑上安装一下,体验一下。
欢迎各位小伙伴来咨询,想要工程源码的加群:797853299

