- 1RabbitMQ异步与重试机制_rabbitmq 重试机制测试
- 2四种经典限流算法的实现思路以及各自的优缺点_java的限流实现的各种优缺点
- 3Flink 实践教程-入门(10):Python作业的使用_flink python
- 4C语言学生选课系统实现_学生选修课程系统设计c语言代码
- 5边缘计算加持下的智慧社区_智慧社区边缘计算
- 6Anaconda环境下安装 opencv_annocoda opencv
- 7思科实验9.网络层:PPP协议配置_思科ppp协议
- 8论文Word问题02:EndNoteX9_插入引用参考文献_endnotex9怎么引用参考文献
- 9zookeeper总结
- 10Mobile ALOHA 的模仿学习算法和协同训练--翻译斯坦福机器人项目1_mobile-aloha联合训练
多模态产品在智能文档处理应用的展望------以TextIn模型为例
赞
踩
前言
第十四届视觉与学习青年学者研讨会(VALSE 2024)于5月5日-7日在山城重庆渝北区悦来国际会议中心举办。大会聚焦计算机视觉、模式识别、多媒体和机器学习等领域的国际前沿和热点方向。大会中,合合信息智能创新事业部研发总监常扬做了"文档解析与向量化技术加速多模态大模型训练与应用"专题汇报,主要讲解TextIn文档解析技术和高精度文本向量化模型的技术特征。下面为大家分享一下这次报告的主要内容。
发展现状
目前已有的文档解析技术依然面临诸多挑战。例如表格(特别是无线表)无法解析或结果错乱的问题,无法按照阅读顺序解析的问题,或是无法解析扫描版或图片版文档,又或是文档的编码出错误。这一问题严重影响到了大语言模型的训练与输出。因此我们需要文档解析技术能够阅读顺序还原准确、元素识别准确,尤其是表格、段落、公式、标题、识别速度快、支持论文等多种排版文档。
通常的做法是建立一个独立的文档解析Pipeline,判断文档类型并进行预处理。它主要分为三个部分:
-
第一个部分将不同类型的文档解析为基础文档表征。
-
第二个部分将基础文档表征进行处理,如版面分析、跨页合并、节点关系处理,将多元异构不同格式文档输出为可理解的顺序文档。
-
最后一个部分,将结果输出为markdown。
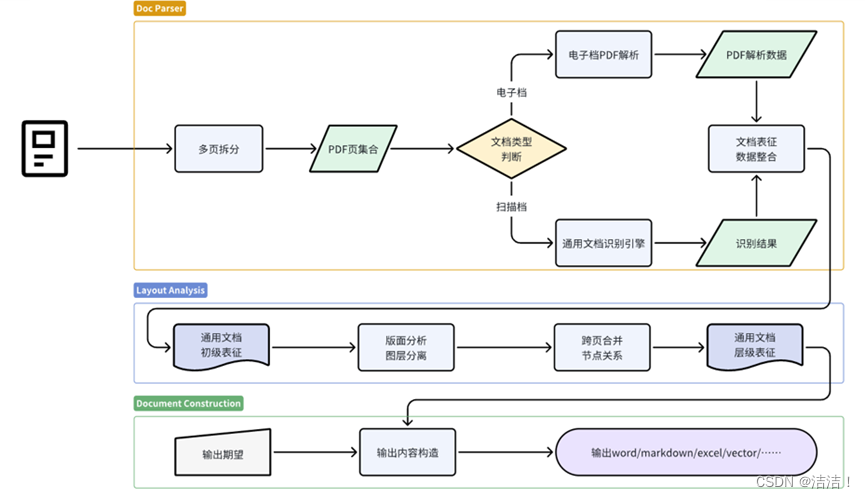
建立文档解析Pipeline的难点在于版面检测。文档元素可能存在遮盖重叠,元素本身形式五花八门,同时文档的版式众多,特别是多栏文档,阅读顺序本就不一样,在插入表格后,情况会变得更为复杂。此外表格造成的困难也是巨大的,无线表格和合并表格使内容难以定位。另外公式的使用也会为识别工作带来挑战。
TextIn 文档解析技术
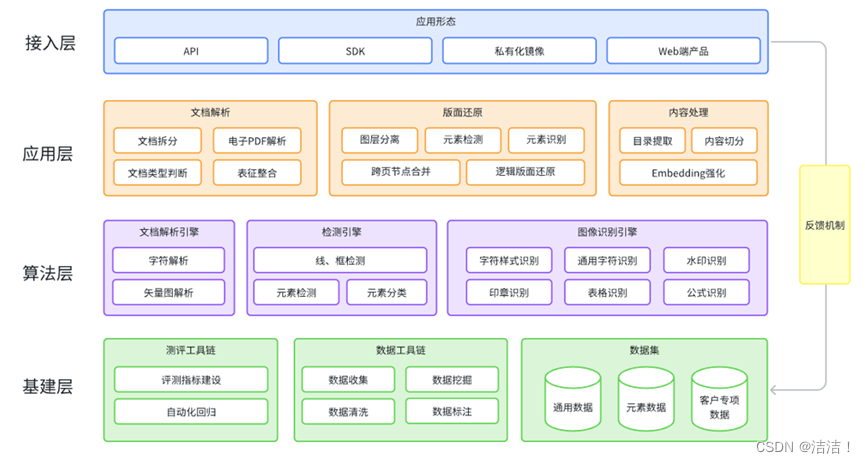
针对上述问题,合合信息发布了TextIn 相关模型。它采用了四层技术架构:底层是围绕数据相关的基建层;上方的算法层将文档拆分为单页的同时,对每个独立的元素进行解析检测和图像文字的识别;得到文档基础表征后,会进入到应用层,进行文档类型判断,表征整合以及版面的还原,最终还原为一个正常阅读顺序的文本,并通过接入层分发至其他应用。
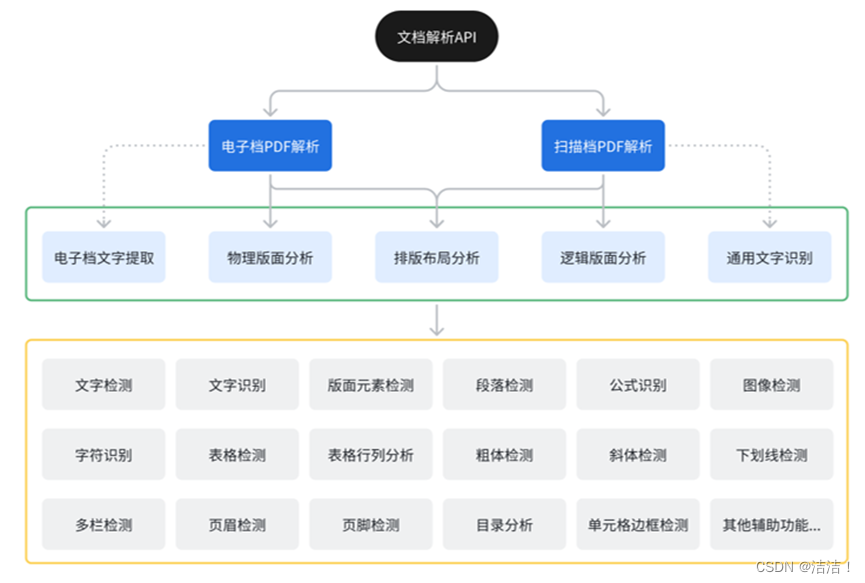
这其中包括两部分核心技术。第一部分是版面分析算法框架。它能够选取合适的流程,将电子档或扫描档解析为独立的元素,再整合成为遵循大模型可理解的阅读顺序的输出。
第二部分是文档树引擎。通过目录树准确地识别主标题、子标题、子段落、表格标题。
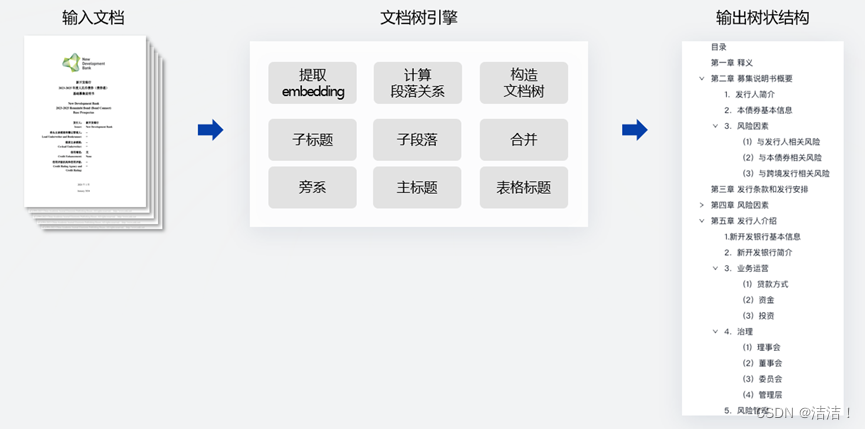
归功于这两样核心技术,TextIn在双栏、非对称双栏、含表格双栏、无线表格、合并表格层级目录文档的解析上都有出色表现。
 | 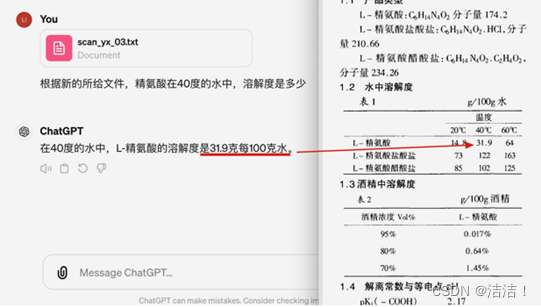 |
|---|---|
| 其他模型 | TextIn模型 |
文本向量化
除了文本解析技术,TextIn在文本向量化领域也尤为突出。近日,TextIn acge_text_embedding 文本向量化模型在 C-MTEB榜单排名第一。同时TextIn模型在多个方面都展现出了明显的优势。相比于传统的预训练或微调垂直领域模型,TextIn模型不仅支持通用分类模型的构建,还能提升长文档信息抽取的精度。此外,该模型的应用成本相对较低,使得大模型能够在多个行业中快速创造价值,推动科技创新和产业升级。在文档问答或知识库问答应用领域都有较强的发展前景。
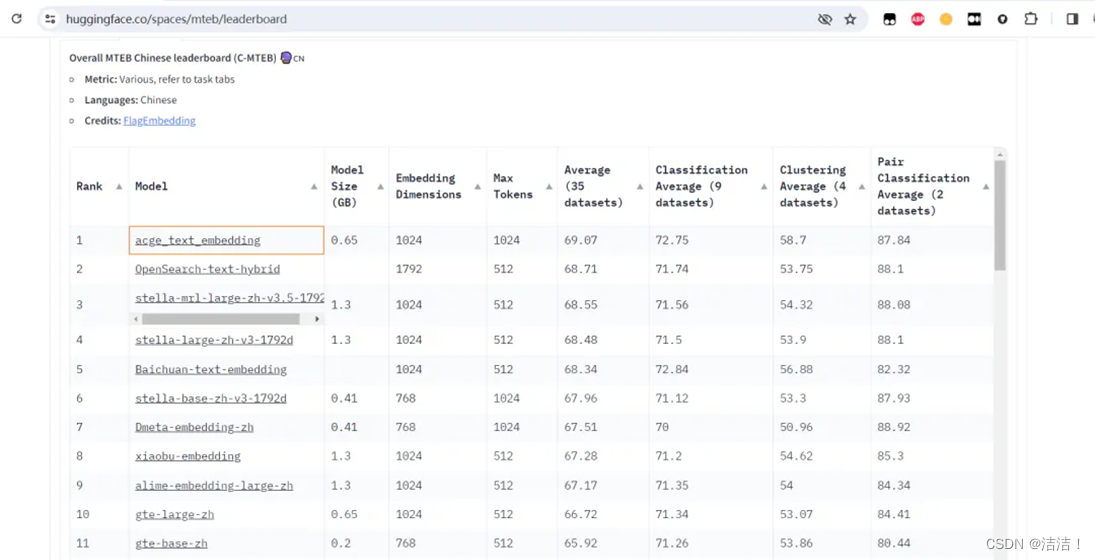
展望
合合信息的研究成果为各行业提供了实用的解决方案。合合信息开发出了高效、准确的图像处理算法和工具,为各种应用场景提供了优化的解决方案。这些成果广泛应用于金融、制造业、医疗等领域,极大地提升了效率和精度,并为各行业的发展带来了实际效益。希望合合信息能够持续进行深入的研究探索和技术创新,不断取得更多突破,推动人工智能技术的应用和智能产业的发展。
合合信息
上海合合信息科技股份有限公司致力于通过智能文字识别及商业大数据领域的核心技术、C端和B端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务。它开发的深受全球用户喜爱的C端产品全球累计用户下载超23亿,累计月活约 1.3亿。其中名片全能王和扫描全能王免费版在App Store排行榜上名列前茅。本次合合信息提供了TextIn的专题网站和讨论交流群,感兴趣的小伙伴不要错过!