
- 1深度解析自然语言处理(NLP)技术_自然语言技术原理剖析
- 2c语言 字母的序号_输入一个英文字母(可能是大写,也可能是小写),输出该字母在字母表中的序号(’a’和
- 3SQL数据库_数据库中standard.
- 4ChatGpt大模型入门_lainchain 大模型
- 5opencv的使用_argc == 2? cvloadimage(argv[1]) : 0;
- 6ChatGPT真的能替代程序员吗?_chatgpt能代替程序员吗
- 7HDFS 教程(超详细)_hdfs count
- 8网闸也不安全 中情局用“野蛮袋鼠”就能***内网
- 9MongoDB分布式部署方式
- 10HNU-电子测试平台与工具-无线RGB彩灯工程_pcb板 hnu
python入门经典代码-python经典入门学习锦集就这篇够了,强烈建议收藏!
赞
踩
原标题:python经典入门学习锦集就这篇够了,强烈建议收藏!

Python 简介
Python 是一种高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。Python 由 Guido van Rossum 于 1989 年底在荷兰国家数学和计算机科学研究所发明,第一个公开发行版发行于 1991 年。
Python 特点
易于学习:Python 有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
易于阅读:Python 代码定义的更清晰。
易于维护:Python 的成功在于它的源代码是相当容易维护的。
一个广泛的标准库:Python 的最大的优势之一是丰富的库,跨平台的,在 UNIX,Windows 和 macOS 兼容很好。
互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
可移植:基于其开放源代码的特性,Python 已经被移植(也就是使其工作)到许多平台。
可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用 C 或 C++ 完成那部分程序,然后从你的 Python 程序中调用。
数据库:Python 提供所有主要的商业数据库的接口。
GUI 编程:Python 支持 GUI 可以创建和移植到许多系统调用。
可嵌入:你可以将 Python 嵌入到 C/C++ 程序,让你的程序的用户获得”脚本化”的能力。
面向对象:Python 是强面向对象的语言,程序中任何内容统称为对象,包括数字、字符串、函数等。
Python 基础语法
运行 Python
交互式解释器
在命令行窗口执行python后,进入 Python 的交互式解释器。exit 或 Ctrl + D 组合键退出交互式解释器。
python学习关注企鹅qun: 8393 83765 各类入门学习资料免费分享哦!
命令行脚本
在命令行窗口执行python xxx.py,以执行 Python 脚本文件。
指定解释器
如果在 Python 脚本文件首行输入#!/usr/bin/env python,那么可以在命令行窗口中执行/path/to/xxx.py以执行该脚本文件。
注:该方法不支持 Windows 环境。
编码
默认情况下,3.x 源码文件都是 UTF-8 编码,字符串都是 Unicode 字符。也可以手动指定文件编码:
# -*- coding: utf-8 -*-
或者
# encoding: utf-8
注意: 该行标注必须位于文件第一行
标识符
第一个字符必须是英文字母或下划线"_" 。
标识符的其他的部分由字母、数字和下划线组成。
标识符对大小写敏感。
关键字
我们不能把关键字用作任何标识符名称。Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释
单行注释采用#,多行注释采用'''或"""。
# 这是单行注释
'''
这是多行注释
这是多行注释
'''
"""
这也是多行注释
这也是多行注释
"""
行与缩进
Python 最具特色的就是使用缩进来表示代码块,不需要使用大括号 {}。 缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。缩进不一致,会导致运行错误。
多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠来实现多行语句。
total = item_one +
item_two +
item_three
在 , {}, 或 中的多行语句,不需要使用反斜杠。
空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是 Python 语法的一部分。书写时不插入空行,Python 解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
记住:空行也是程序代码的一部分。
等待用户输入
input函数可以实现等待并接收命令行中的用户输入。
content = input("请输入点东西并按 Enter 键")
print(content)
同一行写多条语句
Python 可以在同一行中使用多条语句,语句之间使用分号;分割。
import sys; x = 'hello world'; sys.stdout.write(x + '')
多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号:结束,该行之后的一行或多行代码构成代码组。
我们将首行及后面的代码组称为一个子句(clause)。
print 输出
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上end=""或别的非换行符字符串:
print('123') # 默认换行
print('123', end = "") # 不换行
import 与 from…import
在 Python 用 import 或者 from...import 来导入相应的模块。
将整个模块导入,格式为:import module_name
从某个模块中导入某个函数,格式为:from module_name import func1
从某个模块中导入多个函数,格式为:from module_name import func1, func2, func3
将某个模块中的全部函数导入,格式为:from module_name import *
Python 运算符
算术运算符
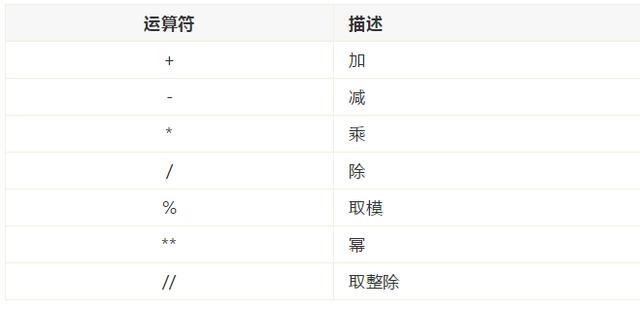
比较运算符
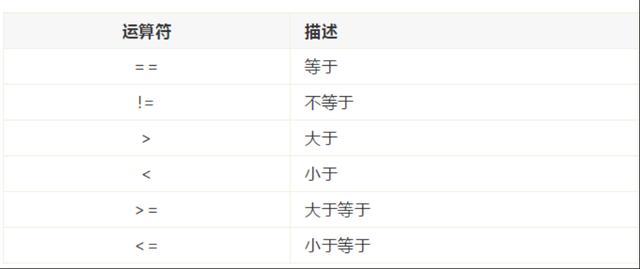
赋值运算符
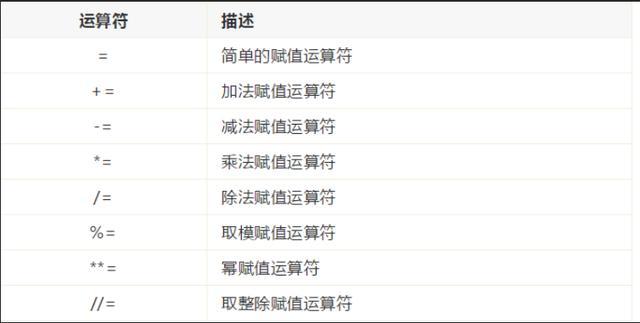
位运算符

逻辑运算符

成员运算符

身份运算符

运算符优先级
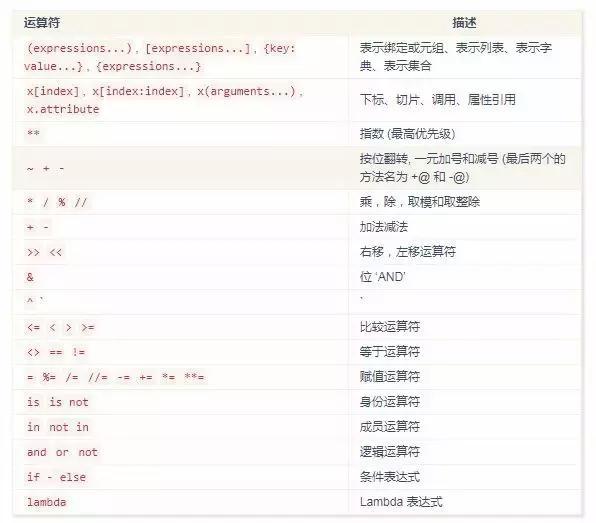
具有相同优先级的运算符将从左至右的方式依次进行。用小括号可以改变运算顺序。
Python 变量
变量在使用前必须先”定义”(即赋予变量一个值),否则会报错(如下图):
>>> name
Traceback (most recent call last):
File "", line 1, in
NameError: name 'name' is not defined
Python 数据类型
布尔(bool)
只有 True 和 False 两个值,表示真或假。
数字(number)
整型(int)
整数值,可正数亦可复数,无小数。 3.x 整型是没有限制大小的,可以当作 Long 类型使用,所以 3.x 没有 2.x 的 Long 类型。
浮点型(float)
浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 10^2 = 250)
复数(complex)
复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示,复数的实部 a 和虚部 b 都是浮点型。
数字运算
不同类型的数字混合运算时会将整数转换为浮点数
在不同的机器上浮点运算的结果可能会不一样
在整数除法中,除法 / 总是返回一个浮点数,如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 //。
// 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系
在交互模式中,最后被输出的表达式结果被赋值给变量 _,_ 是个只读变量
数学函数
注:以下函数的使用,需先导入 math 包。

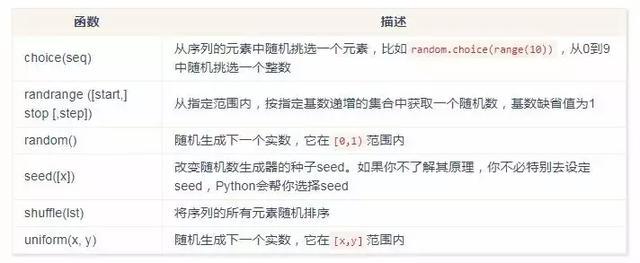
随机数函数
注:以下函数的使用,需先导入 random 包。
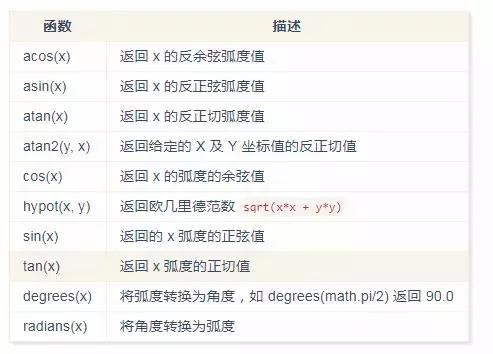
三角函数
注:以下函数的使用,需先导入 math 包。
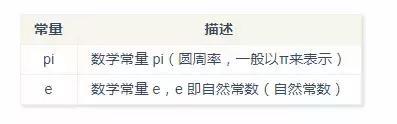
数学常量
字符串(string)
单引号和双引号使用完全相同
使用三引号('''或""")可以指定一个多行字符串
转义符(反斜杠)可以用来转义,使用r可以让反斜杠不发生转义,如r"this is a line with ",则会显示,并不是换行
按字面意义级联字符串,如"this " "is " "string"会被自动转换为this is string
python学习关注企鹅qun: 8393 83765 各类入门学习资料免费分享哦!
字符串可以用 + 运算符连接在一起,用 * 运算符重复
字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始
字符串不能改变
没有单独的字符类型,一个字符就是长度为 1 的字符串
字符串的截取的语法格式如下:变量[头下标:尾下标]
转义字符

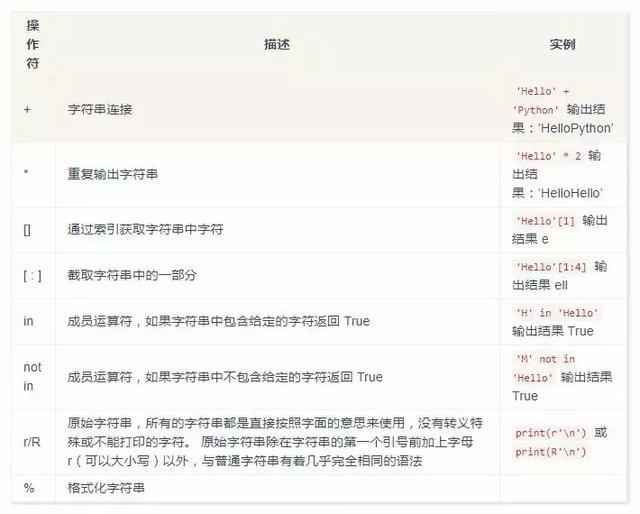
字符串运算符
字符串格式化
在 Python 中,字符串格式化不是 sprintf 函数,而是用 % 符号。例如:
print("我叫%s, 今年 %d 岁!" % ('小明', 10))
// 输出:
我叫小明, 今年 10 岁!
格式化符号:
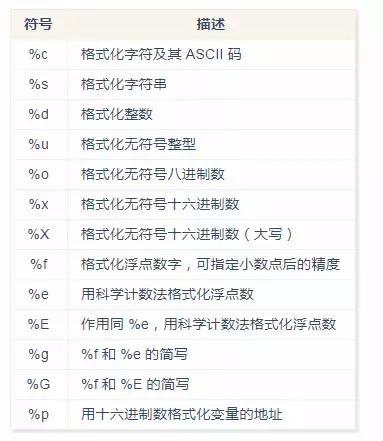
辅助指令:

Python 2.6 开始,新增了一种格式化字符串的函数 str.format,它增强了字符串格式化的功能。
多行字符串
用三引号(''' 或 """)包裹字符串内容
多行字符串内容支持转义符,用法与单双引号一样
三引号包裹的内容,有变量接收或操作即字符串,否则就是多行注释
实例:
string = '''
print(math.fabs(-10))
print(random.choice(li))
'''
print(string)
输出:
print( math.fabs(-10))
print(
random.choice(li))
Unicode
在 2.x 中,普通字符串是以 8 位 ASCII 码进行存储的,而 Unicode 字符串则存储为 16 位 Unicode 字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在 3.x 中,所有的字符串都是 Unicode 字符串。
字符串函数
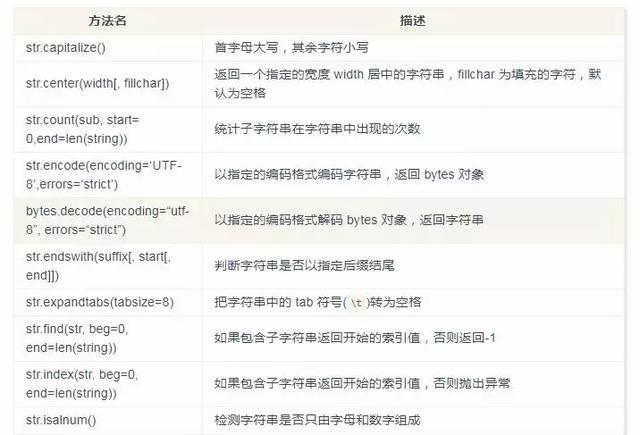
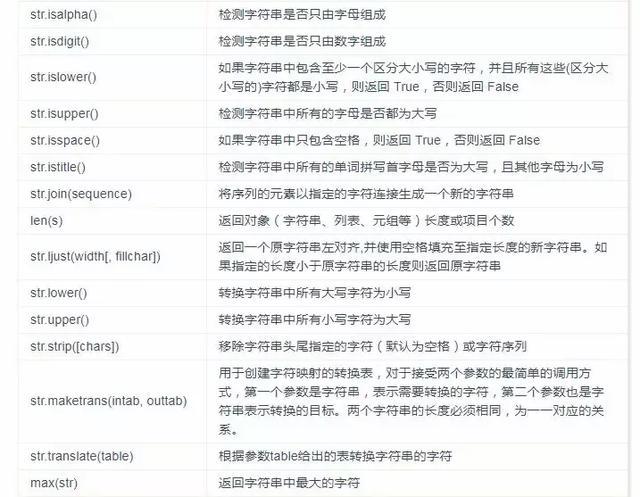
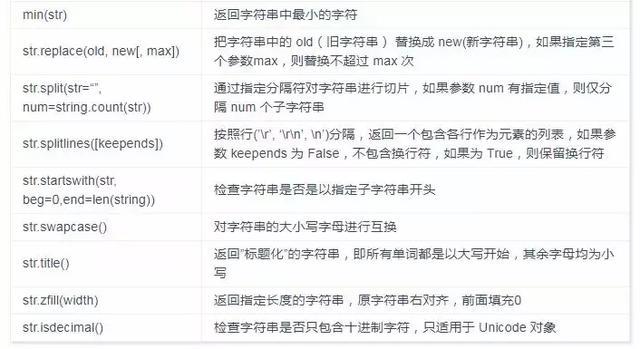
字节(bytes)
在 3.x 中,字符串和二进制数据完全区分开。文本总是 Unicode,由 str 类型表示,二进制数据则由 bytes 类型表示。Python 3 不会以任意隐式的方式混用 str 和 bytes,你不能拼接字符串和字节流,也无法在字节流里搜索字符串(反之亦然),也不能将字符串传入参数为字节流的函数(反之亦然)。
bytes 类型与 str 类型,二者的方法仅有 encode 和 decode 不同。
bytes 类型数据需在常规的 str 类型前加个 b 以示区分,例如 b'abc'。
只有在需要将 str 编码(encode)成 bytes 的时候,比如:通过网络传输数据;或者需要将 bytes 解码(decode)成 str 的时候,我们才会关注 str 和 bytes 的区别。
bytes 转 str:
b'abc'.decode
str(b'abc')
str(b'abc', encoding='utf-8')
str 转 bytes:
'中国'.encode
bytes('中国', encoding='utf-8')
列表(list)
列表是一种无序的、可重复的数据序列,可以随时添加、删除其中的元素。
列表页的每个元素都分配一个数字索引,从 0 开始
列表使用方括号创建,使用逗号分隔元素
列表元素值可以是任意类型,包括变量
使用方括号对列表进行元素访问、切片、修改、删除等操作,开闭合区间为形式
列表的元素访问可以嵌套
方括号内可以是任意表达式
创建列表
hello = (1, 2, 3)
li = [1, "2", [3, 'a'], (1, 3), hello]
访问元素
li = [1, "2", [3, 'a'], (1, 3)]
print(li[3]) # (1, 3)
print(li[-2]) # [3, 'a']
切片访问
格式: list_name[begin:end:step] begin 表示起始位置(默认为0),end 表示结束位置(默认为最后一个元素),step 表示步长(默认为1)
hello = (1, 2, 3)
li = [1, "2", [3, 'a'], (1, 3), hello]
print(li) # [1, '2', [3, 'a'], (1, 3), (1, 2, 3)]
print(li[1:2]) # ['2']
print(li[:2]) # [1, '2']
print(li[:]) # [1, '2', [3, 'a'], (1, 3), (1, 2, 3)]
print(li[2:]) # [[3, 'a'], (1, 3), (1, 2, 3)]
print(li[1:-1:2]) # ['2', (1, 3)]
访问内嵌 list 的元素:
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ['a', 'b', 'c']]
print(li[1:-1:2][1:3]) # (3, 5)
print(li[-1][1:3]) # ['b', 'c']
print(li[-1][1]) # b
修改列表
通过使用方括号,可以非常灵活的对列表的元素进行修改、替换、删除等操作。
li = [0, 1, 2, 3, 4, 5]
li[len(li) - 2] = 22 # 修改 [0, 1, 2, 22, 4, 5]
li[3] = 33 # 修改 [0, 1, 2, 33, 4, 5]
li[1:-1] = [9, 9] # 替换 [0, 9, 9, 5]
li[1:-1] = # 删除 [0, 5]
删除元素
可以用 del 语句来删除列表的指定范围的元素。
li = [0, 1, 2, 3, 4, 5]
del li[3] # [0, 1, 2, 4, 5]
del li[2:-1] # [0, 1, 5]
列表操作符
+ 用于合并列表
* 用于重复列表元素
in 用于判断元素是否存在于列表中
for ... in ... 用于遍历列表元素
[1, 2, 3] + [3, 4, 5] # [1, 2, 3, 3, 4, 5]
[1, 2, 3] * 2 # [1, 2, 3, 1, 2, 3]
3 in [1, 2, 3] # True
for x in [1, 2, 3]: print(x) # 1 2 3
列表函数
len(list) 列表元素个数
max(list) 列表元素中的最大值
min(list) 列表元素中的最小值
list(seq) 将元组转换为列表
li = [0, 1, 5]
max(li) # 5
len(li) # 3
注: 对列表使用 max/min 函数,2.x 中对元素值类型无要求,3.x 则要求元素值类型必须一致。
列表方法
list.append(obj)
在列表末尾添加新的对象
list.count(obj)
返回元素在列表中出现的次数
list.extend(seq)
在列表末尾一次性追加另一个序列中的多个值
list.index(obj)
返回查找对象的索引位置,如果没有找到对象则抛出异常
list.insert(index, obj)
将指定对象插入列表的指定位置
list.pop([index=-1]])
移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
list.remove(obj)
移除列表中某个值的第一个匹配项
list.reverse
反向排序列表的元素
list.sort(cmp=None, key=None, reverse=False)
对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数
list.clear
清空列表 还可以使用 del list[:]、li = 等方式实现
list.copy
复制列表 默认使用等号赋值给另一个变量,实际上是引用列表变量。如果要实现
python学习关注企鹅qun: 8393 83765 各类入门学习资料免费分享哦!
列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。
每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
将列表中每个数值乘三,获得一个新的列表:
vec = [2, 4, 6]
[(x, x**2) for x in vec]
# [(2, 4), (4, 16), (6, 36)]
对序列里每一个元素逐个调用某方法:
freshfruit = [' banana', ' loganberry ', 'passion fruit ']
[weapon.strip for weapon in freshfruit]
# ['banana', 'loganberry', 'passion fruit']
用 if 子句作为过滤器:
vec = [2, 4, 6]
[3*x for x in vec if x > 3]
# [12, 18]
vec1 = [2, 4, 6]
vec2 = [4, 3, -9]
[x*y for x in vec1 for y in vec2]
# [8, 6, -18, 16, 12, -36, 24, 18, -54]
[vec1[i]*vec2[i] for i in range(len(vec1))]
# [8, 12, -54]
列表嵌套解析:
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
new_matrix = [[row[i] for row in matrix] for i in range(len(matrix[0]))]
print(new_matrix)
# [[1, 4, 7], [2, 5, 8], [3, 6, 9]]
元组(tuple)
元组与列表类似,不同之处在于元组的元素不能修改
元组使用小括号,列表使用方括号
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
没有 append,insert 这样进行修改的方法,其他方法都与列表一样
字典中的键必须是唯一的同时不可变的,值则没有限制
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用
访问元组
访问元组的方式与列表是一致的。 元组的元素可以直接赋值给多个变量,但变量数必须与元素数量一致。
a, b, c = (1, 2, 3)
print(a, b, c)
组合元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz')
tup3 = tup1 + tup2;
print (tup3)
# (12, 34.56, 'abc', 'xyz')
删除元组
元组中的元素值是不允许删除的,但我们可以使用 del 语句来删除整个元组
元组函数
len(tuple) 元组元素个数
max(tuple) 元组元素中的最大值
min(tuple) 元组元素中的最小值
tuple(tuple) 将列表转换为元组
元组推导式
t = 1, 2, 3
print(t)
# (1, 2, 3)
u = t, (3, 4, 5)
print(u)
# ((1, 2, 3), (3, 4, 5))
字典(dict)
字典是另一种可变容器模型,可存储任意类型对象
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号分割,整个字典包括在花括号({})中
键必须是唯一的,但值则不必
值可以是任意数据类型
键必须是不可变的,例如:数字、字符串、元组可以,但列表就不行
如果用字典里没有的键访问数据,会报错
字典的元素没有顺序,不能通过下标引用元素,通过键来引用
字典内部存放的顺序和 key 放入的顺序是没有关系的
格式如下:
d = {key1 : value1, key2 : value2 }
访问字典
dis = {'a': 1, 'b': [1, 2, 3]}
print(dis['b'][2])
修改字典
dis = {'a': 1, 'b': [1, 2, 3], 9: {'name': 'hello'}}
dis[9]['name'] = 999
print(dis)
# {'a': 1, 9: {'name': 999}, 'b': [1, 2, 3]}
删除字典
用 del 语句删除字典或字典的元素。
dis = {'a': 1, 'b': [1, 2, 3], 9: {'name': 'hello'}}
del dis[9]['name']
print(dis)
del dis # 删除字典
# {'a': 1, 9: {}, 'b': [1, 2, 3]}
字典函数
len(dict) 计算字典元素个数,即键的总数
str(dict) 输出字典,以可打印的字符串表示
type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型
key in dict 判断键是否存在于字典中
字典方法
dict.clear
删除字典内所有元素
dict.copy
返回一个字典的浅复制
dict.fromkeys(seq[, value])
创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值
dict.get(key, default=None)
返回指定键的值,如果值不在字典中返回默认值
dict.items
以列表形式返回可遍历的(键, 值)元组数组
dict.keys
以列表返回一个字典所有的键
dict.values
以列表返回字典中的所有值
dict.setdefault(key, default=None)
如果 key 在字典中,返回对应的值。如果不在字典中,则插入 key 及设置的默认值 default,并返回 default ,default 默认值为 None。
dict.update(dict2)
把字典参数 dict2 的键/值对更新到字典 dict 里
dic1 = {'a': 'a'}
dic2 = {9: 9, 'a': 'b'}
dic1.update(dic2)
print(dic1)
# {'a': 'b', 9: 9}
dict.pop(key[,default])
删除字典给定键 key 所对应的值,返回值为被删除的值。key 值必须给出,否则返回 default 值。
dict.popitem
随机返回并删除字典中的一对键和值(一般删除末尾对)
字典推导式
构造函数 dict 直接从键值对元组列表中构建字典。如果有固定的模式,列表推导式指定特定的键值对:
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'jack': 4098, 'guido': 4127}
此外,字典推导可以用来创建任意键和值的表达式词典:
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
如果关键字只是简单的字符串,使用关键字参数指定键值对有时候更方便:
>>> dict(sape=4139, guido=4127, jack=4098)
{'sape': 4139, 'jack': 4098, 'guido': 4127}
集合(set)
集合是一个无序不重复元素的序列
创建集合
可以使用大括号 {} 或者 set 函数创建集合
创建一个空集合必须用 set 而不是 {},因为 {} 是用来创建一个空字典
set(value) 方式创建集合,value 可以是字符串、列表、元组、字典等序列类型
创建、添加、修改等操作,集合会自动去重
{1, 2, 1, 3} # {} {1, 2, 3}
set('12345') # 字符串 {'3', '5', '4', '2', '1'}
set([1, 'a', 23.4]) # 列表 {1, 'a', 23.4}
set((1, 'a', 23.4)) # 元组 {1, 'a', 23.4}
set({1:1, 'b': 9}) # 字典 {1, 'b'}
添加元素
将元素 val 添加到集合 set 中,如果元素已存在,则不进行任何操作:
set.add(val)
也可以用 update 方法批量添加元素,参数可以是列表,元组,字典等:
set.update(list1, list2,...)
移除元素
如果存在元素 val 则移除,不存在就报错:
set.remove(val)
如果存在元素 val 则移除,不存在也不会报错:
set.discard(val)
随机移除一个元素:
set.pop
元素个数
与其他序列一样,可以用 len(set) 获取集合的元素个数。
清空集合
set.clear
set = set
判断元素是否存在
val in set
其他方法
set.copy
复制集合
set.difference(set2)
求差集,在 set 中却不在 set2 中
set.intersection(set2)
求交集,同时存在于 set 和 set2 中
set.union(set2)
求并集,所有 set 和 set2 的元素
set.symmetric_difference(set2)
求对称差集,不同时出现在两个集合中的元素
set.isdisjoint(set2)
如果两个集合没有相同的元素,返回 True
set.issubset(set2)
如果 set 是 set2 的一个子集,返回 True
set.issuperset(set2)
如果 set 是 set2 的一个超集,返回 True
集合计算
a = set('abracadabra')
b = set('alacazam')
print(a) # a 中唯一的字母
# {'a', 'r', 'b', 'c', 'd'}
print(a - b) # 在 a 中的字母,但不在 b 中
# {'r', 'd', 'b'}
print(a | b) # 在 a 或 b 中的字母
# {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
print(a & b) # 在 a 和 b 中都有的字母
# {'a', 'c'}
print(a ^ b) # 在 a 或 b 中的字母,但不同时在 a 和 b 中
# {'r', 'd', 'b', 'm', 'z', 'l'}
集合推导式
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a)
# {'d', 'r'}
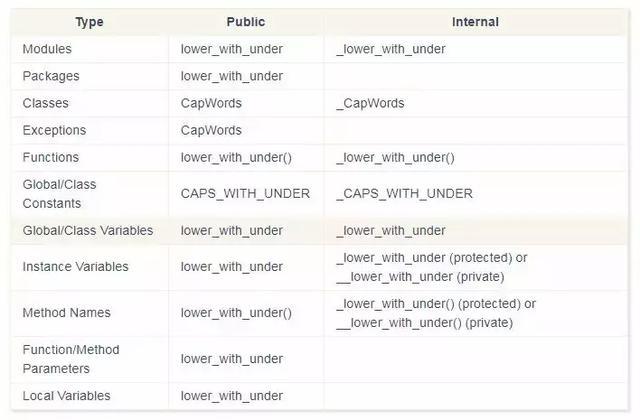
命名规范
好了,到最后了,我们来看看Python语言的命名规范吧--来自Python 之父 Guido 的推荐
最后,觉得本文对你有所帮助,别忘了记得分享哦!
注:python学习关注我们企鹅qun: 8393 83765 各类入门学习资料免费分享哦!返回搜狐,查看更多
责任编辑:

