- 1SpringAOP的实现原理_spring aop 实现原理
- 2可以说今年最详细的面试要点!耗时两个礼拜,五章8000字面试长文,写简历—阿里Offer一步到位!(2)
- 3meta-data android,AndroidManifest meta-data 知识介绍
- 4如何使用Python从视频中提取图像?(帧提取)详细代码实现_python 读取特定路径下的视频文件,并对视频中的图像进行编号,最后将编号后的图像
- 5uCOS-II v2.52在MCS-51系列单片机上的移植实例(修订版)_ucos-ii v2.52基于51单片机的移植实例 + proteus仿真
- 6idea 回滚某次提交的代码_idea代码回滚到指定提交位置
- 7Gradle的学习
- 8学习Python语言有什么优势?_谈谈如果让你再深入学习python语言,你想深入哪方面?
- 9Spark源码——Job全流程以及DAGScheduler的Stage划分_spark dag划分源码
- 10Ubuntu Linux下通过代理(proxy)使用git上github.com
【Fooocus 深度学习】SDXL,AIGC生图,源码解读_fooocus代码解读
赞
踩
使用通配符增加prompt多样性
prompt和negative_prompt都可以通过apply_wildcards函数来实现通配符替换,apply_wildcards会从txt中随机找一个出来。
prompt='sunshine, river, trees, __artist__'
task_prompt = apply_wildcards(prompt, task_rng)
task_negative_prompt = apply_wildcards(negative_prompt, task_rng)
- 1
- 2
- 3
def apply_wildcards(wildcard_text, rng, directory=wildcards_path):
for _ in range(wildcards_max_bfs_depth):
placeholders = re.findall(r'__([\w-]+)__', wildcard_text)
if len(placeholders) == 0:
return wildcard_text
print(f'[Wildcards] processing: {wildcard_text}')
for placeholder in placeholders:
try:
words = open(os.path.join(directory, f'{placeholder}.txt'), encoding='utf-8').read().splitlines()
words = [x for x in words if x != '']
assert len(words) > 0
wildcard_text = wildcard_text.replace(f'__{placeholder}__', rng.choice(words), 1)
except:
print(f'[Wildcards] Warning: {placeholder}.txt missing or empty. '
f'Using "{placeholder}" as a normal word.')
wildcard_text = wildcard_text.replace(f'__{placeholder}__', placeholder)
print(f'[Wildcards] {wildcard_text}')
print(f'[Wildcards] BFS stack overflow. Current text: {wildcard_text}')
return wildcard_text
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
Fooocus的风格实现
Fooocus可选多种风格,都是以更改prompt和negative_prompt来实现。
风格s传入apply_style函数中,得到prompt和negative_prompt:
注意:空列表+空列表仍旧是一个空列表,非空列表加空列表等于没加空列表。
positive_basic_workloads = []
negative_basic_workloads = []
style_selections = ['Fooocus Enhance', 'Fooocus Sharp']
task_prompt='sunshine, river, trees,'
for s in style_selections:
p, n = apply_style(s, positive=task_prompt) # 得到prompt和negative_prompt
positive_basic_workloads = positive_basic_workloads + p
negative_basic_workloads = negative_basic_workloads + n
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
apply_style函数则为:
def apply_style(style, positive):
p, n = styles[style]
return p.replace('{prompt}', positive).splitlines(), n.splitlines()
- 1
- 2
- 3
styles是一个全局字典,目前有213个key,则是有213种风格。每个key中是一个2个元素的元组,即是 prompt和negative_prompt
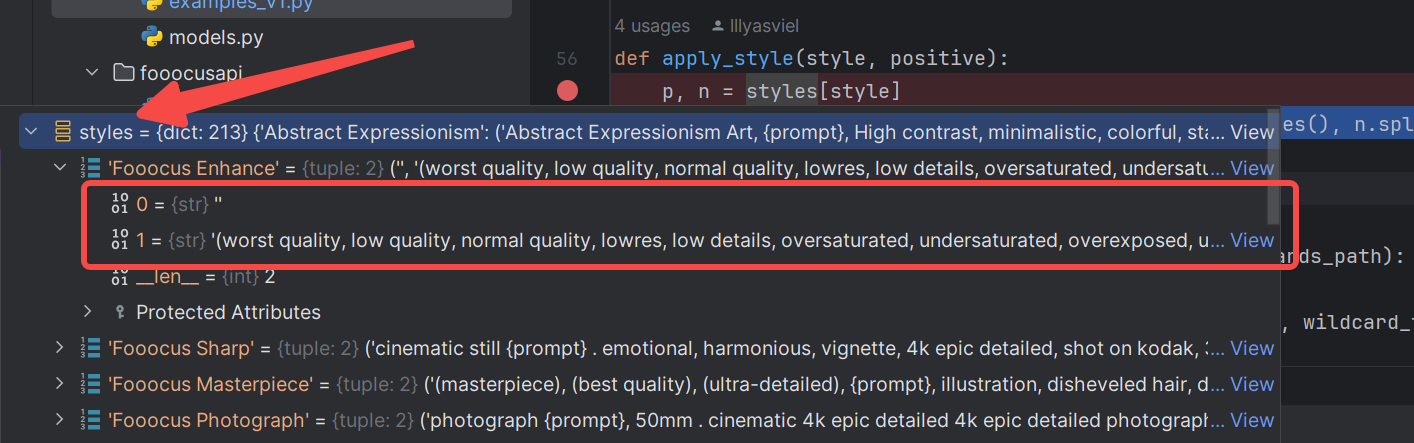
p.replace(‘{prompt}’, positive).splitlines()
用用户输入的prompt来替换风格字符串可能存在的{prompt},然后使用splitlines()方法,得到字符串的list返回(使用splitlines()或许有深层次考虑,但我没发现)。
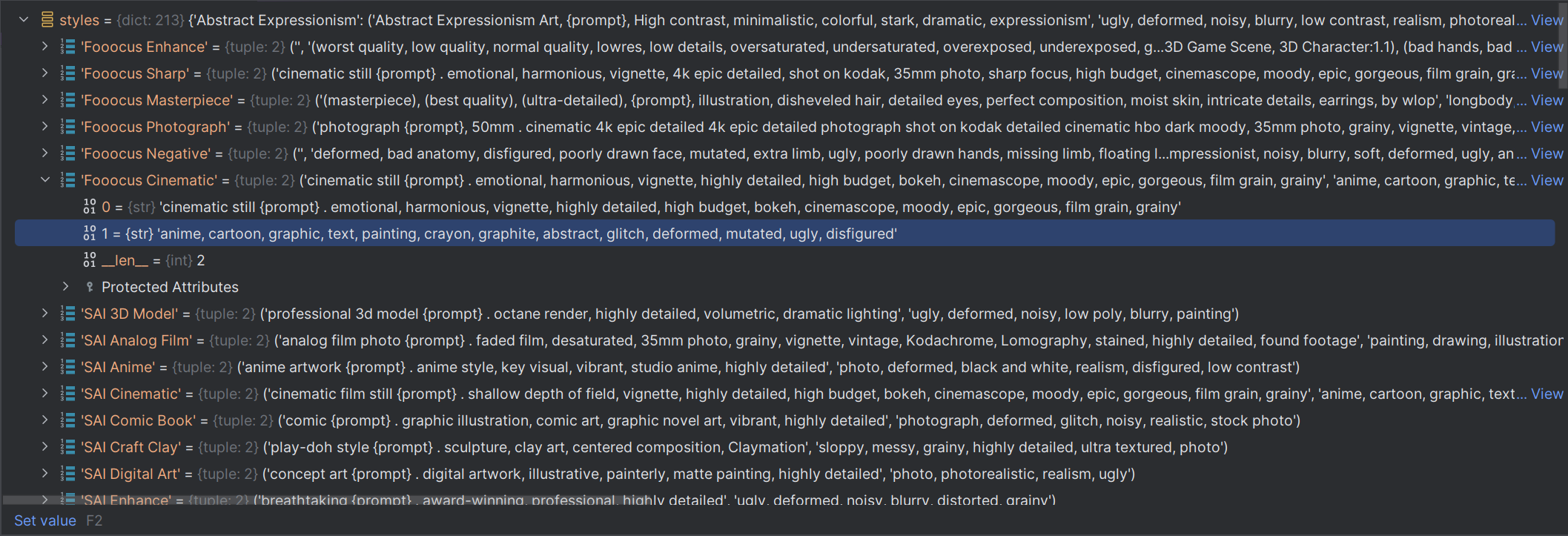
这里就会发现,很容易有多个风格产生多个negativeprompt。
fooocus_expansion
风格里如果有Fooocus V2,这个提示词扩展的逻辑就生效。
fooocus_expansion是这么一段代码,会使用pipeline.final_expansion将用户输入的prompt转为expansion
if prompt == '':
# disable expansion when empty since it is not meaningful and influences image prompt
use_expansion = False
if use_expansion:
for i, t in enumerate(tasks):
progressbar(async_task, 5, f'Preparing Fooocus text #{i + 1} ...')
expansion = pipeline.final_expansion(t['task_prompt'], t['task_seed'])
print(f'[Prompt Expansion] {expansion}')
t['expansion'] = expansion
t['positive'] = copy.deepcopy(t['positive']) + [expansion] # Deep copy.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
pipeline.final_expansion是下面这个class。
这段Python代码定义了一个名为 FooocusExpansion 的类,与使用Hugging Face Transformers库进行自然语言处理(NLP)相关。我们逐步解释该类的功能:
-
初始化(
__init__方法):- 初始化类的实例。
- 使用
AutoTokenizer.from_pretrained从指定路径 (path_fooocus_expansion) 加载一个分词器。 - 从文件 (
positive.txt) 读取一个正面词汇列表,进行预处理,并创建一个名为logits_bias的张量,其值初始化为负无穷。 - 遍历分词器的词汇表,如果词在正面词汇列表中,则在
logits_bias中对应的位置赋值为 0。 - 打印在词汇表中找到的正面词汇数量。
- 加载一个预训练的语言模型,用于因果语言建模 (
AutoModelForCausalLM)。 - 将模型设置为评估模式,并进行一些与设备相关的配置。
-
Logits 处理器(
logits_processor方法):- 这是一个修饰函数(
@torch.no_grad()、@torch.inference_mode())。 - 接受输入的 ID 和分数,根据正面词汇的偏置调整 logits,然后返回修改后的分数。
- 这是一个修饰函数(
-
调用(
__call__方法):- 这是另一个修饰函数。
- 接受一个提示文本和一个种子值作为输入。
- 如果提示文本为空,返回一个空字符串。
- 检查模型 patcher 的当前设备是否与加载设备不同,如果需要,重新加载模型。
- 为了保持可重复性,设置一个种子值并对输入提示进行分词。
- 使用语言模型生成新的标记,指定了一些参数,如 top-k 抽样、最大新标记数和自定义 logits 处理器。
- 将生成的特征解码成一个响应,并返回结果。
这个类是一个用于文本扩展的语言模型包装器,具有特定的分词、模型加载和结果生成配置。看起来设计用于使用预训练语言模型扩展文本提示。
存在的意义:
这个类的目的是使用预训练的语言模型对给定的文本提示进行扩展。通常,文本扩展的需求可能有以下一些原因:
-
增加多样性: 对于某些应用场景,系统生成的文本可能会显得单一。通过扩展文本,可以增加生成结果的多样性,使其更加丰富和有趣。
-
提高语境理解: 有时候,原始提示可能太过简短,不足以提供足够的上下文信息。通过生成更多文本,可以提供更丰富的语境,有助于提高系统对用户意图的理解。
-
解决长度限制: 部分应用可能对生成文本的长度有限制。通过扩展文本,可以满足这些长度限制,确保生成的文本符合系统或应用的要求。
-
抵抗模型的刚性: 预训练语言模型可能倾向于生成某些类型的文本,而这可能并不总是符合用户的期望。通过引入额外的文本,可以对模型生成的内容进行一定程度的调整和引导。
-
生成更详细的回答: 对于一些问题,用户可能期望得到更详细的回答。通过对提示进行扩展,可以生成更丰富、详细的文本,满足用户的需求。
需要注意的是,是否需要文本扩展取决于具体的应用场景和任务。在某些情况下,原始提示可能已经足够,而在其他情况下,通过扩展文本可以改善生成结果的质量和适用性。
class FooocusExpansion:
def __init__(self):
self.tokenizer = AutoTokenizer.from_pretrained(path_fooocus_expansion)
positive_words = open(os.path.join(path_fooocus_expansion, 'positive.txt'),
encoding='utf-8').read().splitlines()
positive_words = ['Ġ' + x.lower() for x in positive_words if x != '']
self.logits_bias = torch.zeros((1, len(self.tokenizer.vocab)), dtype=torch.float32) + neg_inf
debug_list = []
for k, v in self.tokenizer.vocab.items():
if k in positive_words:
self.logits_bias[0, v] = 0
debug_list.append(k[1:])
print(f'Fooocus V2 Expansion: Vocab with {len(debug_list)} words.')
# debug_list = '\n'.join(sorted(debug_list))
# print(debug_list)
# t11 = self.tokenizer(',', return_tensors="np")
# t198 = self.tokenizer('\n', return_tensors="np")
# eos = self.tokenizer.eos_token_id
self.model = AutoModelForCausalLM.from_pretrained(path_fooocus_expansion)
self.model.eval()
load_device = model_management.text_encoder_device()
offload_device = model_management.text_encoder_offload_device()
# MPS hack
if model_management.is_device_mps(load_device):
load_device = torch.device('cpu')
offload_device = torch.device('cpu')
use_fp16 = model_management.should_use_fp16(device=load_device)
if use_fp16:
self.model.half()
self.patcher = ModelPatcher(self.model, load_device=load_device, offload_device=offload_device)
print(f'Fooocus Expansion engine loaded for {load_device}, use_fp16 = {use_fp16}.')
@torch.no_grad()
@torch.inference_mode()
def logits_processor(self, input_ids, scores):
assert scores.ndim == 2 and scores.shape[0] == 1
self.logits_bias = self.logits_bias.to(scores)
bias = self.logits_bias.clone()
bias[0, input_ids[0].to(bias.device).long()] = neg_inf
bias[0, 11] = 0
return scores + bias
@torch.no_grad()
@torch.inference_mode()
def __call__(self, prompt, seed):
if prompt == '':
return ''
if self.patcher.current_device != self.patcher.load_device:
print('Fooocus Expansion loaded by itself.')
model_management.load_model_gpu(self.patcher)
seed = int(seed) % SEED_LIMIT_NUMPY
set_seed(seed)
prompt = safe_str(prompt) + ','
tokenized_kwargs = self.tokenizer(prompt, return_tensors="pt")
tokenized_kwargs.data['input_ids'] = tokenized_kwargs.data['input_ids'].to(self.patcher.load_device)
tokenized_kwargs.data['attention_mask'] = tokenized_kwargs.data['attention_mask'].to(self.patcher.load_device)
current_token_length = int(tokenized_kwargs.data['input_ids'].shape[1])
max_token_length = 75 * int(math.ceil(float(current_token_length) / 75.0))
max_new_tokens = max_token_length - current_token_length
# https://huggingface.co/blog/introducing-csearch
# https://huggingface.co/docs/transformers/generation_strategies
features = self.model.generate(**tokenized_kwargs,
top_k=100,
max_new_tokens=max_new_tokens,
do_sample=True,
logits_processor=LogitsProcessorList([self.logits_processor]))
response = self.tokenizer.batch_decode(features, skip_special_tokens=True)
result = safe_str(response[0])
return result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
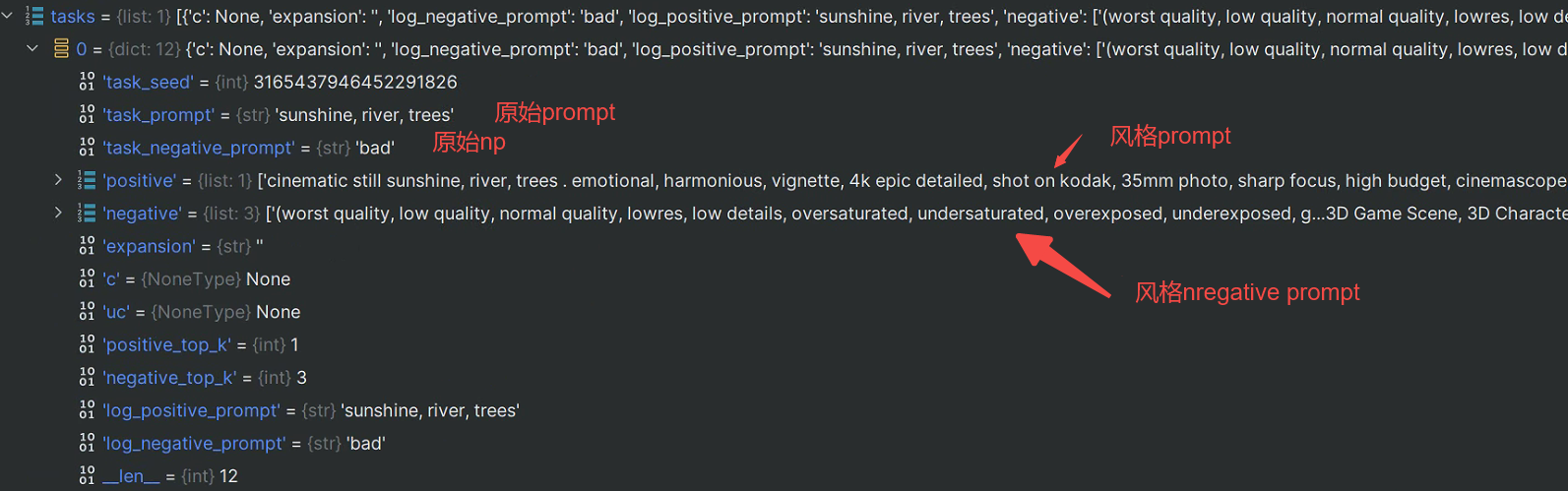
传入的路径是这些:

下图是扩展结果,可以看到有很多正面的词语:
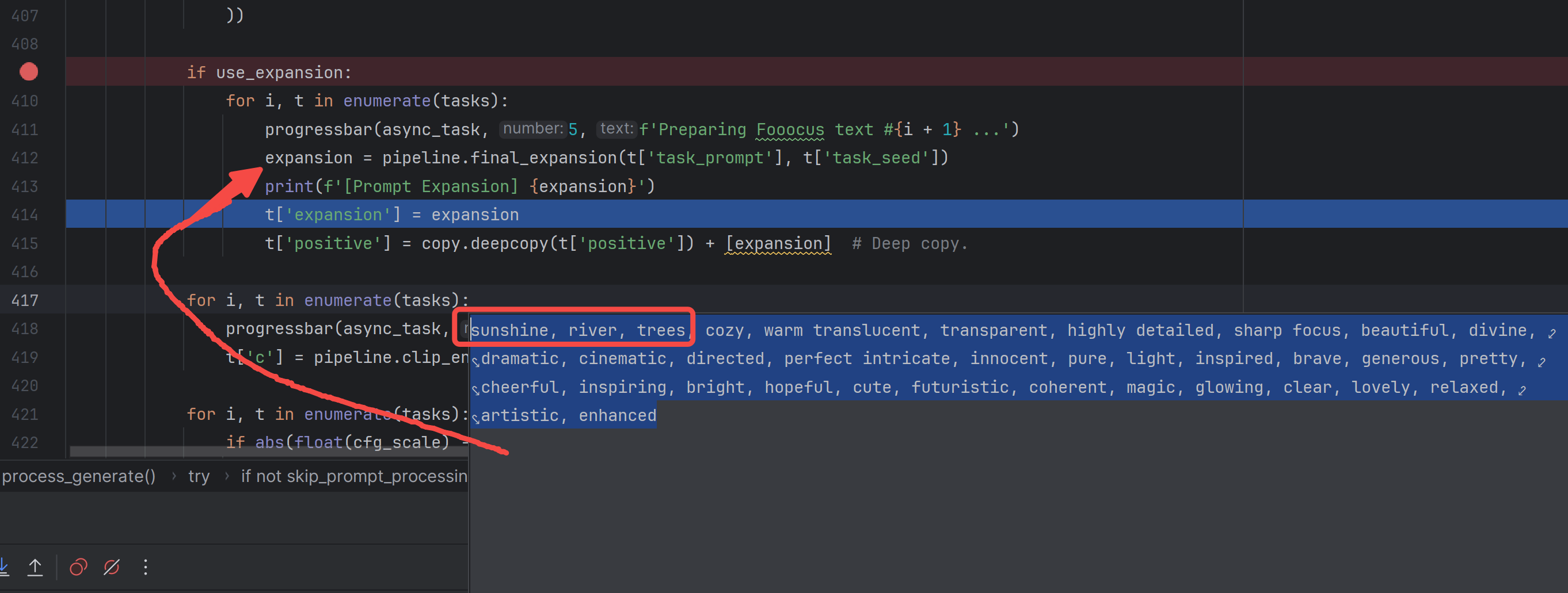
这波操作后,positive有2个(1个是风格来的、1个是现在扩展来的),negative还是之前3个(2个是风格来的、1个是原始输入的negative):
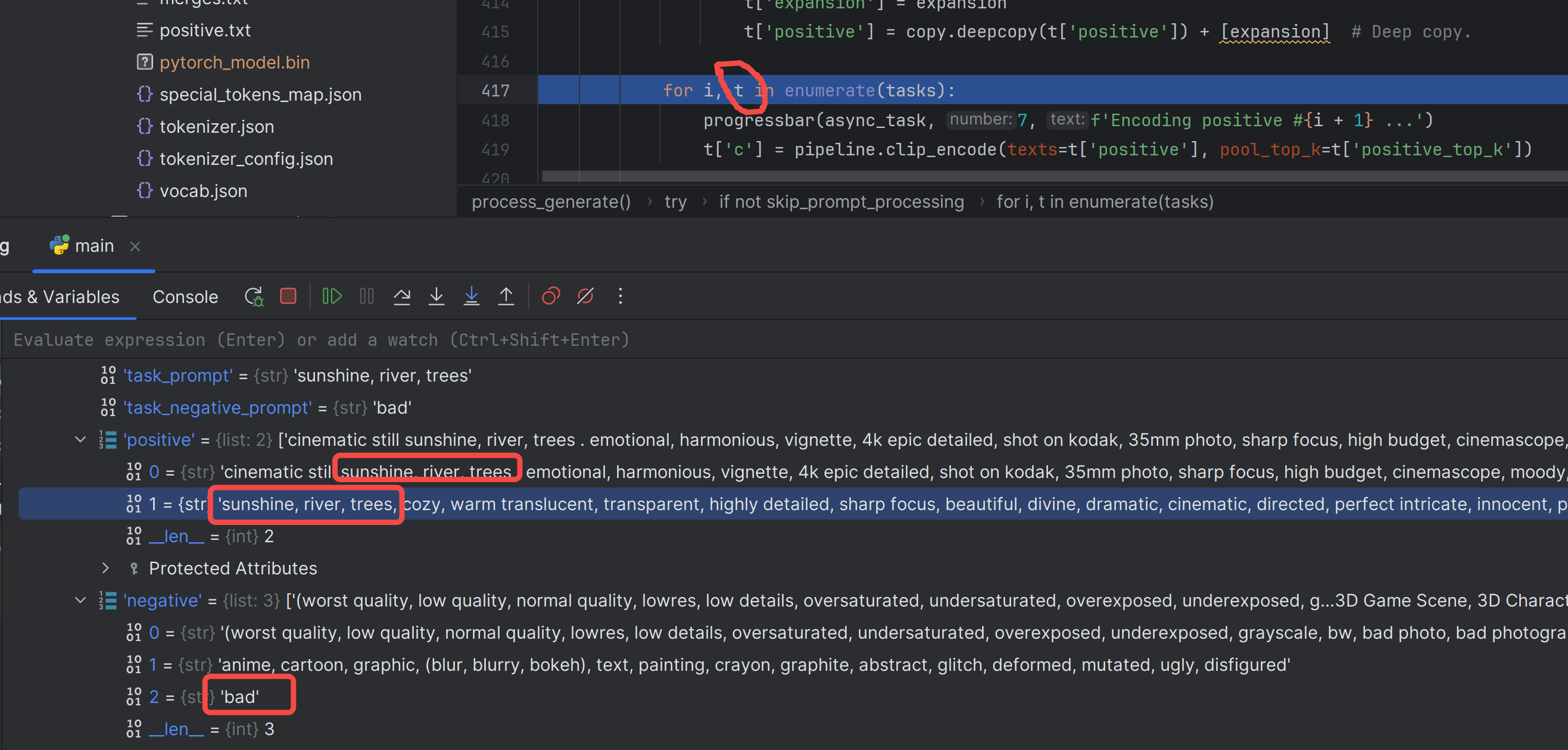
clip
对positive和negative编码:
for i, t in enumerate(tasks):
progressbar(async_task, 7, f'Encoding positive #{i + 1} ...')
t['c'] = pipeline.clip_encode(texts=t['positive'], pool_top_k=t['positive_top_k'])
for i, t in enumerate(tasks):
if abs(float(cfg_scale) - 1.0) < 1e-4:
t['uc'] = pipeline.clone_cond(t['c'])
else:
progressbar(async_task, 10, f'Encoding negative #{i + 1} ...')
t['uc'] = pipeline.clip_encode(texts=t['negative'], pool_top_k=t['negative_top_k'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
编码函数:
@torch.no_grad()
@torch.inference_mode()
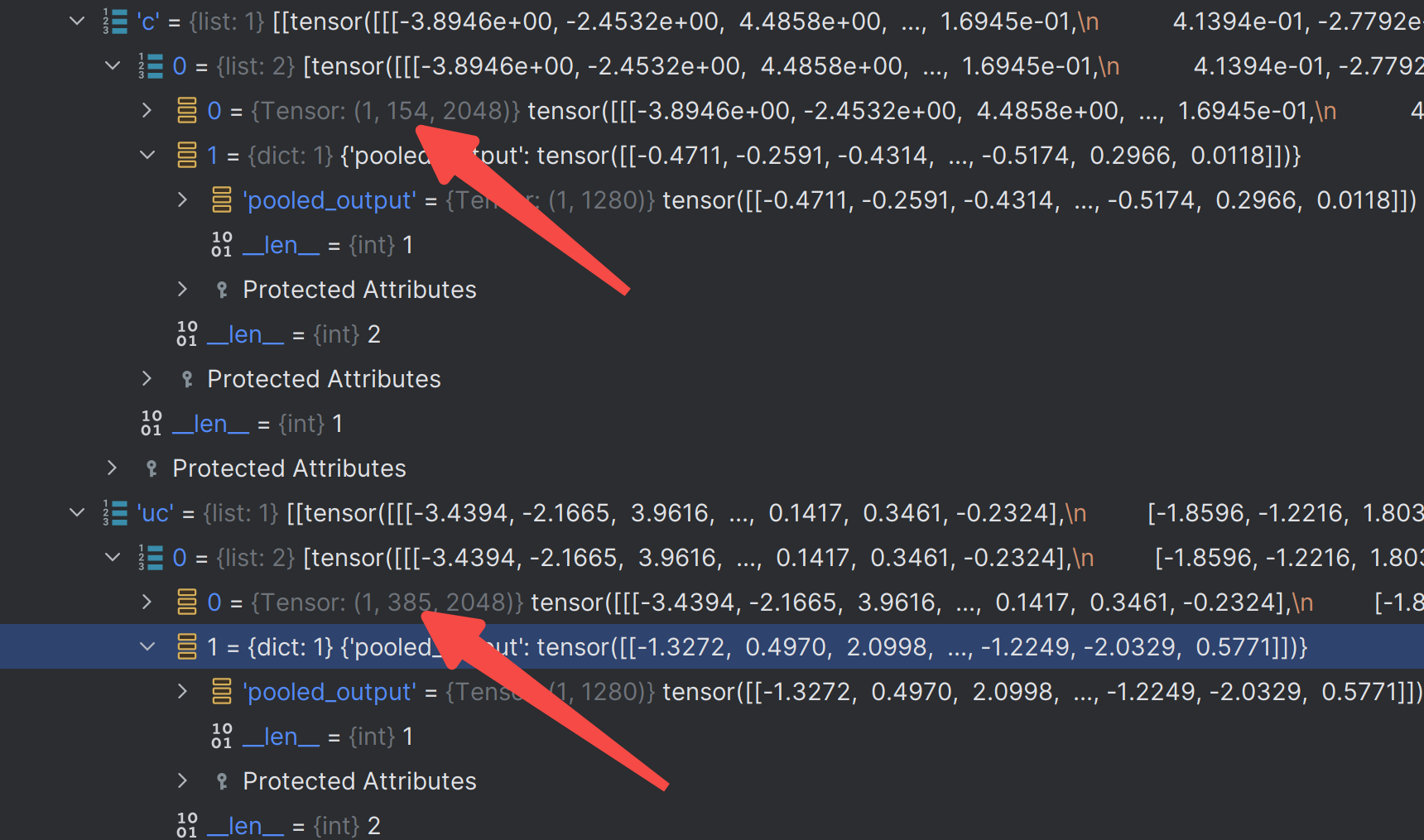
def clip_encode(texts, pool_top_k=1):
global final_clip
if final_clip is None:
return None
if not isinstance(texts, list):
return None
if len(texts) == 0:
return None
cond_list = []
pooled_acc = 0
for i, text in enumerate(texts):
cond, pooled = clip_encode_single(final_clip, text)
cond_list.append(cond)
if i < pool_top_k:
pooled_acc += pooled
return [[torch.cat(cond_list, dim=1), {"pooled_output": pooled_acc}]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
扩散
positive_cond 文本特征
negative_cond 文本特征
steps 30步
switch 这个时候是15,传入的refiner_switch是0.5
switch = int(round(steps * refiner_switch))
switch = advanced_parameters.overwrite_switch)
width 图宽
height 图高
task[‘task_seed’] 种子
callback 回调函数
final_sampler_name ‘dpmpp_2m_sde_gpu’ 采样名称
final_scheduler_name ‘karras’ 调度器
initial_latent 文生图不需要这个,无
denoising_strength 1.0
tiled False
cfg_scale 4.0
refiner_swap_method ‘joint’
imgs = pipeline.process_diffusion(
positive_cond=positive_cond,
negative_cond=negative_cond,
steps=steps,
switch=switch,
width=width,
height=height,
image_seed=task['task_seed'],
callback=callback,
sampler_name=final_sampler_name,
scheduler_name=final_scheduler_name,
latent=initial_latent,
denoise=denoising_strength,
tiled=tiled,
cfg_scale=cfg_scale,
refiner_swap_method=refiner_swap_method
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
采样参数 sigmas
为了得到sigmas:
# 最初调用
minmax_sigmas = calculate_sigmas(sampler=sampler_name, scheduler=scheduler_name, model=final_unet.model, steps=steps, denoise=denoise)
# 在这里进一步想得到sigmas
def calculate_sigmas_scheduler(model, scheduler_name, steps):
if scheduler_name == "karras":
sigmas = k_diffusion_sampling.get_sigmas_karras(n=steps, sigma_min=float(model.model_sampling.sigma_min), sigma_max=float(model.model_sampling.sigma_max))
elif scheduler_name == "exponential":
sigmas = k_diffusion_sampling.get_sigmas_exponential(n=steps, sigma_min=float(model.model_sampling.sigma_min), sigma_max=float(model.model_sampling.sigma_max))
elif scheduler_name == "normal":
sigmas = normal_scheduler(model, steps)
elif scheduler_name == "simple":
sigmas = simple_scheduler(model, steps)
elif scheduler_name == "ddim_uniform":
sigmas = ddim_scheduler(model, steps)
elif scheduler_name == "sgm_uniform":
sigmas = normal_scheduler(model, steps, sgm=True)
else:
print("error invalid scheduler", self.scheduler)
return sigmas
def get_sigmas_karras(n, sigma_min, sigma_max, rho=7., device='cpu'):
"""Constructs the noise schedule of Karras et al. (2022)."""
ramp = torch.linspace(0, 1, n, device=device)
min_inv_rho = sigma_min ** (1 / rho)
max_inv_rho = sigma_max ** (1 / rho)
sigmas = (max_inv_rho + ramp * (min_inv_rho - max_inv_rho)) ** rho
return append_zero(sigmas).to(device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
model.model_sampling.sigma_min、model.model_sampling.sigma_max是模型中的参数。
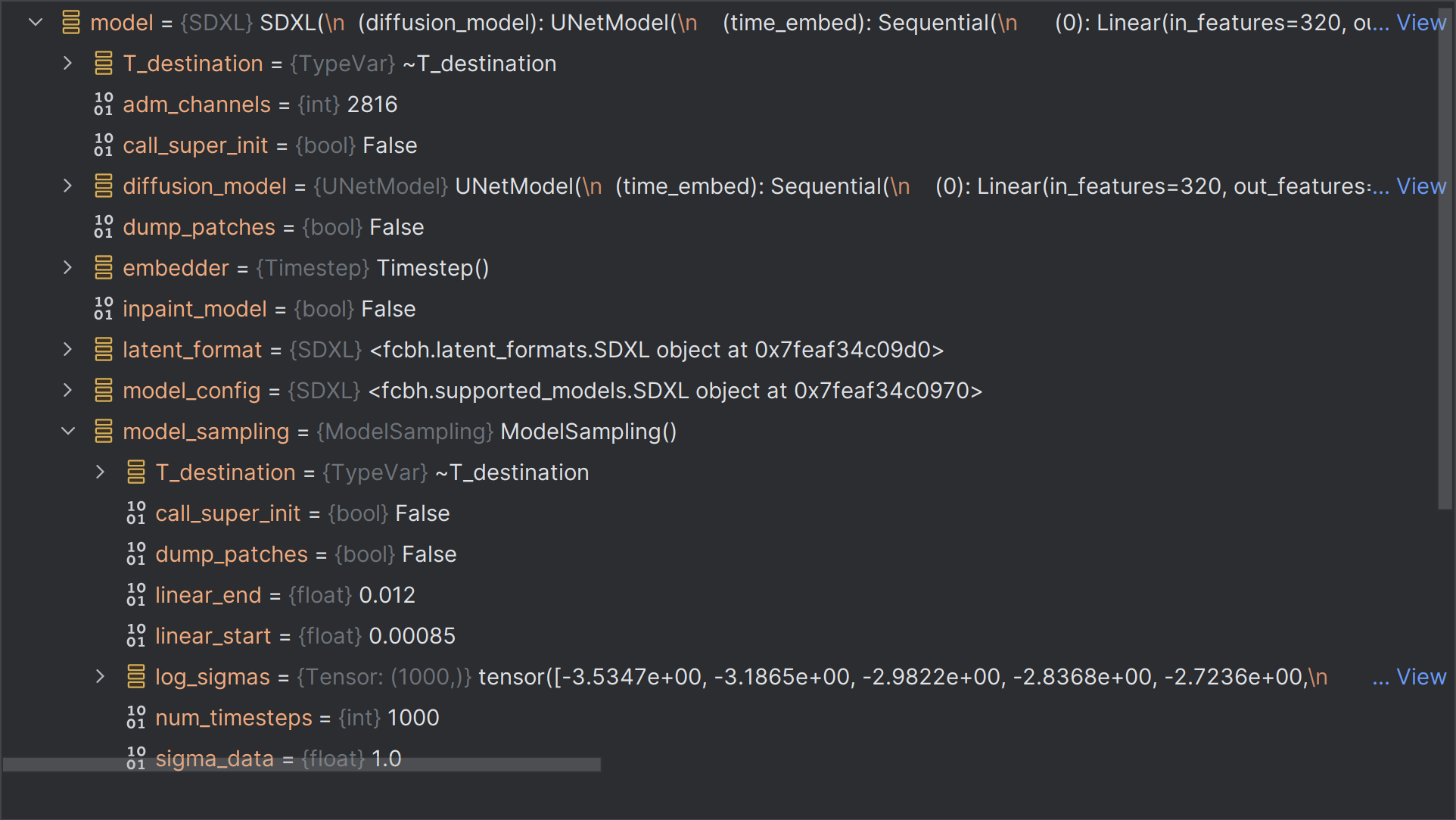
由karras调度器+模型参数,得到最终sigmas,sigmas是每一步扩散时候需要用的参数sigma。
import torch
def append_zero(x):
return torch.cat([x, x.new_zeros([1])])
def get_sigmas_karras(n, sigma_min, sigma_max, rho=7., device='cpu'):
"""Constructs the noise schedule of Karras et al. (2022)."""
ramp = torch.linspace(0, 1, n, device=device)
min_inv_rho = sigma_min ** (1 / rho)
max_inv_rho = sigma_max ** (1 / rho)
sigmas = (max_inv_rho + ramp * (min_inv_rho - max_inv_rho)) ** rho
return append_zero(sigmas).to(device)
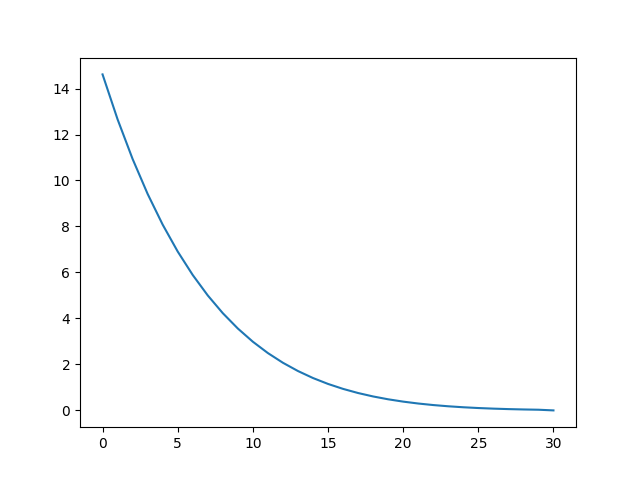
sigmas = get_sigmas_karras(30, 0.0292, 14.6146)
# 绘制图像
import matplotlib.pyplot as plt
plt.plot(sigmas)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
sigmas是由大到小的,karras调度趋势是这样:
BrownianTreeNoiseSamplerPatched
图生图应该会用到,文生图不用。
modules.patch.BrownianTreeNoiseSamplerPatched.global_init(
initial_latent['samples'].to(fcbh.model_management.get_torch_device()),
sigma_min, sigma_max, seed=image_seed, cpu=False)
class BrownianTreeNoiseSamplerPatched:
transform = None
tree = None
global_sigma_min = 1.0
global_sigma_max = 1.0
@staticmethod
def global_init(x, sigma_min, sigma_max, seed=None, transform=lambda x: x, cpu=False):
t0, t1 = transform(torch.as_tensor(sigma_min)), transform(torch.as_tensor(sigma_max))
BrownianTreeNoiseSamplerPatched.transform = transform
BrownianTreeNoiseSamplerPatched.tree = BatchedBrownianTree(x, t0, t1, seed, cpu=cpu)
BrownianTreeNoiseSamplerPatched.global_sigma_min = sigma_min
BrownianTreeNoiseSamplerPatched.global_sigma_max = sigma_max
def __init__(self, *args, **kwargs):
pass
@staticmethod
def __call__(sigma, sigma_next):
transform = BrownianTreeNoiseSamplerPatched.transform
tree = BrownianTreeNoiseSamplerPatched.tree
t0, t1 = transform(torch.as_tensor(sigma)), transform(torch.as_tensor(sigma_next))
return tree(t0, t1) / (t1 - t0).abs().sqrt()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这段代码定义了一个名为BrownianTreeNoiseSamplerPatched的类,它用于生成布朗运动树噪声。以下是对代码的解释:
-
BrownianTreeNoiseSamplerPatched类有几个类级别的属性:transform: 一个函数,用于对输入进行转换,默认为None。tree: 一个BatchedBrownianTree对象,用于生成布朗运动树噪声,默认为None。global_sigma_min和global_sigma_max: 两个表示全局标准差的属性,默认都是 1.0。
-
global_init方法是一个类级别的静态方法,用于全局初始化类的属性。它接受x、sigma_min、sigma_max、seed、transform和cpu作为参数,然后进行相应的初始化工作:- 将传入的
sigma_min和sigma_max使用transform函数进行处理,并赋值给t0和t1。 - 将
transform、BatchedBrownianTree(使用传入的参数进行初始化)、以及全局的sigma_min和sigma_max设置为相应的值。
- 将传入的
-
__init__方法是一个空的初始化方法,没有具体的实现。 -
__call__方法是一个静态方法,用于生成布朗运动树噪声。它接受sigma和sigma_next作为参数:- 从类属性中获取当前的
transform和tree。 - 使用传入的参数
sigma和sigma_next,并将它们通过transform函数进行处理,分别赋值给t0和t1。 - 调用
tree的__call__方法,传入t0和t1,然后除以(t1 - t0).abs().sqrt()。这一步用于归一化生成的噪声。
- 从类属性中获取当前的
这段代码是一个用于生成布朗运动树噪声的类,通过全局初始化方法 global_init 进行初始化,并通过 __call__ 方法生成噪声。这种布朗运动树噪声的生成常常用于模拟自然界中的随机过程。
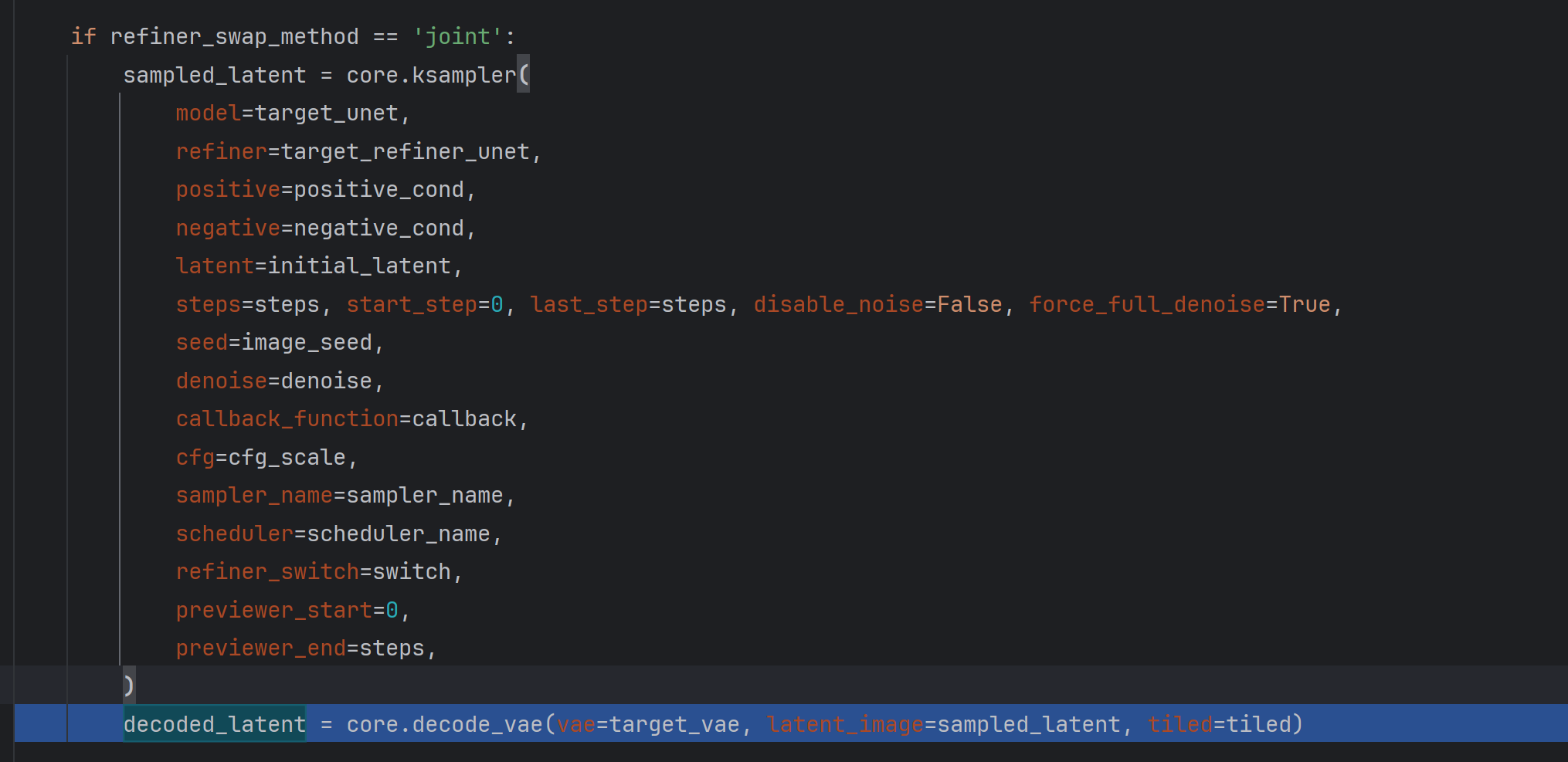
joint sample
joint这种方式是refiner一起的。
if refiner_swap_method == 'joint':
sampled_latent = core.ksampler(
model=target_unet,
refiner=target_refiner_unet,
positive=positive_cond,
negative=negative_cond,
latent=initial_latent,
steps=steps, start_step=0, last_step=steps, disable_noise=False, force_full_denoise=True,
seed=image_seed,
denoise=denoise,
callback_function=callback,
cfg=cfg_scale,
sampler_name=sampler_name,
scheduler=scheduler_name,
refiner_switch=switch,
previewer_start=0,
previewer_end=steps,
)
decoded_latent = core.decode_vae(vae=target_vae, latent_image=sampled_latent, tiled=tiled)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
ksampler中处理一些噪声,然后使用fcbh.sample.sample:
@torch.no_grad()
@torch.inference_mode()
def ksampler(model, positive, negative, latent, seed=None, steps=30, cfg=7.0, sampler_name='dpmpp_2m_sde_gpu',
scheduler='karras', denoise=1.0, disable_noise=False, start_step=None, last_step=None,
force_full_denoise=False, callback_function=None, refiner=None, refiner_switch=-1,
previewer_start=None, previewer_end=None, sigmas=None, noise_mean=None)
- 1
- 2
- 3
- 4
- 5
- 6
使用fcbh.sample.sample:
samples = fcbh.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
denoise=denoise, disable_noise=disable_noise, start_step=start_step,
last_step=last_step,
force_full_denoise=force_full_denoise, noise_mask=noise_mask, callback=callback,
disable_pbar=disable_pbar, seed=seed, sigmas=sigmas)
out = latent.copy()
out["samples"] = samples
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
sample过程:
def sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=1.0, disable_noise=False, start_step=None, last_step=None, force_full_denoise=False, noise_mask=None, sigmas=None, callback=None, disable_pbar=False, seed=None):
real_model, positive_copy, negative_copy, noise_mask, models = prepare_sampling(model, noise.shape, positive, negative, noise_mask)
noise = noise.to(model.load_device)
latent_image = latent_image.to(model.load_device)
sampler = fcbh.samplers.KSampler(real_model, steps=steps, device=model.load_device, sampler=sampler_name, scheduler=scheduler, denoise=denoise, model_options=model.model_options)
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
samples = samples.cpu()
cleanup_additional_models(models)
cleanup_additional_models(set(get_models_from_cond(positive, "control") + get_models_from_cond(negative, "control")))
return samples
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
fcbh.samplers.KSampler 从噪声中不断演化。
vae
从latent空间vae解码出所需原图。