
变压器 5g
With the burgeoning of Transfer Learning, Deep Learning has achieved many wonders. More specifically, in NLP, with the rise of the Transformer (Vaswani et. al.), various approaches for ‘Language Modeling’ have arisen wherein we leverage transfer learning by pre-training the model for a very generic task and then fine-tuning it on specific downstream problems.
随着迁移学习的蓬勃发展,深度学习已实现了许多奇迹。 更具体地说,在NLP中,随着Transformer的兴起( Vaswani等人 ),出现了各种“语言建模”方法,其中我们通过对模型进行预训练以完成非常通用的任务,然后进行微调来利用转移学习它针对特定的下游问题。
In this article, we’ll discuss Google’s state of the art, T5 — Text-to-Text Transfer Transformer Model which was proposed earlier this year in the paper, “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”. This paper is essentially a survey of modern transfer learning techniques used in language understanding and hence proposes a unified framework that attempts to combine all language problems into a text-to-text format. We will discuss this approach in greater detail in the coming sections. Moreover, the authors have also open-sourced a new dataset (for facilitating their work) called C4 — Colossal Clean Crawled Corpus.
在这篇文章中,我们将讨论艺术,T5的谷歌的状态- T的外部- 牛逼邻T外部贸易交接牛逼 ransformer模型,它在今年早些时候提出的文件,“ 探索迁移学习的限制与统一文本-to-Text Transformer ”。 本文本质上是对用于语言理解的现代迁移学习技术的调查,因此提出了一个统一的框架,该框架试图将所有语言问题组合为文本到文本格式。 我们将在接下来的部分中详细讨论这种方法。 此外,作者还开源了一个新的数据集(为了方便他们的工作),称为C4 - C大型C贫C精炼CAppium。
T5—文本到文本传输变压器 (T5— Text-To-Text Transfer Transformer)
As mentioned earlier, T5 attempts to combine all the downstream tasks into a text-to-text format.
如前所述,T5尝试将所有下游任务组合为文本到文本格式。
文本到文本框架 (The Text-to-Text Framework)

Consider the example of a BERT-style architecture that is pre-trained on a Masked LM and Next Sentence Prediction objective and then, fine-tuned on downstream tasks (for example predicting a class label in classification or the span of the input in QnA). Here, we separately fine-tune different instances of the pre-trained model on different downstream tasks.
考虑一个BERT样式的架构示例,该架构在Masked LM和Next Sentence Prediction目标上进行了预训练,然后在下游任务上进行了微调(例如,预测类别中的类标签或QnA中输入的范围) 。 在这里,我们分别针对不同的下游任务微调了预训练模型的不同实例。
The text-to-text framework on the contrary, suggests using the same model, same loss function, and the same hyperparameters on all the NLP tasks. In this approach, the inputs are modeled in such a way that the model shall recognize a task, and the output is simply the “text” version of the expected outcome. Refer to the above animation to get a clearer view of this.
相反,文本到文本框架建议在所有NLP任务上使用相同的模型,相同的损失函数和相同的超参数。 在这种方法中,对输入进行建模的方式是模型可以识别任务,而输出只是预期结果的“文本”版本。 请参考上面的动画以获得更清晰的视图。
Fun fact: We can even apply T5 to regression tasks by training it to output the string representation of the expected output.
有趣的事实:通过训练T5输出期望输出的字符串表示形式,我们甚至可以将T5应用于回归任务。
C4—巨大的干净爬行的语料库 (C4— Colossal Clean Crawled Corpus)
It is a stereotype to pre-train language models on huge unlabeled datasets. Common Crawl is one of such datasets. It is obtained by scraping web pages and ignoring the markup from the HTML. It produces around 20TB of scraped data each month. However, Common Crawl contains large amounts of gibberish text like menus or error messages, or duplicate text. Moreover, there is also an appreciable amount of useless text with respect to our tasks like offensive words, placeholder text, or source codes.
这是在大量未标记数据集上预训练语言模型的刻板印象。 Common Crawl是此类数据集之一。 它是通过抓取网页并忽略HTML中的标记而获得的。 每个月会产生约20TB的抓取数据。 但是,“常见爬网”包含大量乱码,如菜单或错误消息,或重复的文本。 此外,对于我们的任务,还有相当数量的无用文字,例如令人反感的文字,占位符文字或源代码。
For C4, the authors took Common Crawl scrape from April 2019 and applied some cleansing filters on it:
对于C4,作者从2019年4月开始抓取Common Crawl刮擦并在其上应用了一些清理过滤器:
- Retaining sentences that end only with a valid terminal punctuation mark (a period, exclamation mark, question mark, or end quotation mark). 保留仅以有效的终端标点符号(句点,感叹号,问号或结束引号)结尾的句子。
Removing any page containing offensive words that appear on the “List of Dirty, Naughty, Obscene or Otherwise Bad Words”.
删除出现在“ 脏话,顽皮话,淫秽话或其他不良话语清单 ”上的任何含有冒犯性话语的页面。
- “JavaScript must be enabled” type warnings are removed by filtering out any line that contains the word JavaScript. 通过过滤掉包含JavaScript单词的任何行,可以删除“必须启用JavaScript”类型的警告。
- Pages with placeholder text like “lorem ipsum” are removed. 带有占位符文本(如“ lorem ipsum”)的页面将被删除。
- Source codes are removed by removing any pages that contain a curly brace “{” (since curly braces appear in many well-known programming languages). 通过删除任何包含花括号“ {”的页面来删除源代码(因为花括号在许多众所周知的编程语言中都显示)。
- For removing duplicates, three-sentence spans are considered. Any duplicate occurrences of the same 3 sentences are filtered out. 为了删除重复项,请考虑三句跨度。 同一3个句子的任何重复出现都将被过滤掉。
Finally, since the downstream tasks are mostly for English language, langdetect is used to filter out any pages that are not classified as English with a probability of at least 0.99.
最后,由于下游任务主要用于英语, 因此使用langdetect过滤掉任何未归类为英语的页面的可能性至少为0.99。
This resulted in a 750GB dataset which is not just reasonably larger than the most pre-training datasets but also contains a relatively very clean text.
这产生了750GB的数据集,它不仅比大多数预训练数据集合理地大,而且还包含相对非常干净的文本。
输入和输出表示 (Input and Output Representations)
This is one of the major concerns of T5 as this is what makes the unified text-to-text approach possible. To avail the same model for all the downstream tasks, a task-specific text prefix is added to the original input that is fed to the model. This text prefix is also considered as a hyperparameter.
这是T5的主要问题之一,因为这使统一的文本到文本方法成为可能。 为了对所有下游任务使用相同的模型,将特定于任务的文本前缀添加到提供给模型的原始输入中。 此文本前缀也被视为超参数。
As an example,to ask the model to translate the sentence “That is good.” from English to German, the model would be fed the sequence “translate English to German: That is good.” and would be trained to output “Das ist gut.”
例如,要求模型翻译句子“那很好”。 从英语到德语,将向模型提供以下顺序:“ 将英语翻译为德语:很好。 ”,并将经过训练以输出“ 达斯主义者的直觉”。 ”
— T5 Paper
— T5纸
Similarly, for classification tasks, the model predicts a single word corresponding to the target label.
类似地,对于分类任务,模型预测与目标标签相对应的单个单词。
For example, on the MNLI benchmark the goal is to predict whether a premise implies (“entailment”), contradicts (“contradiction”), or neither (“neutral”) a hypothesis. With our preprocessing, the input sequence becomes “mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity.” with the corresponding target word “entailment”.
例如,在MNLI基准的目标是预测的前提是否意味着(“ 蕴涵 ”)相矛盾(“ 矛盾 ”),或者两者都不是(“ 中性 ”)的假设。 通过我们的预处理,输入序列变成了“ mnli前提:我讨厌鸽子”。 假设:我对鸽子的感觉充满敌意。 ”和相应的目标词“ 蕴含 ”。
— T5 Paper
— T5纸
Here’s an issue with this. What if the predicted word is something else i.e. not “entailment”, “contradiction” or “neutral”. Well, in that case, the model is trained to consider all the other words as wrong.
这是一个问题。 如果预测的单词不是“蕴含”,“矛盾”或“中立”,该怎么办? 好吧,在那种情况下,训练模型可以将所有其他单词视为错误。
该模型 (The Model)
The proposed model is essentially a Encoder-Decoder Transformer (Vaswani et. al.) with some architectural changes (like applying Layer Normalization before a sub block and then adding the initial input to the sub-block output; also known as pre-norm). Moreover, the model configuration is similar to BERT base (Devlin et. al.).
提出的模型本质上是一个编码器-解码器变压器( Vaswani et al。 ),具有一些架构上的变化(例如在子块之前应用Layer Normalization,然后将初始输入添加到子块输出;也称为pre-norm)。 。 此外,模型配置类似于BERT基( Devlin等人 )。
We’ll skip these architectures as they’re out of scope for this article. If you’re interested in knowing the specifications of these models in particular, I have already covered them in the following articles:
我们将跳过这些架构,因为它们不在本文讨论范围之内。 如果您有兴趣特别了解这些模型的规格,那么我将在以下文章中介绍它们:
Transformers: https://towardsdatascience.com/transformers-explained-65454c0f3fa7
变形金刚: https : //towardsdatascience.com/transformers-explained-65454c0f3fa7
Transformers Implementation: https://medium.com/swlh/abstractive-text-summarization-using-transformers-3e774cc42453
变压器实现: https : //medium.com/swlh/abstractive-text-summarization-using-transformers-3e774cc42453
BERT: https://medium.com/swlh/bert-pre-training-of-transformers-for-language-understanding-5214fba4a9af
BERT: https : //medium.com/swlh/bert-pre-training-of-transformers-for-language-understanding-5214fba4a9af
培训方式 (Training Approach)

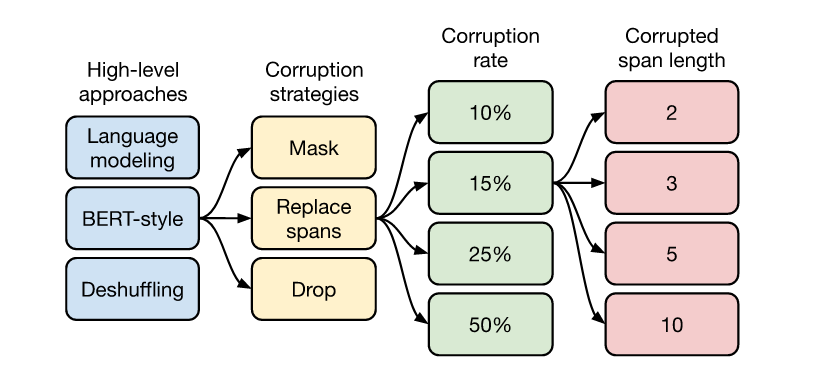
At an architectural level, there are several options in selecting the training approach:The paper is an exhaustive survey on many modern approaches for language understanding. Hence, many architectural specifications have been explored and compared.
在体系结构级别上,选择培训方法有多种选择:本文是对许多现代语言理解方法的详尽调查。 因此,已经探索和比较了许多架构规范。
Encoder-Decoder (Left): This is the standard encoder-decoder, seq2seq architecture wherein the encoder is trained in a BERT-style, fully visible manner (i.e. every token contributes to the attention calculation of every other token in the sequence), and the decoder is trained in a GPT-style causal manner (i.e. every token is attended by all the tokens that occur before it in the sequence).
编码器-解码器(左):这是标准的编码器-解码器seq2seq架构,其中以BERT样式, 完全可见的方式训练编码器(即,每个令牌都有助于序列中每个其他令牌的注意力计算),以及解码器以GPT样式的因果方式进行训练(即,每个令牌都由序列中在其之前出现的所有令牌所伴随)。
Language Model (Middle): This is essentially the causal attention mechanism that was discussed earlier. It is an autoregressive modeling approach.
语言模型(中):本质上是前面讨论的因果注意机制。 这是一种自回归建模方法。
Prefix LM (Right): This is a combination of the BERT-style and language model approaches. For example, the task of translating from English to German can have a BERT-style attention on: “translate English to German: That is good. target:”. And then the translation “Das ist gut.” will be attended autoregressively.
前缀LM(右):这是BERT样式和语言模型方法的组合。 例如,将英语翻译成德语的任务可以引起BERT风格的关注:“将英语翻译成德语:很好。 目标:”。 然后翻译为“ Das ist gut”。 将自发参加。
With experimentation, the best results were obtained with the Encoder-Decoder approach.
通过实验,使用“编码器-解码器”方法可获得最佳结果。
无监督目标 (Unsupervised Objective)

With respect to the pre-training objective too, the authors have explored some of the approaches in practice:
关于培训前的目标,作者还探索了实践中的一些方法:
Language Modeling: This approach mainly includes the causal prediction task i.e. predicting the next word in the sentence considering all the words preceding that word.
语言建模:此方法主要包括因果预测任务,即考虑该词之前的所有词来预测句子中的下一个词。
Deshuffling: All the words in a sentence are shuffled and the model is trained to predict the original text.
去混洗:将句子中的所有单词混洗,并训练模型以预测原始文本。
Corrupting Spans: Masking a sequence of words from the sentence and training the model to predict these masked words as shown in the figure above. It is also known as a denoising objective.
损坏的跨度:屏蔽句子中的一系列单词,并训练模型以预测这些屏蔽的单词,如上图所示。 它也被称为降噪目标。
After exploration, the denoising objective had the most promising results.
经过探索,降噪目标得到了最有希望的结果。
结果 (Results)
First things first, T5 has achieved the state of the art in many GLUE, SuperGLUE tasks along with translation and summarization benchmarks.
首先,T5在许多GLUE,SuperGLUE任务以及翻译和摘要基准中都达到了最先进的水平。
T5 is surprisingly good at this task. The full 11-billion parameter model produces the exact text of the answer 50.1%, 37.4%, and 34.5% of the time on TriviaQA, WebQuestions, and Natural Questions, respectively.
T5出奇地擅长此任务。 完整的110亿参数模型分别在TriviaQA , WebQuestions和Natural Questions上分别产生答案的准确文本,分别为50.1%,37.4%和34.5%。
To generate realistic text, T5 relies on a fill-in-the-blanks type task with which it is familiar due to the pre-training. So, the authors have created a new downstream task called sized fill-in-the-blank. For example, given the sentence, “I like to eat peanut butter and _4_ sandwiches,”, the model will be trained to predict approximately 4 words for the blank.
为了生成逼真的文本,T5依赖于由于预先训练而熟悉的填空任务。 因此,作者创建了一个新的下游任务,称为“ 大小填充空白” 。 例如,给定句子“ 我喜欢吃花生酱和_4_三明治 ”,该模型将被训练为空白预测大约4个单词。
Fun fact: The model also adjusts its predictions based on the requested size of the missing text.
有趣的事实:该模型还会根据请求的缺失文本大小来调整其预测。
For the demonstration of the above, refer to the official blog.
有关上述说明,请参阅官方博客 。
放在一起 (Putting it All Together)
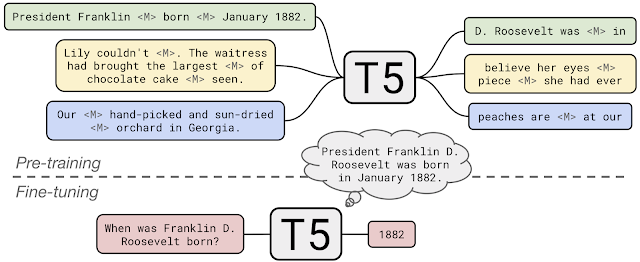
- T5 is first pre-trained on the C4 dataset for the denoising, corrupting span objective with an Encoder-Decoder architecture. T5首先在C4数据集上经过预编码,以使用Encoder-Decoder体系结构进行降噪,破坏跨度目标。
- It is then fine tuned on the downstream tasks with a supervised objective with appropriate input modeling for the text-to-text setting. 然后在带有监督目标的下游任务上进行微调,并为文本到文本设置设置适当的输入模型。
结论 (Conclusion)
In this article, we dived deep into Google’s T5 model which is one of the state of the art models in language understanding. We saw the new dataset: C4. The main takeaway from this article would be the empirical results obtained by the T5 authors regarding the training approaches, model architectures and the datasets. Moreover, it can be also observed that DL is approaching more and more towards achieving human quality understanding— in this context, generalizing to just one model for many NLP tasks.
在本文中,我们深入研究了Google的T5模型,该模型是语言理解方面的最新模型之一。 我们看到了新的数据集:C4。 本文的主要内容是T5作者在训练方法,模型架构和数据集方面的经验结果。 此外,还可以观察到,DL正在越来越多地实现对人类素质的理解-在这种情况下,DL仅适用于许多NLP任务的模型。
Github repo: https://github.com/google-research/text-to-text-transfer-transformer
Github仓库: https : //github.com/google-research/text-to-text-transfer-transformer
API for the model architecture and pre-trained weights by huggingface: https://huggingface.co/transformers/model_doc/t5.html
通过拥抱面Kong获得模型架构和预训练权重的API: https ://huggingface.co/transformers/model_doc/t5.html
C4 Tensorflow datasets: https://www.tensorflow.org/datasets/catalog/c4
C4 Tensorflow数据集: https ://www.tensorflow.org/datasets/catalog/c4
翻译自: https://towardsdatascience.com/t5-text-to-text-transfer-transformer-643f89e8905e
变压器 5g

