
- 1标准DH建模与改进DH建模(三)—— 怎么用改进DH法_工业机器人dh和改进dh
- 2带T带Z的时间字符串使用LocalDateTime类转换成时间/时间戳类型_时间戳 t z
- 3命令行实现FFMpeg拉流推流方法思路_ffmpeg 推流 命令行
- 4数据安全被篡改的风险分析解决方案_信息安全 数据窜改风险监测
- 5解决 macOS 系统向日葵远程控制鼠标、键盘无法点击的问题_macos远程windows桌面键盘锁了
- 6完美收官!字节4面斩下2-2Offer,入职就是30K16薪,全凭这套“面试+架构进阶知识点
- 7python lxml用法
- 8[Linux防火墙]一文学会防火墙概念及常用命令_linux防火墙怎么设置默认区域
- 9Linux环境(Ubuntu)上搭建MQTT服务器(EMQX )_ubuntu怎么开放emqx相关端口
- 10【MATLAB源码-第139期】基于matlab的OFDM信号识别与相关参数的估计,高阶累量/小波算法调制识别,循环谱估计,带宽估计,载波数目估计等等。_ofdm循环谱
数字信号处理-02- FPGA常用运算模块-加减法器和乘法器_fpga 信道模拟器如何乘以衰减系数
赞
踩
写在前面
本文是本系列的第二篇,本文主要介绍FPGA常用运算模块-加减法器和乘法器,xilinx提供了相关的IP以便于用户进行开发使用。
加减法器模块
在xilinx中,有一个IP模块提供加减法运算的功能,
概述
加法器/减法器IP 提供 LUT 和单个 DSP slice 实现加减法实现。加法器/减法器模块可以创建加法器(A+B)、减法器(A–B) 和可动态配置的加法器/减法器,用于操作有符号或无符号数据。该功能可以在一个单个 DSP slice 或 LUT(但目前不是两者的混合)。该模块可以流水线化。支持fabric实现输入范围从1到256位宽,该IP核支持DSP片实现,输入高达58位。可选进位输入和输出、时钟启用和同步清除、旁路(负载)能力、设置B值为一个常量。
IP核图示以及端口介绍
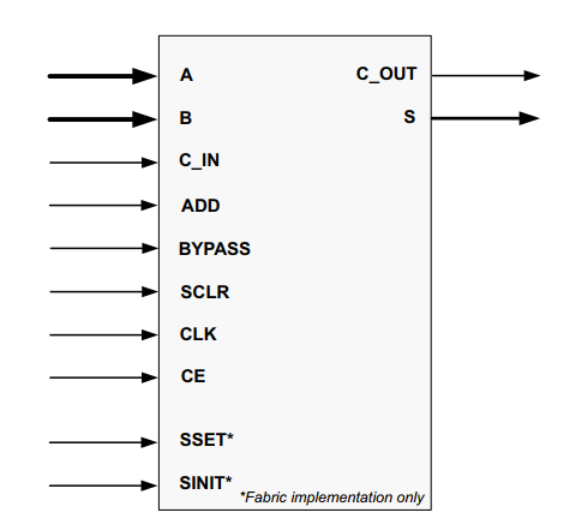
| Name | Direction | Description |
|---|---|---|
| A[N:0] | Input | 输入端口A,位宽为N+1 |
| B[M:0] | Input | 输入端口B,位宽为M+1 |
| ADD | Input | 控制加法器/减法器执行的操作(1=加法,0=减法) |
| C_IN | Input | 进位输入 |
| C_OUT | Output | 进位输出 |
| S[P:0] | Output | 结果输出 |
| BYPASS | Input | 旁路控制,将B输出给S |
| CE | Input | 时钟使能,高有效 |
| CLK | Input | 时钟信号,上升沿有效 |
| SCLR | Input | 同步复位,将重置核心中的所有寄存器,定制内核时可以选择SCLR和CE引脚的优先级 |
| SINIT | Input | Synchronous Initialization - forces outputs to a user defined state when driven High |
| SSET | Input | Synchronous Set - forces outputs to a High state when driven High |
如果Constant Input = TRUE and Bypass = FALSE,则B端口不存在。一个用户定义的核心内部常量被应用到B操作数的位置。
输出位宽设计
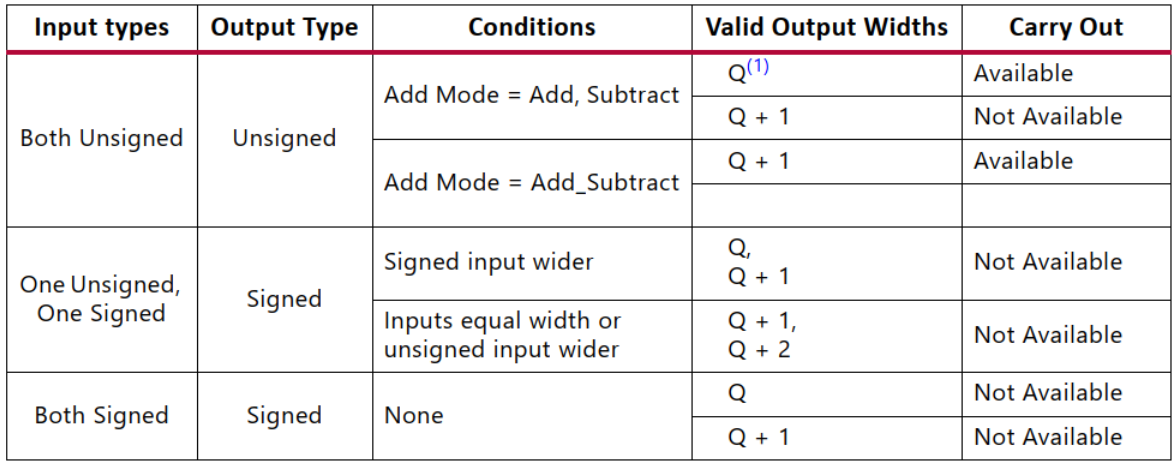
Q的值等于AB输入两者之间的最大值。
流水线操作
加法器/减法器模块可以选择流水线操作用来提高速度。流水线操作由延迟参数控制。将延迟配置设置为自动,以实现最优的流水线速度。将延迟配置设置为手动,以允许在延迟参数中输入有效数量的流水线层级数。
DSP片
对于DSP片的实现方式,单个的DSP片可以用0、1或2级寄存器进行流水线操作。Latency Configuration = Automatic ,此时优化速度延迟获得最优的流水操作速度;如果Latency = 1, 只有输出寄存器存在。Latency = 2,输出和输入寄存器都存在。
Fabric 实现
对于使用PFGA的逻辑资源的实现方式,流水线操作是通过将输入总线 分成许多总线片(等于流水线阶段的数量)来实现的。在第一阶段,对每个总线片做尽可能多的工作,将它们加在一起,并存储结果和每个结果的进位输出。在第二阶段,从最低有效位的部分得到的进位被输入到下一个较高有效位的结果中,它产生一个进位被输入到下一个阶段的下一个结果中,直到进位被传播到顶部。
因为需要存储的数据较少,所以这比存储每个切片的输入直到生成该切片的进位的更直观的技术更有效。 此外,该设计更小且更易于布线。
上电或复位后,流水线模块需要几个时钟周期才使输出变为有效,由延迟控制参数指定。
如果在流水线模块上请求旁路,则旁路值会在延迟控制指定的时钟周期数之后出现在输出上。如果同时请求旁路和时钟使能,则必须设置旁路优先级,以便旁路不会覆盖时钟使能。 对于流水线模块,资源使用率大约是非流水线模块的延迟倍数。为了提高时钟速度,流水线导致面积使用量的显着增加。 如果需要延迟但面积比速度更重要,请在此模块的 S 输出中添加一个基于 SRL16 的移位寄存器,以优化面积使用。
加法器IP配置
加法器IP配置如图所示,
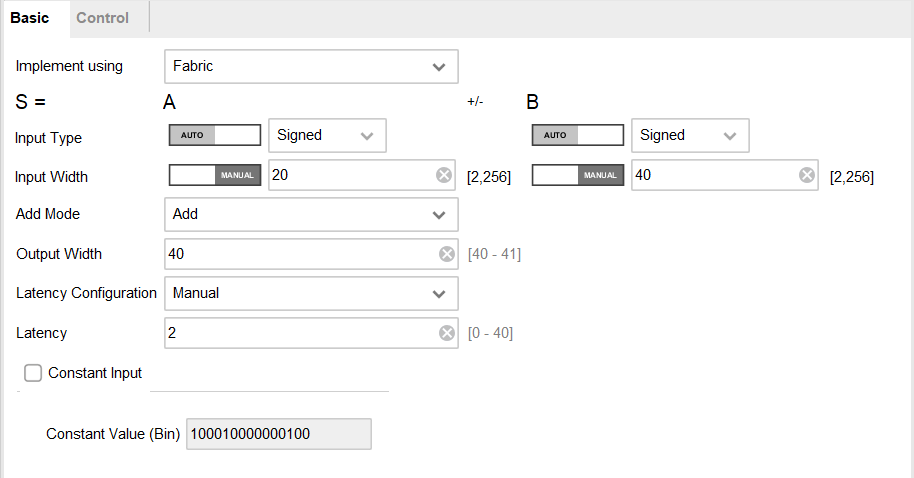
在basic界面,可以对IP的实现方式,输入的数据类型,位宽,IP的方式(加法器、减法器、加减法器)、流水操作延迟方式和延时周期,常数输入进行配置。
Constant Input and Constant Value :当常量输入为 TRUE 时,端口 B 设置为参数 Constant Value 指定的值。常数值必须是以二进制格式输入且不得超过 B 输入宽度。在大多数情况下指定端口 B 是一个常量时候,会自动创建一个没有端口 B 的模块。但是在当请求旁路功能时,因为需要端口 B 来提供旁路数据。默认是端口 B 提供的端口 B 值。会生成B端口。
加减法器的控制配置界面如下,
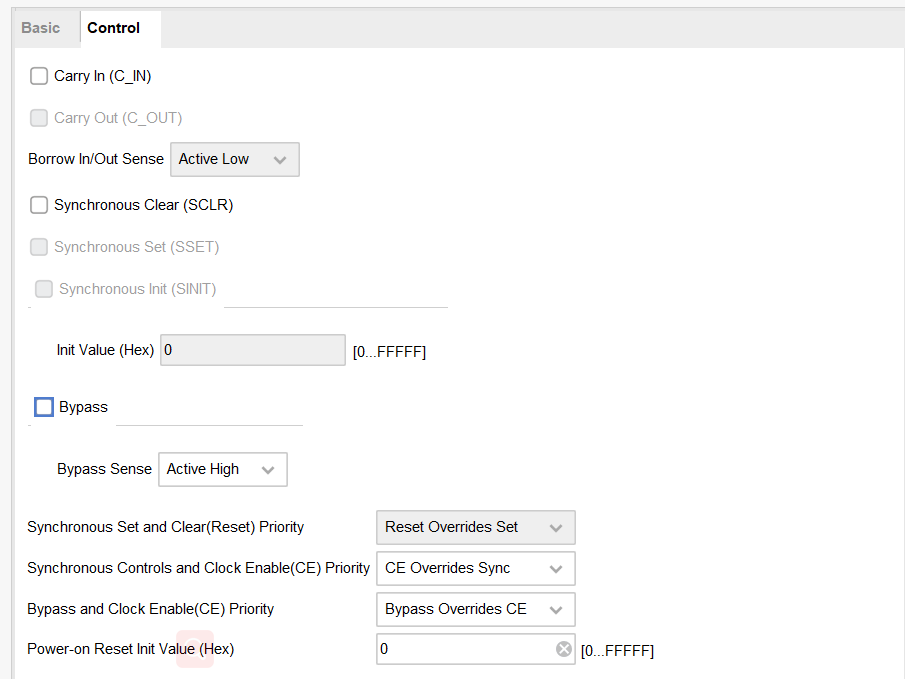
在控制界面可以配置加减法器进位、旁路、复位等控制操作。
Carry In :设置为TRUE时,创建一个C_IN端口。这是用于加法器的高电平有效进位端口和用于减法器和加/减法器的可编程(高电平有效/低电平有效,带借入/输出检测)进位端口。
Carry Out :当设置为TRUE时,创建一个端口C_OUT。实现了加法器和加减法器的高有效同步进位,以及可编程(设置高低有效,借入/借出检测)的减法器和加减法器中的减法器的借位标志。
Bypass :设置为 TRUE 时,创建旁路引脚。激活 BYPASS 引脚设置输出为端口 B 上给定的值。此功能用于创建可加载的计数器和累加器。
Bypass and Clock Enable (CE) Priority :该参数控制是否旁路输入由时钟使能限定。当设置为Bypass_Overrides_CE时,BYPASS 信号的激活也使能寄存器。当设置为CE_Overrides_Bypass,寄存器必须有 CE 激活才能加载 B 端口数据。
Bypass Sense :控制旁路的敏感电平,是高有效还是低有效,因为高低电平有效在有些时候都能获得更好的效率。
Borrow In/Out Sense :当设置为Active_Low时,用于减法的C_IN和C_OUT引脚是低有效的。这符合fabric实现规则,是一个最佳设置。
Synchronous Set :指定是否包含 SSET 引脚。 在DSP实现模式下,SSET 引脚无效。
Synchronous Init :指定是否包含一个SINIT引脚,当断言时,该引脚同步地将输出值设置为Init value定义的值。如果SINIT存在,那么SSET和SCLR都不存在。 在DSP实现模式下,SINIT引脚是无效的。
Init Value :十六进制指定当断言SINIT时输出初始化为指定的值。如果Synchronous Init = false 则忽略。
Power on Reset Init Value :指定(十六进制)S寄存器在上电复位时初始化的值。
Synchronous Controls and Clock Enable (CE) Priority : 该参数控制SCLR(以及逻辑单元模式下的SSET和SINIT)输入是否由时钟使能限定。当设置为 Sync_Overrides_CE 时,同步控制覆盖 CE 信号。 当设置为 CE_Overrides_Sync 时,控制信号仅在 CE 为高时有效。 请注意,在结构原语上,SCLR 和 SSET 控制覆盖 CE,因此选择 CE_Overrides_Sync 通常会导致额外的逻辑。
Sync Set and Clear (Reset) Priority :控制 SCLR 和 SSET 的相对优先级。当设置为 Reset_Overrides_Set 时,SCLR 会覆盖 SSET。默认值是Reset_Overrides_Set,因为这是原语的排列方式。使 SSET 优先需要额外的逻辑。
乘法器
乘法器IP实现高性能、优化的乘法器方案。可以使用资源和性能权衡选项来为特定的应用程序定制IP。该IP支持输入范围从1到64位,输出从1到128位。所有乘法器都可配置延迟。当使用DSP Slice时,支持对称四舍五入到无限。
概述
乘法器IP允许设计者精细地构建定点乘法器。可以使用 DSP Slices、Slice 逻辑或组合的方式进行构建乘法器IP,并且针对性能或资源进行了优化的结构。常数系数乘法器也可以使用许多不同的逻辑资源选项来实现。并且可以通过流水线操作层级数量以适应延迟和性能要求。DSP Slice的对称舍入特性可用于并行乘法器。
IP核图示以及端口介绍
| Signal | Direction | Description |
|---|---|---|
| A[N-1:0] | Input | 乘数A,位宽为N |
| B[M-1:0] | Input | 乘数B,位宽为M,只有在parallel multipliers模式下有该端口。 |
| CLK | Input | 时钟信号 |
| CE | Input | 高有效时钟使能信号 |
| SCLR | Input | 高有效同步复位信号,(SCLR/CE 优先级可以配置) |
| P[X:Y] | Output | 乘法输出 |
乘法器IP配置
乘法器IP的basic配置界面如下:
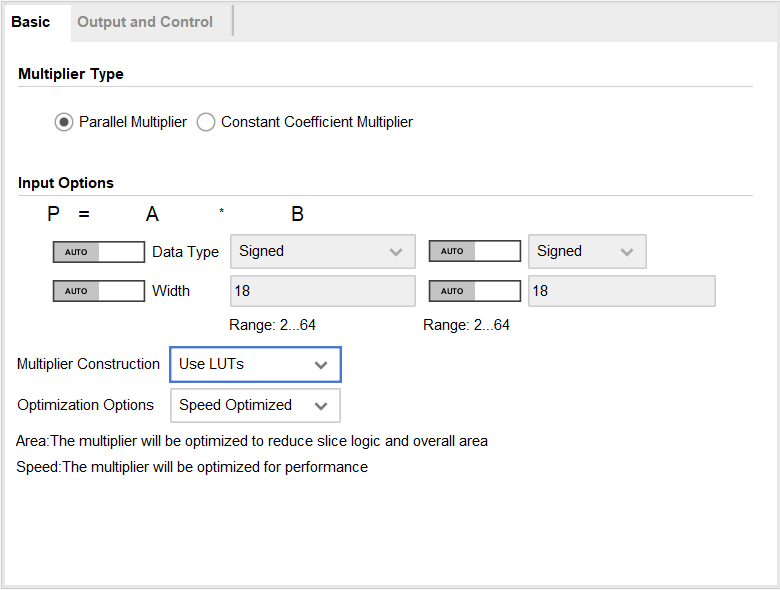
在该界面可以进行配置乘法器的类型,乘数的数据类型,位宽,乘法器的实现方式以及优化方式。
Multiplier Type :在并行和常数系数乘法器选项之间进行选择。
并行乘法器选项:这些选项只有当选择的乘法器类型是并行乘法器时才可见。
-
Multiplier Construction :选择用于IP实现的结构是LUT还是专用乘法器原语。
-
Optimization Options :
DSP48E1 Slice:可以为高达 47x47 的乘法器大小选择速度或面积优化。 速度优化 :充分利用乘法器原语来提供最高性能的实现。面积优化 :混合使用切片逻辑和专用乘法器原语来降低基于 DSP 切片的乘法器利用率,同时仍提供合理的性能。 对于 47x47 以上的尺寸,只允许优化速度。
LUT-based multipliers : 区域优化降低了延迟和LUT利用率,以可实现的时钟频率为代价。当两个输入操作数都是无符号且两个输入操作数都小于16位时,区域优化是最有效的。
Constant-Coefficient Multiplier Options :这些选项只有当选择的乘数类型是常数系数乘法器时才可见。
- Coefficient :在显示的范围内输入系数的整数值。 支持正系数和负系数。 常量 (B) 端口的输入类型(有符号或无符号)由 Vivado IDE 根据输入的整数常量自动配置。 可以选择 A 端口是有符号的还是无符号的。
- Memory Options : 选择乘法器是使用分布式内存、块内存还是使用 DSP Slices 来实现。
乘法器IP的输出控制配置界面如下:
Output Product Range: 根据输入操作数的宽度自动配置输出产品宽度。
Use Custom Output Width :如果通过设置 MSB 和 LSB 范围,对输出进行切片。
Use Symmetric Rounding :对于基于 DSP Slice 的并行乘法器,如果需要,可以将乘积对称舍入到无穷大。这与MATLAB的 round 函数的行为相同。
Pipelining and Control Signals:
Pipeline Stages :
为乘数实例选择流水线操作的层级。右边的标签提供了关于实现最佳性能的流水操作的最佳数量的反馈。
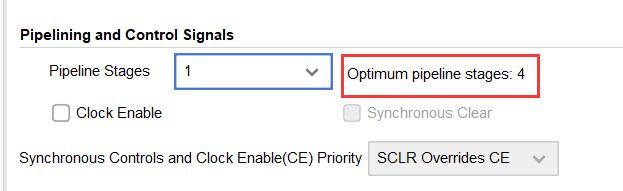
- Pipeline Stages = 0 意味着IP是组合的。
- Pipeline Stages = 1 意味着IP的输出是寄存器型的。
- Pipeline Stages > 1 使寄存器插入到输入和输出之间,直到最优的流水线操作的层级。添加更多寄存器可以提高可实现的时钟速度,同时增加延迟。
流水线操作的层级设置的值大于最优值的值,将导致在输出时添加基于SRL16的移位寄存器,以实现额外的延迟。
- Clock Enable :选择设计中的所有寄存器是否都具有时钟使能控制。
- Synchronous Clear :选择是否该设计中的所有寄存器都具有同步复位控制。
- SCLR/CE Priority :当SCLR和CE引脚同时存在时,可以选择scr和CE的优先级。选择 SCLR overrides CE ,使用的资源最少,实现的性能最好。
References
- PG192
- PG108

