
热门标签
热门文章
- 1基于Spring Boot的二手交易平台_基于springboot的二手交易平台
- 2自学软件测试,学到什么程度可以开始找工作?自学1个月找Offer秘籍_软件测试学到什么程度能找到实习
- 3Flink 性能优化总结(反压优化篇)_flink 优化
- 4详解pandas的read_csv函数_pandas read_csv参数详解
- 5今日arXiv最热NLP大模型论文:面向不确定性感知的Language Agent
- 6完全二叉树标准(详细图解)_完全二叉树举例
- 7用Spring Boot maven插件打包成可执行的jar或者war_maven springboot打包
- 8机器人|逆运动学问题解决方法总结_逆运动学数值法优化法
- 9软件开发过程与项目管理(14.项目核心计划执行控制)_开发计划与实际时间不符
- 10YOLOv3论文思想与算法原理_yolov3算法原理
当前位置: article > 正文
LLM-04 大模型 15分钟 FineTuning 微调 ChatGLM3-6B(准备环境) 3090 24GB实战 需22GB显存 LoRA微调 P-TuningV2微调_3090 微调chatglm3
作者:AllinToyou | 2024-05-17 22:43:35
赞
踩
3090 微调chatglm3
背景介绍
ChatGLM3是由智谱AI和清华大学KEG实验室联合开发的一款新一代对话预训练模型。这个模型是ChatGLM系列的最新版本,旨在提供更流畅的对话体验和较低的部署门槛。ChatGLM3-6B是该系列中的一个开源模型,它继承了前两代模型的优秀特性,并引入了一些新的功能和改进。
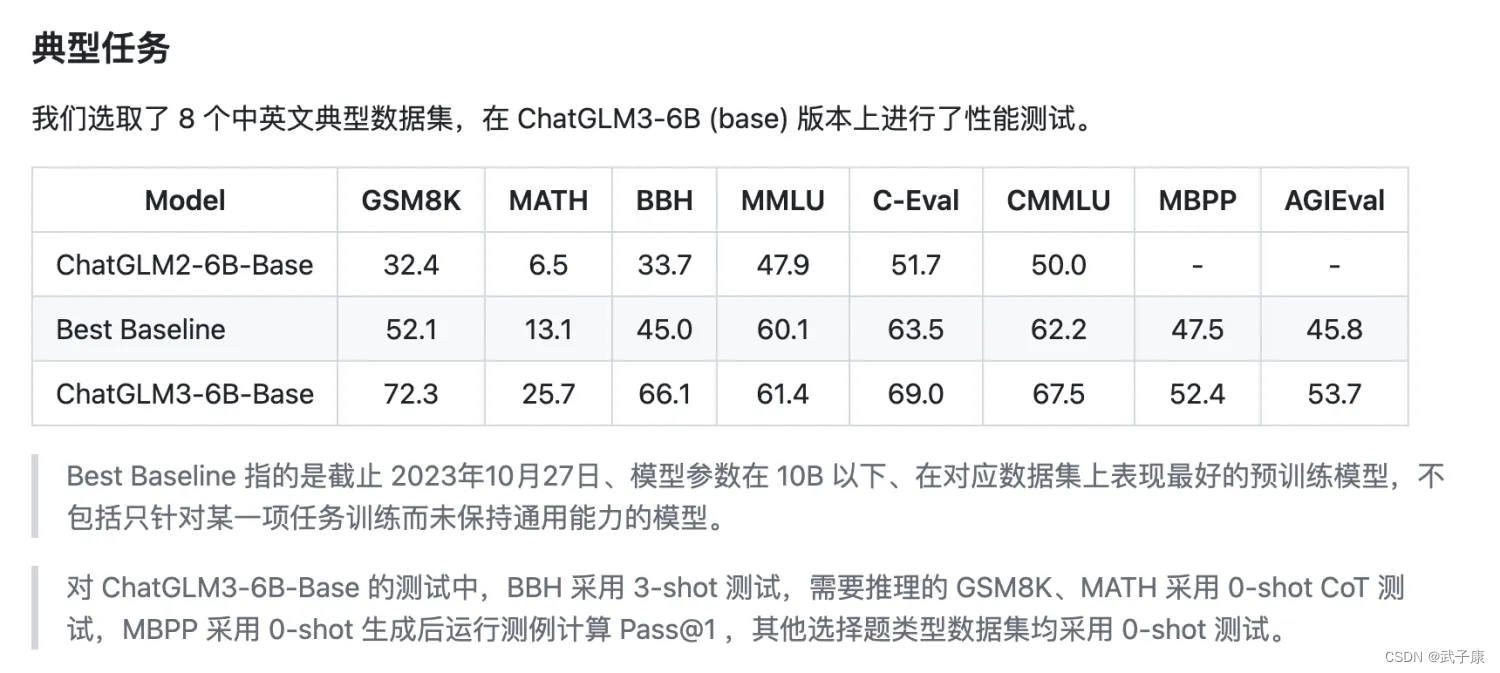
- 基础模型性能提升:ChatGLM3-6B基于更多样的训练数据、更充分的训练步数和更合理的训练策略,使得其基础模型性能得到显著提升。例如,ChatGLM3-6B-Base在10B以下的基础模型中表现最佳。
- 功能支持:ChatGLM3-6B支持多轮对话、工具调用(Function Call)、代码执行(Code Interpreter)和Agent任务。这些功能使得模型不仅能进行普通的对话,还能执行更复杂的任务,如代码解释和工具调用。
- 开源和部署:ChatGLM3-6B作为一个开源模型,鼓励开发者和社区共同推动大模型技术的发展。模型的部署相对简单,支持多种部署方式,包括在本地或云端部署。
安全和合规性:尽管模型在训练各阶段都尽力确保数据的合规性和准确性,但由于其规模较小且受概率随机性影响,无法保证输出内容的准确性。开发者需要注意模型输出可能被用户输入误导的风险。
项目地址
# github
https://github.com/THUDM/ChatGLM3
- 1
- 2
# huggingface
https://huggingface.co/THUDM/chatglm3-6b
- 1
- 2

配置要求
官方推荐
我们仅提供了单机多卡/多机多卡的运行示例,因此您需要至少一台具有多个 GPU 的机器。本仓库中的默认配置文件中,我们记录了显存的占用情况:
- SFT 全量微调: 4张显卡平均分配,每张显卡占用 48346MiB 显存。
- P-TuningV2 微调: 1张显卡,占用 18426MiB 显存。
- LORA 微调: 1张显卡,占用 14082MiB 显存。
实机配置
目前我有三个方案:
- 方案1:MacBookProM1 16GB(平常用的机器,可以支撑起 LoRA…勉强跑 不推荐)
- 方案2:找算法组借的 2070 Super 8GB * 2 一共16GB显存(但是不能微调,后续说)
- 方案3:租的 3090 24GB * 1(完美,ChatGLM3-6B的微调任务都在该机器上完成的)

微调选择
方案1,可以作为学习可以,但是由于本身MPS的问题,运行速度并不快,而且M1最高配置只有16GB,非常难受。
方案2,虽然我们的总量够了 16GB,达到了 LoRA 和 P-TuningV2 的要求,但是要求每张显卡都有可以完整放下模型的空余,也就是说,我们单卡的 8GB 是不满足的。具体需要13GB,可看上章节 LLM-02 中的实机运行内容。
方案3,虽然不便宜,但是是主力机了。后续的微调都在这里完成。
由于 全量 SFT 要求的显存买不起··· 所以选择了 LoRA 和 P-TuningV2。
准备工作
更新系统
先更新下操作系统,等等内容,CUDA版本等等。
sudo apt update
sudo apt install -y build-essential libbz2-dev libssl-dev libffi-dev zlib1g-dev libncurses5-dev libncursesw5-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-dev
- 1
- 2
Pyenv
配置一个新的环境,确保安装3.10版本,避免版本问题。
# 安装
pyenv install 3.10
# 配置全局,也可以使用 local 配置当前目录
pyenv global 3.10
# 测试
python
- 1
- 2
- 3
- 4
- 5
- 6

venv
独立的包环境,防止依赖之间互相干扰。
python -m venv env
source env/bin/active
- 1
- 2
克隆项目
这里直接GitHub走起!
克隆项目之后,我还安装了依赖。
pip install -r requirements.txt
- 1

下载模型
模型的目录是(我发现好多人找不到自己下载的模型在哪里···)
~/.cache/huggingface/
- 1
如果你有下载到指定目录的需求,可以使用如下的代码帮助你:
from transformers import AutoTokenizer, AutoModel
model_name = "THUDM/chatglm3-6b"
model_path = "/root/autodl-tmp/model/chatglm3-6b"
tokenizer = AutoTokenizer.from_pretrained(model_name,trust_remote_code=True)
model = AutoModel.from_pretrained(model_name,trust_remote_code=True)
tokenizer.save_pretrained(model_path,trust_remote_code=True)
model.save_pretrained(model_path,trust_remote_code=True)
print("done!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

我的下载目录是这里:
# 以后可以用这个路径
/root/autodl-tmp/model/chatglm3-6b
- 1
- 2

启动测试
我的模型地址:
python /root/autodl-tmp/ChatGLM3/basic_demo/cli_demo.py
- 1
正常启动(注意模型的位置,可以vim查看cli_demo.py中的MODEL_PATH)

微调依赖
# 官方准备的微调示例
cd /root/autodl-tmp/ChatGLM3/finetune_demo/
# 安装依赖
pip install -r requirements.txt
- 1
- 2
- 3
- 4

等待依赖安装完毕

本章小结
到此,环境的准备工作已经完成!下一节我们开始微调!
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/585512
推荐阅读
相关标签

