
- 1Terraform学习日记-AWS-EC2_terraform --install-autocomplete
- 2【云原生|K8s系列第5篇】:实战使用Service暴露应用_external service暴露服务
- 3Ping的含义和作用_ping 域名是为了什么
- 4计算机网络方面有哪些书籍值得推荐?_关于计算机网络方面的书籍
- 5java毕业设计点餐系统的设计与实现mybatis+源码+调试部署+系统+数据库+lw_基于java的智慧食堂设计与实现
- 6【2024最新】Gradle安装配置教程_gradle下载安装
- 72024年最全【粉丝福利 第1期】教你如何一站式解决OpenCV工程化开发痛点,2024年最新网络安全开发基础面试题
- 8python识别视频中火焰_监控视频中火焰检测算法
- 9建立Typora-Markdown云笔记-错误解决_typora新建文件时保存报错
- 10Python函数(函数定义、函数调用)用法详解_python定义函数可以用到之后的函数
Golang 学习笔记3:Go 并发与网络_go 接口并发
赞
踩
13,Go 错误处理
1,error 接口
error 接口是 Go 原生内置的类型,它的定义如下:
// $GOROOT/src/builtin/builtin.go
type error interface {
Error() string
}
- 1
- 2
- 3
- 4
任何实现了 error 的 Error 方法的类型的实例,都可以作为错误值赋值给 error 接口变量。
Go 中有两个常用的函数可生成 error 类型变量:
errors.Newfmt.Errorf
使用示例:
func doSomething(...) error {
... ...
return errors.New("some error occurred")
}
- 1
- 2
- 3
- 4
判断错误的最常用方式:
err := doSomething()
if err != nil {
// 不关心err变量底层错误值所携带的具体上下文信息
// 执行简单错误处理逻辑并返回
... ...
return err
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面的方式,调用者并不关心具体的错误信息。
通过下面的方式可以针对不同的错误信息,做出不同的处理逻辑。
data, err := b.Peek(1) if err != nil { switch err.Error() { case "bufio: negative count": // ... ... return case "bufio: buffer full": // ... ... return case "bufio: invalid use of UnreadByte": // ... ... return default: // ... ... return } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
但是上面的方式严重依赖错误信息,一旦错误信息发生改变,调用者就得跟着改变。
Go 1.13 及后续版本,建议使用的错误判断方法:
errors.Is方法去检视某个错误值是否就是某个预期错误值errors.As方法去检视某个错误值是否是某自定义错误类型的实例
对于 errors.Is 方法,如果 error 类型变量的底层错误值是一个包装错误(Wrapped Error),errors.Is 方法会沿着该包装错误所在错误链(Error Chain),与链上所有被包装的错误(Wrapped Error)进行比较,直至找到一个匹配的错误为止。
例子:
var ErrSentinel = errors.New("the underlying sentinel error") func main() { // 用 %w 来包装错误 err1 := fmt.Errorf("wrap sentinel: %w", ErrSentinel) err2 := fmt.Errorf("wrap err1: %w", err1) println(err2 == ErrSentinel) // false if errors.Is(err2, ErrSentinel) { // true println("err2 is ErrSentinel") return } println("err2 is not ErrSentinel") }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
对于 errors.As 方法,使用模式:
// 类似 if e, ok := err.(*MyError); ok { … }
var e *MyError
if errors.As(err, &e) {
// 如果err类型为*MyError,变量e将被设置为对应的错误值
}
- 1
- 2
- 3
- 4
- 5
- 6
如果 error 类型变量的动态错误值是一个包装错误,errors.As 函数会沿着该包装错误所在错误链,与链上所有被包装的错误的类型进行比较,直至找到一个匹配的错误类型,就像 errors.Is 函数那样。
type MyError struct { e string } func (e *MyError) Error() string { return e.e } func main() { var err = &MyError{"MyError error demo"} err1 := fmt.Errorf("wrap err: %w", err) err2 := fmt.Errorf("wrap err1: %w", err1) var e *MyError if errors.As(err2, &e) { // true println("MyError is on the chain of err2") // 要特别注意这里,并不是将 err2 赋给了 e // 而是将 err2 链上匹配上的值 err 赋给了 e // 因此 err == e println(e == err) // true return } println("MyError is not on the chain of err2") }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2,panic 异常
panic 指的是 Go 程序在运行时出现的一个异常情况。如果异常出现了,但没有被捕获并恢复,Go 程序的执行就会被终止。
panic 主要有两类来源:
- 来自 Go 运行时
- 通过 panic 函数主动触发
当函数 F 调用 panic 函数时,函数 F 的执行将停止。不过,函数 F 中已进行求值的 deferred 函数都会得到正常执行,执行完这些 deferred 函数后,函数 F 才会把控制权返还给其调用者。
在 Go 标准库中,大多数 panic 的使用都是充当类似断言的作用的。
在 Go 中,作为 API 函数的作者,你一定不要将 panic 当作错误返回给 API 调用者。
一个例子:
func foo() { println("call foo") bar() println("exit foo") } func bar() { println("call bar") panic("panic occurs in bar") zoo() println("exit bar") } func zoo() { println("call zoo") println("exit zoo") } func main() { println("call main") foo() println("exit main") }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
其输出结果如下:
call main
call foo
call bar
panic: panic occurs in bar
- 1
- 2
- 3
- 4
在整个程序中,都没有对 panic 异常进行捕捉,所以在遇到 panic 异常后,程序就退出了。
在 Go 中使用 recover 函数对 panic 异常进行捕捉。
// 在一个 defer 匿名函数中调用 recover 函数对 panic 进行捕捉
func bar() {
defer func() {
if e := recover(); e != nil {
fmt.Println("recover the panic:", e)
}
}()
println("call bar")
panic("panic occurs in bar")
zoo()
println("exit bar")
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- recover 是 Go 内置的专门用于恢复 panic 的函数,它必须被放在一个 defer 函数中才能生效
- 如果 recover 捕捉到 panic,它就会返回以 panic 的具体内容为错误上下文信息的错误值
- 实际过程是,在 bar 中遇到 panic 后,bar 函数被异常终止
- 在 bar 退出时,要执行 defer 函数,此时 defer 函数中的 recover 捕获到了一个 pnic 异常
- 并且 recover 阻止了异常继续向上抛
- 此时,从 foo 函数的视角来看,bar 函数与正常返回没有什么差别。foo 函数依旧继续向下执行。
- 如果没有 panic 发生,那么 recover 将返回 nil
- 而且,如果 panic 被 recover 捕捉到,panic 引发的 panicking 过程就会停止
捕捉异常后的程序运行结果:
call main
call foo
call bar
recover the panic: panic occurs in bar
exit foo
exit main
- 1
- 2
- 3
- 4
- 5
- 6
将 panic 作为断言方式使用:
// $GOROOT/src/encoding/json/encode.go func (w *reflectWithString) resolve() error { ... ... switch w.k.Kind() { case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64: w.ks = strconv.FormatInt(w.k.Int(), 10) return nil case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr: w.ks = strconv.FormatUint(w.k.Uint(), 10) return nil } // 正常情况下,程序不会走到这里 // 如果走到了这里,说明出现了问题 // 相当于 assert 的作用 panic("unexpected map key type") }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
注意,Go 中 panic 并不同于 Java,Python 中的 raise 异常,所以不要将 panic 像 Exception 一样使用。 就是,作为 Go API 函数的作者,一定不要将 panic 当作错误返回给 API 调用者。
3,defer 函数
defer 是 Go 语言提供的一种延迟调用机制,defer 的运作离不开函数。
- 在 Go 中,只有在函数(和方法)内部才能使用 defer;
- defer 关键字后面只能接函数(或方法),这些函数被称为 deferred 函数。
- defer 将它们注册到其所在 Goroutine 中,用于存放 deferred 函数的栈数据结构中,这些 deferred 函数将在执行 defer 的函数退出前,按后进先出(LIFO)的顺序被程序调度执行。
- defer 关键字是在注册函数时对函数的参数进行求值的。
无论是执行到函数体尾部返回,还是在某个错误处理分支显式 return,又或是出现 panic,已经存储到 deferred 函数栈中的函数,都会被调度执行。所以说,deferred 函数是一个可以在任何情况下为函数进行收尾工作的好“伙伴”。
使用 defer 的一个示例:
func doSomething() error { var mu sync.Mutex mu.Lock() defer mu.Unlock() r1, err := OpenResource1() if err != nil { return err } defer r1.Close() r2, err := OpenResource2() if err != nil { return err } defer r2.Close() r3, err := OpenResource3() if err != nil { return err } defer r3.Close() // 使用r1,r2, r3 return doWithResources() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
对于自定义的函数或方法,defer 可以给与无条件的支持,但是对于有返回值的自定义函数或方法,返回值会在 deferred 函数被调度执行的时候被自动丢弃。
不是所有的内置函数都能作为 deffered 函数
- append、cap、len、make、new、imag 等内置函数都是不能直接作为 deferred 函数的
- 而 close、copy、delete、print、recover 等内置函数则可以直接被 defer 设置为 deferred 函数
对于那些不能直接作为 deferred 函数的内置函数,我们可以使用一个包裹它的匿名函数来间接满足要求,以 append 为例是这样的:
defer func() {
_ = append(sl, 11)
}()
- 1
- 2
- 3
14,Go 并发
Go 语言原生支持并发,Go 并发这个词,它包含两方面内容:
- 一个是并发的概念
- 一个是 Go 针对并发设计给出的自身的实现方案,也就是 goroutine、channel、select 这些 Go 并发的语法特性
1,goroutine
goroutine 是由 Go 运行时(runtime)负责调度的、轻量的用户级线程,为并发程序设计提供原生支持。
- 资源占用小,每个 goroutine 的初始栈大小仅为 2k;
- 一个 Go 程序中可以创建成千上万个并发的 Goroutine
- 由 Go 运行时而不是操作系统调度,goroutine 上下文切换在用户层完成,开销更小;
- 操作系统眼中只有线程,它甚至不知道有一种叫 Goroutine 的事物存在。所以,Goroutine 的调度全要靠 Go 自己完成
- 在操作系统层面,线程竞争的“CPU”资源是真实的物理 CPU
- Goroutine 们要竞争的“CPU”资源就是操作系统线程,Goroutine 调度器的任务是将 Goroutine 按照一定算法放到不同的操作系统线程中去执行。
- 在语言层面而不是通过标准库提供。goroutine 由go关键字创建,一退出就会被回收或销毁,开发体验更佳;
- 语言内置 channel 作为 goroutine 间通信原语,为并发设计提供了强大支撑。
Go 语言通过 go关键字+函数/方法 的方式创建一个 goroutine。创建后,新 goroutine 将拥有独立的代码执行流,并与创建它的 goroutine 一起被 Go 运行时调度。
多数情况下,我们不需要考虑对 goroutine 的退出进行控制:goroutine 的执行函数的返回,就意味着 goroutine 退出。
如果 main goroutine 退出了,那么也意味着整个应用程序的退出。
此外,你还要注意的是,goroutine 执行的函数或方法即便有返回值,Go 也会忽略这些返回值。所以,如果你要获取 goroutine 执行后的返回值,你需要另行考虑其他方法,比如通过 goroutine 间的通信来实现。
2,channel
channel 既可以用来实现 Goroutine 间的通信,还可以实现 Goroutine 间的同步。
channel 是用于 Goroutine 间通信的,所以绝大多数对 channel 的读写都被分别放在了不同的 Goroutine 中。
Go 在语法层面将并发原语 channel 作为一等公民对待,使得我们可以像使用普通变量那样使用 channel,比如:
- 定义 channel 类型变量
- 给 channel 变量赋值
- 将 channel 作为参数传递给函数 / 方法
- 将 channel 作为返回值从函数 / 方法中返回
- 甚至将 channel 发送到其他 channel 中
channel 也是一种复合数据类型,在声明一个 channel 类型变量时,必须给出其具体的元素类型:
// 声明一个元素为 int 类型的 channel 类型变量 ch
var ch chan int
- 1
- 2
如果 channel 类型变量在声明时没有被赋予初值,那么它的默认值为 nil。
为 channel 类型变量赋初值的唯一方法就是使用 make 函数:
ch1 := make(chan int) // 无缓冲 channel
ch2 := make(chan int, 5) // 有缓冲 channel,缓冲区长度是 5
- 1
- 2
上面两种类型的变量关于发送(send)与接收(receive)的特性是不同的。
Go 提供了<- 操作符用于对 channel 类型变量进行发送与接收操作:
ch1 <- 13 // 将整型字面值13发送到无缓冲channel类型变量ch1中
n := <- ch1 // 从无缓冲channel类型变量ch1中接收一个整型值存储到整型变量n中
ch2 <- 17 // 将整型字面值17发送到带缓冲channel类型变量ch2中
m := <- ch2 // 从带缓冲channel类型变量ch2中接收一个整型值存储到整型变量m中
- 1
- 2
- 3
- 4
无缓冲 channel 的运行时层实现不带有缓冲区,所以 Goroutine 对无缓冲 channel 的接收和发送操作是同步的。也就是说,对同一个无缓冲 channel,只有对它进行接收操作的 Goroutine 和对它进行发送操作的 Goroutine 都存在的情况下,通信才能得以进行,否则单方面的操作会让对应的 Goroutine 陷入挂起状态,比如下面示例代码:
// 这里创建了一个无缓冲的 channel 类型变量 ch1,对 ch1 的读写都放在了一个 Goroutine 中
func main() {
ch1 := make(chan int)
ch1 <- 13 // fatal error: all goroutines are asleep - deadlock!
n := <-ch1
println(n)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
因此上面代码要进行如下改进:
func main() {
ch1 := make(chan int)
go func() {
ch1 <- 13 // 将发送操作放入一个新goroutine中执行
}()
n := <-ch1
println(n)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
带缓冲 channel 的运行时层实现带有缓冲区,因此,对带缓冲 channel 的发送操作在缓冲区未满、接收操作在缓冲区非空的情况下是异步的(发送或接收不需要阻塞等待)。
示例:
ch2 := make(chan int, 1)
n := <-ch2 // 由于此时ch2的缓冲区中无数据,因此对其进行接收操作将导致goroutine挂起
ch3 := make(chan int, 1)
ch3 <- 17 // 向ch3发送一个整型数17
ch3 <- 27 // 由于此时ch3中缓冲区已满,再向ch3发送数据也将导致goroutine挂起
- 1
- 2
- 3
- 4
- 5
- 6
我们还可以声明只发送 channel 类型(send-only)和只接收 channel 类型(recv-only):
ch1 := make(chan<- int, 1) // 只发送channel类型
ch2 := make(<-chan int, 1) // 只接收channel类型
<-ch1 // invalid operation: <-ch1 (receive from send-only type chan<- int)
ch2 <- 13 // invalid operation: ch2 <- 13 (send to receive-only type <-chan int)
- 1
- 2
- 3
- 4
- 5
试图从一个只发送 channel 类型变量中接收数据,或者向一个只接收 channel 类型发送数据,都会导致编译错误。
通常只发送 channel 类型和只接收 channel 类型,会被用作函数的参数类型或返回值,用于限制对 channel 内的操作,或者是明确可对 channel 进行的操作的类型。
例如下面生产者和消费者的例子:
func produce(ch chan<- int) { for i := 0; i < 10; i++ { ch <- i + 1 time.Sleep(time.Second) } close(ch) } func consume(ch <-chan int) { for n := range ch { println(n) } } func main() { ch := make(chan int, 5) var wg sync.WaitGroup wg.Add(2) go func() { produce(ch) wg.Done() }() go func() { consume(ch) wg.Done() }() wg.Wait() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
在这个例子中:
- 我们启动了两个 Goroutine,分别代表生产者(produce)与消费者(consume)。
- 生产者只能向 channel 中发送数据,我们使用chan<- int作为 produce 函数的参数类型;
- 消费者只能从 channel 中接收数据,我们使用<-chan int作为 consume 函数的参数类型。
- 在消费者函数 consume 中,我们使用了 for range 循环语句来从 channel 中接收数据,for range 会阻塞在对 channel 的接收操作上,直到 channel 中有数据可接收或 channel 被关闭循环,才会继续向下执行。
- channel 被关闭后,for range 循环也就结束了。
- channel 关闭后,所有等待从这个 channel 接收数据的操作都将返回。
- 从一个已关闭的 channel 接收数据将永远不会被阻塞,并可得到对应类型的零值
- channel一旦没有人引用了,就会被gc掉,不关闭也ok。但是如果有goroutine一直在读channel,那么channel一直存在,不会关闭。直到程序退出。
n := <- ch // 当ch被关闭后,n将被赋值为ch元素类型的零值
m, ok := <-ch // 当ch被关闭后,m将被赋值为ch元素类型的零值, ok值为false
for v := range ch { // 当ch被关闭后,for range循环结束
... ...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
channel 的一个使用惯例,那就是发送端负责关闭 channel。
一旦向一个已经关闭的 channel 执行发送操作,这个操作就会引发 panic,比如:
ch := make(chan int, 5)
close(ch)
ch <- 13 // panic: send on closed channel
- 1
- 2
- 3
3,无缓冲 channel 的惯用法
无缓冲 channel 兼具通信和同步特性,在并发程序中应用颇为广泛。
- 第一种用法:用作信号传递
- 第二种用法:用于替代锁机制
第一种用法:用作信号传递
无缓冲 channel 用作信号传递的时候,有两种情况,分别是 1 对 1 通知信号和 1 对 n 通知信号。
第二种用法:用于替代锁机制
无缓冲 channel 具有同步特性,这让它在某些场合可以替代锁,让我们的程序更加清晰,可读性也更好。
4,有缓冲 channel 的惯用法
带缓冲的 channel 与无缓冲的 channel 的最大不同之处,就在于它的异步性。也就是说,对一个带缓冲 channel,在缓冲区未满的情况下,对它进行发送操作的 Goroutine 不会阻塞挂起;在缓冲区有数据的情况下,对它进行接收操作的 Goroutine 也不会阻塞挂起。
- 第一种用法:用作消息队列
- 无论是 1 收 1 发还是多收多发,带缓冲 channel 的收发性能都要好于无缓冲 channel;
- 对于带缓冲 channel 而言,发送与接收的 Goroutine 数量越多,收发性能会有所下降;
- 对于带缓冲 channel 而言,选择适当容量会在一定程度上提升收发性能。
- 第二种用法:用作计数信号量
- len(channel) 的应用
- 当 ch 为无缓冲 channel 时,len(ch) 总是返回 0;
- 当 ch 为带缓冲 channel 时,len(ch) 返回当前 channel ch 中尚未被读取的元素个数。
那我们是否可以使用 len 函数来实现带缓冲 channel 的“判满”、“判有”和“判空”逻辑呢?
var ch chan T = make(chan T, capacity) // 判空 if len(ch) == 0 { // 此时channel ch空了? } // 判有 if len(ch) > 0 { // 此时channel ch中有数据? } // 判满 if len(ch) == cap(ch) { // 此时channel ch满了? }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
channel 原语用于多个 Goroutine 间的通信,一旦多个 Goroutine 共同对 channel 进行收发操作,len(channel) 就会在多个 Goroutine 间形成“竞态”。
单纯地依靠 len(channel) 来判断 channel 中元素状态,是不能保证在后续对 channel 的收发时 channel 状态是不变的。
5,nil channel
如果一个 channel 类型变量的值为 nil,我们称它为 nil channel,对 nil channel 的读写都会发生阻塞。
func main() {
var c chan int
<-c //阻塞
}
或者:
func main() {
var c chan int
c<-1 //阻塞
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6,select
当涉及同时对多个 channel 进行操作时,我们会结合另外一个原语 select,一起使用。
通过 select,我们可以同时在多个 channel 上进行发送 / 接收操作:
select {
case x := <-ch1: // 从channel ch1接收数据
... ...
case y, ok := <-ch2: // 从channel ch2接收数据,并根据ok值判断ch2是否已经关闭
... ...
case ch3 <- z: // 将z值发送到channel ch3中:
... ...
default: // 当上面case中的channel通信均无法实施时,执行该默认分支
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
当 select 语句中没有 default 分支,而且所有 case 中的 channel 操作都阻塞了的时候,整个 select 语句都将被阻塞,直到某一个 case 上的 channel 变成可发送,或者某个 case 上的 channel 变成可接收,select 语句才可以继续进行下去。
15,Go 共享内存
Go 语言之父 Rob Pike 还有一句经典名言:“不要通过共享内存来通信,应该通过通信来共享内存”。这就奠定了 Go 应用并发设计的主流风格:使用 channel 进行不同 Goroutine 间的通信。
一般情况下,建议优先使用 channel 并发模型进行并发程序设计。
不过,Go 也并没有彻底放弃基于共享内存的并发模型,而是在提供 CSP 并发模型原语的同时,还通过标准库的:
- sync 包,提供了针对传统的、基于共享内存并发模型的低级同步原语,包括:
- 互斥锁(sync.Mutex)
- 读写锁(sync.RWMutex):适合应用在具有一定并发量且读多写少的场合
- 条件变量(sync.Cond)
- 并通过 atomic 包提供了原子操作原语等
Mutex 的使用示例:
var mu sync.Mutex
mu.Lock() // 加锁
doSomething()
mu.Unlock() // 解锁
- 1
- 2
- 3
- 4
- 5
RWMutex 的使用示例:
var rwmu sync.RWMutex
rwmu.RLock() //加读锁
readSomething()
rwmu.RUnlock() //解读锁
rwmu.Lock() //加写锁
changeSomething()
rwmu.Unlock() //解写锁
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
其实,面向 CSP 并发模型的 channel 原语和面向传统共享内存并发模型的 sync 包提供的原语,已经能够满足 Go 语言应用并发设计中 99.9% 的并发同步需求了。而剩余那 0.1% 的需求,我们可以使用 Go 标准库提供的 atomic 包来实现。
16,Go Socket 编程
Go 为开发人员提供了阻塞 I/O 模型,Gopher 只需在 Goroutine 中以最简单、最易用的“阻塞 I/O 模型”的方式,进行 Socket 操作就可以。
但这种方式是 Go 模拟出来,是为了让开发者使用起来更加简单易懂,对应的、真实的底层操作系统 Socket,实际上是非阻塞的。
Go 没有使用基于线程的并发模型,而是使用了开销更小的 Goroutine 作为基本执行单元,这让每个 Goroutine 处理一个 TCP 连接成为可能,并且在高并发下依旧表现出色。
虽然目前主流 socket 网络编程模型是 I/O 多路复用模型,但考虑到这个模型在使用时的体验较差,Go 语言将这种复杂性隐藏到运行时层,并结合 Goroutine 的轻量级特性,在用户层提供了基于 I/O 阻塞模型的 Go socket 网络编程模型,这一模型就大大简化了编程难度。
1,Server 端
Go Server 端编程套路模板:
func handleConn(c net.Conn) { defer c.Close() for { // read from the connection // ... ... // write to the connection //... ... } } func main() { l, err := net.Listen("tcp", ":8888") if err != nil { fmt.Println("listen error:", err) return } for { c, err := l.Accept() if err != nil { fmt.Println("accept error:", err) break } // start a new goroutine to handle // the new connection. go handleConn(c) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
2,Client 端
Go Client 端与 Server 端建立连接的两种方式:
conn, err := net.Dial("tcp", "localhost:8888")
// 带有超时机制的建连
conn, err := net.DialTimeout("tcp", "localhost:8888", 2 * time.Second)
- 1
- 2
- 3
- 4
net.Dial 函数的第一个参数的可选值,共九个:
- “tcp”:代表 TCP 协议,其基于的 IP 协议的版本根据参数address的值自适应。
- “tcp4”:代表基于 IP 协议第四版的 TCP 协议。
- “tcp6”:代表基于 IP 协议第六版的 TCP 协议。
- “udp”:代表 UDP 协议,其基于的 IP 协议的版本根据参数address的值自适应。
- “udp4”:代表基于 IP 协议第四版的 UDP 协议。
- “udp6”:代表基于 IP 协议第六版的 UDP 协议。
- “unix”:代表 Unix 通信域下的一种内部 socket 协议,以 SOCK_STREAM 为 socket 类型。
- “unixgram”:代表 Unix 通信域下的一种内部 socket 协议,以 SOCK_DGRAM 为 socket 类型。
- “unixpacket”:代表 Unix 通信域下的一种内部 socket 协议,以 SOCK_SEQPACKET 为 socket 类型。
3,Socket 读操作
从 Socket 读数据的三种情况:
- Socket 中无数据:如果没有设置超时时间,那么读操作会一直阻塞
- SetReadDeadline 方法可以设置超时时间,SetReadDeadline 方法接受一个绝对时间作为超时的 deadline。
- 一旦通过这个方法设置了某个 socket 的 Read deadline,当发生超时后,如果我们不重新设置 Deadline,那么后面与这个 socket 有关的所有读操作,都会返回超时失败错误。
SetReadDeadline(time.Time{})可用于取消超时时间
- Socket 中有部分数据:Socket 中有部分数据就绪,且数据数量小于一次读操作期望读出的数据长度
- 读操作将会成功读出这部分数据,并返回,而不是等待期望长度数据全部读取后,再返回
- Socket 中有足够数据:成功读出期望的数据,并返回
- 剩下的数据会在下一次读取时获取
4,Socket 写操作
当 Write 调用的返回值 n 的值,与预期要写入的数据长度相等,且 err = nil 时,我们就执行了一次成功的 Socket 写操作,这是我们在调用 Write 时遇到的最常见的情形。
其它情况还有:
- 写阻塞
- 写入部分数据
- 写入超时
- SetWriteDeadline 方法用于设置写超时时间
5,关闭 Socket
当客户端主动关闭了 Socket,那么服务端的Read调用将会读到什么呢?这里要分“有数据关闭”和“无数据关闭”两种情况。
- 有数据关闭:指在客户端关闭连接时,Socket 中还有服务端尚未读取的数据
- 在这种情况下,服务端的 Read 会成功将剩余数据读取出来,
- 最后一次 Read 操作将得到io.EOF错误码,表示客户端已经断开了连接。
- 无数据关闭
- 服务端调用的 Read 方法将直接返回io.EOF。
17,strings 包
1,string 类型
在 Go 语言中,string 类型的值是不可变的。在进行字符串拼接的时候,Go 语言会把所有被拼接的字符串依次拷贝到一个崭新且足够大的连续内存空间中,并把持有相应指针值的 string 值作为结果返回。
因此,当程序中存在过多的字符串拼接操作的时候,会对内存的分配产生非常大的压力。
2,strings.Builder
与 string 相比,Builder 的优势主要体现在字符串拼接方面。与 string 一样,Builder 的底层也是一个 byte 类型的切片(字节切片),Builder 会按需扩容,不必每次拼接都需要拷贝。
使用 StringBuffer 或是 StringBuild 来拼接字符串,会比使用 + 或 += 性能高三到四个数量级。
当一个 Builder 中的空间够用时,其不会发生扩容,当不够用时,其会自动进行扩容。发生扩容时,会产生新的更大的内存空间,并将旧空间中的数据拷贝到新空间。
Builder 对象中的方法:
- Write
- WriteByte
- WriteRune
- WriteString
- Grow:用于扩容
- Reset:重置容器,其中的内容将被丢弃
3,strings.Reader
strings.Reader 类型是为了高效读取字符串而存在的。
Reader 对象中的方法:
- ReadByte
- ReadRune
- ReadAt
- Seek
4,其它方法
Go 的 strings 包中有很多字符串相关操作函数:
strings.Split:字符串分割strings.Join:字符串连接strings.Count:计数strings.Compare:字符串比较strings.Contains:是否包含strings.HasPrefix:是否包含前缀strings.HasSuffix:是否包含后缀strings.Index:某字符的位置,不存在返回 -1strings.LastIndexstrings.Repeat:重复字符串几次strings.Replace:字符串替换strings.Split:字符串分割strings.Trim:字符串去除某字符strings.TrimLeftstrings.TrimRightstrings.TrimSpace:去除首尾空格strings.ToLower:转小写strings.ToUpper:转大写strings.Title:首字母转大写strings.Fields:字符串变数组,将字符串以空白字符分割
18,bytes 包
strings 包主要面向的是 Unicode 字符和经过 UTF-8 编码的字符串,而 bytes 包面对的则主要是字节和字节切片。
在内部,bytes.Buffer 类型同样是使用字节切片作为内容容器的。
bytes.Buffer 类型的用途主要是作为字节序列的缓冲区,bytes.Buffer 是集读、写功能于一身的数据类型。
19,io 包
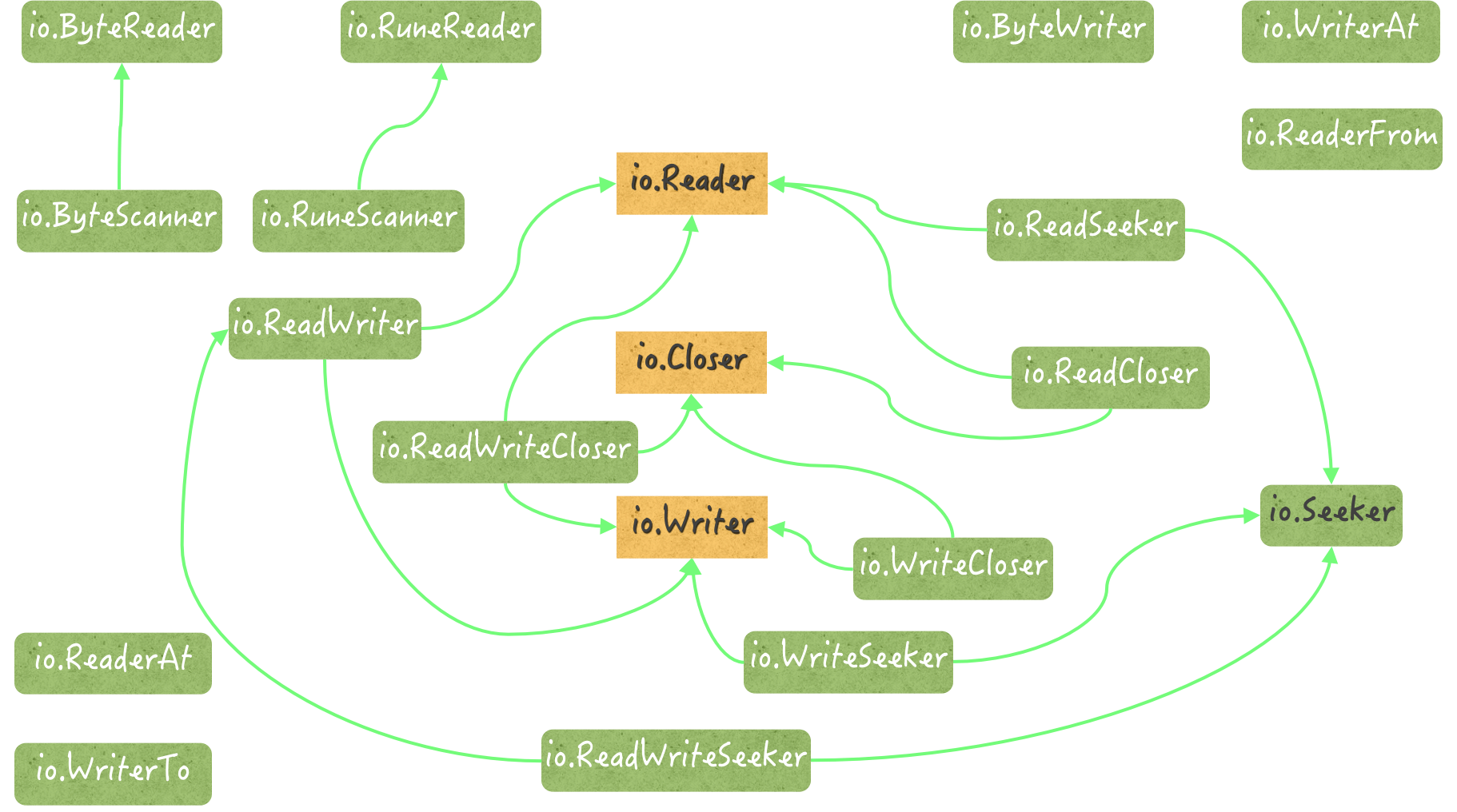
20,os 包
- os.File:代表操作系统中的文件
- os.Create:根据给定的路径创建一个新的文件
- os.NewFile:它并不是创建一个新的文件,而是依据一个已经存在的文件的描述符,来新建一个包装了该文件的 File 值。
- os.Open:打开一个文件并返回包装了该文件的 File 值
- os.OpenFile:它其实是 os.Create 函数和 os.Open 函数的底层支持,它最为灵活。
模式值有:
- os.O_RDONLY:只读
- os.O_WRONLY:只写
- os.O_RDWR:读写
- os.O_APPEND:当向文件中写入内容时,把新内容追加到现有内容的后边
- os.O_CREATE:当给定路径上的文件不存在时,创建一个新文件
- os.O_EXCL:与 os.O_CREATE 一同使用,表示在给定的路径上不能有已存在的文件
- os.O_SYNC:在打开的文件之上实施同步 I/O。它会保证读写的内容总会与硬盘上的数据保持同步
- os.O_TRUNC:如果文件已存在,并且是常规的文件,那么就先清空其中已经存在的任何内容
21,Go 优秀项目
开发框架
- Web 框架
- gin
- beego
- martini
- revel
- echo
- iris
- negroni
- gorilla:mux、websocket
- buffalo
- goproxy
- go-restful
- graphql
- 路由:httprouter
- 微服务:go-kit/kit、go-micro、goa、kite
- RPC:grpc-go、grpc-gateway、rpcx
- 数据库
- mysql
- gorm
- sqlx
- gorp
- xorm
- redigo
- redis
- mgo
- elastic
- 命令行:cobra、urfave/cli、promptui、fatih/color
- 日志:logrus、zap
- 网页解析:goquery
- 文件、文本分析
- blackfriday
- xlsx
- gofpdf
- go-yaml/yaml
- SurntSushi/toml
- 序列化
- golang/protobuf
- gogo/protobuf
- gopacket
- gjson
- ffjson
- go-simplejson
- structs
- go-spew
- 高级数据结构:go-datastructures、gods
- 单元测试:testify
- 错误处理:pkg/errors
- 任务管理:robfig/cron
- 嵌入式设备:gobot
- 文本搜索:bleve
- 分布式计算:netstack、protoactor-go
数据分析
- 机器学习:golearn、prose、hybridgroup/gocv
- 数据处理:pachyderm、gonum
云计算
- 容器技术
- moby
- kubernetes
- rkt
- gvisor
- rancher
- runc
- distribution
- 注册服务:registrator、harbor
- 访问框架:go-cloud、go-github
中间件
- 反向代理:traefik、frp
- 消息队列:nsq、gnatsd、jocko、centrifugo
- 服务发现:consul、consul-template、istio
- KV 存储:etcd、bolt、badger
- 负载均衡:seesaw、fabio
独立服务
- CI/CD:gogs、gitea
- Web 服务器:caddy
- 监控系统:prometheus
- 数据库:
- influxdb
- cockroach
- tidb
- cayley
- noms
- vitess
- dgraph
- kingshard
- ledisdo
- goleveldb
- 对象存储服务器:minio
- 消息服务器:centrifugo、gorush
- 集群管理:nomad、gala
- 数据采集软件:pholcus、ferret
- 应用系统:goim
系统工具
- 同步工具:syncthing、oklog
- 流量重放:goreplay/gor
- 负载测试:vegeta、boom、k6、ney
- 系统监控:telegraf、gopsutil
- 任务管理:realize
- 扫描渗透:vuls、gitleaks
- Web 交互:gotty、wuzz
- HTTP 客户端:httpstat、bat
- 配置管理:confd
Go 程序辅助工具
- 程序调试:delve
- 程序监控:termui、go-metrics、checkup、gops
- 程序分析:uber/go-torch
- 依赖管理:dep、glide、godep、govendor、gb
- 程序测试:ginkgo、goss、go-fuzz、goconvey
- 文档生成:go-swagger
- 程序发布:goreleaser


