- 1DH参数(Denavit-Hartenberg parameters)
- 2docker学习笔记7:centos docker安装mysql
- 3mysql设置主从数据库的同步_mysql 配置好主从同步后会先做全量同步嘛
- 4原生IP和住宅IP有什么区别?
- 5一、阿里外包面试题&解析_外派阿里面试题
- 61.43 财务测量指标——动态评价法(利息与折现)
- 7大脑与AI的认知差异:解码人类思维
- 8从git或者svn上下载下来的前端代码应该如何运行起来_svn拉下来的前端项目怎么运行
- 9python sklearn knn快速实现,保姆级教学_本关任务:学会如何使用sklearn构建knn模型。
- 10基于TensorRT的BERT实时自然语言理解(下)_bert 在python tensorrt 预测
使用 Scrapy 和 Selenium 爬取 Boss 直聘职位信息(可视化结果)_scrapy爬取boss
赞
踩
在本博客中,我们将介绍如何使用 Scrapy 和 Selenium 来爬取 Boss 直聘 网站上的职位信息。Boss 直聘是一个广受欢迎的招聘平台,提供了大量的职位信息,以及公司和 HR 的联系信息。通过本文的指南,你将学会如何创建一个爬虫来抓取特定城市的 Python 职位信息。
简介
在这个示例中,我们将创建一个 Scrapy 爬虫,使用 Selenium 来模拟浏览器操作,以抓取 Boss 直聘网站上特定城市的 Python 职位信息。我们将获取职位名称、工资、福利、地区、招聘类型、学历要求、关键词、详细要求、公司名称、是否上市、公司规模、所属行业、公司介绍、详细地址、HR 姓名和职位的信息。以下是实现这一目标的详细步骤。
步骤 1: 创建 Scrapy 项目
首先,确保你已经安装了 Scrapy 和 Selenium。然后,创建一个新的 Scrapy 项目:
scrapy startproject boss
- 1
步骤 2: 创建 Spider
在 Scrapy 项目中,你需要创建一个 Spider 来定义爬取网站的规则和行为。在项目目录下创建一个名为 boss_spider.py 的 Spider 文件,然后添加以下代码:
import time import scrapy from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from boss.items import BossItem class BsSpider(scrapy.Spider): name = "bs" start_urls = ["https://www.zhipin.com/web/geek/job?query=python&city=101110100"] def parse(self, response): # 创建 ChromeOptions 对象 chrome_options = Options() # 禁用图片加载 prefs = {"profile.managed_default_content_settings.images": 2} chrome_options.add_experimental_option("prefs", prefs) # 启动 Chrome 浏览器 driver = webdriver.Chrome(options=chrome_options) # 循环,可以设置连续爬取多个城市的职位信息 city_list = ['101110100'] for j in city_list: for p in range(1, 11): # 下一页 next_url = f'https://www.zhipin.com/web/geek/job?query=python&city={j}&page={p}' # 打开网页 driver.get(next_url) time.sleep(1) for i in range(1, 31): # 反爬 time.sleep(1) # 等待页面加载完成 try: wait = WebDriverWait(driver, 10) wait.until(EC.presence_of_element_located((By.XPATH, f'//ul/li[{i}]/div[1]/a'))) except: continue # 省略爬取数据的代码... # 创建一个BossItem对象并将数据存储其中 try: item = BossItem() item['job_name'] = job_name item['salary'] = salary # 添加其他字段... # 返回BossItem对象给Scrapy管道进行进一步处理 yield item except: continue # 关闭新页面 try: driver.close() except: continue # 切换回旧页面 try: driver.switch_to.window(driver.window_handles[-1]) except: continue # 关闭浏览器 driver.quit()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
请注意,这里使用了 Selenium 来模拟浏览器操作,以便在页面加载和元素查找方面更加灵活。同时,我们需要为每个职位信息创建一个 BossItem 对象,并使用 yield 语句返回它们,以便 Scrapy 管道进行进一步处理。
步骤 3: 创建 Item
在 Scrapy 项目中,需要定义要抓取的数据结构。在项目目录下的 items.py 文件中,添加以下代码:
import scrapy class BossItem(scrapy.Item): job_name = scrapy.Field() salary = scrapy.Field() benefit = scrapy.Field() local = scrapy.Field() type = scrapy.Field() requ = scrapy.Field() key = scrapy.Field() detail = scrapy.Field() company = scrapy.Field() market = scrapy.Field() scale = scrapy.Field() business = scrapy.Field() introduce = scrapy.Field() address = scrapy.Field() url = scrapy.Field() hr_name = scrapy.Field() hr_p = scrapy.Field()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这里定义了与职位信息相关的字段,以便在 Spider 中使用。
步骤 4: 配置 Settings
在 Scrapy 项目的 settings.py 文件中,确保已经启用了 Scrapy 的下载中间件,并禁用了默认的 User-Agent。这样可以更好地模拟浏览器行为,减轻反爬虫限制:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy_user_agents.middlewares.RandomUserAgentMiddleware': 400,
# 其他中间件...
}
USER_AGENTS = [
# 添加一些常见的 User-Agent
]
ROBOTSTXT_OBEY = False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
步骤 5: 运行 Spider
现在,你可以在 Scrapy 项目的根目录下运行 Spider:
scrapy crawl bs
- 1
Spider 将开始抓取 Boss 直聘网站上的职位信息,并将它们存储在指定的数据结构中。你可以根据需要进一步配置 Scrapy 的管道,以将数据保存到数据库或其他数据存储中。
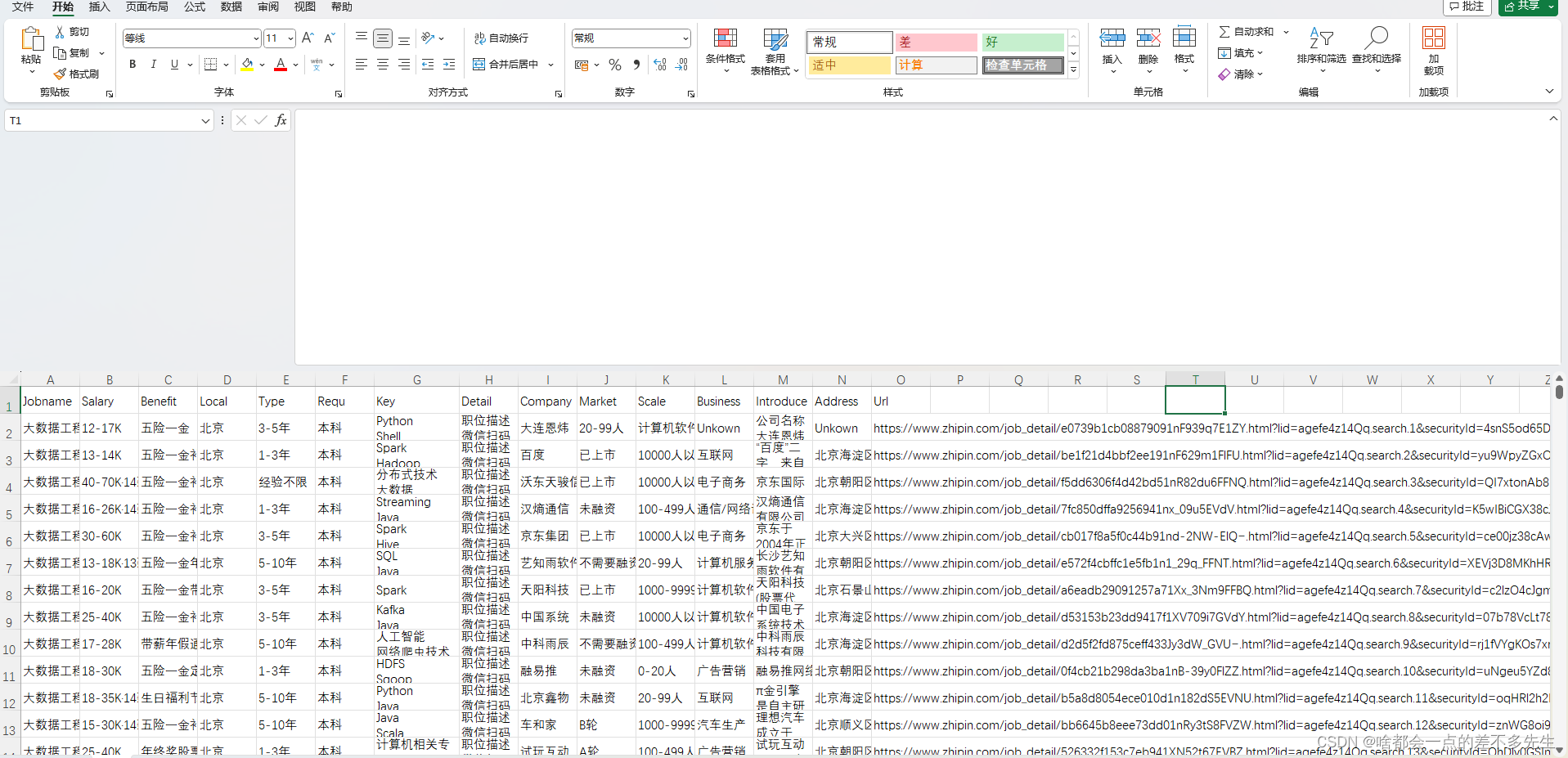
数据结果展示
可视化结果
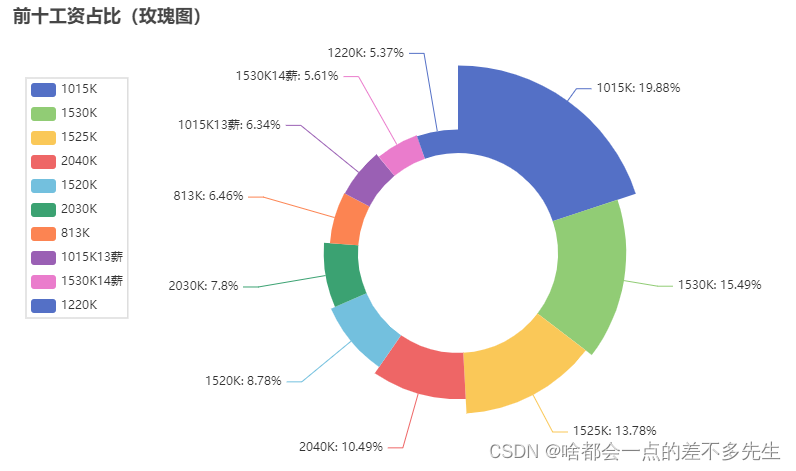
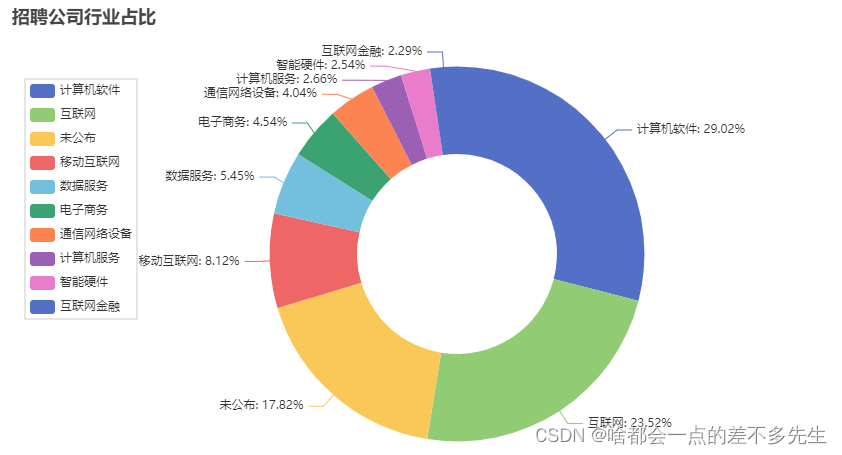
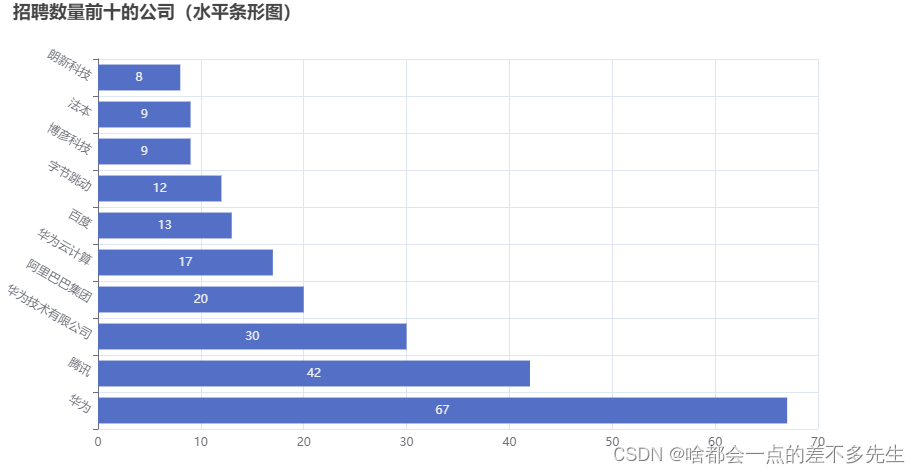
这就是使用 Scrapy 和 Selenium 爬取 Boss 直聘职位信息的完整流程。通过这个示例,你可以学习如何创建一个强大的爬虫来抓取网站上的数据,为你的数据分析和应用提供有用的信息。希望这篇博客对你有所帮助,谢谢阅读!
需要源代码的同学可以添加微信: