
- 1手把手教你从微软官网上下载系统镜像【保持最新版】_微软系统镜像官网
- 2Git小乌龟的安装及简单使用_git小乌龟安装
- 3【纯手撸】使用PySide6 / pyqt 搭建现代化普通B端系统图形化界面_python pyside6 做资源管理器框架界面
- 4408数据结构笔记整理
- 5区块链技术的应用前景及挑战_一个企业如果要实施区块链技术有哪些挑战
- 6arkTS开发鸿蒙OS个人商城案例【2024最新 新年限定开发案例QAQ】_arkts案例
- 7uni-app 微信小程序之自定义navigationBar顶部导航栏_微信小程序自定义顶部导航栏(兼容适配所有机型)
- 8Java stringbuilder与string相互转换_stringbuilder转string
- 9大模型时代,程序员需要具备哪些技能才能胜任?
- 10HDFS 架构剖析_简述hdfs架构
(一)RabbitMQ——消息队列简介_rabbitmq 发送消息前需要手动创建队列吗
赞
踩
目录
1. 消息队列使用背景
比如电商使用场景:
- 商品的原始数据保存在数据库中,增删改查都在数据库中完成。
- 搜索服务数据来源是索引库(Elasticsearch),如果数据库商品发生变化,索引库数据不能及时更新。
- 商品详情做了页面静态化处理,静态页面数据也不会随着数据库商品更新而变化。
- 如果我们在后台修改了商品的价格,搜索页面和商品详情页显示的依然是旧的价格,这样显然不对。该如何解决?
初级优化方案:
- 方案1:每当后台对商品做增删改操作,同时修改索引库数据及更新静态页面。
- 方案2:搜索服务和商品页面静态化服务对外提供操作接口,后台在商品增删改后,调用接口。
这两种方案都有个严重的问题:就是代码耦合,后台服务中需要嵌入搜索和商品页面服务,违背了微服务的独立原则。
消息队列方案:
商品服务对商品增删改以后,无需去操作索引库和静态页面,只需向MQ发送一条消息(比如包含商品id的消息),也不关心消息被谁接收。
搜索服务和静态页面服务监听MQ,接收消息,然后分别去处理索引库和静态页面(根据商品id去更新索引库和商品详情静态页面)。
2. 消息队列定义
2.1 遵循设计原则
- 要满足未来的业务需求的不断变化和增加. 也就是可扩展性.
- 要满足性能的可伸缩性. 也就是可集群性…通过增加机器能处理更多的请求
- 要解耦合.如果不解耦合, 未来业务增加或变更的时候你还在修改原来代码.试问你有多大的把握保证升级好系统不出问题? 如何可以写新的代码而不用修改老代码所带来的好处谁都知道.
- 简单易懂.
2.2 消息队列定义
MQ全称为Message Queue,即消息队列。“消息队列”是在消息的传输过程中保存消息的容器。它是典型的:生产者、消费者模型。生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,这样就实现了生产者和消费者的解耦。
3. 应用场景
3.1 任务异步处理
高并发环境下,由于来不及同步处理,请求往往会发生堵塞,比如说,大量的insert,update之类的请求同时到达MySQL,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发too many connections错误。通过使用消息队列,我们可以异步处理请求,从而缓解系统的压力。将不需要同步处理的并且耗时长的操作由消息队列通知消息接收方进行异步处理。减少了应用程序的响应时间。
3.2 应用程序解耦合
MQ相当于一个中介,生产方通过MQ与消费方交互,它将应用程序进行解耦合。
4. 实现MQ两种主流方式AMQP、JMS
4.1 AMQP JMS区别和联系
| JMS | AMQP |
|---|---|
| JMS是定义了统一的接口,来对消息操作进行统一 | AMQP是通过规定协议来统一数据交互的格式 |
| JMS限定了必须使用Java语言 | AMQP只是协议,不规定实现方式,因此是跨语言的 |
| JMS规定了两种消息模型 | 而AMQP的消息模型更加丰富 |
4.2 常见MQ产品
| ActiveMQ: | 基于JMS |
| RabbitMQ: | 基于AMQP协议,erlang语言开发,稳定性好 |
| RocketMQ: | 基于JMS,阿里巴巴产品,目前交由Apache基金会 |
| Kafka: | 分布式消息系统,高吞吐量 |
5. RabbitMQ的基本结构介绍
5.1 RabbitMQ结构图
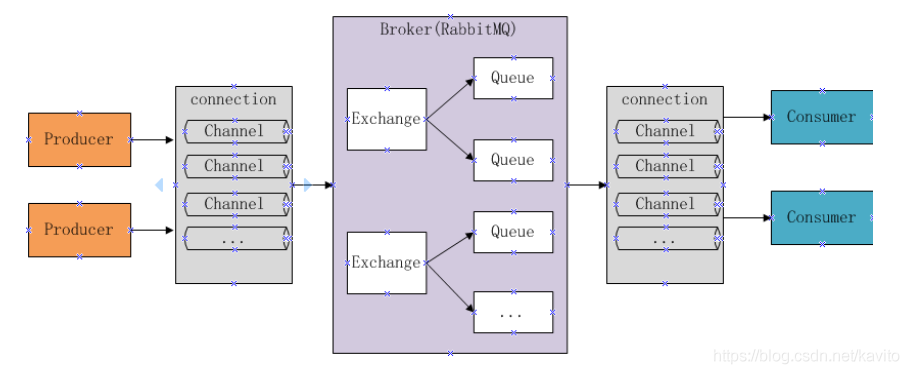
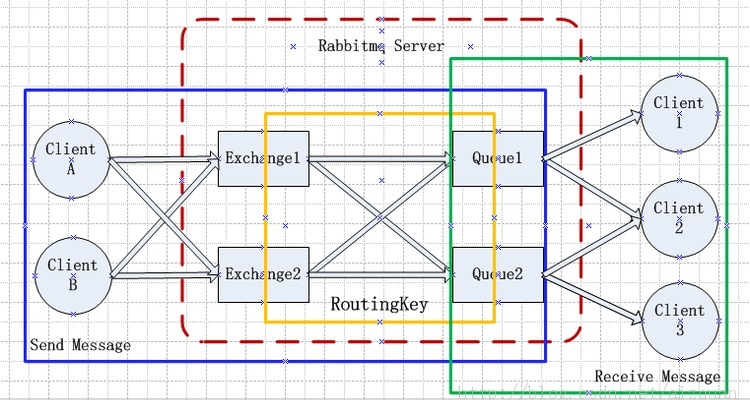
5.2 组成部分说明
5.2.1 Broker
Broker:消息队列服务进程,此进程包括两个部分:Exchange和Queue
它提供一种传输服务,它的角色就是维护一条从生产者到消费者的路线,保证数据能按照指定的方式进行传输
5.2.2 Exchange
Exchange:消息队列交换机,按一定的规则将消息路由转发到某个队列,对消息进行过虑。
从架构图可以看出,Procuder Publish的Message进入了Exchange。接着通过“routing keys”, RabbitMQ会找到应该把这个Message放到哪个queue里。queue也是通过这个routing keys来做的绑定。有三种类型的Exchanges:direct, fanout,topic。 每个实现了不同的路由算法(routing algorithm)。
- Direct exchange: 如果 routing key 匹配, 那么Message就会被传递到相应的queue中。其实在queue创建时,它会自动的以queue的名字作为routing key来绑定那个exchange。
- Fanout exchange: 会向响应的queue广播。
- Topic exchange: 对key进行模式匹配,比如ab*可以传递到所有ab*的queue。
5.2.3 Queue
Queue:消息队列,存储消息的队列,消息到达队列并转发给指定的
消息的载体,每个消息都会被投到一个或多个队列
5.2.4 Producer
Producer:消息生产者,即生产方客户端,生产方客户端将消息发送
数据的发送方。createmessages and publish (send) them to a broker server (RabbitMQ).一个Message有两个部分:payload(有效载荷)和label(标签)。payload顾名思义就是传输的数据。label是exchange的名字或者说是一个tag,它描述了payload,而且RabbitMQ也是通过这个label来决定把这个Message发给哪个Consumer。AMQP仅仅描述了label,而RabbitMQ决定了如何使用这个label的规则。
5.2.5 Consumer
Consumer:消息消费者,即消费方客户端,接收MQ转发的消息。
数据的接收方。Consumersattach to a broker server (RabbitMQ) and subscribe to a queue。把queue比作是一个有名字的邮箱。当有Message到达某个邮箱后,RabbitMQ把它发送给它的某个订阅者即Consumer。当然可能会把同一个Message发送给很多的Consumer。在这个Message中,只有payload,label已经被删掉了。对于Consumer来说,它是不知道谁发送的这个信息的。就是协议本身不支持。但是当然了如果Producer发送的payload包含了Producer的信息就另当别论了。
5.2.6 Connection
就是一个TCP的连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接。
5.2.7 Channels
虚拟连接。它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
那么,为什么使用Channel,而不是直接使用TCP连接?
对于OS来说,建立和关闭TCP连接是有代价的,频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。
但是,在TCP连接中建立Channel是没有上述代价的。
对于Producer或者Consumer来说,可以并发的使用多个Channel进行Publish或者Receive。
有实验表明,1s的数据可以Publish10K的数据包。当然对于不同的硬件环境,不同的数据包大小这个数据肯定不一样,但是我只想说明,对于普通的Consumer或者Producer来说,这已经足够了。如果不够用,你考虑的应该是如何细化split你的设计。
5.2.8 vhost
每个virtual host本质上都是一个RabbitMQ Server,拥有它自己的queue,exchagne,和bings rule等等。这保证了你可以在多个不同的application中使用RabbitMQ。
Virtual hosts虚拟主机,一个broker里可以有多个vhost,用作不同用户的权限分离
5.2.9 Binding
:绑定,它的作用就是把exchange和queue按照路由规则绑定起来
5.2.10 Routing Key
路由关键字,exchange根据这个关键字进行消息投递
5.2.11 元数据
RabbitMQ 内部有各种基础构件,包括队列、交换器、绑定、虚拟主机等,他们组成了 AMQP 协议消息通信的基础,而这些构件以元数据的形式存在,它始终记录在 RabbitMQ 内部,它们分别是:
- 队列元数据:队列名称和它们的属性
- 交换器元数据:交换器名称、类型和属性
- 绑定元数据:一张简单的表格展示了如何将消息路由到队列
- vhost元数据:为 vhost 内的队列、交换器和绑定提供命名空间和安全属性
5.3 生产者和消费者流程概要
5.3.1 生产者发送消息流程
- 生产者和Broker建立TCP连接。
- 生产者和Broker建立通道。
- 生产者通过通道消息发送给Broker,由Exchange将消息进行转发。
- Exchange将消息转发到指定的Queue(队列)
5.3.2 消费者接收消息流程
- 消费者和Broker建立TCP连接
- 消费者和Broker建立通道
- 消费者监听指定的Queue(队列)
- 当有消息到达Queue时Broker默认将消息推送给消费者。
- 消费者接收到消息。
- ack回复
6. RabbitMQ6种消息模型简介
RabbitMQ提供了6种消息模型,但是第6种其实是RPC,并不是MQ,因此不予学习。那么也就剩下5种。但是其实3、4、5这三种都属于订阅模型,只不过进行路由的方式不同。

6种消息模型具体在其他章节进行介绍

