
- 1HTML期末学生大作业-奶茶网页作业html+css+javascript
- 2【MyBatis】ClassNotFoundException: Cannot find class: xxx`_mybatis的xml文件用类名报classnotfind
- 3Android使用Profiler查看应用内存分析_android profiler内存分析
- 4记oracle数据库中视图与greenplum中视图不同_greenplum 系统视图存放在
- 5tensorflow-gpu安装(详解)_tensorflow gpu安装
- 6GESP Python编程一级认证真题 2024年3月
- 7Spring boot 启动源码
- 8PMP刷题小结2_分析进度灵活性最小的活动排序
- 9Vivado将output定义为reg时遇到的问题_output reg
- 10大学生选课系统|基于Springboot的大学生选课系统设计与实现(源码+数据库+文档)_数据库学生选课系统课程设计
nnU-Net v2的环境配置到训练自己的数据集(详细步骤)_nnunetv2
赞
踩
一、说明
- 学习参加阿里云平台的竞赛第一次接触nnUNet任务,若有错误麻烦指出,谢谢啦
- 竞赛是关于牙齿的分割任务,背景说明和数据集下载地址为:MICCAI 2023 Challenges :STS-基于3D CBCT的牙齿分割任务
二、所需的环境配置
官方文档地址:GitHub-nnUNet
1. 版本要求:python >(或=) 3.9,pytorch>1.12.0 (之前使用的环境python版本为3.8.10,在安装nnU-Net时报错。torch最好的GPU版本的)
2. 创建虚拟环境:在pycharm中打开终端,输入命令行:conda create -n nnUNet python=3.9,创建一个名字为 nnUNet 的虚拟环境,并且指定python为3.9的版本

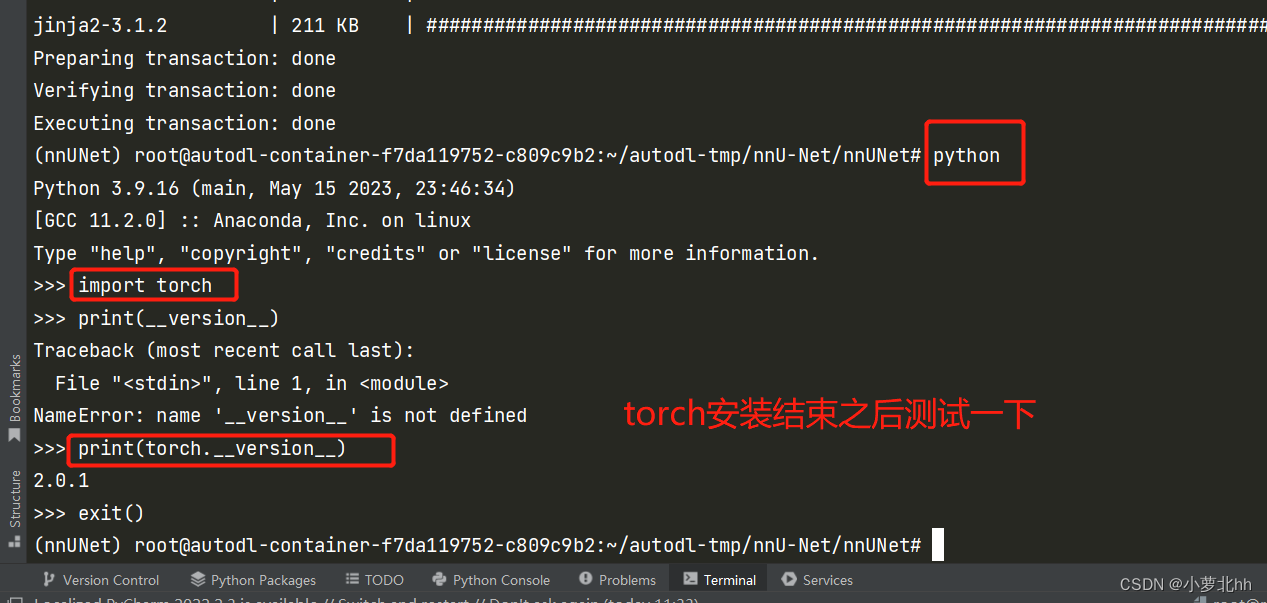
3. 在虚拟环境中安装torch:
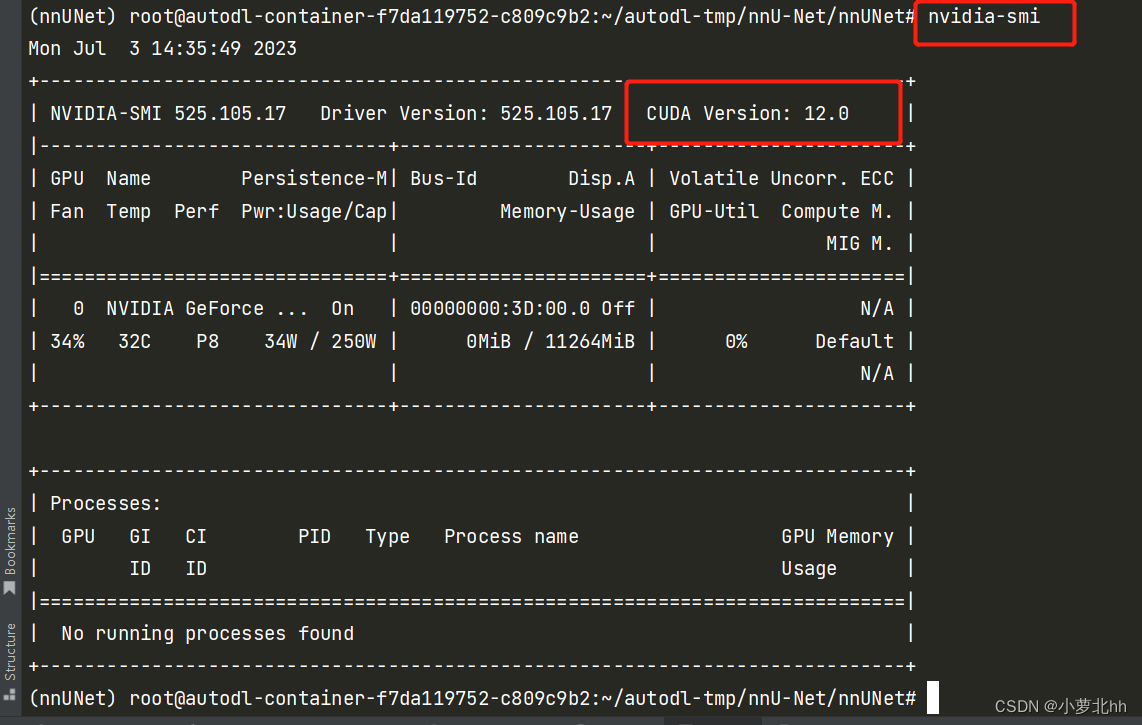
(1) 首先输入:nvidia-smi 查看信息,下图中的CUDA Version:12.0是指CUDA最高版本为12.0,即安装GPU版本的torch 的时候,安装12.0以下的版本
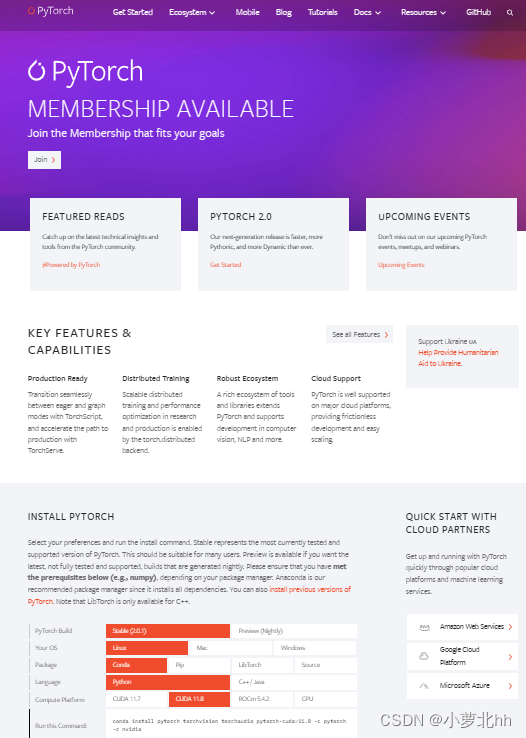
(2) 打开Pytorch官网:Pytorch地址,在此界面下拉,按照自己配置选择,然后复制给出的命令行

(3) 回到pycharm终端,进入粘贴此代码,进行torch安装

三、nnUNet框架的安装
注意:环境已经安装配好之后,接下来的所有操作都在此环境中,即:都需要先激活虚拟环境。GitHub-文档说明link
1. 安装nnUNet:(1)激活虚拟环境,(2)使用此命令行:
pip install nnunetv2
- 1
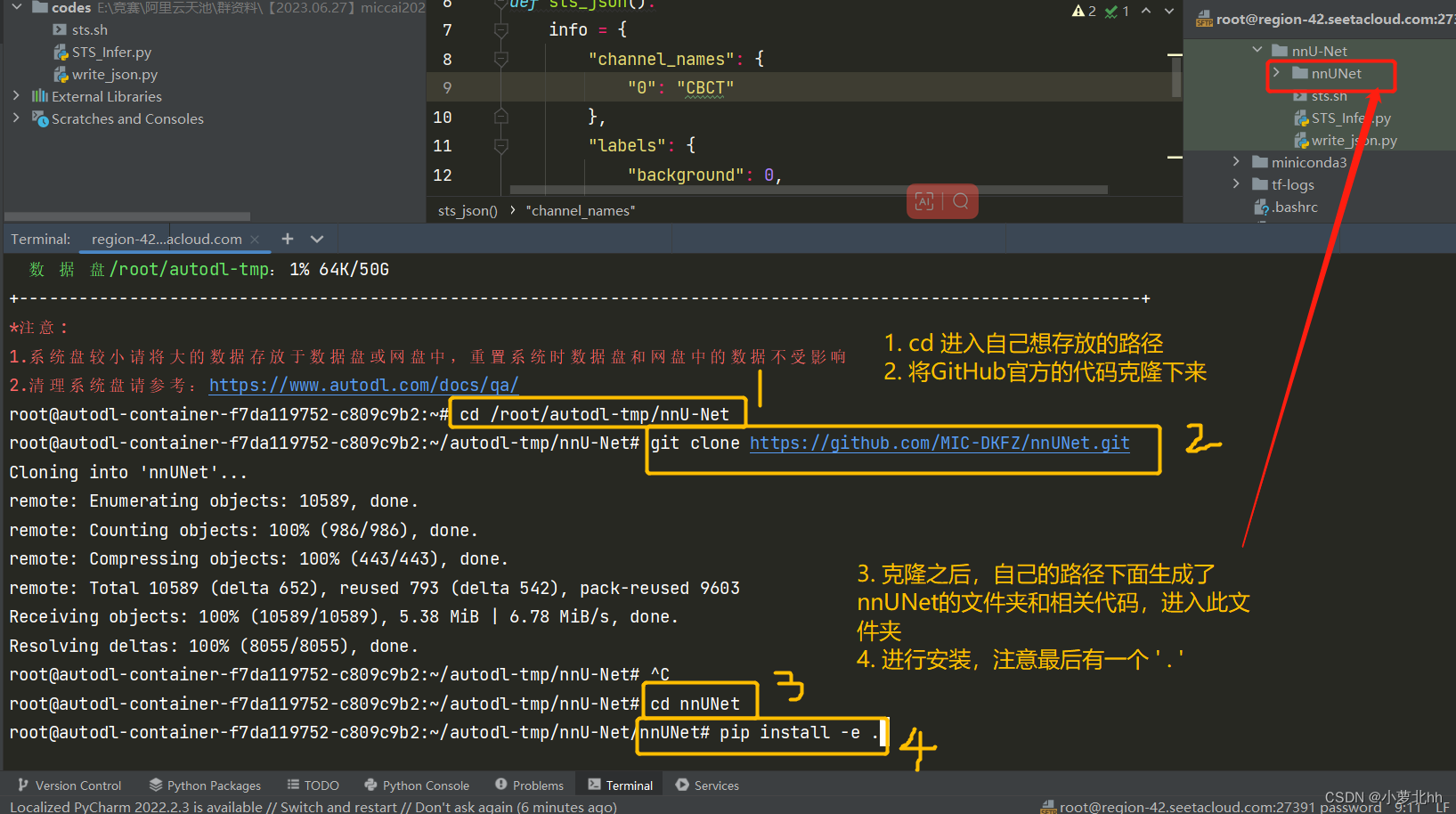
2. 创建nnUNet代码副本,和直接在GitHub上下载下来一样效果,继续在终端的虚拟环境中,按顺序分别执行以下3个命令行:(注意:最后一个命令最后有一个.)其中,pip install -e .的目的:(1)安装nnUNet需要的python包;(2)向终端添加新的命令,这些命令用于后续整个nnU-Net pipeline的执行,这些命令都有一个前缀:nnUNetv2_
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .
- 1
- 2
- 3
具体步骤如下图:
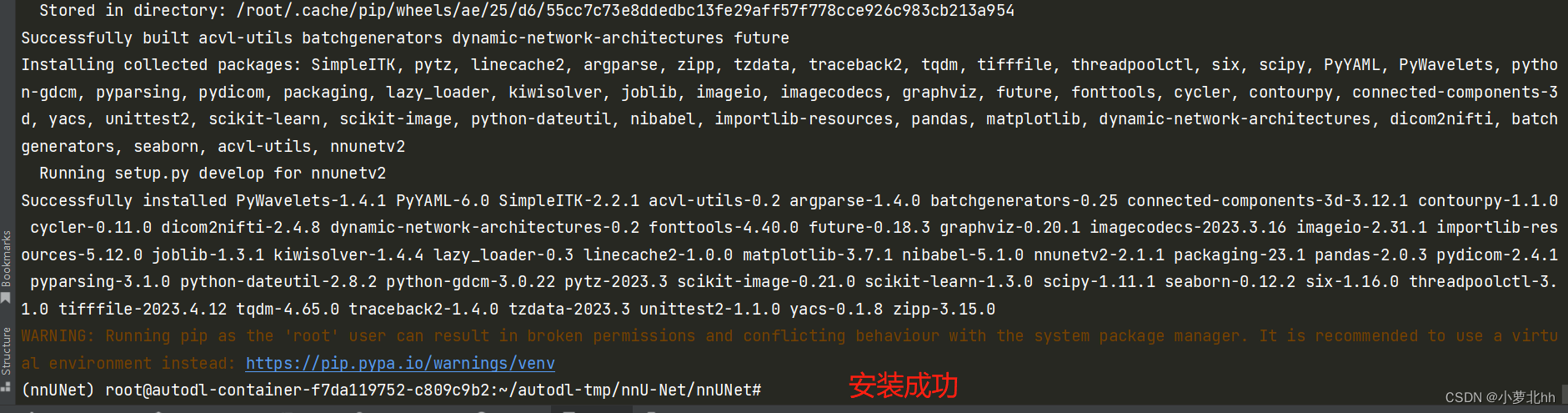
3. 安装隐藏层(可选,可以不安装),hiddenlayer 使 nnU-net 能够生成网络拓扑图
pip install --upgrade git+https://github.com/FabianIsensee/hiddenlayer.git
- 1
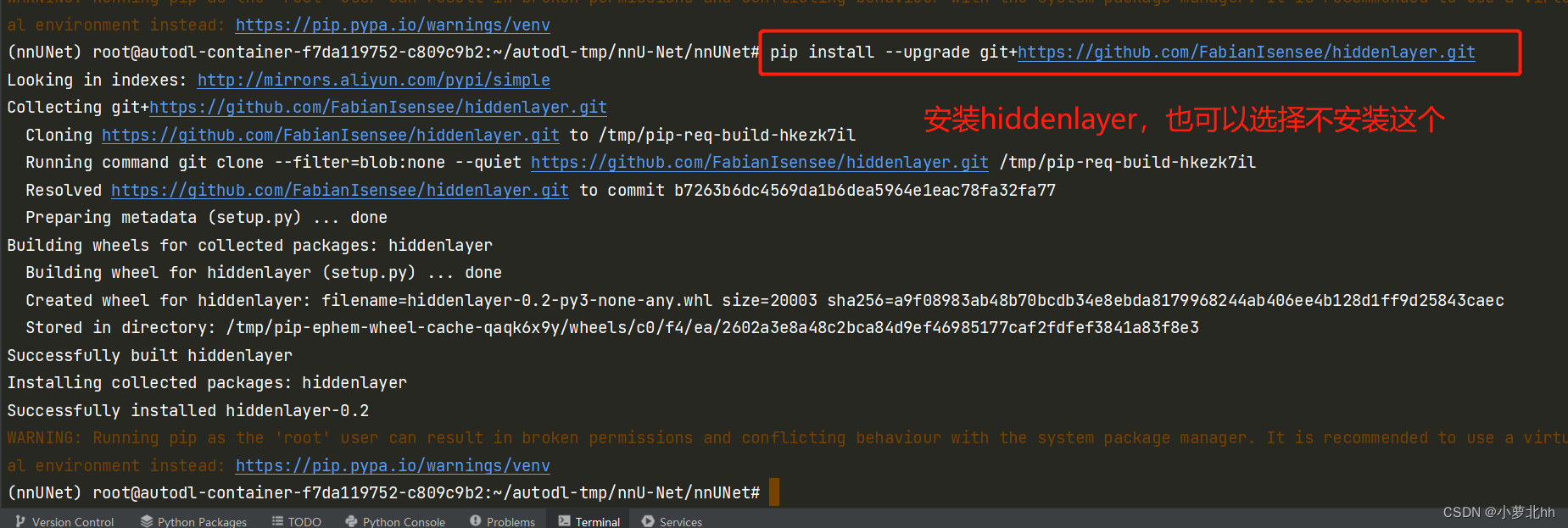
四、数据集的准备
得到克隆之后的副本,即:名为 nnUNet 的文件夹,参照官方文档,准备数据集。GitHub-文档说明link
1. 数据集文件夹结构:按照如下步骤创建文件夹,存放相应的数据集
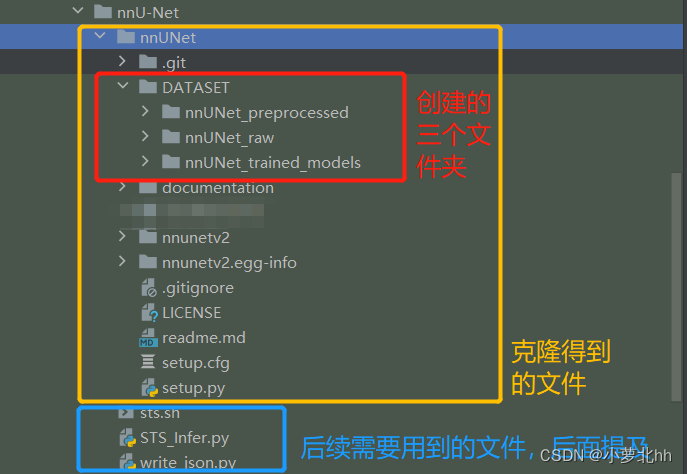
(1) 在 名为 nnUNet 的文件夹 中创建一个名为 名为 GATASET 的文件夹 的文件夹
(2) 在 名为 GATASET 的文件夹 中创建3个文件夹,命名分别为:nnUNet_raw、nnUNet_preprocessed 和 nnUNet_trained_models。如下图所示:
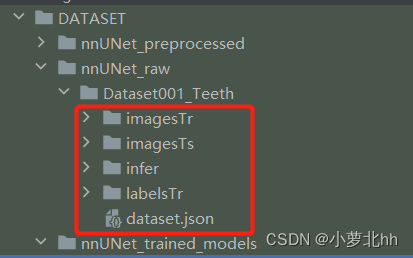
(3) 在 名为 nnUNet_raw 的文件夹 中创建1个 名为 Dataset001_Teeth 的文件夹
说明1:文件夹命名为:Dataset+三位整数+任务名,
Dataset001_Teeth中数据集ID为1,任务名为Teeth。此文件夹下存放需要的训练数据集imageTr、测试集imageTs、标签labelsTr。其中imageTs是与imageTr中一一对应的标签,文件中都是nii.gz文件。imageTs是可选项,可以没有。如下图所示
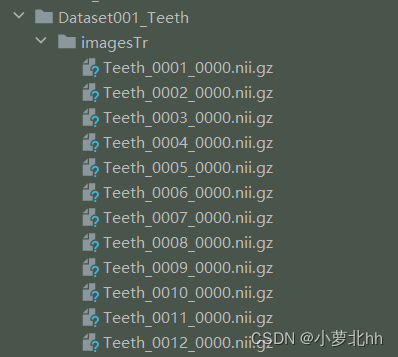
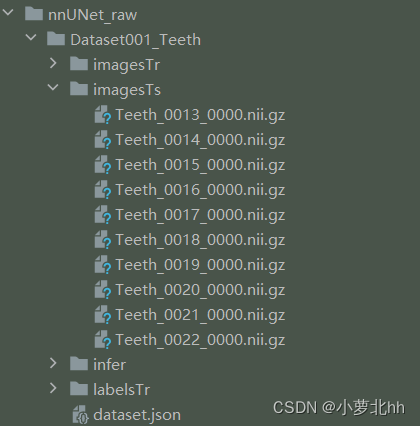
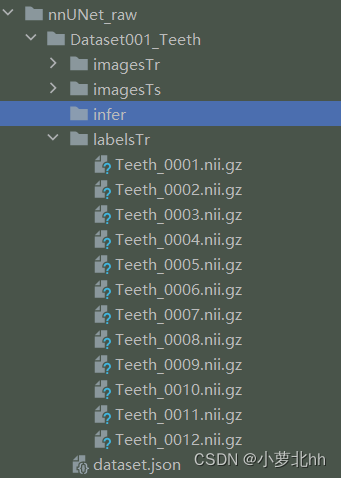
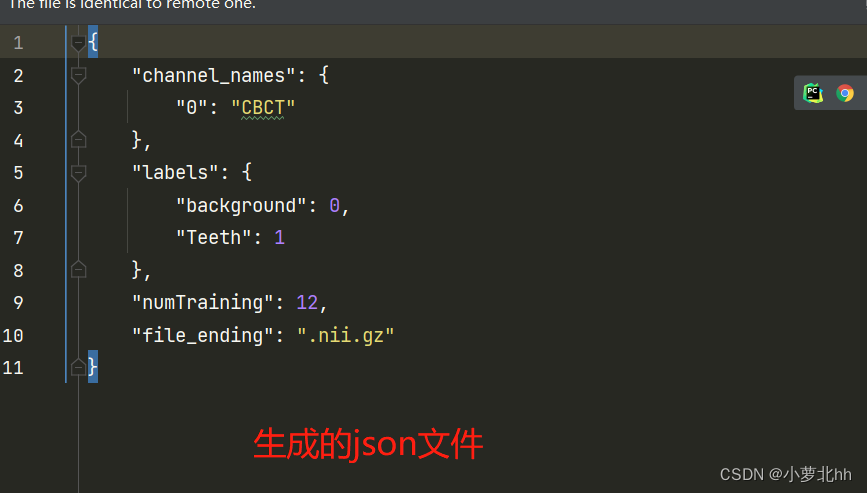
说明2:json文件是对三个文件夹内容的字典呈现。先在
Dataset001_Teeth文件夹下创建一个空白的dataset.json文件,然后运行以下代码写入相应的 json文件
import json nnUNet_dir = '/root/autodl-tmp/nnU-Net/nnUNet/DATASET/' #此路径根据自己实际修改 def sts_json(): info = { "channel_names": { "0": "CBCT" }, "labels": { "background": 0, "Teeth": 1 }, "numTraining": 12, "file_ending": ".nii.gz" } with open(nnUNet_dir + 'nnUNet_raw/Dataset001_Teeth/dataset.json', 'w') as f: json.dump(info, f, indent=4) sts_json()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
运行后生成的 json文件内容如下:
五、设置读取文件路径设置(重要)
1. 需要让nnUNet知道文件存放在哪里,否则执行数据处理等一下相关操作都会报错,如下图
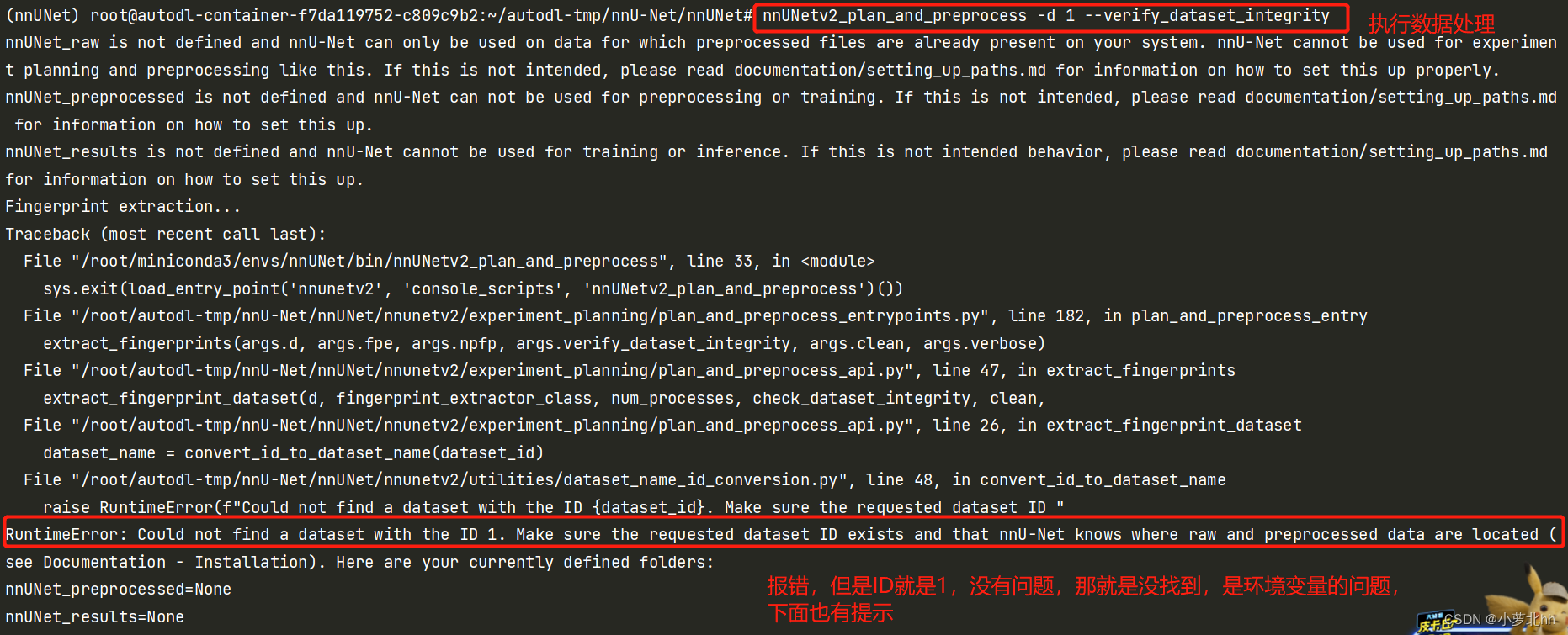

2. 方法一:(自己使用的方法一)
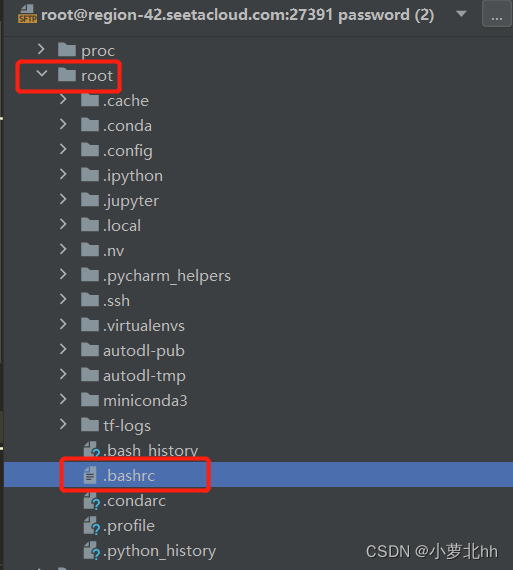
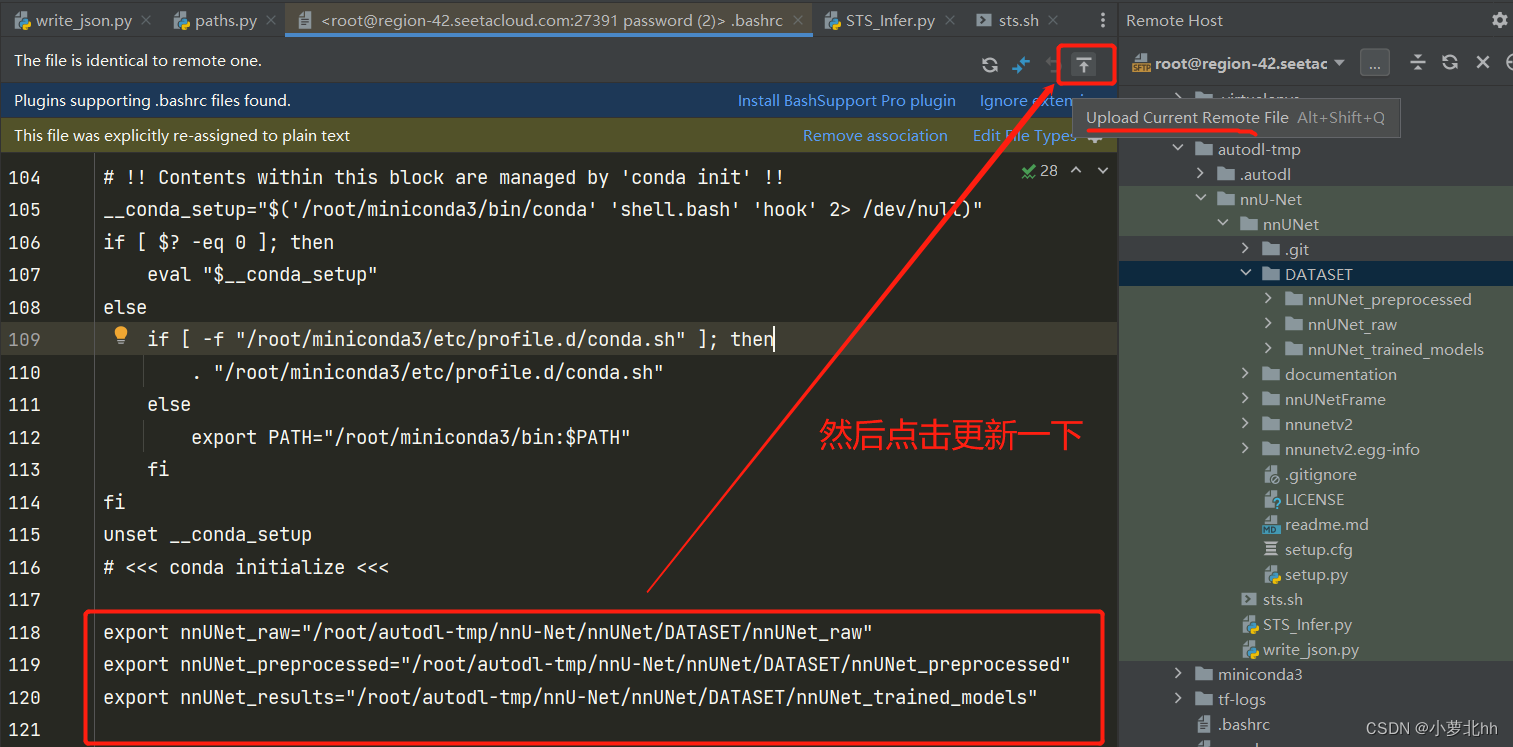
(1) 找到root文件夹下的.bashrc文件(注:这里自己租用的云平台的服务器,若是自己的服务器在home文件夹下找 .bashrc文件,若没有,在home目录下使用Ctrl+h,显示隐藏文件)
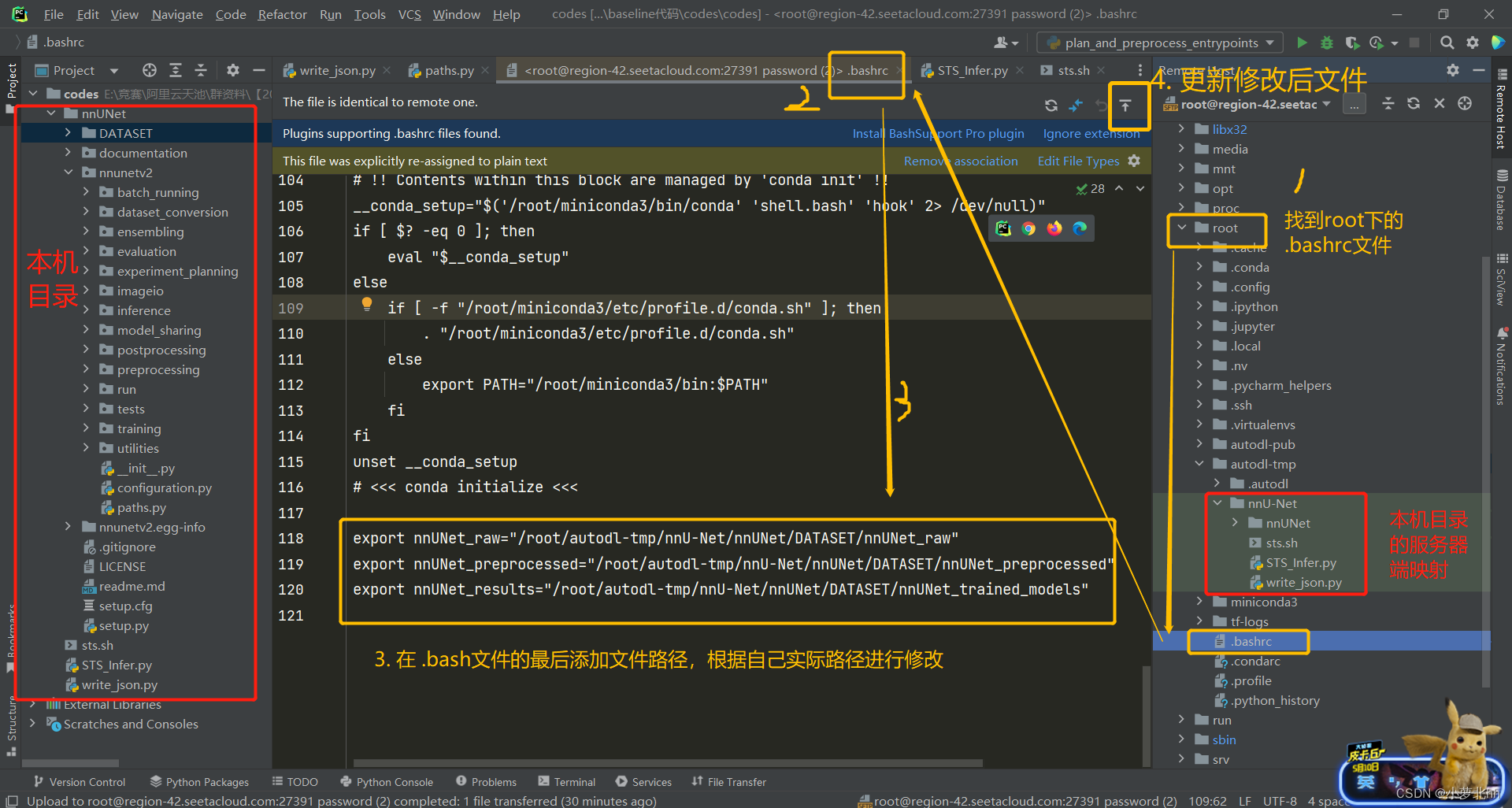
(2) 打开.bashrc文件,在最后添加此三行内容,记得要更新一下修改后的文件,具体说明如下图
export nnUNet_raw="/root/autodl-tmp/nnU-Net/nnUNet/DATASET/nnUNet_raw"
export nnUNet_preprocessed="/root/autodl-tmp/nnU-Net/nnUNet/DATASET/nnUNet_preprocessed"
export nnUNet_results="/root/autodl-tmp/nnU-Net/nnUNet/DATASET/nnUNet_trained_models"
- 1
- 2
- 3
3. 方法二:
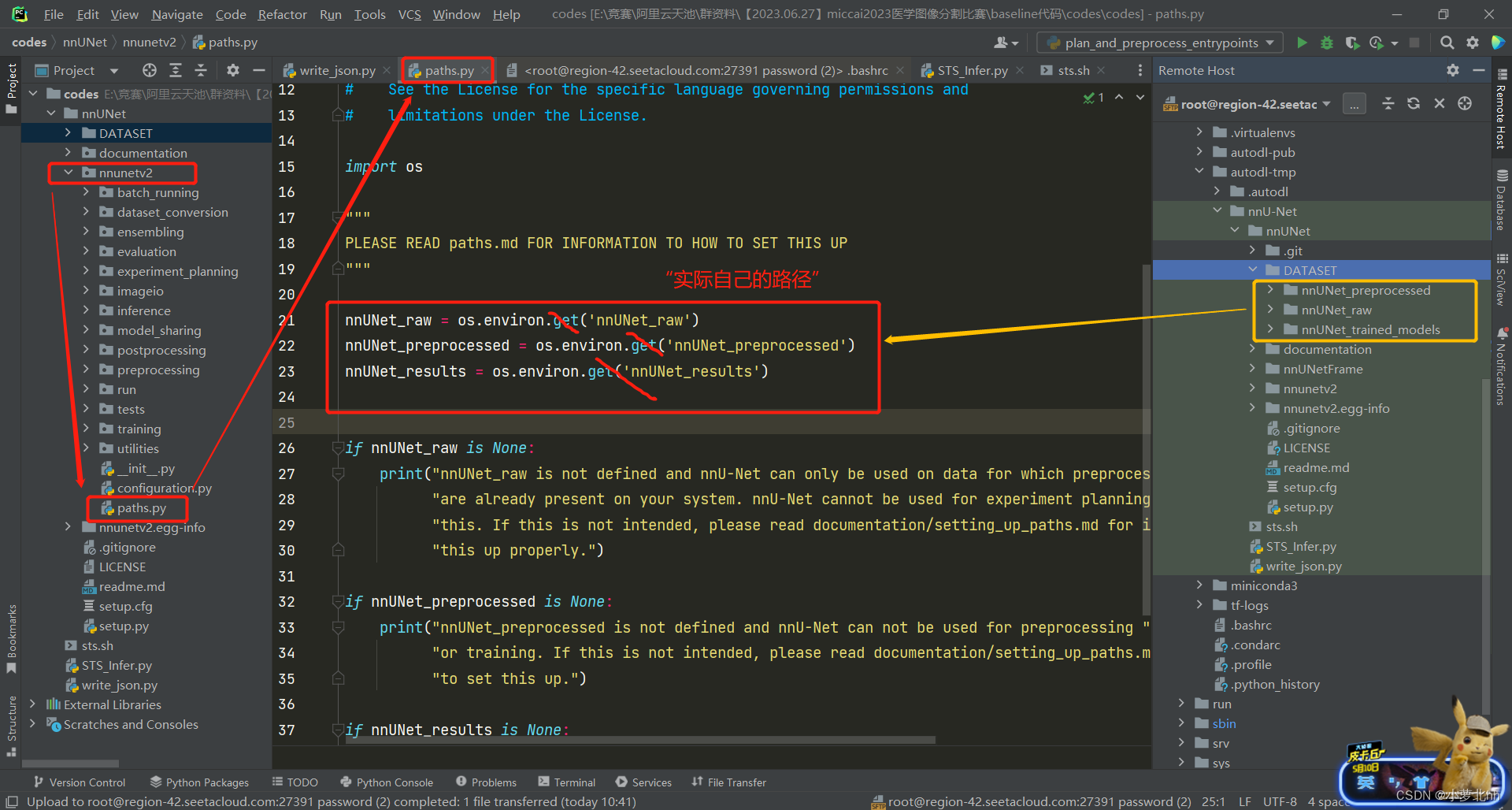
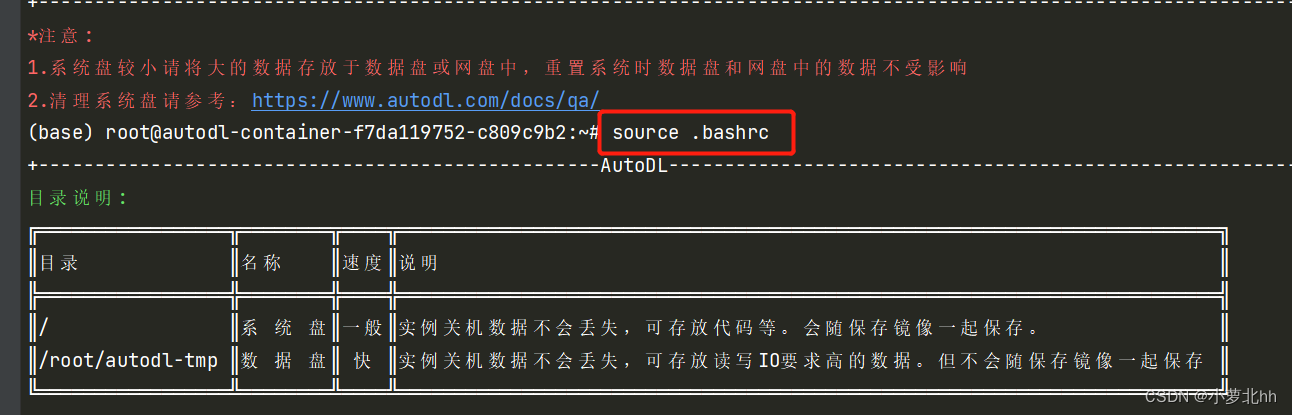
4 注:更新文档可以点击按钮更新,然后在终端使用命令行source .bashrc更新,如下图
(1)
(2)
六、数据集的转换
- 此任务的数据集不需要格式转换,此步骤是为了将数据集转换成上述imageTr文件夹里面图片中显示的样子:
名字_000X的形式 - 数据集转换的指令:
nnUNet_convert_decathlon_task -i /root/autodl-tmp/nnU-Net/nnUNet/DATASET/nnUNet_raw/Dataset001_Teeth
- 1
- 此步骤参考:link
七、数据集预处理
1. 此步骤对数据进行:裁剪crop,重采样resample以及标准化normalization,具体论文中有讲解,或参看此博文:nnU-Net论文解读。将提取数据集指纹(一组特定于数据集的属性,例如图像大小、体素间距、强度信息等)。此信息用于设计三种 U-Net 配置。每个管道都在其自己的数据集预处理版本上运行
2. 继续在虚拟环境中执行一下命令行:
nnUNetv2_plan_and_preprocess -d DATASET_ID --verify_dataset_integrity
- 1
此命令行中的DATASRT_ID根据自己任务修改,此任务中,Dataset001_Teeth 中可知ID为1 所以执行的命令为:
nnUNetv2_plan_and_preprocess -d 1 --verify_dataset_integrity
- 1
具体如下图所示:


3. 运行后将在 nnUNet_preprocessed 文件夹中创建一个以数据集命名的新子文件夹。命令完成后,将出现一个 dataset_fingerprint.json 文件以及一个 nnUNetPlans.json 文件。还有一些子文件夹包含 UNet 配置的预处理数据。

八、模型训练
1. 这是五折交叉验证,可以使用代码直接一折一折接着跑
(1.1) 创建一个tst.sh 文件,并写入此代码:
for fold in {0..4}
do
# echo "nnUNetv2_train 1 3d_lowres $fold"
nnUNetv2_train 1 3d_lowres $fold
done
- 1
- 2
- 3
- 4
- 5
(1.2) 在虚拟环境下的终端运行此 tst.sh 文件,使用 source命令可以执行脚本(参考link),具体命令行为:
source /root/autodl-tmp/nnU-Net/sts.sh
- 1
具体为下图所示:


2. 也可以使用代码一折跑完,再次运行代码跑第二折:
进入虚拟环境,使用命令行:
nnUNetv2_train 1 3d_lowres 0 # 其中1表示数据集ID,上述提及过。0表示第1折
- 1
设置的是1000 epoch,第一折的1000epoch跑结束之后,修改命令行中的折数,即最后一个数:
nnUNetv2_train 1 3d_lowres 1 # 其中1表示数据集ID,上述提及过。1表示第2折
- 1
直到跑完5折交叉验证。
3. 在正常运行代码后遇到的问题:
(1) 不小心碰到键盘或者Ctrl+C会中断实验,此代码会50个epoch保存一下checkpoint ,若中断使用:原来指令后面加--c可以接着运行,用运行第一折时中断为例:
nnUNetv2 train 1 3d_lowres 0 --c
- 1


(2)nohup 后台挂起,使用nohup+运行的命令行+&,这样断网什么的不会影响进程

