
- 1Java面试题太多记不住?这个小技巧你值得拥有_java面试题太多背不下来
- 22022最新VMware虚拟机下载·Linux系统装配·镜像文件下载·联网使用一条龙--------希望可以帮到你们_vmware镜像文件下载
- 3[Unity优化]UGUI图集的使用_ugui的图集需要放入resources么
- 4mac系统 sublime 安装 pretty json 插件以及热键_mac sublime json beauty
- 5Python版开心消消乐来了,你能通关吗?_python消消乐
- 6本科论文查重会检测AI辅写疑似度吗?从七个方面为你揭秘!_本科论文查aigc吗
- 7轻松管理基于 RAG 的知识库!RBAC 的最佳实践来了_rag知识库
- 8【GitHub项目推荐--5个最佳开源免费的ERP系统,接活赚钱拿去改改!】【转载】_开源erp
- 9git 撤销merge_Git与GitHub入门笔记
- 10visionPro通过网线连接海康相机踩过的坑_visionpro支持海康相机吗
Transformer原理详解和代码_transformer代码实现
赞
踩
Transformer背景
Transformer是一种Encoder-Decoder结构的NLP模型,在模型通过self-attention机制代替了循环神经网络和卷积网络,有效缓解了长序列首尾信息难以交互和序列模型无法并行推理的问题。Transformer在许多语言任务上都有良好的表现。它的出现加快了深度学习的发展,不仅在自然语言领域有着良好的表现,且在计算机视觉领域也取得了良好的成效。(transformer出自于《Attention Is All You Need》)
Transformer结构和相应的代码
Transformer是一个Encoder-Decoder的结构。模型引入了Positional Encoding,用于描述Embedding向量的位置,使序列中不同位置的向量具有空间上的联系。模型使用了Multi-Head Attention替代了循环神经网络的结构,使模型具备并行推理的能力。同时模型也使用了残差连接,用于保留原数据的信息,同时也防止随着模型层数的增加产生梯度消失的现象。具体的模型结构见下图
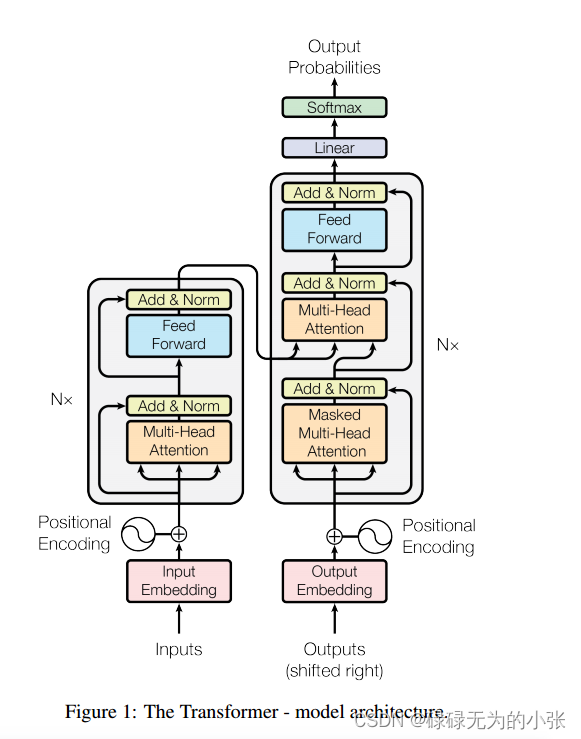
Positional Encoding (位置编码)
位置编码是transformer的亮点之一,它使用了正弦和余弦函数来描述了序列中不同token之间的位置信息。由于正弦函数和余弦函数自身具有一个优良的性质,即函数 s i n ( x ) sin(x) sin(x)与 s i n ( x + k ) sin(x+k) sin(x+k)之间的距离可以通过线性函数描述出来( sin ( x + k ) = sin x cos k + cos x sin k = ( sin x , cos x ) ⋅ ( cos k , sin k ) T \sin(x+k)=\sin x\cos k+\cos x \sin k=(\sin x,\cos x)\cdot (\cos k,\sin k)^{T} sin(x+k)=sinxcosk+cosxsink=(sinx,cosx)⋅(cosk,sink)T),较好的描述了不同位置之间的关系。
位置函数定义如下
P
E
(
p
o
s
,
2
i
)
=
sin
(
p
o
s
1000
0
2
i
/
d
m
o
d
e
l
)
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
(
p
o
s
1000
0
2
i
/
d
m
o
d
e
l
)
其中 p o s ( p o s ∈ [ 0 , m a x _ l e n ) ) pos(pos\in [0,max\_len)) pos(pos∈[0,max_len))是指token在序列中的位置; d m o d e l d_{model} dmodel是指embedding的长度, 2 i 2i 2i和 2 i + 1 2i+1 2i+1是分别指在embedding中的奇偶位置,即 P E ( p o s , k ) PE(pos,k) PE(pos,k)是指第 p o s pos pos个token的第 k k k个变量。
所以positional encoding的代码实现如下(参考pytorch文档中的实现方式)
class PositionalEncoding(nn.Module):
def __init__(self,d_model,max_len=5000):
super().__init__()
pe = torch.zeros(max_len,d_model) #生成PE向量
position = torch.arange(0,max_len,dtype=torch.float).unsqueeze(1) #生成位置向量,pe是二维的所以position也生成二维
div_term = torch.exp(torch.arange(0,d_model,2).float()*(-math.log(10000))/d_model) #这里是对分母做了对数变换
pe[:,::2] = torch.sin(position*div_term) #偶数位置
pe[:,1::2] = torch.cos(position*div_term) #奇数位置
self.register_buffer("pe",pe,persistent=False)
def forward(self,x):
x = x+self.pe[None,:,:] #第一维留给batch
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
对于上述的代码,可能还存在一个问题就是位置向量直接与embedding叠加了。人们主观上认为叠加并不能体现位置变量的特点,但是向量和向量之间叠加在几何意义是从俩个方向向量合成了一个方向向量,所以它们是具有空间特性在的(此处说明不严谨,但比较好理解)。
Multi Head Attention(多头注意力机制)
多头注意力机制是transformer的主要创新点,它摒弃了传统卷积神经网络和神经网络的思想,通过 Scaled Dot-Product Attention实现了信息交互,但一次性使用scle dot attention对计算机计算和信息交互而言效果并不好,所以对embedding向量进行映射,映射为等长的向量。对每个向量使用 Scaled Dot-Product Attention
,最后进行合并输出。这里我们将每个注意力计算称为一个注意力机制头,所以就有了多头注意力。
多头注意力机制中包含了三种,分别是self-attention(自注意力机制)、cross-attention(交叉注意机制)和masked self attention(掩码自注意力机制)。
Scaled Dot-Product Attention
Scaled Dot-Product Attention是计算注意力的核心,它引入了三个变量
q
u
e
r
y
query
query、
k
e
y
key
key和
v
a
l
u
e
value
value,结构见下图。

可以发现其实 Scaled Dot-Product Attention的结构与attention的思想是相似,通过计算attention score输出value,从而确定value各个变量值得关注的地方。具体公式如下
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V
Attention(Q,K,V)=softmax(dk
QKT)V
其中 d k d_{k} dk是指向量映射后每个头的向量长度。
从公式中我们可以发现
Q
Q
Q和
K
K
K相乘后是可以直接softmax的,但是
Q
Q
Q和
K
K
K的相乘类似于
d
k
d_{k}
dk个标准正太分布相加,所以它们的服从于
N
(
0
,
d
k
)
N(0,d_{k})
N(0,dk),这里我们一般要对其进行标准化处理,防止数据方差过大。标准化公式为
s
c
a
l
e
(
Q
K
T
)
=
Q
K
T
−
0
(
d
k
)
=
Q
K
T
d
k
scale(QK^{T}) = \frac{QK^{T}-0}{\sqrt(d_{k})} = \frac{QK^{T}}{\sqrt{d_{k}}}
scale(QKT)=(
dk)QKT−0=dk
QKT
实现的代码见下
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super().__init__()
self.softmax = nn.Softmax(dim=-1) #对最后一维进行softmax
def forward(self,q,k,v,mask=None,e=1e-12):
d_k = q.size(-1)
attn_score = torch.matmul(q,k.permute(0,1,3,2))/math.sqrt(d_k) #shape:[B,num_head,seq_len,seq_len]
attn_score = self.softmax(attn_score) #对每行就行softmax,最后一个维度是需要softmax
if mask is not None:
attn_score = attn_score.masked_fill(mask==0,-9e15)
output = torch.matmul(attn_score,v) #shape:[B,num_head,seq_len,head_dim]
return output,attn_score
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
多头注意力机制
有了scaled-dot-product attention的基础,理解多头注意力基础就简单了。多头注意力的结构见下图
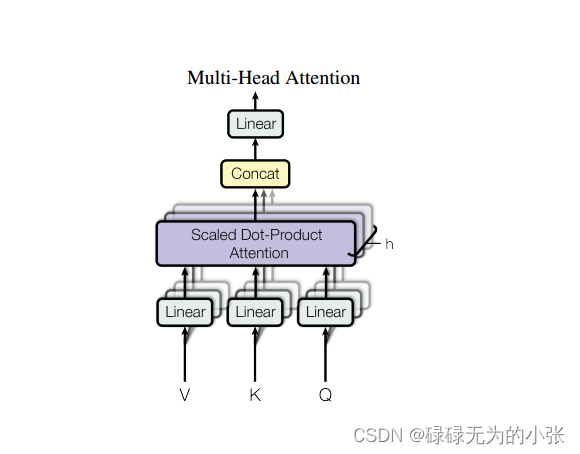
从结构图中,我们可以看到多个 Scaled dot-product attention合并了,然后通过线性层进行输出。同时这里对输入的
Q
Q
Q、
K
K
K和
V
V
V进行了线性变换(输入和输出的维度是一致的,可以认为是为获得更好的QKV才这么设计)。
Muti-Head Attention的定义如下
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
,
⋯
,
h
e
a
d
h
)
MultiHead(Q,K,V) = Concat(head_{1},head_{2},\cdots,head_{h})
MultiHead(Q,K,V)=Concat(head1,head2,⋯,headh)
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
head_{i}=Attention(QW^{Q}_{i},KW^{K}_{i},VW^{V}_{i})
headi=Attention(QWiQ,KWiK,VWiV)
其中
h
h
h为
h
e
a
d
head
head的数量;
W
i
Q
∈
R
d
m
o
d
e
l
×
d
k
W^{Q}_{i}\in R^{d_{model}\times d_{k}}
WiQ∈Rdmodel×dk,
W
i
k
∈
R
d
m
o
d
e
l
×
d
k
W^{k}_{i}\in R^{d_{model}\times d_{k}}
Wik∈Rdmodel×dk,
W
i
V
∈
R
d
m
o
d
e
l
×
d
v
W^{V}_{i}\in R^{d_{model}\times d_{v}}
WiV∈Rdmodel×dv
具体代码如下
class MultiHeadAttention(nn.Module): def __initt__(self,d_model,num_heads): super().__init__() assert d_model//num_heads==0 self.num_head = num_heads self.d_model = d_model self.head_dim = d_model/num_heads self.WQ = nn.Linear(d_model,d_model) #[batch_size,seq_len,embed_dim] self.WK = nn.Linear(d_model,d_model) self.WV = nn.Linear(d_model,d_model) self.linear = nn.Linear(d_model,d_model) self.self_attention = ScaledDotProductAttention() def forward(self,query,key,value,mask =None,return_attention=None): batch_size,seq_len,d_model = query.shape #将向量拆分为多个头 Query = self.WQ(query).view(batch_size,seq_len,self.num_head,-1).permute(0,2,1,3) #[batch_size,seq_len,embed_dim]->[batch_size,seq_len,num_head,head_dim]->[batch_size,num_head,seq_len,head_dim] Key = self.WK(key).view(batch_size,seq_len,self.num_head,-1).permute(0,2,1,3) Value = self.WV(value).view(batch_size,seq_len,self.num_head,-1).permute(0,2,1,3) output,attention_score = self.self_attention(Query,Key,Value,mask=mask) output = output.permute(0,2,1,3).contiguous().view(batch_size,seq_len,d_model) o = self.linear(output) if return_attention is not None: return o,attention_score else: return o

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
根据论文中的转换,我们应当使用多个linear模块进行变换。这里我们将模块合并了,通过一个线性层实现,然后在分别取出属于各个头的向量。
在self-attention和masked self-attention中 Q = K = V = x Q=K=V=x Q=K=V=x,在cross-attention中, Q = x K = V = e n c o u t p u t Q=x \quad K=V=enc_{output} Q=xK=V=encoutput。
PositionwiseFeedForward
在Transformer的结构图中,我们可以发现有一个Feed Forward模块,它就是用于将attention产生的结果送入下一层,这里使用了主要使用了全连接和残差连接。其中残差是用于预防层数过深。其公式如下
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x) = max(0,xW_{1}+b_{1})W_{2}+b_{2}
FFN(x)=max(0,xW1+b1)W2+b2从公式中,我们可以发现,它使用了一个线性层+RELU+线性层。
实现的代码如下
class PositionwiseFeedForward(nn.Module):
def __init__(self,d_model,ffn_dim,drop_prob=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model,ffn_dim)
self.Dropout = nn.Dropout(drop_prob)
self.ReLU = nn.ReLU()
self.linear2 = nn.Linear(ffn_dim,d_model)
def forward(self,x):
x = self.linear1(x)
x = self.ReLU(x)
x = self.Dropout(x)
x = self.linear2(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Mask(掩码机制)
在Transformer中引入了掩码机制,防止Attention计算时关注到生成序列的信息,同时也可以防止生成序列关注到序列PADDING的信息,实现方式是通过将Attention对应的序列位置赋予一个极小的值。代码如下
def make_pad_mask(self,q,k,q_pad_idx,k_pad_idx): #假设输入的向量为[len,batch_size] q,k = q.transpose(1,0),k.transpose(1,0) len_q,len_k = q.size(1),k.size(1) k = k.ne(k_pad_idx).unsqueeze(1).unsqueeze(2) #pad_idx是指padding的序号,即对pad的位置放回false k = k.repeat(1,1,len_q,1) q = q.ne(q_pad_idx).unsqueeze(1).unsqueeze(2) q = q.repeat(1,1,1,len_k) mask = k&q #挑选k_mask和q_mask的并集 return mask def make_no_peak_mask(self,q,k): q,k = q.transpose(1,0),k.transpose(1,0) len_q,len_k = q.size(1),k.size(1) mask = torch.tril(torch.ones(len_q,len_k)).type(torch.BoolTensor) #对需要预测的位置进行mask return mask src_mask = make_pad_mask(src, src, src_pad_idx, src_pad_idx) src_trg_mask = make_pad_mask(trg, src, trg_pad_idx, src_pad_idx) trg_mask = make_pad_mask(trg, trg, trg_pad_idx, trg_pad_idx) * make_no_peak_mask(trg, trg)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
Transformer整体结构

上图展示了Encoder和Decoder的详细结构。对于Encoder而言都是一个self-attention
+FeedForward。对于Decoder而言一个masked-self-attention+cross-attention+feedforward
接下来实现Transformer代码
实现Encoder模块
#Econder layer层 class EncoderLayer(nn.Module): def __init__(self,d_model,feedforward_dim,num_heads,drop_prob): super().__init__() self.multiattention = MultiHeadAttention(d_model,num_heads) self.norm1 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(drop_prob) self.ffn = PositionwiseFeedForward(d_model,feedforward_dim) self.norm2 = nn.LayerNorm(d_model) self.dropout2 = nn.Dropout(drop_prob) def forward(self,x,src_mask): _x = x x = self.multiattention(x,x,x,src_mask) x = self.dropout1(x) x = self.norm1(x+_x) _x = x x = self.ffn(x) x = self.dropout2(x) x = self.norm2(x+_x) return x #N层Encoder layer class Encoder(nn.Module): def __init__(self,enc_voc_size,max_len,d_model,feedforward_dim,num_heads,num_layers,drop_prob): super().__init__() self.embed = TransformerEmbedding(d_model=d_model,max_len=max_len,vocab_size=enc_voc_size,drop_prob=drop_prob) self.layers = nn.ModuleList([EncoderLayer(d_model=d_model,feedforward=feedforward_dim,num_heads=num_heads,drop_prob=drop_prob) for _ in range(num_layers)]) def forward(self,x,src_mask): x = self.embed(x) for layer in self.layers: x = layer(x,src_mask) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
实现Decoder模块
#decoder layer class DecoderLayer(nn.Module): def __init__(self,d_model,feedforward_dim,num_heads,drop_prob): super().__init__() self.multiattention = MultiHeadAttention(d_model,num_heads) self.norm1 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(drop_prob) self.enc_dec_attention = MultiHeadAttention(d_model,num_heads) self.norm2 = nn.LayerNorm(drop_prob) self.dropout2 = nn.Dropout(drop_prob) self.ffn = PositionwiseFeedForward(d_model,feedforward_dim) self.norm3 = nn.LayerNorm(d_model) self.dropout3 = nn.Dropout(drop_prob) def forward(self,dec,enc,trg_mask,src_mask): _x = dec x = self.multiattention(dec,dec,dec,trg_mask) x = self.dropout1(x) x = self.norm1(x+_x) if enc is not None: _x = x x = self.enc_dec_attention(x,enc,enc,src_mask) # query=decoder_input,key=value=encoder_output x = self.dropout2(x) x = self.norm2(x+_x) _x = x x = self.ffn(x) x = self.dropout3(x) output = self.norm3(x+_x) return output #N层decoder layer class Deocoder(nn.Module): def __init__(self,dec_voc_size,max_len,d_model,feedforward_dim,num_heads,num_layers,drop_prob): super().__init__() self.embed = TransformerEmbedding(d_mdoel=d_model,max_len=max_len,vocab_size=dec_voc_size,drop_prob=drop_prob) self.layers = nn.ModuleList([DecoderLayer(d_model,feedforward_dim,num_heads,drop_prob) for _ in num_layers]) self.linear = nn.Linear(d_model,dec_voc_size) def forward(self,trg,src,trg_mask,src_mask): trg = self.embed(trg) for layer in self.layers: trg = layer(trg,src,trg_mask,src_mask) output = self.linear(trg) return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
实现Transformer模块
class Transformer(nn.Module): def __init__(self,src_pad_idx,trg_pad_idx,enc_voc_size,dec_voc_size, d_model,num_heads,max_len,feedforward_dim,num_layers,drop_prob): super().__init__() self.src_pad_idx = src_pad_idx self.trg_pad_idx = trg_pad_idx self.encoder = Encoder(d_model=d_model,num_heads=num_heads,max_len=max_len, feedforward_dim=feedforward_dim,enc_voc_size=enc_voc_size, drop_prob=drop_prob,num_layers=num_layers) self.decoder = Deocoder(d_model=d_model,num_heads=num_heads,max_len=max_len, feedforward_dim=feedforward_dim,dec_voc_size=dec_voc_size, drop_prob=drop_prob,num_layers=num_layers) def forward(self,src,trg): src_mask = self.make_pad_mask(src, src, self.src_pad_idx, self.src_pad_idx) src_trg_mask = self.make_pad_mask(trg, src, self.trg_pad_idx, self.src_pad_idx) trg_mask = self.make_pad_mask(trg, trg, self.trg_pad_idx, self.trg_pad_idx) * self.make_no_peak_mask(trg, trg) enc_src = self.encoder(src, src_mask) output = self.decoder(trg, enc_src, trg_mask, src_trg_mask) return output #将mask机制用在Transformer输入时 def make_pad_mask(self,q,k,q_pad_idx,k_pad_idx): q,k = q.transpose(1,0),k.transpose(1,0) len_q,len_k = q.size(1),k.size(1) k = k.ne(k_pad_idx).unsqueeze(1).unsqueeze(2) k = k.repeat(1,1,len_q,1) q = q.ne(q_pad_idx).unsqueeze(1).unsqueeze(2) q = q.repeat(1,1,1,len_k) mask = k&q return mask def make_no_peak_mask(self,q,k): q,k = q.transpose(1,0),k.transpose(1,0) len_q,len_k = q.size(1),k.size(1) mask = torch.tril(torch.ones(len_q,len_k)).type(torch.BoolTensor) return mask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
Transformer至此整个模型架构就完成了,如果上述中存在错误,请指正, 后续再整理把整个模型的训练代码。
Transfomrer目前的火热主要来源于其self-attention,它的设计非常符合人类,许多transformer的变体也是基于self-attention的基础上,进行各种的变换。

