
- 1你会让你的孩子当程序员吗?_程序员的坏处
- 2java多线程模拟12306售票(北京动力节点Java基础课程第七章多线程作业题其二)_12306座位分配逻辑 java
- 3Mac电脑M1芯片Python环境搭建_mac m1 python 安装 依赖
- 4修改Android开机动画_adb命令修改系统开机画面
- 5用FPGA实现嵌入式微处理器_微处理器与嵌入式fpga
- 6需求管理有什么工具?_需求管理工具
- 7敏捷项目管理SCRUM Master PSM I 2周通关攻略 不过你来找我_psm i 题库
- 8名片识别 php,小程序云开发实战:实现 AI 智能名片识别小程序
- 9Cause: java.sql.SQLSyntaxErrorException: Unknown column ‘***_id‘ in ‘field list‘
- 10HCIA-AI
7 Series FPGAs Integrated Block for PCI Express IP核中基于64位事务层接口的AXI4-Stream接口设计(三)
赞
踩
在PCIe通信中,Inbound Packets(入站数据包)是从PCIe设备(通常是Endpoint,即EP)发送到主机系统(通常是Root Complex,即RC)的数据包。这些数据包通常包含设备发送到主机内存的数据,或者是设备对主机发出的请求或中断的响应。
1 Basic TLP Receive Operation
接收入站数据包(Inbound Packets)的基本TLP接收操作涉及到AXI4-Stream接口信号的一系列事件。为了使端点IP核(Endpoint core)能够将TLP呈现给用户应用逻辑,接收AXI4-Stream接口上必须发生以下事件序列:
-
当用户应用准备好接收数据时,它会断言
m_axis_rx_tready信号。 -
当IP核准备好传输数据时,它会断言
m_axis_rx_tvalid信号,并在m_axis_rx_tdata[63:0]上呈现第一个完整的TLP QWORD(Quad Word,128位)。 -
IP核保持
m_axis_rx_tvalid信号断言状态,并在随后的时钟周期(只要用户应用逻辑断言m_axis_rx_tready)上在m_axis_rx_tdata[63:0]上呈现TLP的其余QWORDs。 -
当到达TLP的最后一个QWORD或DWORD时,IP核会断言
m_axis_rx_tvalid和m_axis_rx_tlast信号,并在m_axis_rx_tdata[63:0]上呈现最后一个QWORD(如果整个QWORD都是数据)或者仅呈现最后一个DWORD(如果QWORD的剩余部分不是有效数据)。同时,m_axis_rx_tkeep信号将指示哪些字节是有效的。如果最后一个QWORD的所有字节都是有效的,m_axis_rx_tkeep将是0xFF;如果只有最后一个DWORD(32位)是有效的,m_axis_rx_tkeep将是0x0F。 -
如果在下一个时钟周期没有更多的TLP可用,IP核将取消断言
m_axis_rx_tvalid信号,以表示m_axis_rx_tdata[63:0]上的有效传输结束。
注意:用户应用应该仅在m_axis_rx_tvalid信号同时被断言时,才关注m_axis_rx_tlast、m_axis_rx_tkeep和m_axis_rx_tdata的断言。在数据包传输过程中,m_axis_rx_tvalid信号永远不会在包中间被取消断言。
当PCIe IP核断言m_axis_rx_tlast信号时,这通常表示当前传输的TLP(Transaction Layer Packet)的最后一个数据段或数据包本身已经到达。Figure 3-15展示了一个没有数据负载的3-DW(Double Word,即32位)TLP头,是32位地址可寻址的内存读取请求(Memory Read request)。
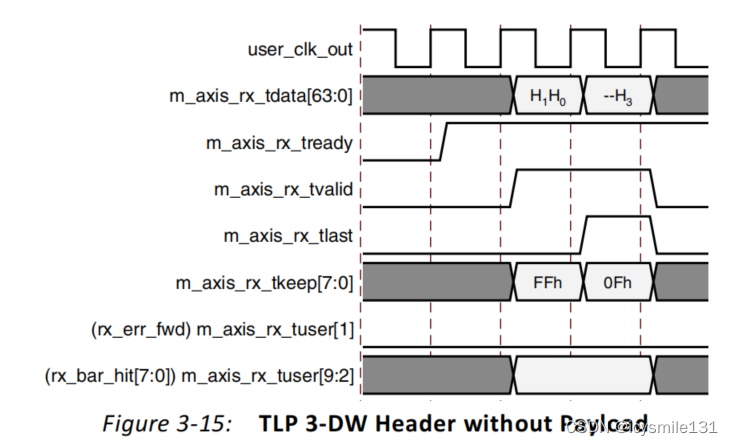
对于这样的请求,由于它仅包含头部信息而没有数据负载,当IP核完成头部的传输时,它会断言m_axis_rx_tlast来指示TLP的结束。同时,m_axis_rx_tvalid信号会在传输过程中被持续断言,直到m_axis_rx_tlast被断言。
在图3-16中,展示了一个没有数据负载的4-DW(Double Word,即64位)TLP(Transaction Layer Packet)头部,该TLP是一个64位地址可寻址的内存读取请求(Memory Read request)。当PCIe IP核断言m_axis_rx_tlast信号时,它还在m_axis_rx_tkeep上放置了一个0xFF的值,以通知你m_axis_rx_tdata[63:0]包含了有效的数据。
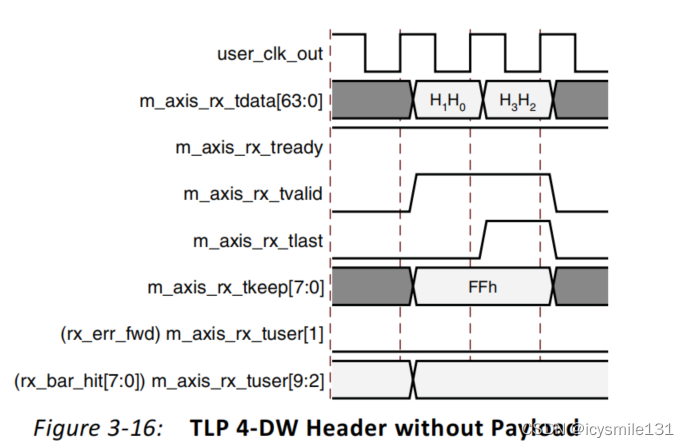
m_axis_rx_tkeep信号用于指示m_axis_rx_tdata总线上的哪些字节是有效的。对于一个64位(即4-DW)的数据传输,m_axis_rx_tkeep上的0xFF值意味着m_axis_rx_tdata[63:0]上的所有64位都是有效的。
Figure 3-17展示了一个带有数据负载的3-DW(Double Word,即32位x3 = 96位)TLP头部,该TLP是一个32位地址可寻址的内存写入请求(Memory Write request)。
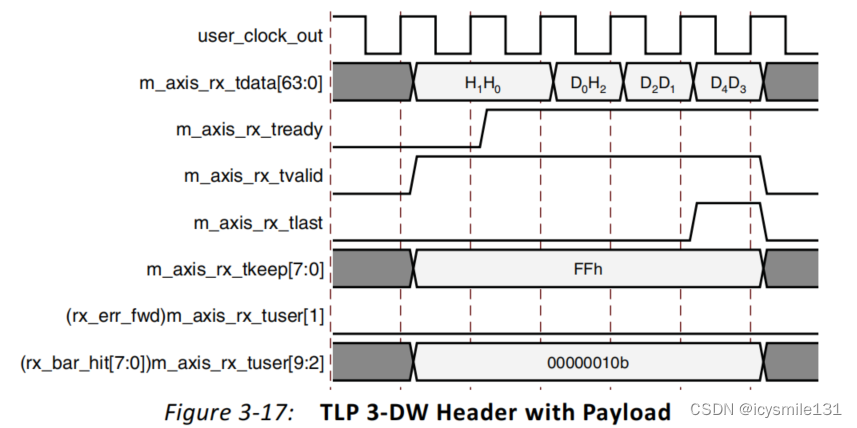
当TLP的最后一个Double Word(无论是头部、数据负载还是CRC)被传输时,IP心会断言m_axis_rx_tlast来指示TLP的结束。在这个Double Word上,m_axis_rx_tkeep将被设置为0xFF(如果整个Double Word都是有效的),或者设置为一个较低的值(如果只有部分字节是有效的)。
用户应用逻辑可以检查m_axis_rx_tlast和m_axis_rx_tkeep信号来确定TLP的结束以及每个Double Word的有效字节。
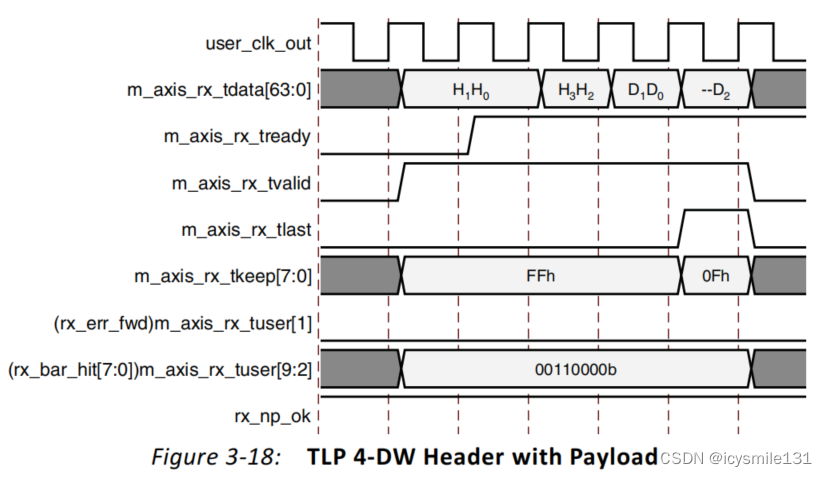
Figure 3-18展示了一个带有数据负载的4-DW(Double Word,即64位x4 = 256位)TLP(Transaction Layer Packet)头部,该TLP是64位地址可寻址的内存写入请求(Memory Write request)。然而,当IP核断言m_axis_rx_tlast时,它在m_axis_rx_tkeep上放置了一个0x0F的值,这表示m_axis_rx_tdata[63:0]中的低32位(即m_axis_rx_tdata[31:0])包含有效数据,而高32位是无效的。
在PCIe通信中,m_axis_rx_tkeep信号通常用于指示在m_axis_rx_tdata上的哪些字节是有效的。在这个例子中,由于m_axis_rx_tkeep被设置为0x0F(二进制为00001111),这意味着在64位的数据总线m_axis_rx_tdata[63:0]中,只有最低的4个字节(32位)是有效的。
2 Packet Re-ordering on Receive Interface
在PCIe的接收接口上,数据包重排序(Packet Re-ordering)是遵循PCI Express基础规范第2章中描述的PCI事务排序规则来处理的。这些排序规则确保了Posted(已发布)和Completion(完成)TLPs(传输层数据包)能够绕过被阻塞的Non-Posted(非发布)TLPs。为了有效管理接收端的Non-Posted Buffer空间,PCIe核心提供了两种机制:
- 接收Non-Posted节流(Receive Non-Posted Throttling):
使用rx_np_ok信号来防止IP核在rx_np_ok信号被取消断言后呈现超过两个Non-Posted请求。
- 接收Non-Posted请求(Receive Request for Non-Posted):
允许用户通过rx_np_req信号控制Non-Posted队列的流量控制。
接收Non-Posted节流机制假设用户应用通常在其接收端有足够的空间来接收Non-Posted TLPs,并且用户应用会专门针对Non-Posted请求对IP核进行节流。而接收Non-Posted请求(Receive Request for Non-Posted)机制则假设用户应用在其接收端有空间时请求IP核呈现一个Non-Posted TLP。
这两种机制是互斥的,一个设计中只能激活一个。这个选项必须在生成和定制PCIe IP核时进行选择。如果在高级设置中选择了接收Non-Posted请求选项,那么接收Non-Posted请求机制将被启用,并且任何对rx_np_ok信号的断言/取消断言都将被忽略,反之亦然。
在生成和定制PCIe IP核时,必须选择这个选项。如果在高级设置中选择了“接收Non-Posted请求”(Receive Non-Posted Request)选项,那么“接收请求以获取Non-Posted TLP”的机制将被启用。此时,任何对rx_np_ok信号的断言(assertion)或取消断言(deassertion)都将被忽略,反之亦然。
2.1 Receive Non-Posted Throttling (Receive Non-Posted Request Disabled,
TRN_ NP_ FC attribute FALSE)
如果用户应用能够接收来自IP核的Posted和Completion事务,但尚未准备好接受Non-Posted事务,用户应用可以取消断言rx_np_ok信号,如图3-22所示。用户应用必须在它能够接受的倒数第二个Non-Posted TLP的m_axis_rx_tlast之前的至少两个时钟周期内取消断言rx_np_ok。
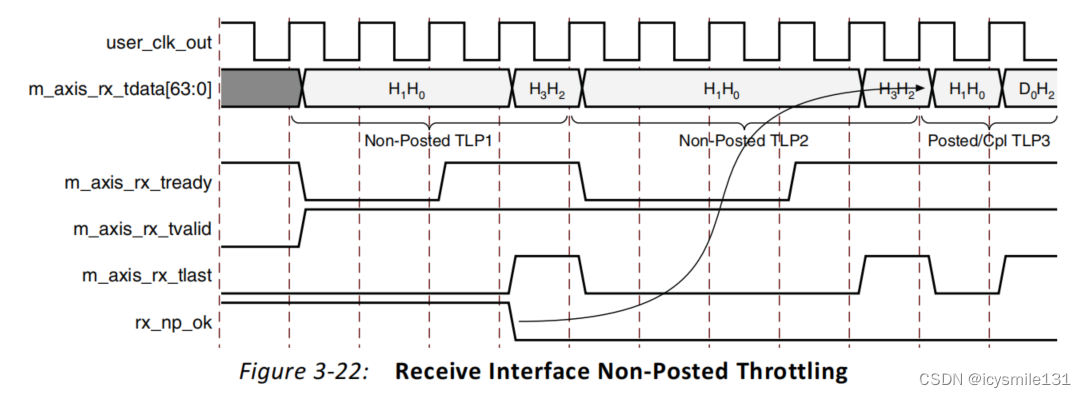
在rx_np_ok被取消断言期间,接收到的Posted和Completion事务将绕过Non-Posted事务继续传递。当用户应用准备好接受Non-Posted事务时,它必须重新断言rx_np_ok。之前被绕过的Non-Posted事务将在其他接收到的TLP之前呈现给用户应用。
对于rx_np_ok可以取消断言的时间长度没有限制;但是,你必须注意不要长时间取消断言rx_np_ok,因为这可能导致请求者(Requester)中的完成超时。
数据包重新排序(Packet re-ordering)允许用户应用优化Non-Posted TLPs的处理速率,同时以非阻塞的方式继续接收和处理Posted和Completion TLPs。rx_np_ok信号的限制要求用户应用能够接收并缓冲至少三个Non-Posted TLPs。以下算法描述了管理Non-Posted TLP缓冲区的过程:
假设Non-Posted_Buffers_Available表示用户应用可用的Non-Posted缓冲区空间的大小。Non-Posted缓冲区空间的大小大于三个Non-Posted TLPs。当从IP核接收Non-Posted TLP进行处理时,Non-Posted_Buffers_Available会递减;当用户应用处理完Non-Posted TLP并释放缓冲区时,Non-Posted_Buffers_Available会递增。
- For every clock cycle do {
- if (Non-Posted_Buffers_Available <= 3) {
- if (Valid transaction Start-of-Frame accepted by user application) {
- Extract TLP Format and Type from the 1st TLP DW
- if (TLP type == Non-Posted) {
- Deassert rx_np_ok on the following clock cycle
- - or -
- Other optional user policies to stall NP transactions
- } else {
- }
- }
- } else { // Non-Posted_Buffers_Available > 3
- Assert rx_np_ok on the following clock cycle.
- }
- }
2.2 Receive Request for Non-Posted (Receive Non-Posted Request Enabled,
TRN_ NP_ FC attribute TRUE)
The 7 Series FPGAs Integrated Block for PCI Express IP核允许用户应用通过rx_np_req信号来控制Non-Posted队列的流控信用返回。当用户应用的接收器中有空间可以接收一个Non-Posted事务时,它必须为每个用户应用可以接受的Non-Posted事务断言rx_np_req一个时钟周期。这允许集成模块从其接收队列中向核心事务接口呈现一个Non-Posted事务,如图3-23所示,并向连接的链路伙伴返回一个Non-Posted信用。
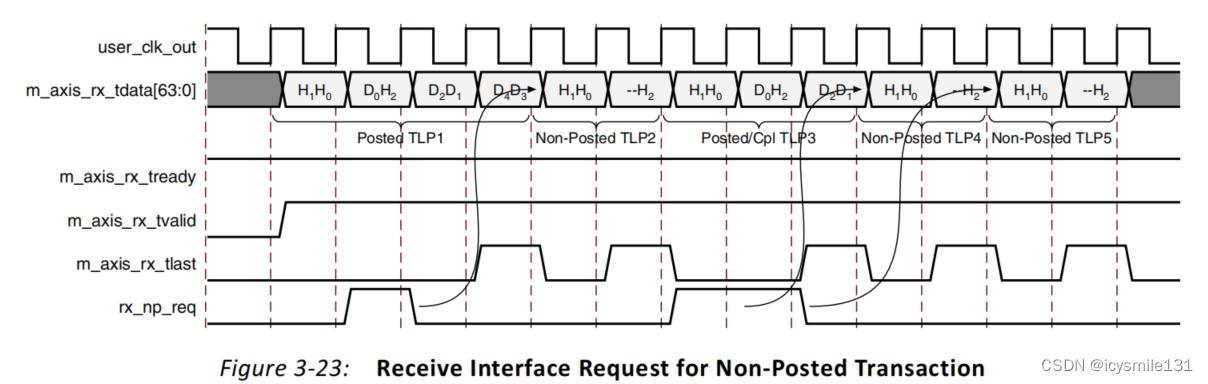
PCIe IP核维护了一个计数,记录了来自用户应用的最多12个Non-Posted请求。换句话说,即使接收缓冲区中没有Non-Posted TLPs,IP核也会记住rx_np_req的断言,并在用户应用之前发出请求时,将接收到的Non-Posted TLPs呈现给用户应用。
如果IP核没有来自用户应用的未决请求,而接收缓冲区中有等待的Non-Posted TLPs,那么接收到的Posted和Completion事务将绕过等待的Non-Posted事务。
当用户应用准备好接受一个Non-Posted TLP时,断言rx_np_req一个或多个时钟周期会导致在下一个可用的TLP边界处交付相应数量的等待中的Non-Posted TLPs。换句话说,当前在用户应用接口上的任何Posted或Completion TLP都会在等待的Non-Posted TLPs呈现给用户应用之前完成。如果没有Posted或Completion TLPs,而有一个Non-Posted TLP在等待,断言rx_np_req会导致该Non-Posted TLP呈现给用户应用。
除了限制Non-Posted TLPs的速率以允许Posted和Completion TLPs通过外,TLPs将按顺序交付给用户应用。当用户应用再次开始接受Non-Posted TLPs时,随后的Posted或Completion TLPs仍将保持有序。
如果用户应用可以立即接受所有接收到的Non-Posted事务,并且不关心控制Non-Posted队列的流控信用返回,那么可以将此信号保持断言状态。
通过适当管理rx_np_req信号,用户应用可以有效地控制Non-Posted事务的接收速率,并在需要时与其他类型的事务保持有序性。


