
- 1Android——APP启动流程&&Android开机流程_安卓app 启动 顺序
- 2微信小程序getUserProfile详解_wx.getuserprofile
- 3[UNet]通过一个小测试了解Command和ClientRpc的功能
- 4Git Manual / Git使用手册 / Git, GitLab, Git Bash, TortoiseGit (建议全文复制到Word文档中通过导航窗格查看)...
- 5王道考研购物网站(JSP+java+springmvc+mysql+MyBatis)
- 6WPF 登录窗口demo示例
- 7NumPy的实用函数整理之where_numpy where
- 8机器学习 决策树_头歌决策树案例
- 9Pandas透视表大揭秘:从基础到高级技巧的完整指南_pandas数据透视表函数
- 10五种常见的电子商务模式对比:B2B、B2C、C2B、C2C、O2O
Kubernetes 进阶训练营 控制器_matchexpressions
赞
踩
控制器
前面我们一起学习了 Pod 的原理和一些基本使用,但是在实际使用的时候并不会直接使用 Pod,而是会使用各种控制器来满足我们的需求,Kubernetes 中运行了一系列控制器来确保集群的当前状态与期望状态保持一致,它们就是 Kubernetes 的大脑。例如,ReplicaSet 控制器负责维护集群中运行的 Pod 数量;Node 控制器负责监控节点的状态,并在节点出现故障时及时做出响应。总而言之,在 Kubernetes 中,每个控制器只负责某种类型的特定资源。
Kubernetes 控制器会监听资源的 创建/更新/删除 事件,并触发 Reconcile 调谐函数作为响应,整个调整过程被称作 “Reconcile Loop”(调谐循环) 或者 “Sync Loop”(同步循环)。Reconcile 是一个使用资源对象的命名空间和资源对象名称来调用的函数,使得资源对象的实际状态与 资源清单中定义的状态保持一致。调用完成后,Reconcile 会将资源对象的状态更新为当前实际状态。我们可以用下面的一段伪代码来表示这个过程:
for {
desired := getDesiredState() // 期望的状态
current := getCurrentState() // 当前实际状态
if current == desired { // 如果状态一致则什么都不做
// nothing to do
} else { // 如果状态不一致则调整编排,到一致为止
// change current to desired status
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这个编排模型就是 Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。
ReplicaSet 控制器
和 Pod 一样我们仍然还是通过 YAML 文件来描述我们的 ReplicaSet 资源对象,如下 YAML 文件是一个常见的 ReplicaSet 定义
# nginx-rs.yaml apiVersion: apps/v1 kind: ReplicaSet metadata: name: nginx-rs namespace: default spec: replicas: 3 # 期望的 Pod 副本数量,默认值为1 selector: # Label Selector,必须匹配 Pod 模板中的标签 matchLabels: app: nginx template: # Pod 模板 metadata: labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
上面的 YAML 文件结构和我们之前定义的 Pod 看上去没太大两样,有常见的 apiVersion、kind、metadata,在 spec 下面描述 ReplicaSet 的基本信息,其中包含3个重要内容:
- replias:表示期望的 Pod 的副本数量
- selector:Label Selector,用来匹配要控制的 Pod 标签,需要和下面的 Pod 模板中的标签一致
- template:Pod 模板,实际上就是以前我们定义的 Pod 内容,相当于把一个 Pod 的描述以模板的形式嵌入到了 ReplicaSet 中来。
ReplicaSet 控制器会通过定义的 Label Selector 标签去查找集群中的 Pod 对象:
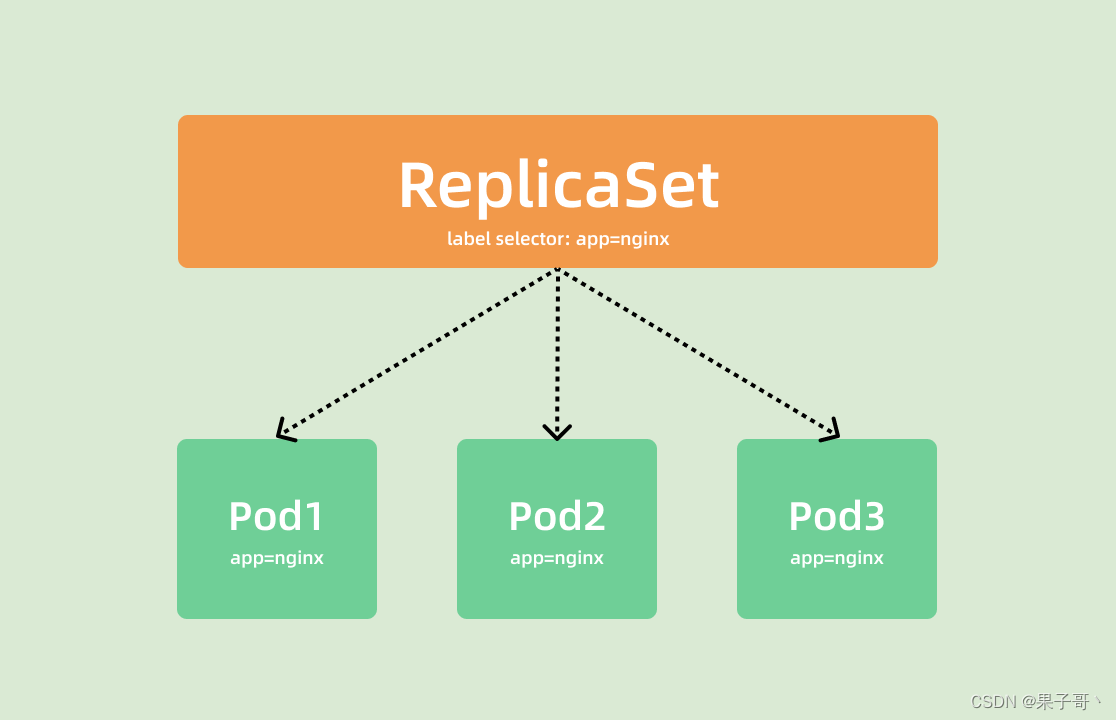
另外被 ReplicaSet 持有的 Pod 有一个 metadata.ownerReferences 指针指向当前的 ReplicaSet,表示当前 Pod 的所有者,这个引用主要会被集群中的垃圾收集器使用以清理失去所有者的 Pod 对象。这个 ownerReferences 和数据库中的外键是不是非常类似。可以通过将 Pod 资源描述信息导出查看:
➜ ~ kubectl get pod nginx-rs-xsb59 -o yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: "2021-11-03T06:18:10Z" generateName: nginx-rs- labels: app: nginx name: nginx-rs-xsb59 namespace: default ownerReferences: - apiVersion: apps/v1 blockOwnerDeletion: true controller: true kind: ReplicaSet name: nginx-rs uid: 4a3121fa-b5ae-4def-b2d2-bf17bc06b7b7 resourceVersion: "1781596" selfLink: /api/v1/namespaces/default/pods/nginx-rs-xsb59 uid: 0a4cae9a-105b-4024-ae96-ee516bfb2d23 ......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我们可以看到 Pod 中有一个 metadata.ownerReferences 的字段指向了 ReplicaSet 资源对象。如果要彻底删除 Pod,我们就只能删除 RS 对象:
➜ ~ kubectl delete rs nginx-rs
# 或者执行 kubectl delete -f nginx-rs.yaml
- 1
- 2
这就是 ReplicaSet 对象的基本使用。
比如上面资源对象如果我们要使用 RC 的话,对应的 selector 是这样的:
selector:
app: nginx
- 1
- 2
RC 只支持单个 Label 的等式,而 RS 中的 Label Selector 支持 matchLabels 和 matchExpressions 两种形式:
selector:
matchLabels:
app: nginx
---
selector:
matchExpressions: # 该选择器要求 Pod 包含名为 app 的标签
- key: app
operator: In
values: # 并且标签的值必须是 nginx
- nginx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Deployment
Deployment 资源对象的格式和 ReplicaSet 几乎一致,如下资源对象就是一个常见的 Deployment 资源类型
# nginx-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deploy namespace: default spec: replicas: 3 # 期望的 Pod 副本数量,默认值为1 selector: # Label Selector,必须匹配 Pod 模板中的标签 matchLabels: app: nginx template: # Pod 模板 metadata: labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我们这里只是将类型替换成了 Deployment,我们可以先来创建下这个资源对象:
➜ ~ kubectl apply -f nginx-deploy.yaml
deployment.apps/nginx-deploy created
➜ ~ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 3/3 3 3 58s
- 1
- 2
- 3
- 4
- 5
都是根据spec.replicas来维持的副本数量,我们随意查看一个 Pod 的描述信息:
➜ ~ kubectl describe pod nginx-deploy-85ff79dd56-txc4h
Controlled By: ReplicaSet/nginx-deploy-85ff79dd56
- 1
- 2
Controlled By: ReplicaSet/nginx-deploy-85ff79dd56,什么意思?是不是表示当前我们这个 Pod 的控制器是一个 ReplicaSet 对象啊,我们不是创建的一个 Deployment 吗?为什么 Pod 会被 RS 所控制呢?观察对应的RS对象的详细信息。
➜ ~ kubectl describe rs nginx-deploy-85ff79dd56
Controlled By: Deployment/nginx-deploy
- 1
- 2
其中有这样的一个信息:Controlled By: Deployment/nginx-deploy,明白了吧?意思就是我们的 Pod 依赖的控制器 RS 实际上被我们的 Deployment 控制着呢,我们可以用下图来说明 Pod、ReplicaSet、Deployment 三者之间的关系:
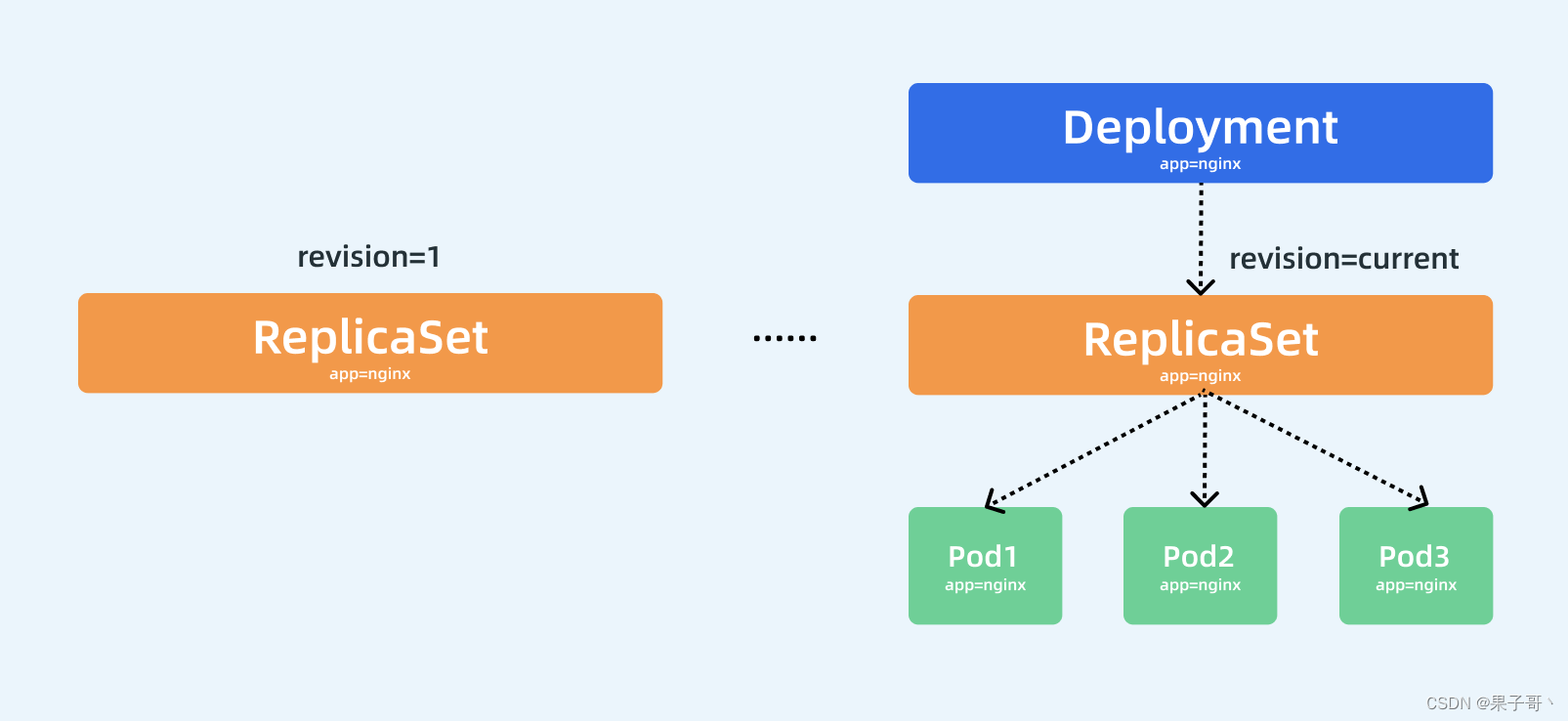
通过上图我们可以很清楚的看到,定义了3个副本的 Deployment 与 ReplicaSet 和 Pod 的关系,就是一层一层进行控制的。ReplicaSet 作用和之前一样还是来保证 Pod 的个数始终保存指定的数量,所以 Deployment 中的容器 restartPolicy=Always 是唯一的就是这个原因,因为容器必须始终保证自己处于 Running 状态,ReplicaSet 才可以去明确调整 Pod 的个数。而 Deployment 是通过管理 ReplicaSet 的数量和属性来实现水平扩展/收缩以及滚动更新两个功能的。
水平扩展/收缩
kubectl scale 命令来完成这个操作
➜ ~ kubectl scale deployment nginx-deploy --replicas=4
deployment.apps/nginx-deployment scaled
- 1
- 2
可以看到 ReplicaSet 控制器增加了一个新的 Pod,同样的 Deployment 资源对象的事件中也可以看到完成了扩容的操作:
➜ ~ kubectl describe deploy nginx-deploy
Name: nginx-deploy
Namespace: default
......
OldReplicaSets: <none>
NewReplicaSet: nginx-deploy-85ff79dd56 (4/4 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 43m deployment-controller Scaled up replica set nginx-deploy-85ff79dd56 to 3
Normal ScalingReplicaSet 3m16s deployment-controller Scaled up replica set nginx-deploy-85ff79dd56 to 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
滚动更新
如果只是水平扩展/收缩这两个功能,就完全没必要设计 Deployment 这个资源对象了,Deployment 最突出的一个功能是支持滚动更新,比如现在我们需要把应用容器更改为 nginx:1.7.9 版本,修改后的资源清单文件如下所示:
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deploy namespace: default spec: replicas: 3 selector: matchLabels: app: nginx minReadySeconds: 5 strategy: type: RollingUpdate # 指定更新策略:RollingUpdate和Recreate rollingUpdate: maxSurge: 1 maxUnavailable: 1 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
后前面相比较,除了更改了镜像之外,我们还指定了更新策略:
minReadySeconds: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
- 1
- 2
- 3
- 4
- 5
- 6
- minReadySeconds:表示 Kubernetes 在等待设置的时间后才进行升级,如果没有设置该值,Kubernetes 会假设该容器启动起来后就提供服务了,如果没有设置该值,在某些极端情况下可能会造成服务不正常运行,默认值就是0。
- type=RollingUpdate:表示设置更新策略为滚动更新,可以设置为Recreate和RollingUpdate两个值,Recreate表示全部重新创建,默认值就是RollingUpdate。
- maxSurge:表示升级过程中最多可以比原先设置多出的 Pod 数量 ,例如:maxSurage=1,replicas=5,就表示Kubernetes 会先启动一个新的 Pod,然后才删掉一个旧的 Pod,整个升级过程中最多会有5+1个 Pod。
- maxUnavaible:表示升级过程中最多有多少个 Pod 处于无法提供服务的状态,当maxSurge不为0时,该值也不能为0,例如:maxUnavaible=1,则表示 Kubernetes 整个升级过程中最多会有1个 Pod 处于无法服务的状态。
我们可以添加了一个额外的
--record参数来记录下我们的每次操作所执行的命令,以方便后面查看。
现在我们来直接更新上面的 Deployment 资源对象:
kubectl apply -f nginx-deploy.yaml
- 1
更新后,我们可以执行下面的 kubectl rollout status 命令来查看我们此次滚动更新的状态:
➜ ~ kubectl rollout status deployment/nginx-deploy
Waiting for deployment "nginx-deploy" rollout to finish: 2 out of 3 new replicas have been updated...
- 1
- 2
从上面的信息可以看出我们的滚动更新已经有两个 Pod 已经更新完成了,在滚动更新过程中,我们还可以执行如下的命令来暂停更新
➜ ~ kubectl rollout pause deployment/nginx-deploy
deployment.apps/nginx-deploy paused
- 1
- 2
这个过程就是滚动更新的过程,启动一个新的 Pod,杀掉一个旧的 Pod,然后再启动一个新的 Pod,这样滚动更新下去,直到全都变成新的 Pod,这个时候系统中应该存在 4 个 Pod,因为我们设置的策略maxSurge=1,所以在升级过程中是允许的,而且是两个新的 Pod,两个旧的 Pod。
回滚到前面的任意一个版本,这个版本是如何定义的呢?我们可以通过命令 rollout history 来获取:
➜ ~ kubectl rollout history deployment nginx-deploy
deployment.apps/nginx-deploy
REVISION CHANGE-CAUSE
1 <none>
2 <none>
- 1
- 2
- 3
- 4
- 5
其实 rollout history 中记录的 revision 是和 ReplicaSets 一一对应。如果我们手动删除某个 ReplicaSet,对应的rollout history就会被删除,也就是说你无法回滚到这个revison了,同样我们还可以查看一个revison的详细信息:
➜ ~ kubectl rollout history deployment nginx-deploy --revision=1
deployment.apps/nginx-deploy with revision #1
Pod Template:
Labels: app=nginx
pod-template-hash=85ff79dd56
Containers:
nginx:
Image: nginx
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
假如现在要直接回退到当前版本的前一个版本,我们可以直接使用如下命令进行操作:
➜ ~ kubectl rollout undo deployment nginx-deploy
- 1
当然也可以回退到指定的revision版本:
➜ ~ kubectl rollout undo deployment nginx-deploy --to-revision=1
deployment "nginx-deploy" rolled back
- 1
- 2
回滚的过程中我们同样可以查看回滚状态:
➜ ~ kubectl rollout status deployment/nginx-deploy
Waiting for deployment "nginx-deploy" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "nginx-deploy" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "nginx-deploy" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "nginx-deploy" rollout to finish: 2 of 3 updated replicas are available...
Waiting for deployment "nginx-deploy" rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx-deploy" successfully rolled out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这个时候查看对应的 RS 资源对象可以看到 Pod 副本已经回到之前的 RS 里面去了。
➜ ~ kubectl get rs -l app=nginx
NAME DESIRED CURRENT READY AGE
nginx-deploy-5b7b9ccb95 0 0 0 31m
nginx-deploy-85ff79dd56 3 3 3 95m
- 1
- 2
- 3
- 4
不过需要注意的是回滚的操作滚动的revision始终是递增的:
➜ ~ kubectl rollout history deployment nginx-deploy
deployment.apps/nginx-deploy
REVISION CHANGE-CAUSE
2 <none>
3 <none>
- 1
- 2
- 3
- 4
- 5
StatefulSet控制器
Deployment 并不能编排所有类型的应用,对无状态服务编排是非常容易的,但是对于有状态服务就无能为力了。我们需要先明白一个概念:什么是有状态服务,什么是无状态服务。
- 无状态服务(Stateless Service):该服务运行的实例不会在本地存储需要持久化的数据,并且多个实例对于同一个请求响应的结果是完全一致的,比如前面我们讲解的 WordPress 实例,我们是不是可以同时启动多个实例,但是我们访问任意一个实例得到的结果都是一样的吧?因为他唯一需要持久化的数据是存储在MySQL数据库中的,所以我们可以说 WordPress 这个应用是无状态服务,但是 MySQL 数据库就不是了,因为他需要把数据持久化到本地。
- 有状态服务(Stateful Service):就和上面的概念是对立的了,该服务运行的实例需要在本地存储持久化数据,比如上面的 MySQL 数据库,你现在运行在节点 A,那么他的数据就存储在节点 A 上面的,如果这个时候你把该服务迁移到节点 B 去的话,那么就没有之前的数据了,因为他需要去对应的数据目录里面恢复数据,而此时没有任何数据。
现在对有状态和无状态有一定的认识了吧,比如我们常见的 WEB 应用,是通过 Session 来保持用户的登录状态的,如果我们将 Session 持久化到节点上,那么该应用就是一个有状态的服务了,因为我现在登录进来你把我的 Session 持久化到节点 A 上了,下次我登录的时候可能会将请求路由到节点 B 上去了,但是节点 B 上根本就没有我当前的 Session 数据,就会被认为是未登录状态了,这样就导致我前后两次请求得到的结果不一致了。所以一般为了横向扩展,我们都会把这类 WEB 应用改成无状态的服务,怎么改? ==将 Session 数据存入一个公共的地方,比如 Redis 里面 == ,是不是就可以了,对于一些客户端请求 API 的情况,我们就不使用 Session 来保持用户状态,改成用 Token 也是可以的。
无状态服务利用我们前面的 Deployment 可以很好的进行编排,对应有状态服务,需要考虑的细节就要多很多了,容器化应用程序最困难的任务之一,就是设计有状态分布式组件的部署体系结构。由于无状态组件没有预定义的启动顺序、集群要求、点对点 TCP 连接、唯一的网络标识符、正常的启动和终止要求等,因此可以很容易地进行容器化。
诸如数据库,大数据分析系统,分布式 key/value 存储、消息中间件需要有复杂的分布式体系结构,都可能会用到上述功能。为此,Kubernetes 引入了 StatefulSet 这种资源对象来支持这种复杂的需求。StatefulSet 类似于 ReplicaSet,但是它可以处理 Pod 的启动顺序,为保留每个 Pod 的状态设置唯一标识,具有以下几个功能特性:
- 稳定的、唯一的网络标识符
- 稳定的、持久化的存储
- 有序的、优雅的部署和缩放
- 有序的、优雅的删除和终止
- 有序的、自动滚动更新
Headless Service
Headless Service。Service 其实在之前我们和大家提到过,Service 是应用服务的抽象,通过 Labels 为应用提供负载均衡和服务发现,每个 Service 都会自动分配一个 cluster IP 和 DNS 名,在集群内部我们可以通过该地址或者通过 FDQN 的形式来访问服务。比如,一个 Deployment 有 3 个 Pod,那么我就可以定义一个 Service,有如下两种方式来访问这个 Service:
- cluster IP 的方式,比如:当我访问 10.109.169.155 这个 Service 的 IP 地址时,10.109.169.155 其实就是一个 VIP,它会把请求转发到该 Service 所代理的 Endpoints 列表中的某一个 Pod 上。具体原理我们会在后面的 Service 章节中和大家深入了解。
- Service 的 DNS 方式,比如我们访问“mysvc.mynamespace.svc.cluster.local”这条 DNS 记录,就可以访问到 mynamespace 这个命名空间下面名为 mysvc 的 Service 所代理的某一个 Pod。
对于 DNS 这种方式实际上也有两种情况:
- 第一种就是普通的 Service,我们访问
“mysvc.mynamespace.svc.cluster.local”的时候是通过集群中的 DNS 服务解析到的 mysvc 这个 Service 的 cluster IP 的 - 第二种情况就是
Headless Service,对于这种情况,我们访问“mysvc.mynamespace.svc.cluster.local”的时候是直接解析到的 mysvc 代理的某一个具体的 Pod 的 IP 地址,中间少了 cluster IP 的转发,这就是二者的最大区别,Headless Service 不需要分配一个 VIP,而是可以直接以 DNS 的记录方式解析到后面的 Pod 的 IP 地址。
比如我们定义一个如下的 Headless Service:(headless-svc.yaml)
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
ports:
- name: http
port: 80
clusterIP: None
selector:
app: nginx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
实际上 Headless Service 在定义上和普通的 Service 几乎一致, 只是他的 clusterIP=None ,所以,这个 Service 被创建后并不会被分配一个 cluster IP,而是会以 DNS 记录的方式暴露出它所代理的 Pod,而且还有一个非常重要的特性,对于 Headless Service 所代理的所有 Pod 的 IP 地址都会绑定一个如下所示的 DNS 记录:<pod-name>.<svc-name>.<namespace>.svc.cluster.local
这个 DNS 记录正是 Kubernetes 集群为 Pod 分配的一个唯一标识,只要我们知道 Pod 的名字,以及它对应的 Service 名字,就可以组装出这样一条 DNS 记录访问到 Pod 的 IP 地址,这个能力是非常重要的,接下来我们就来看下 StatefulSet 资源对象是如何结合 Headless Service 提供服务的。
StatefulSet
特性
apiVersion: v1 kind: PersistentVolume metadata: name: pv001 spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce hostPath: path: /tmp/pv001 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv002 spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce hostPath: path: /tmp/pv002
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
然后接下来声明一个如下所示的 StatefulSet 资源清单:(nginx-sts.yaml)
apiVersion: apps/v1 kind: StatefulSet metadata: name: web namespace: default spec: serviceName: "nginx" replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - name: web containerPort: 80 volumeMounts: - name: www mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: www spec: accessModes: [ "ReadWriteOnce" ] resources: requests: storage: 1Gi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
从上面的资源清单中可以看出和我们前面的 Deployment 基本上也是一致的,也是通过声明的 Pod 模板来创建 Pod 的,另外上面资源清单中和 volumeMounts 进行关联的不是 volumes 而是一个新的属性:volumeClaimTemplates,该属性会自动创建一个 PVC 对象,其实这里就是一个 PVC 的模板,和 Pod 模板类似,PVC 被创建后会自动去关联当前系统中和他合适的 PV 进行绑定。
除此之外,还多了一个 serviceName: "nginx" 的字段,serviceName 就是管理当前 StatefulSet 的服务名称,该服务必须在 StatefulSet 之前存在,并且负责该集合的网络标识,Pod 会遵循以下格式获取 DNS/主机名:pod-specific-string.serviceName.default.svc.cluster.local,其中 pod-specific-string 由 StatefulSet 控制器管理。
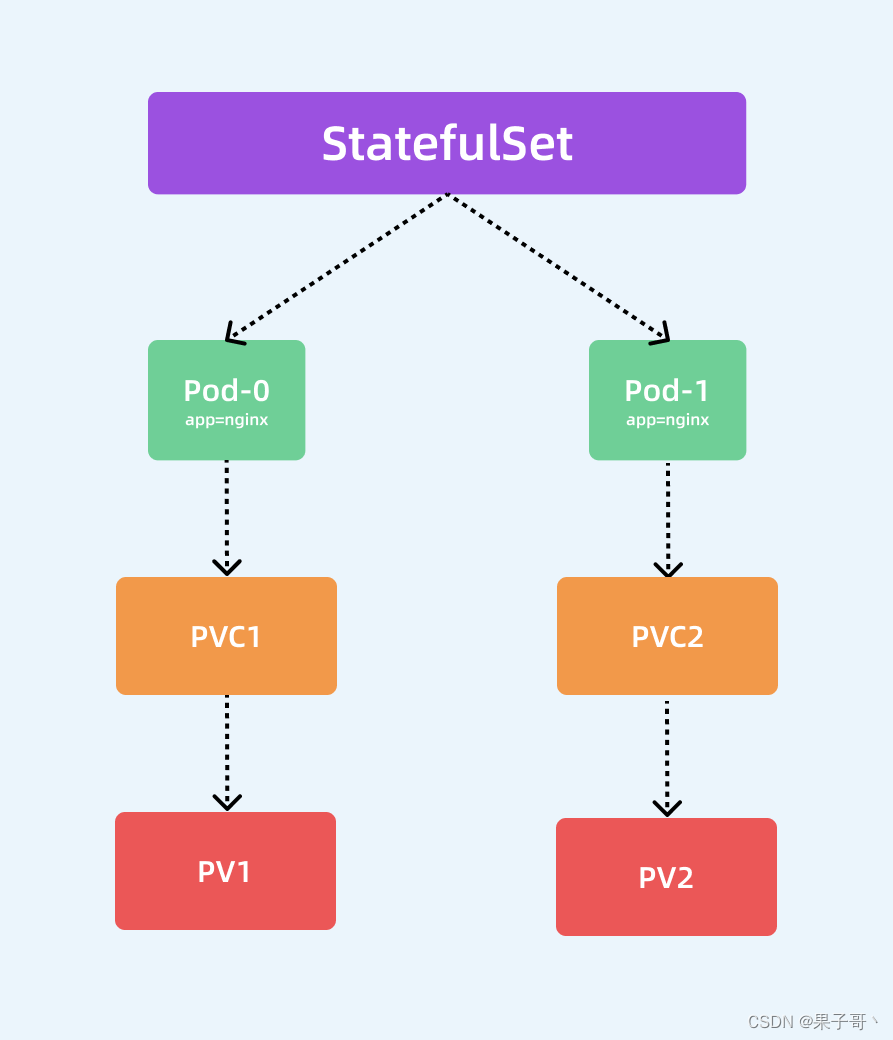
StatefulSet 的拓扑结构和其他用于部署的资源对象其实比较类似,比较大的区别在于 StatefulSet 引入了 PV 和 PVC 对象来持久存储服务产生的状态,这样所有的服务虽然可以被杀掉或者重启,但是其中的数据由于 PV 的原因不会丢失。
由于我们这里用volumeClaimTemplates声明的模板是挂载点的方式,并不是 volume,所有实际上上当于把 PV 的存储挂载到容器中,所以会覆盖掉容器中的数据,在容器启动完成后我们可以手动在 PV 的存储里面新建 index.html 文件来保证容器的正常访问,当然也可以进入到容器中去创建,这样更加方便:
$ for i in 0 1; do kubectl exec web-$i -- sh -c 'echo hello $(hostname) > /usr/share/nginx/html/index.html'; done
现在我们优先创建上面定义的 Headless Service:
➜ ~ kubectl apply -f headless-svc.yaml
service/nginx created
➜ ~ kubectl get service nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 9s
Headless Service 创建完成后就可以来创建对应的 StatefulSet 对象了:
➜ ~ kubectl apply -f nginx-sts.yaml
statefulset.apps/web created
➜ ~ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound pv001 1Gi RWO 10m
www-web-1 Bound pv002 1Gi RWO 6m26s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
可以看到这里通过 Volume 模板自动生成了两个 PVC 对象,也自动和 PV 进行了绑定。
StatefulSet 中的 Pod 拥有一个具有稳定的、独一无二的身份标志。这个标志基于 StatefulSet 控制器分配给每个 Pod 的唯一顺序索引。Pod 的名称的形式为<statefulset name>-<ordinal index>。我们这里的对象拥有两个副本,所以它创建了两个 Pod 名称分别为:web-0 和 web-1,我们可以使用 kubectl exec 命令进入到容器中查看它们的 hostname。
管理策略
对于某些分布式系统来说,StatefulSet 的顺序性保证是不必要和/或者不应该的,这些系统仅仅要求唯一性和身份标志。为了解决这个问题,我们只需要在声明 StatefulSet 的时候重新设置 spec.podManagementPolicy 的策略即可。
默认的管理策略是 OrderedReady,表示让 StatefulSet 控制器遵循上文演示的顺序性保证。除此之外,还可以设置为 Parallel 管理模式,表示让 StatefulSet 控制器并行的终止所有 Pod,在启动或终止另一个 Pod 前,不必等待这些 Pod 变成 Running 和 Ready 或者完全终止状态。
更新策略
前面课程中我们学习了 Deployment 的升级策略,在 StatefulSet 中同样也支持两种升级策略:onDelete 和 RollingUpdate,同样可以通过设置 .spec.updateStrategy.type 进行指定。
- OnDelete: 该策略表示当更新了 StatefulSet 的模板后,只有手动删除旧的 Pod 才会创建新的 Pod。
- RollingUpdate:该策略表示当更新 StatefulSet 模板后会自动删除旧的 Pod 并创建新的Pod,如果更新发生了错误,这次“滚动更新”就会停止。不过需要注意 StatefulSet 的 Pod 在部署时是顺序从
0~n的,而在滚动更新时,这些 Pod 则是按逆序的方式即n~0一次删除并创建。
另外SatefulSet 的滚动升级还支持 Partitions的特性,可以通过.spec.updateStrategy.rollingUpdate.partition 进行设置,在设置 partition 后,SatefulSet 的 Pod 中序号大于或等于 partition 的 Pod 会在 StatefulSet 的模板更新后进行滚动升级,而其余的 Pod 保持不变,这个功能是不是可以实现灰度发布?大家可以去手动验证下。
在实际的项目中,其实我们还是很少会去直接通过 StatefulSet 来部署我们的有状态服务的,除非你自己能够完全能够 hold 住,对于一些特定的服务,我们可能会使用更加高级的 Operator 来部署,比如 etcd-operator、prometheus-operator 等等,这些应用都能够很好的来管理有状态的服务,而不是单纯的使用一个 StatefulSet 来部署一个 Pod 就行,因为对于有状态的应用最重要的还是数据恢复、故障转移等等。
DaemonSet
通过该控制器的名称我们可以看出它的用法:Daemon,就是用来部署守护进程的,DaemonSet用于在每个 Kubernetes 节点中将守护进程的副本作为后台进程运行,说白了就是在每个节点部署一个 Pod副本,当节点加入到 Kubernetes 集群中,Pod 会被调度到该节点上运行,当节点从集群只能够被移除后,该节点上的这个 Pod 也会被移除,当然,如果我们删除 DaemonSet,所有和这个对象相关的 Pods都会被删除。那么在哪种情况下我们会需要用到这种业务场景呢?其实这种场景还是比较普通的,比如:
- 集群存储守护程序,如 glusterd、ceph 要部署在每个节点上以提供持久性存储;
- 节点监控守护进程,如 Prometheus 监控集群,可以在每个节点上运行一个 node-exporter 进程来收集监控节点的信息;
- 日志收集守护程序,如 fluentd 或 logstash,在每个节点上运行以收集容器的日志
- 节点网络插件,比如 flannel、calico,在每个节点上运行为 Pod 提供网络服务。
由 DaemonSet 控制器创建的 Pod 实际上提前已经确定了在哪个节点上了(Pod创建时指定了.spec.nodeName),所以:
DaemonSet并不关心一个节点的unshedulable字段,这个我们会在后面的调度章节和大家讲解的。DaemonSet可以创建 Pod,即使调度器还没有启动。
下面我们直接使用一个示例来演示下,在每个节点上部署一个 Nginx Pod:
# nginx-ds.yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: nginx-ds namespace: default spec: selector: matchLabels: k8s-app: nginx template: metadata: labels: k8s-app: nginx spec: containers: - image: nginx:1.7.9 name: nginx ports: - name: http containerPort: 80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
然后直接创建即可:
➜ ~ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 18d v1.22.2
node1 Ready <none> 18d v1.22.2
node2 Ready <none> 18d v1.22.2
➜ ~ kubectl get pods -l k8s-app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-ds-5b2m7 1/1 Running 0 15s 10.244.2.165 node2 <none> <none>
nginx-ds-jfr89 1/1 Running 0 15s 10.244.1.170 node1 <none> <none>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我们观察可以发现除了 master1 节点之外的2个节点上都有一个相应的 Pod 运行,因为 master1 节点上默认被打上了污点,所以默认情况下不能调度普通的 Pod 上去
基本上我们可以用下图来描述 DaemonSet 的拓扑图:
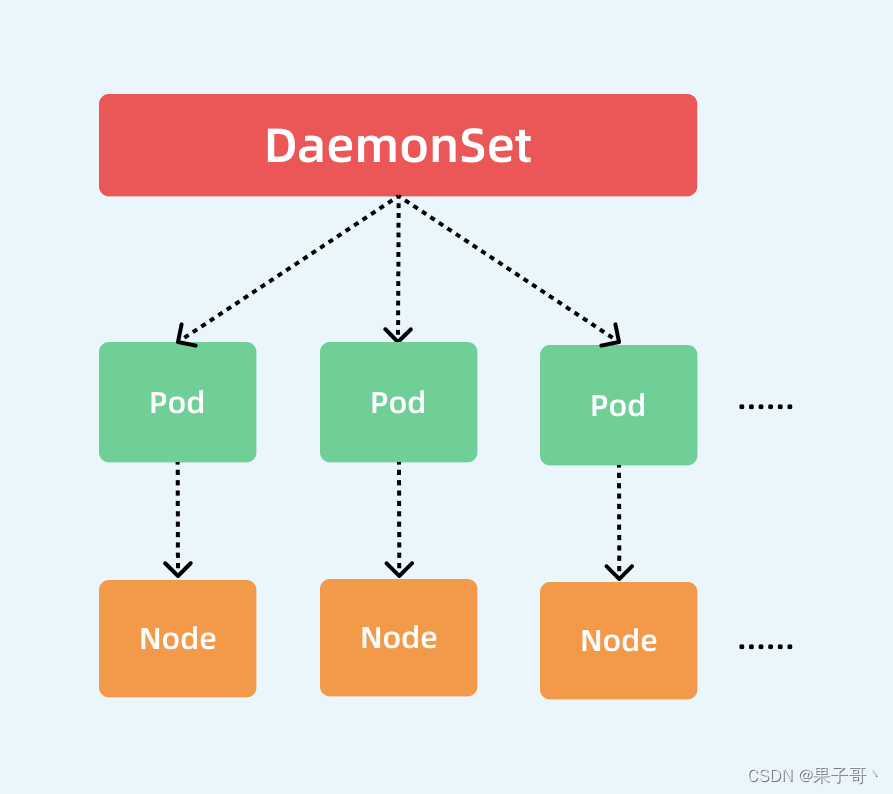
集群中的 Pod 和 Node 是一一对应d的,而 DaemonSet 会管理全部机器上的 Pod 副本,负责对它们进行更新和删除。
那么,DaemonSet 控制器是如何保证每个 Node 上有且只有一个被管理的 Pod 呢?
- 首先控制器从 Etcd 获取到所有的 Node 列表,然后遍历所有的 Node。
- 根据资源对象定义是否有调度相关的配置,然后分别检查 Node 是否符合要求。
- 在可运行 Pod 的节点上检查是否已有对应的 Pod,如果没有,则在这个 Node 上创建该 Pod;如果有,并且数量大于 1,那就把多余的 Pod 从这个节点上删除;如果有且只有一个 Pod,那就说明是正常情况。
当然该资源对象也有对应的更新策略,有 OnDelete 和 RollingUpdate 两种方式,默认是滚动更新。
Job与CronJob
Job 负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。而CronJob 则就是在 Job 上加上了时间调度。
Job
我们用 Job 这个资源对象来创建一个任务,我们定义一个 Job 来执行一个倒计时的任务,对应的资源清单如下所示:
# job-demo.yaml apiVersion: batch/v1 kind: Job metadata: name: job-demo spec: template: spec: restartPolicy: Never containers: - name: counter image: busybox command: - "bin/sh" - "-c" - "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
我们可以看到 Job 中也是一个 Pod 模板,和之前的 Deployment、StatefulSet 之类的是一致的,只是 Pod 中的容器要求是一个任务,而不是一个常驻前台的进程了,因为需要退出,另外值得注意的是 Job 的 RestartPolicy 仅支持 Never 和 OnFailure 两种,不支持 Always,我们知道 Job 就相当于来执行一个批处理任务,执行完就结束了,如果支持 Always 的话是不是就陷入了死循环了?
Job 对象创建成功后,我们可以查看下对象的详细描述信息:
➜ ~ kubectl describe job job-demo Name: job-demo Namespace: default Selector: controller-uid=10618fc6-5610-41c6-bdeb-531167716179 Labels: controller-uid=10618fc6-5610-41c6-bdeb-531167716179 job-name=job-demo Annotations: <none> Parallelism: 1 Completions: 1 Completion Mode: NonIndexed Start Time: Sat, 13 Nov 2021 18:34:17 +0800 Completed At: Sat, 13 Nov 2021 18:34:36 +0800 Duration: 19s Pods Statuses: 0 Running / 1 Succeeded / 0 Failed Pod Template: Labels: controller-uid=10618fc6-5610-41c6-bdeb-531167716179 job-name=job-demo Containers: counter: Image: busybox Port: <none> Host Port: <none> Command: bin/sh -c for i in 9 8 7 6 5 4 3 2 1; do echo $i; done Environment: <none> Mounts: <none> Volumes: <none> Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulCreate 73s job-controller Created pod: job-demo--1-p9s5r Normal Completed 54s job-controller Job completed
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
可以看到,Job 对象在创建后,它的 Pod 模板,被自动加上了一个 controller-uid=< 一个随机字符串 > 这样的 Label 标签,而这个 Job 对象本身,则被自动加上了这个 Label 对应的 Selector,从而 保证了 Job 与它所管理的 Pod 之间的匹配关系。而 Job 控制器之所以要使用这种携带了 UID 的 Label,就是为了避免不同 Job 对象所管理的 Pod 发生重合。
我们可以看到很快 Pod 变成了 Completed 状态,这是因为容器的任务执行完成正常退出了,我们可以查看对应的日志:
➜ ~ kubectl logs job-demo--1-p9s5r
9
8
7
6
5
4
3
2
1
➜ ~ kubectl get pod
NAME READY STATUS RESTARTS AGE
job-demo--1-p9s5r 0/1 Completed 0 11m
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上面我们这里的 Job 任务对应的 Pod 在运行结束后,会变成 Completed 状态,但是如果执行任务的 Pod 因为某种原因一直没有结束怎么办呢? 同样我们可以在 Job 对象中通过设置字段 spec.activeDeadlineSeconds 来限制任务运行的最长时间,比如:
spec:
activeDeadlineSeconds: 100
- 1
- 2
那么当我们的任务 Pod 运行超过了 100s 后,这个 Job 的所有 Pod 都会被终止,并且, Pod 的终止原因会变成 DeadlineExceeded。
如果的任务执行失败了,会怎么处理呢,这个和定义的 restartPolicy 有关系,比如定义如下所示的 Job 任务,定义 restartPolicy: Never 的重启策略:
# job-failed-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-failed-demo
spec:
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo123", "test failed job!"]
restartPolicy: Never
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
直接创建上面的资源对象:
➜ ~ kubectl apply -f job-failed-demo.yaml
job.batch/job-failed-demo created
➜ ~ kubectl get pod
NAME READY STATUS RESTARTS AGE
job-failed-demo--1-87wvj 0/1 StartError 0 4m40s
job-failed-demo--1-bl7jm 0/1 StartError 0 5m7s
job-failed-demo--1-dcmph 0/1 StartError 0 3m
job-failed-demo--1-hb24j 0/1 StartError 0 20s
job-failed-demo--1-n7h24 0/1 StartError 0 4m20s
job-failed-demo--1-q7vxq 0/1 StartError 0 5m24s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可以看到当我们设置成 Never 重启策略的时候,Job 任务执行失败后会不断创建新的 Pod,但是不会一直创建下去,会根据 spec.backoffLimit 参数进行限制,默认为6,通过该字段可以定义重建 Pod 的次数,另外需要注意的是 Job 控制器重新创建 Pod 的间隔是呈指数增加的,即下一次重新创建 Pod 的动作会分别发生在 10s、20s、40s… 后。
但是如果我们设置的 restartPolicy: OnFailure 重启策略,则当 Job 任务执行失败后不会创建新的 Pod 出来,只会不断重启 Pod。
除此之外,我们还可以通过设置 spec.parallelism 参数来进行并行控制,该参数定义了一个 Job 在任意时间最多可以有多少个 Pod 同时运行。spec.completions 参数可以定义 Job 至少要完成的 Pod 数目。如下所示创建一个新的 Job 任务,设置允许并行数为2,至少要完成的 Pod 数为8:
# job-para-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-para-test
spec:
parallelism: 2
completions: 8
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo", "test paralle job!"]
restartPolicy: Never
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
创建完成后查看任务状态:
➜ ~ kubectl get pod NAME READY STATUS RESTARTS AGE job-para-test--1-rwxm8 0/1 ContainerCreating 0 6s job-para-test--1-vgtxf 0/1 ContainerCreating 0 2s ➜ ~ kubectl get job NAME COMPLETIONS DURATION AGE job-para-test 0/8 29s 29s ➜ ~ kubectl get job NAME COMPLETIONS DURATION AGE job-para-test 8/8 111s 2m34s ➜ ~ kubectl get pod NAME READY STATUS RESTARTS AGE job-para-test--1-7nk2x 0/1 Completed 0 76s job-para-test--1-dcdvp 0/1 Completed 0 2m2s job-para-test--1-k9sgw 0/1 Completed 0 2m36s job-para-test--1-rwkkb 0/1 Completed 0 2m17s job-para-test--1-rwxm8 0/1 Completed 0 2m36s job-para-test--1-tqlzd 0/1 Completed 0 106s job-para-test--1-vgtxf 0/1 Completed 0 2m32s job-para-test--1-vxj6b 0/1 Completed 0 91s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
可以看到一次可以有2个 Pod 同时运行,需要8个 Pod 执行成功,如果不是8个成功,那么会根据 restartPolicy 的策略进行处理,可以认为是一种检查机制。
CronJob
一个 CronJob 对象其实就对应中 crontab 文件中的一行,它根据配置的时间格式周期性地运行一个 Job,格式和 crontab 也是一样的。
crontab 的格式为:分 时 日 月 星期 要运行的命令 。
第1列分钟 0~59
第2列小时 0~23
第3列日 1~31
第4列月 1~12
第5列星期 0~7(0和7表示星期天)
第6列要运行的命令
- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在,我们用 CronJob 来管理我们上面的 Job 任务,定义如下所示的资源清单:
# cronjob-demo.yaml apiVersion: batch/v1 kind: CronJob metadata: name: cronjob-demo spec: schedule: "*/1 * * * *" jobTemplate: spec: template: spec: restartPolicy: OnFailure containers: - name: hello image: busybox args: - "bin/sh" - "-c" - "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这里的 Kind 变成了 CronJob 了,要注意的是 .spec.schedule 字段是必须填写的,用来指定任务运行的周期,格式就和 crontab 一样,另外一个字段是 .spec.jobTemplate, 用来指定需要运行的任务,格式当然和 Job 是一致的。还有一些值得我们关注的字段 .spec.successfulJobsHistoryLimit(默认为3) 和 .spec.failedJobsHistoryLimit(默认为1),表示历史限制,是可选的字段,指定可以保留多少完成和失败的 Job。然而,当运行一个 CronJob 时,Job 可以很快就堆积很多,所以一般推荐设置这两个字段的值,如果设置限制的值为 0,那么相关类型的 Job 完成后将不会被保留。
这个就是 CronJob 的基本用法,一旦不再需要 CronJob,我们可以使用 kubectl 命令删除它:
kubectl get cronjob
➜ ~ kubectl delete cronjob cronjob-demo
cronjob "cronjob-demo" deleted
- 1
- 2
- 3
不过需要注意的是这将会终止正在创建的 Job,但是运行中的 Job 将不会被终止,不会删除 Job 或 它们的 Pod。
思考:那如果我们想要在每个节点上去执行一个 Job 或者 Cronjob 又该怎么来实现呢?
HPA
kubectl scale 命令可以来实现 Pod 的扩缩容功能,但是这个是完全手动操作的,要应对线上的各种复杂情况,我们需要能够做到自动化去感知业务,来自动进行扩缩容 。为此,Kubernetes 也为我们提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称 HPA,HPA 通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量,这是 HPA 最基本的原理:
Metrics Server
在 HPA 的第一个版本中,我们需要 Heapster 提供 CPU 和内存指标,在 HPA v2 过后就需要安装 Metrcis Server 了,Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,有了 Metrics Server 之后,我们就完全可以通过标准的 Kubernetes API 来访问我们想要获取的监控数据了:
https://10.96.0.1/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
- 1
比如当我们访问上面的 API 的时候,我们就可以获取到该 Pod 的资源数据,这些数据其实是来自于 kubelet 的 Summary API 采集而来的 。不过需要说明的是我们这里可以通过标准的 API 来获取资源监控数据,并不是因为 Metrics Server 就是 APIServer 的一部分,而是通过 Kubernetes 提供的 Aggregator 汇聚插件来实现的,是独立于 APIServer 之外运行的。

聚合API
Aggregator 允许开发人员编写一个自己的服务,把这个服务注册到 Kubernetes 的 APIServer 里面去,这样我们就可以像原生的 APIServer 提供的 API 使用自己的 API 了,我们把自己的服务运行在 Kubernetes 集群里面,然后 Kubernetes 的 Aggregator 通过 Service 名称就可以转发到我们自己写的 Service 里面去了。这样这个聚合层就带来了很多好处:
- 增加了 API 的扩展性,开发人员可以编写自己的 API 服务来暴露他们想要的 API。
- 丰富了 API,核心 kubernetes 团队阻止了很多新的 API 提案,通过允许开发人员将他们的 API 作为单独的服务公开,这样就无须社区繁杂的审查了。
- 开发分阶段实验性 API,新的 API 可以在单独的聚合服务中开发,当它稳定之后,在合并会 APIServer 就很容易了。
- 确保新 API 遵循 Kubernetes 约定,如果没有这里提出的机制,社区成员可能会被迫推出自己的东西,这样很可能造成社区成员和社区约定不一致。
安装
所以现在我们要使用 HPA,就需要在集群中安装 Metrics Server 服务,要安装 Metrics Server 就需要开启 Aggregator ,因为 Metrics Server 就是通过该代理进行扩展的,不过我们集群是通过 Kubeadm 搭建的,默认已经开启了,如果是二进制方式安装的集群,需要单独配置 kube-apsierver 添加如下所示的参数:
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果 kube-proxy 没有和 APIServer 运行在同一台主机上,那么需要确保启用了如下 kube-apsierver 的参数:
--enable-aggregator-routing=true
对于这些证书的生成方式,我们可以查看官方文档:https://github.com/kubernetes-sigs/apiserver-builder-alpha/blob/master/docs/concepts/auth.md。
Aggregator 聚合层启动完成后,就可以来安装 Metrics Server 了,我们可以获取该仓库的官方安装资源清单:
# 官方仓库地址:https://github.com/kubernetes-sigs/metrics-server
➜ ~ wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.5.1/components.yaml
- 1
- 2
在部署之前,修改 components.yaml 的镜像地址为:
hostNetwork: true # 使用hostNetwork模式
containers:
- name: metrics-server
image: cnych/metrics-server:v0.5.1
- 1
- 2
- 3
- 4
等部署完成后,可以查看 Pod 日志是否正常:
➜ ~ kubectl apply -f components.yaml ➜ ~ kubectl get pods -n kube-system -l k8s-app=metrics-server NAME READY STATUS RESTARTS AGE metrics-server-6f667d74b6-6c9ps 0/1 Running 0 7m52s ➜ ~ manifests kubectl logs -f metrics-server-6f667d74b6-6c9ps -n kube-system I1115 10:06:02.381541 1 serving.go:341] Generated self-signed cert (/tmp/apiserver.crt, /tmp/apiserver.key) E1115 10:06:02.735837 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.31.31:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.31.31 because it doesn't contain any IP SANs" node="master1" E1115 10:06:02.744967 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.31.108:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.31.108 because it doesn't contain any IP SANs" node="node1" I1115 10:06:02.751391 1 requestheader_controller.go:169] Starting RequestHeaderAuthRequestController I1115 10:06:02.751410 1 shared_informer.go:240] Waiting for caches to sync for RequestHeaderAuthRequestController I1115 10:06:02.751413 1 configmap_cafile_content.go:202] Starting client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file I1115 10:06:02.751397 1 configmap_cafile_content.go:202] Starting client-ca::kube-system::extension-apiserver-authentication::client-ca-file I1115 10:06:02.751423 1 shared_informer.go:240] Waiting for caches to sync for client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file I1115 10:06:02.751424 1 shared_informer.go:240] Waiting for caches to sync for client-ca::kube-system::extension-apiserver-authentication::client-ca-file I1115 10:06:02.751473 1 dynamic_serving_content.go:130] Starting serving-cert::/tmp/apiserver.crt::/tmp/apiserver.key I1115 10:06:02.751822 1 secure_serving.go:202] Serving securely on [::]:443 I1115 10:06:02.751896 1 tlsconfig.go:240] Starting DynamicServingCertificateController E1115 10:06:02.756987 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.31.46:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.31.46 because it doesn't contain any IP SANs" node="node2" I1115 10:06:02.851642 1 shared_informer.go:247] Caches are synced for client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file I1115 10:06:02.851739 1 shared_informer.go:247] Caches are synced for RequestHeaderAuthRequestController I1115 10:06:02.851748 1 shared_informer.go:247] Caches are synced for client-ca::kube-system::extension-apiserver-authentication::client-ca-file E1115 10:06:17.742350 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.31.108:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.31.108 because it doesn't contain any IP SANs" node="node1" ......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
因为部署集群的时候,CA 证书并没有把各个节点的 IP 签上去,所以这里 Metrics Server 通过 IP 去请求时,提示签的证书没有对应的 IP(错误:x509: cannot validate certificate for 192.168.31.108 because it doesn’t contain any IP SANs),我们可以添加一个–kubelet-insecure-tls参数跳过证书校验:
args:
- --cert-dir=/tmp
- --secure-port=443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
- 1
- 2
- 3
- 4
- 5
然后再重新安装即可成功!可以通过如下命令来验证:
➜ ~ kubectl apply -f components.yaml ➜ ~ kubectl get pods -n kube-system -l k8s-app=metrics-server NAME READY STATUS RESTARTS AGE metrics-server-85499dc4f5-mgpcb 1/1 Running 0 32s ➜ ~ kubectl logs -f metrics-server-85499dc4f5-mgpcb -n kube-system I1115 10:14:19.401808 1 serving.go:341] Generated self-signed cert (/tmp/apiserver.crt, /tmp/apiserver.key) I1115 10:14:19.840290 1 secure_serving.go:202] Serving securely on [::]:443 I1115 10:14:19.840395 1 requestheader_controller.go:169] Starting RequestHeaderAuthRequestController I1115 10:14:19.840403 1 shared_informer.go:240] Waiting for caches to sync for RequestHeaderAuthRequestController I1115 10:14:19.840411 1 dynamic_serving_content.go:130] Starting serving-cert::/tmp/apiserver.crt::/tmp/apiserver.key I1115 10:14:19.840438 1 tlsconfig.go:240] Starting DynamicServingCertificateController ...... ➜ ~ kubectl get apiservice | grep metrics v1beta1.metrics.k8s.io kube-system/metrics-server True 10m ➜ ~ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" {"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{},"items":[{"metadata":{"name":"master1","creationTimestamp":"2021-11-15T10:15:38Z","labels":{"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"master1","kubernetes.io/os":"linux","node-role.kubernetes.io/control-plane":"","node-role.kubernetes.io/master":"","node.kubernetes.io/exclude-from-external-load-balancers":""}},"timestamp":"2021-11-15T10:15:33Z","window":"20s","usage":{"cpu":"132348072n","memory":"813200Ki"}},{"metadata":{"name":"node1","creationTimestamp":"2021-11-15T10:15:38Z","labels":{"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"node1","kubernetes.io/os":"linux"}},"timestamp":"2021-11-15T10:15:32Z","window":"20s","usage":{"cpu":"60153492n","memory":"520628Ki"}},{"metadata":{"name":"node2","creationTimestamp":"2021-11-15T10:15:38Z","labels":{"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"node2","kubernetes.io/os":"linux"}},"timestamp":"2021-11-15T10:15:29Z","window":"20s","usage":{"cpu":"81697469n","memory":"557208Ki"}}]} ➜ ~ kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% master1 115m 5% 794Mi 21% node1 58m 1% 505Mi 6% node2 55m 1% 545Mi 7%
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
现在我们可以通过 kubectl top 命令来获取到资源数据了,证明 Metrics Server 已经安装成功了。
HPA
现在我们用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容。资源清单如下所示:
# hpa-demo.yaml apiVersion: apps/v1 kind: Deployment metadata: name: hpa-demo spec: selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
然后直接创建 Deployment,注意一定先把之前创建的具有 app=nginx 的 Pod 先清除掉:
➜ ~ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-demo-7848d4b86f-khndb 1/1 Running 0 56s
- 1
- 2
- 3
现在我们来创建一个 HPA 资源对象,可以使用kubectl autoscale命令来创建:
➜ ~ kubectl autoscale deployment hpa-demo --cpu-percent=10 --min=1 --max=10
horizontalpodautoscaler.autoscaling/hpa-demo autoscaled
➜ ~ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo <unknown>/10% 1 10 0 6s
- 1
- 2
- 3
- 4
- 5
此命令创建了一个关联资源 hpa-demo 的 HPA,最小的 Pod 副本数为1,最大为10。HPA 会根据设定的 cpu 使用率(10%)动态的增加或者减少 Pod 数量。
➜ ~ kubectl get hpa hpa-demo -o yaml apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: annotations: autoscaling.alpha.kubernetes.io/conditions: '[{"type":"AbleToScale","status":"True","lastTransitionTime":"2021-11-15T10:19:06Z","reason":"SucceededGetScale","message":"the HPA controller was able to get the target''s current scale"},{"type":"ScalingActive","status":"False","lastTransitionTime":"2021-11-15T10:19:06Z","reason":"FailedGetResourceMetric","message":"the HPA was unable to compute the replica count: failed to get cpu utilization: missing request for cpu"}]' creationTimestamp: "2021-11-15T10:18:51Z" managedFields: - apiVersion: autoscaling/v1 fieldsType: FieldsV1 fieldsV1: f:spec: f:maxReplicas: {} f:minReplicas: {} f:scaleTargetRef: {} f:targetCPUUtilizationPercentage: {} manager: kubectl operation: Update time: "2021-11-15T10:18:51Z" - apiVersion: autoscaling/v1 fieldsType: FieldsV1 fieldsV1: f:metadata: f:annotations: .: {} f:autoscaling.alpha.kubernetes.io/conditions: {} f:status: f:currentReplicas: {} manager: kube-controller-manager operation: Update subresource: status time: "2021-11-15T10:19:06Z" name: hpa-demo namespace: default resourceVersion: "631809" uid: 34b91709-d003-4039-9cf0-05bb3fa4da73 spec: maxReplicas: 10 minReplicas: 1 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: hpa-demo targetCPUUtilizationPercentage: 10 status: currentReplicas: 1 desiredReplicas: 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
然后我们可以根据上面的 YAML 文件就可以自己来创建一个基于 YAML 的 HPA 描述文件了。但是我们发现上面信息里面出现了一些 Fail 信息,我们来查看下这个 HPA 对象的信息:
➜ ~ kubectl describe hpa hpa-demo Name: hpa-demo Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Mon, 15 Nov 2021 18:18:51 +0800 Reference: Deployment/hpa-demo Metrics: ( current / target ) resource cpu on pods (as a percentage of request): <unknown> / 10% Min replicas: 1 Max replicas: 10 Deployment pods: 1 current / 0 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True SucceededGetScale the HPA controller was able to get the target's current scale ScalingActive False FailedGetResourceMetric the HPA was unable to compute the replica count: failed to get cpu utilization: missing request for cpu Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedGetResourceMetric 1s (x3 over 31s) horizontal-pod-autoscaler failed to get cpu utilization: missing request for cpu Warning FailedComputeMetricsReplicas 1s (x3 over 31s) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: missing request for cpu
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
我们可以看到上面的事件信息里面出现了 failed to get cpu utilization: missing request for cpu 这样的错误信息。这是因为我们上面创建的 Pod 对象没有添加 request 资源声明,这样导致 HPA 读取不到 CPU 指标信息,所以 如果要想让 HPA 生效,对应的 Pod 资源必须添加 requests 资源声明 ,更新我们的资源清单文件:
apiVersion: apps/v1 kind: Deployment metadata: name: hpa-demo spec: selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80 resources: requests: memory: 50Mi cpu: 50m
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
然后重新更新 Deployment,重新创建 HPA 对象:
➜ ~ kubectl apply -f hpa-demo.yaml deployment.apps/hpa-demo configured ➜ ~ kubectl get pods -o wide -l app=nginx NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES hpa-demo-6b4467b546-h489x 1/1 Running 0 18s 10.244.1.11 node1 <none> <none> ➜ ~ kubectl delete hpa hpa-demo horizontalpodautoscaler.autoscaling "hpa-demo" deleted ➜ ~ kubectl autoscale deployment hpa-demo --cpu-percent=10 --min=1 --max=10 horizontalpodautoscaler.autoscaling/hpa-demo autoscaled ➜ ~ kubectl describe hpa hpa-demo Name: hpa-demo Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Mon, 15 Nov 2021 18:21:12 +0800 Reference: Deployment/hpa-demo Metrics: ( current / target ) resource cpu on pods (as a percentage of request): 0% (0) / 10% Min replicas: 1 Max replicas: 10 Deployment pods: 1 current / 1 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request) ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: <none> ➜ ~ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 35s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
现在可以看到 HPA 资源对象已经正常了,现在我们来增大负载进行测试,我们来创建一个 busybox 的 Pod,并且循环访问上面创建的 Pod:
➜ ~ kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://10.244.1.11; done
- 1
- 2
- 3
然后观察 Pod 列表,可以看到,HPA 已经开始工作:
➜ ~ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 310%/10% 1 10 1 105s
➜ ~ kubectl get pods -l app=nginx --watch
NAME READY STATUS RESTARTS AGE
hpa-demo-6b4467b546-h489x 1/1 Running 0 2m25s
hpa-demo-6b4467b546-pg4fz 0/1 ContainerCreating 0 9s
hpa-demo-6b4467b546-qrwv5 0/1 ContainerCreating 0 9s
hpa-demo-6b4467b546-s4vdz 0/1 ContainerCreating 0 9s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我们可以看到已经自动拉起了很多新的 Pod,最后会定格在了我们上面设置的 10 个 Pod,同时查看资源 hpa-demo 的副本数量,副本数量已经从原来的1变成了10个:
➜ ~ kubectl get deployment hpa-demo
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-demo 10/10 10 10 2m56s
- 1
- 2
- 3
查看 HPA 资源的对象了解工作过程:
➜ ~ kubectl describe hpa hpa-demo Name: hpa-demo Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Mon, 15 Nov 2021 18:21:12 +0800 Reference: Deployment/hpa-demo Metrics: ( current / target ) resource cpu on pods (as a percentage of request): 110% (55m) / 10% Min replicas: 1 Max replicas: 10 Deployment pods: 10 current / 10 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request) ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 67s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 52s horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 37s horizontal-pod-autoscaler New size: 10; reason: cpu resource utilization (percentage of request) above target
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
同样的这个时候我们来关掉 busybox 来减少负载,然后等待一段时间观察下 HPA 和 Deployment 对象:
➜ ~ k8strain3 kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 0%/10% 1 10 10 3m46s
➜ ~ kubectl get deployment hpa-demo
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-demo 1/1 1 1 24m
- 1
- 2
- 3
- 4
- 5
- 6
缩放间隙
从 Kubernetes v1.12 版本开始我们可以通过设置 kube-controller-manager 组件的–horizontal-pod-autoscaler-downscale-stabilization 参数来设置一个持续时间,用于指定在当前操作完成后,HPA 必须等待多长时间才能执行另一次缩放操作。默认为5分钟,也就是默认需要等待5分钟后才会开始自动缩放。
可以看到副本数量已经由 10 变为 1,当前我们只是演示了 CPU 使用率这一个指标,在后面的课程中我们还会学习到根据自定义的监控指标来自动对 Pod 进行扩缩容。
内存
要使用基于内存或者自定义指标进行扩缩容(现在的版本都必须依赖 metrics-server 这个项目)。现在我们再用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容。资源清单如下所示:
# hpa-mem-demo.yaml apiVersion: apps/v1 kind: Deployment metadata: name: hpa-mem-demo spec: selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: volumes: - name: increase-mem-script configMap: name: increase-mem-config containers: - name: nginx image: nginx ports: - containerPort: 80 volumeMounts: - name: increase-mem-script mountPath: /etc/script resources: requests: memory: 50Mi cpu: 50m securityContext: privileged: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这里和前面普通的应用有一些区别,我们将一个名为 increase-mem-config 的 ConfigMap 资源对象挂载到了容器中,该配置文件是用于后面增加容器内存占用的脚本,配置文件如下所示:
# increase-mem-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: increase-mem-config
data:
increase-mem.sh: |
#!/bin/bash
mkdir /tmp/memory
mount -t tmpfs -o size=40M tmpfs /tmp/memory
dd if=/dev/zero of=/tmp/memory/block
sleep 60
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
由于这里增加内存的脚本需要使用到 mount 命令,这需要声明为特权模式,所以我们添加了 securityContext.privileged=true 这个配置。现在我们直接创建上面的资源对象即可:
➜ ~ kubectl apply -f increase-mem-cm.yaml
➜ ~ kubectl apply -f hpa-mem-demo.yaml
➜ ~ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-74675cc6c9-sqz2l 1/1 Running 0 17s
- 1
- 2
- 3
- 4
- 5
然后需要创建一个基于内存的 HPA 资源对象:
# hpa-mem.yaml apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: hpa-mem-demo namespace: default spec: maxReplicas: 5 minReplicas: 1 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: hpa-mem-demo metrics: # 指定内存的一个配置 - type: Resource resource: name: memory targetAverageUtilization: 30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
要注意这里使用的 apiVersion 是 autoscaling/v2beta1,然后 metrics 属性里面指定的是内存的配置,直接创建上面的资源对象即可:
➜ ~ kubectl apply -f hpa-mem.yaml
horizontalpodautoscaler.autoscaling/hpa-mem-demo created
➜ ~ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-mem-demo Deployment/hpa-mem-demo 6%/30% 1 5 1 32s
- 1
- 2
- 3
- 4
- 5
到这里证明 HPA 资源对象已经部署成功了,接下来我们对应用进行压测,将内存压上去,直接执行上面我们挂载到容器中的 increase-mem.sh 脚本即可:
➜ ~ kubectl exec -it hpa-mem-demo-74675cc6c9-sqz2l -- /bin/bash
root@hpa-mem-demo-74675cc6c9-sqz2l:/# ls /etc/script/
increase-mem.sh
root@hpa-mem-demo-74675cc6c9-sqz2l:/# source /etc/script/increase-mem.sh
dd: writing to '/tmp/memory/block': No space left on device
81921+0 records in
81920+0 records out
41943040 bytes (42 MB, 40 MiB) copied, 0.0908717 s, 462 MB/s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
然后打开另外一个终端观察 HPA 资源对象的变化情况:
➜ ~ kubectl get hpa -w NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-mem-demo Deployment/hpa-mem-demo 87%/30% 1 5 3 90s ➜ ~ kubectl describe hpa hpa-mem-demo Name: hpa-mem-demo Namespace: default Labels: <none> Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"autoscaling/v2beta1","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"name":"hpa-mem-demo","namespace":"defau... CreationTimestamp: Mon, 15 Nov 2021 18:40:37 +0800 Reference: Deployment/hpa-mem-demo Metrics: ( current / target ) resource memory on pods (as a percentage of request): 87% (45752320) / 30% Min replicas: 1 Max replicas: 5 Deployment pods: 3 current / 3 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from memory resource utilization (percentage of request) ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedGetResourceMetric 87s horizontal-pod-autoscaler failed to get memory utilization: unable to get metrics for resource memory: no metrics returned from resource metrics API Warning FailedComputeMetricsReplicas 87s horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get memory utilization: unable to get metrics for resource memory: no metrics returned from resource metrics API Normal SuccessfulRescale 27s horizontal-pod-autoscaler New size: 3; reason: memory resource utilization (percentage of request) above target Normal SuccessfulRescale 46s horizontal-pod-autoscaler New size: 4; reason: memory resource utilization (percentage of request) above target ➜ ~ kubectl top pod hpa-mem-demo-74675cc6c9-gbj9t NAME CPU(cores) MEMORY(bytes) hpa-mem-demo-66944b79bf-tqrn9 0m 41Mi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
可以看到内存使用已经超过了我们设定的 30% 这个阈值了,HPA 资源对象也已经触发了自动扩容,变成了4个副本了:
➜ ~ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-74675cc6c9-cpdw4 1/1 Running 0 69s
hpa-mem-demo-74675cc6c9-s8bz4 1/1 Running 0 114s
hpa-mem-demo-74675cc6c9-sqz2l 1/1 Running 0 3m9s
hpa-mem-demo-74675cc6c9-z8cx8 1/1 Running 0 114s
- 1
- 2
- 3
- 4
- 5
- 6
当内存释放掉后,controller-manager 默认5分钟过后会进行缩放,到这里就完成了基于内存的 HPA 操作。
Admission准入控制器
Kubernetes 提供了需要扩展其内置功能的方法,最常用的可能是自定义资源类型和自定义控制器了,除此之外,Kubernetes 还有一些其他非常有趣的功能,比如 admission webhooks 就可以用于扩展 API,用于修改某些 Kubernetes 资源的基本行为。
准入控制器是在对象持久化之前用于对 Kubernetes API Server 的请求进行拦截的代码段,在请求经过身份验证和授权之后放行通过。准入控制器可能正在 validating、mutating 或者都在执行,Mutating 控制器可以修改他们处理的资源对象,Validating 控制器不会,如果任何一个阶段中的任何控制器拒绝了请求,则会立即拒绝整个请求,并将错误返回给最终的用户。
这意味着有一些特殊的控制器可以拦截 Kubernetes API 请求,并根据自定义的逻辑修改或者拒绝它们。Kubernetes 有自己实现的一个控制器列表:https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#what-does-each-admission-controller-do,当然你也可以编写自己的控制器,虽然这些控制器听起来功能比较强大,但是这些控制器需要被编译进 kube-apiserver,并且只能在 apiserver 启动时启动。
也可以直接使用 kube-apiserver 启动参数查看内置支持的控制器:
kube-apiserver --help |grep enable-admission-plugins
- 1
由于上面的控制器的限制,我们就需要用到动态的概念了,而不是和 apiserver 耦合在一起,Admission webhooks 就通过一种动态配置方法解决了这个限制问题。
admission webhook 是什么?
在 Kubernetes apiserver 中包含两个特殊的准入控制器:MutatingAdmissionWebhook 和ValidatingAdmissionWebhook,这两个控制器将发送准入请求到外部的 HTTP 回调服务并接收一个准入响应。如果启用了这两个准入控制器,Kubernetes 管理员可以在集群中创建和配置一个 admission webhook。
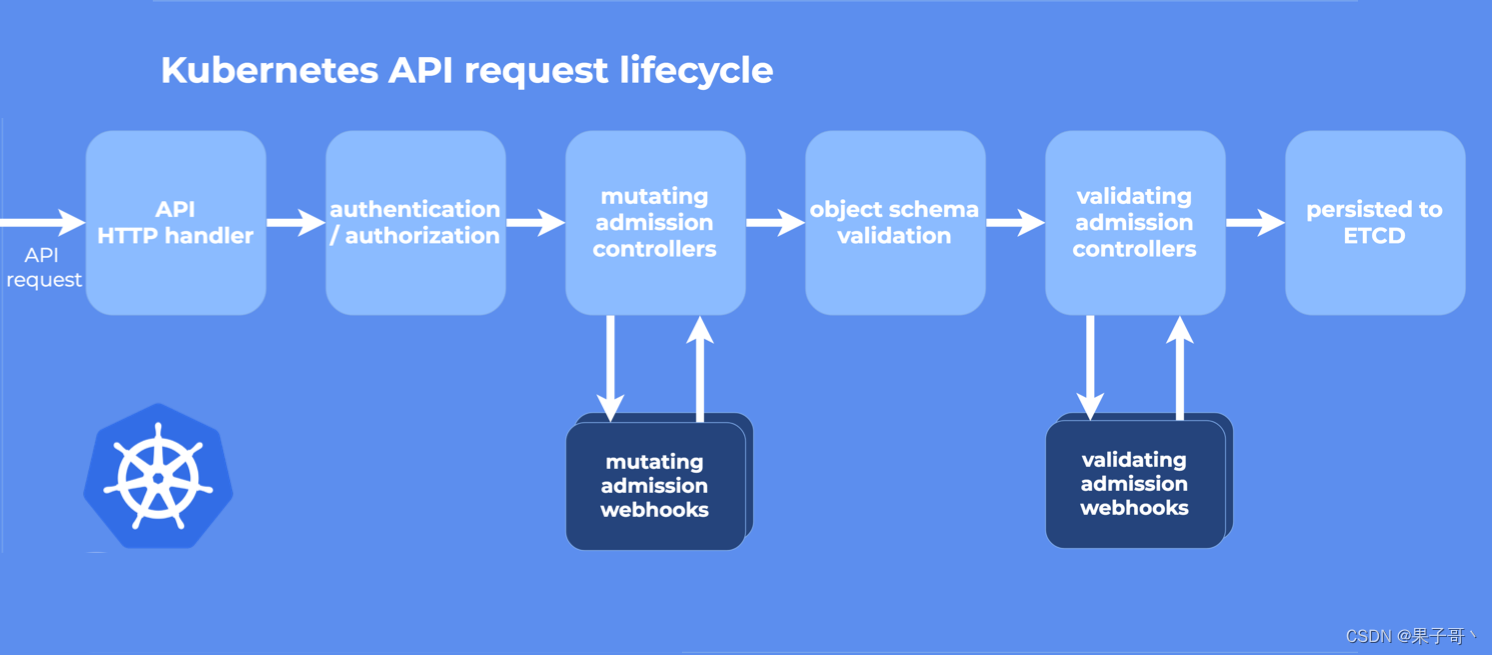
整体的步骤如下所示:
- 检查集群中是否启用了 admission webhook 控制器,并根据需要进行配置。
- 编写处理准入请求的 HTTP 回调,回调可以是一个部署在集群中的简单 HTTP 服务,甚至也可以是一个 serverless 函数。
- 通过 MutatingWebhookConfiguration 和 ValidatingWebhookConfiguration 资源配置 admission webhook。
这两种类型的 admission webhook 之间的区别是非常明显的:validating webhooks 可以拒绝请求,但是它们却不能修改准入请求中获取的对象,而 mutating webhooks 可以在返回准入响应之前通过创建补丁来修改对象,如果 webhook 拒绝了一个请求,则会向最终用户返回错误。
现在非常火热的 Service Mesh 应用 istio 就是通过 mutating webhooks 来自动将 Envoy 这个 sidecar 容器注入到 Pod 中去的:https://istio.io/docs/setup/kubernetes/sidecar-injection/。
创建配置一个 Admission Webhook
上面我们介绍了 Admission Webhook 的理论知识,接下来我们在一个真实的 Kubernetes 集群中来实际测试使用下,我们将创建一个 webhook 的 webserver,将其部署到集群中,然后创建 webhook 配置查看是否生效。
首先确保在 apiserver 中启用了 MutatingAdmissionWebhook 和 ValidatingAdmissionWebhook 这两个控制器,通过参数 --enable-admission-plugins 进行配置,当前 v1.22 版本已经内置默认开启了,如果没有开启则需要添加上这两个参数,然后重启 apiserver。
然后通过运行下面的命令检查集群中是否启用了准入注册 API:
➜ ~ kubectl api-versions |grep admission
admissionregistration.k8s.io/v1
- 1
- 2
编写webhook
满足了前面的先决条件后,接下来我们就来实现一个 webhook 示例,通过监听两个不同的 HTTP 端点(validate 和 mutate)来进行 validating 和 mutating webhook 验证。
这个 webhook 的完整代码可以在 Github 上获取:https://github.com/cnych/admission-webhook-example,该仓库 Fork 自项目 https://github.com/banzaicloud/admission-webhook-example。这个 webhook 是一个简单的带 TLS 认证的 HTTP 服务,用 Deployment 方式部署在我们的集群中。
代码中主要的逻辑在两个文件中:
- main.go 和 webhook.go
- main.go 文件包含创建 HTTP 服务的代码,
- webhook.go 包含 validates 和 mutates 两个 webhook 的逻辑,大部分代码都比较简单,首先查看 main.go 文件,查看如何使用标准 golang 包来启动 HTTP 服务,以及如何从命令行标志中读取 TLS 配置的证书:
flag.StringVar(¶meters.certFile, "tlsCertFile", "/etc/webhook/certs/cert.pem", "File containing the x509 Certificate for HTTPS.") flag.StringVar(¶meters.keyFile, "tlsKeyFile", "/etc/webhook/certs/key.pem", "File containing the x509 private key to --tlsCertFile.")- 1
- 2
然后一个比较重要的是 serve 函数,用来处理传入的 mutate 和 validating 函数 的 HTTP 请求。该函数从请求中反序列化 AdmissionReview 对象,执行一些基本的内容校验,根据 URL 路径调用相应的 mutate 和 validate 函数,然后序列化 AdmissionReview 对象:
func (whsvr *WebhookServer) serve(w http.ResponseWriter, r *http.Request) { var body []byte if r.Body != nil { if data, err := ioutil.ReadAll(r.Body); err == nil { body = data } } if len(body) == 0 { glog.Error("empty body") http.Error(w, "empty body", http.StatusBadRequest) return } // 校验 Content-Type contentType := r.Header.Get("Content-Type") if contentType != "application/json" { glog.Errorf("Content-Type=%s, expect application/json", contentType) http.Error(w, "invalid Content-Type, expect `application/json`", http.StatusUnsupportedMediaType) return } var admissionResponse *v1beta1.AdmissionResponse ar := v1beta1.AdmissionReview{} if _, _, err := deserializer.Decode(body, nil, &ar); err != nil { glog.Errorf("Can't decode body: %v", err) admissionResponse = &v1beta1.AdmissionResponse{ Result: &metav1.Status{ Message: err.Error(), }, } } else { if r.URL.Path == "/mutate" { admissionResponse = whsvr.mutate(&ar) } else if r.URL.Path == "/validate" { admissionResponse = whsvr.validate(&ar) } } admissionReview := v1beta1.AdmissionReview{} if admissionResponse != nil { admissionReview.Response = admissionResponse if ar.Request != nil { admissionReview.Response.UID = ar.Request.UID } } resp, err := json.Marshal(admissionReview) if err != nil { glog.Errorf("Can't encode response: %v", err) http.Error(w, fmt.Sprintf("could not encode response: %v", err), http.StatusInternalServerError) } glog.Infof("Ready to write reponse ...") if _, err := w.Write(resp); err != nil { glog.Errorf("Can't write response: %v", err) http.Error(w, fmt.Sprintf("could not write response: %v", err), http.StatusInternalServerError) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
主要的准入逻辑是 validate 和 mutate 两个函数。validate 函数检查资源对象是否需要校验:不验证 kube-system 和 kube-public 两个命名空间中的资源,如果想要显示的声明不验证某个资源,可以通过在资源对象中添加一个 admission-webhook-example.qikqiak.com/validate=false 的 annotation 进行声明。如果需要验证,则根据资源类型的 kind,和标签与其对应项进行比较,将 service 或者 deployment 资源从请求中反序列化出来。如果缺少某些 label 标签,则响应中的 Allowed 会被设置为 false。如果验证失败,则会在响应中写入失败原因,最终用户在尝试创建资源时会收到失败的信息。
https://www.qikqiak.com/k3s/controller/admission/
Crd
Custom Resource Define 简称 CRD,是 Kubernetes(v1.7+)为提高可扩展性,让开发者去自定义资源的一种方式。CRD 资源可以动态注册到集群中,注册完毕后,用户可以通过 kubectl 来创建访问这个自定义的资源对象,类似于操作 Pod 一样。不过需要注意的是 CRD 仅仅是资源的定义而已,需要一个 Controller 去监听 CRD 的各种事件来添加自定义的业务逻辑。
https://www.qikqiak.com/k3s/controller/crd/
Operator 就可以看成是 CRD 和 Controller 的一种组合特例,Operator 是一种思想,它结合了特定领域知识并通过 CRD 机制扩展了 Kubernetes API 资源,使用户管理 Kubernetes 的内置资源(Pod、Deployment等)一样创建、配置和管理应用程序,Operator 是一个特定的应用程序的控制器,通过扩展 Kubernetes API 资源以代表 Kubernetes 用户创建、配置和管理复杂应用程序的实例,通常包含资源模型定义和控制器,通过 Operator 通常是为了实现某种特定软件(通常是有状态服务)的自动化运维。
我们完全可以通过上面的方式编写一个 CRD 对象,然后去手动实现一个对应的 Controller 就可以实现一个 Operator,但是我们也发现从头开始去构建一个 CRD 控制器并不容易,需要对 Kubernetes 的 API 有深入了解,并且 RBAC 集成、镜像构建、持续集成和部署等都需要很大工作量。为了解决这个问题,社区就推出了对应的简单易用的 Operator 框架,比较主流的是 kubebuilder 和 Operator Framework,这两个框架的使用基本上差别不大,我们可以根据自己习惯选择一个即可。
OpenKruise¶
OpenKruise 是一个基于 Kubernetes 的扩展套件,主要聚焦于云原生应用的自动化,比如部署、发布、运维以及可用性防护。OpenKruise 提供的绝大部分能力都是基于 CRD 扩展来定义的,它们不存在于任何外部依赖,可以运行在任意纯净的 Kubernetes 集群中。Kubernetes 自身提供的一些应用部署管理功能,对于大规模应用与集群的场景这些功能是远远不够的,OpenKruise 弥补了 Kubernetes 在应用部署、升级、防护、运维等领域的不足。
OpenKruise 提供了以下的一些核心能力:
- 增强版本的 Workloads:OpenKruise 包含了一系列增强版本的工作负载,比如 CloneSet、Advanced StatefulSet、Advanced DaemonSet、BroadcastJob 等。它们不仅支持类似于 Kubernetes 原生 Workloads 的基础功能,还提供了如原地升级、可配置的扩缩容/发布策略、并发操作等。其中,原地升级是一种升级应用容器镜像甚至环境变量的全新方式,它只会用新的镜像重建 Pod 中的特定容器,整个 Pod 以及其中的其他容器都不会被影响。因此它带来了更快的发布速度,以及避免了对其他 Scheduler、CNI、CSI 等组件的负面影响。
- 应用的旁路管理:OpenKruise 提供了多种通过旁路管理应用 sidecar 容器、多区域部署的方式,“旁路” 意味着你可以不需要修改应用的 Workloads 来实现它们。比如,SidecarSet 能帮助你在所有匹配的 Pod 创建的时候都注入特定的 sidecar 容器,甚至可以原地升级已经注入的 sidecar 容器镜像、并且对 Pod 中其他容器不造成影响。而 WorkloadSpread 可以约束无状态 Workload 扩容出来 Pod 的区域分布,赋予单一 workload 的多区域和弹性部署的能力。
- 高可用性防护:OpenKruise 可以保护你的 Kubernetes 资源不受级联删除机制的干扰,包括 CRD、Namespace、以及几乎全部的 Workloads 类型资源。相比于 Kubernetes 原生的 PDB 只提供针对 Pod Eviction 的防护,PodUnavailableBudget 能够防护 Pod Deletion、Eviction、Update 等许多种 voluntary disruption 场景。
- 高级的应用运维能力:OpenKruise 也提供了很多高级的运维能力来帮助你更好地管理应用,比如可以通过 ImagePullJob 来在任意范围的节点上预先拉取某些镜像,或者指定某个 Pod 中的一个或多个容器被原地重启。
https://www.qikqiak.com/k3s/controller/openkruise/

