
- 1git——git 更新远程分支到本地 && git 切换分支_git 怎么将远程分支更新替换本地分支
- 2基于Token的身份验证的原理_token验证流程原理
- 3解决Git Clone失败,浏览器可以访问github项目,但是git clone失败_github无法clone代码
- 4MySQL C API的使用
- 5Hive介绍与环境搭建
- 6python eel 多线程_利用Eel使JavaScript调用Python程序
- 7十分钟学会WebSocket_websocket会有跨域吗
- 82018中国计算机所有相关会议,2018年计算机视觉顶会和人工智能顶级会议时间表...
- 9FPGA有符号数相关运算
- 10spark端口
Spark2.0机器学习系列之4:随机森林介绍、关键参数分析_spark机器学习算法 参数限制
赞
踩
概述
随机森林是决策树的组合算法,基础是决策树,关于决策树和Spark2.0中的代码设计可以参考本人另外一篇博客:
http://blog.csdn.net/qq_34531825/article/details/52330942
随机森林Spark中基于Pipeline和DataFrame的代码编写和决策树基本上是一样的,只需要将classifer换一下可以了,其它部分是一模一样的,因此本文不再对代码进行注释分析。
随机森林模型可以快速地被应用到几乎任何的数据科学问题中去,从而使人们能够高效快捷地获得第一组基准测试结果。在各种各样的问题中,随机森林一次又一次地展示出令人难以置信的强大,而与此同时它又是如此的方便实用。
随机森林是决策树模型的组合,是解决分类和回归问题最为成功的机器学习算法之一。组合多个决策树的目的是为了降低overfitting的风险。
随机森林同时也具备了决策树的诸多优点:
- 可以处理类别特征;
- 可以扩张到多分类问题;
- 不需要对特征进行标准化(归一化)处理;
- 能够检测到feature间的互相影响。
另外随机森林能够处理很高维度(feature很多)的数据,并且不用做特征选择,在训练完后,它能够给出哪些features比较重要
Random forests are ensembles of decision trees. Random forests are one of the most successful machine learning models for classification and regression. They combine many decision trees in order to reduce the risk of overfitting. Like decision trees, random forests handle categorical features, extend to the multiclass classification setting, do not require feature scaling, and are able to capture non-linearities and feature interactions.
随机森林算法
(1)算法:因为随机森林算法是对多个决策树分开独立训练的,所以很容易设计成并行算法。
(2)随机森林是每一颗决策树预测结果的组合,因此随机森林算法产生的预测结果降低了预测的方差,提高了在测试数据上的表现。
Random forests train a set of decision trees separately, so the training can be done in parallel. The algorithm injects randomness Combining the predictions from each tree reduces the variance of the predictions, improving the performance on test data.
(3)随机森林训练过程中的随机性,包括两个方面,数据的随机性选取,以及待选特征的随机选取。
除了上述的这些随机性,对每一棵决策树的训练是完全相同的方法。
Training The randomness injected into the training process includes:
Subsampling the original dataset on each iteration to get a different training set (a.k.a. bootstrapping).
Considering different random subsets of features to split on at each tree node.
Apart from these randomizations, decision tree training is done in the same way as for individual decision trees.
(4)数据取样:假设我们设定训练集中的样本个数为N,然后通过有重置的重复多次抽样来获得这N个样本,这样的抽样结果将作为我们生成决策树的训练集;
(5)待选特征随机选取:如果有M个输入变量,每个节点都将随机选择m(m小于M)个特定的变量,然后运用这m个变量来确定最佳的分裂点。在决策树的生成过程中,m的值是保持不变的;
(6)预测:通过对所有的决策树进行加总来预测新的数据(在分类时采用多数投票,在回归时采用平均)。
算法缺点:
http://www.cnblogs.com/emanlee/p/4851555.html一文中说到了随机森林算法的优缺点,分析的很详细。他列举的缺点是:
(1)随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
(2)对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。
Spark2.0中完整的随机森林代码:
关键参数
最重要的,常常需要调试以提高算法效果的有两个参数:numTrees,maxDepth。
- numTrees(决策树的个数):增加决策树的个数会降低预测结果的方差,这样在测试时会有更高的accuracy。训练时间大致与numTrees呈线性增长关系。
- maxDepth:是指森林中每一棵决策树最大可能depth,在决策树中提到了这个参数。更深的一棵树意味模型预测更有力,但同时训练时间更长,也更倾向于过拟合。但是值得注意的是,随机森林算法和单一决策树算法对这个参数的要求是不一样的。随机森林由于是多个的决策树预测结果的投票或平均而降低而预测结果的方差,因此相对于单一决策树而言,不容易出现过拟合的情况。所以随机森林可以选择比决策树模型中更大的maxDepth。
甚至有的文献说,随机森林的每棵决策树都最大可能地进行生长而不进行剪枝。但是不管怎样,还是建议对maxDepth参数进行一定的实验,看看是否可以提高预测的效果。
另外还有两个参数,subsamplingRate,featureSubsetStrategy一般不需要调试,但是这两个参数也可以重新设置以加快训练,但是值得注意的是可能会影响模型的预测效果(如果需要调试的仔细读下面英文吧)。
We include a few guidelines for using random forests by discussing the various parameters. We omit some decision tree parameters since those are covered in the decision tree guide.
The first two parameters we mention are the most important, and tuning them can often improve performance:
(1)numTrees: Number of trees in the forest.
Increasing the number of trees will decrease the variance in predictions, improving the model’s test-time accuracy.
Training time increases roughly linearly in the number of trees.
(2)maxDepth: Maximum depth of each tree in the forest.
Increasing the depth makes the model more expressive and powerful. However, deep trees take longer to train and are also more prone to overfitting.
In general, it is acceptable to train deeper trees when using random forests than when using a single decision tree. One tree is more likely to overfit than a random forest (because of the variance reduction from averaging multiple trees in the forest).
The next two parameters generally do not require tuning. However, they can be tuned to speed up training.
(3)subsamplingRate: This parameter specifies the size of the dataset used for training each tree in the forest, as a fraction of the size of the original dataset. The default (1.0) is recommended, but decreasing this fraction can speed up training.
(4)featureSubsetStrategy: Number of features to use as candidates for splitting at each tree node. The number is specified as a fraction or function of the total number of features. Decreasing this number will speed up training, but can sometimes impact performance if too low.
We include a few guidelines for using random forests by discussing the various parameters. We omit some decision tree parameters since those are covered in the decision tree guide.
完整代码
package my.spark.ml.practice.classification;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.ml.Pipeline;
import org.apache.spark.ml.PipelineModel;
import org.apache.spark.ml.PipelineStage;
import org.apache.spark.ml.classification.RandomForestClassificationModel;
import org.apache.spark.ml.classification.RandomForestClassifier;
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator;
import org.apache.spark.ml.feature.IndexToString;
import org.apache.spark.ml.feature.StringIndexer;
import org.apache.spark.ml.feature.StringIndexerModel;
import org.apache.spark.ml.feature.VectorIndexer;
import org.apache.spark.ml.feature.VectorIndexerModel;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class myRandomForest {
public static void main(String[] args) {
SparkSession spark=SparkSession
.builder()
.appName("CoFilter")
.master("local[4]")
.config("spark.sql.warehouse.dir",
"file///:G:/Projects/Java/Spark/spark-warehouse" )
.getOrCreate();
String path="C:/Users/user/Desktop/ml_dataset/classify/horseColicTraining2libsvm.txt";
String path2="C:/Users/user/Desktop/ml_dataset/classify/horseColicTest2libsvm.txt";
//屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN);
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF);
Dataset<Row> training=spark.read().format("libsvm").load(path);
Dataset<Row> test=spark.read().format("libsvm").load(path2);
//采用的数据集是《机器学习实战》一书中所用到一个比较难分数据集:
//从疝气病症预测马的死亡率,加载前用Python将格式转换为
//libsvm格式(比较简单的一种Spark SQL DataFrame输入格式)
//这种格式导入的数据,label和features自动分好了,不需要再做任何抓换了。
StringIndexerModel indexerModel=new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
.fit(training);
VectorIndexerModel vectorIndexerModel=new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.fit(training);
IndexToString converter=new IndexToString()
.setInputCol("prediction")
.setOutputCol("convertedPrediction")
.setLabels(indexerModel.labels());
//设计了一个简单的循环,对关键参数(决策树的个数)进行分析调试
for (int numOfTrees = 10; numOfTrees < 500; numOfTrees+=50) {
RandomForestClassifier rfclassifer=new RandomForestClassifier()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures")
.setNumTrees(numOfTrees);
PipelineModel pipeline=new Pipeline().setStages
(new PipelineStage[]
{indexerModel,vectorIndexerModel,rfclassifer,converter})
.fit(training);
Dataset<Row> predictDataFrame=pipeline.transform(test);
double accuracy=new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy").evaluate(predictDataFrame);
System.out.println("numOfTrees "+numOfTrees+" accuracy "+accuracy);
//RandomForestClassificationModel rfmodel=
//(RandomForestClassificationModel) pipeline.stages()[2];
//System.out.println(rfmodel.toDebugString());
}//numOfTree Cycle
}
}
/**
对两个关键参数maxDepth(1-4)和NumTrees(100-1000)组合进行分析:
maxDepth 1 numOfTrees 100 accuracy 0.761
...
maxDepth 1 numOfTrees 500 accuracy 0.791
maxDepth 1 numOfTrees 600 accuracy 0.820
maxDepth 1 numOfTrees 700 accuracy 0.791
...
maxDepth 2 numOfTrees 100 accuracy 0.776
maxDepth 2 numOfTrees 200 accuracy 0.820//最高
maxDepth 2 numOfTrees 300 accuracy 0.805
...
maxDepth 2 numOfTrees 1000 accuracy 0.805
maxDepth 3 numOfTrees 100 accuracy 0.791
...
maxDepth 3 numOfTrees 600 accuracy 0.805
maxDepth 3 numOfTrees 700 accuracy 0.791
maxDepth 3 numOfTrees 800 accuracy 0.820//最高
maxDepth 3 numOfTrees 900 accuracy 0.791
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
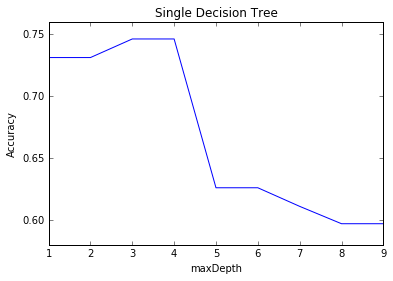
与一棵决策树比较
在这个数据集上,单一决策树预测最高0.746,随机森林在这个难数据集上效果还是很明显的
(预测accuracy可以稳定在80%左右,最高达到82%)。
python格式转换代码:转换为libsvm格式
fr=open("C:\\Users\\user\\Desktop\\ml_dataset\\classify\\horseColicTest2.txt");
fr2=open("C:\\Users\\user\\Desktop\\ml_dataset\\classify\\horseColicTest2libsvm.txt",'w+');
for line in fr.readlines():
line= line.strip().split("\t")
features=line[:-1]
label=(line[-1])
fr2.write(label+" ")
for k in range(len(features)):
fr2.write(str(k+1))
fr2.write(":")
fr2.write(features[k]+" ")
fr2.write("\n")
fr.close()
fr2.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
参考:
(1)Spark2.0 文档
(2)http://www.cnblogs.com/emanlee/p/4851555.html

