- 1AI抗疫,百度如何成为城市治理的“新基建”样本?_后疫情 ai助力城市治理新格局
- 2Python生成随机试卷及答案_python根据题库自动出试卷
- 3【创作赢红包】Nginx四——Nginx实现负载均衡的多种策略_nginx负载均衡策略
- 4【Vite+Vue3+TS】基于Vite+Vue3+TypeScript+ESLint+Prettier+Stylelint搭建项目(亲测超详细)_vue3 vite ts eslint prettier axios
- 5LINUX 解压分卷ZIP_linux 解压zip 多个分文件
- 6论文阅读 (98):Learning from Positive and Unlabeled Multi-Instance Bags in Anomaly Detection (2023KDD)
- 7uniapp 底部导航栏设置_uniapp增加底部
- 8基于JAVA(springboot框架)图书馆书库管理系统 毕业设计开题报告_图书馆管理系统开题报告
- 9双一流高校博士研究生奖助学金汇总_直博生奖学金
- 10因果推断学习笔记(一)_样本重加权
【机器学习】【深度学习】优化器(Optimizer)
赞
踩
一、概述
什么是优化器?
优化器(Optimizer)是深度学习中的一个核心的概念,用于更新神经网络的权重,以减少或最小化损失函数(loss function)的值。损失函数衡量了模型的预测值与真实值之间的差异,而优化器的目标是通过调整网络参数来最小化这个差异,从而提高模型的准确性和性能。
在神经网络训练过程中,优化器在反向传播过程中起着至关重要的作用。反向传播计算了损失函数相当于模型参数的梯度(即损失函数的导数),优化器则使用这些梯度来更新模型的参数。
为什么使用优化器?
- 使用优化器可以提高模型的准确性。优化器通过调整模型的权重和偏置,以最小化损失函数,从而提高模型二点准确性。
- 改善学习速率。优化器能够根据损失函数的梯度调整学习速率,帮助模型更好地学习,同时避免在训练过程中陷入局部最小值。
- 提高训练效率。优化器的选择对模型的训练素的和最终性能有着很大的影响。不同的优化器可能适合不同的任务,和数据集。
二、常见的优化器用处及应用场景
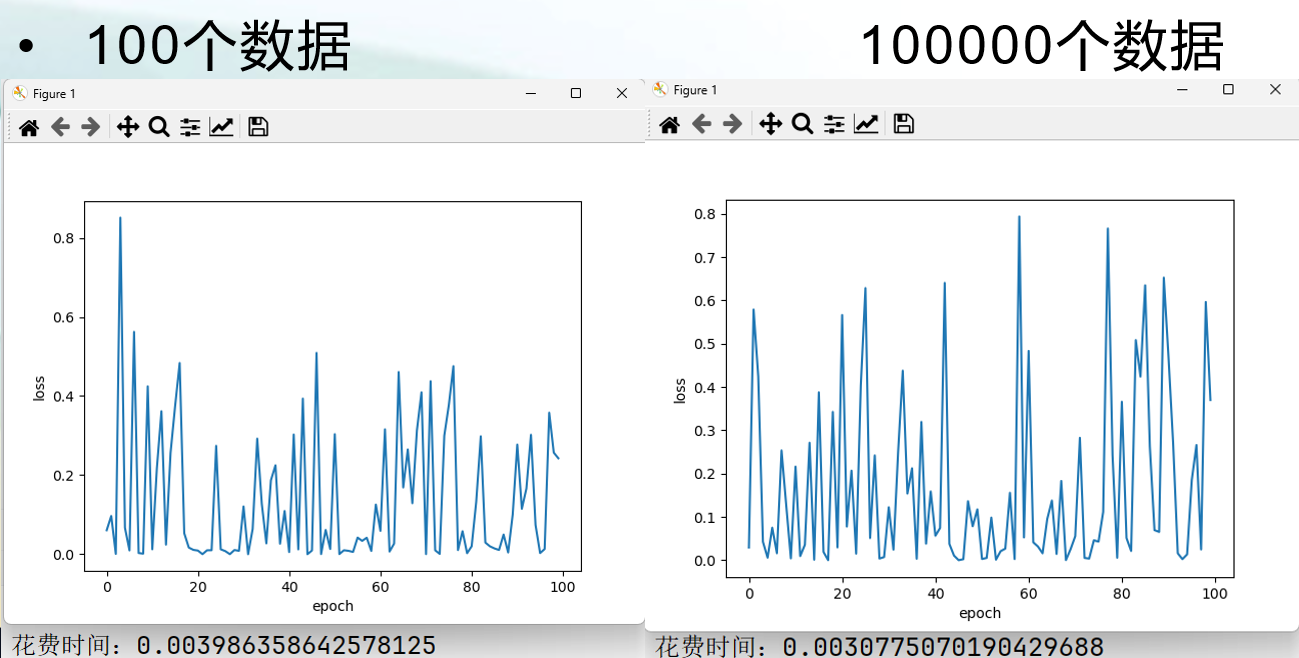
批量梯度下降(BGD)
批量梯度下降(BGD)(Batch Gradient Descent):BGD是最原始的梯度下降方法,每次迭代使用全部训练数据来计算损失函数的梯度,并更新模型参数。
应用场景与特点:
- 小型数据集;
- 准确性高;
- 全局最优解;
- 收敛速度不是关键因素;
- 不适用大型数据集,因为计算成本太高了。
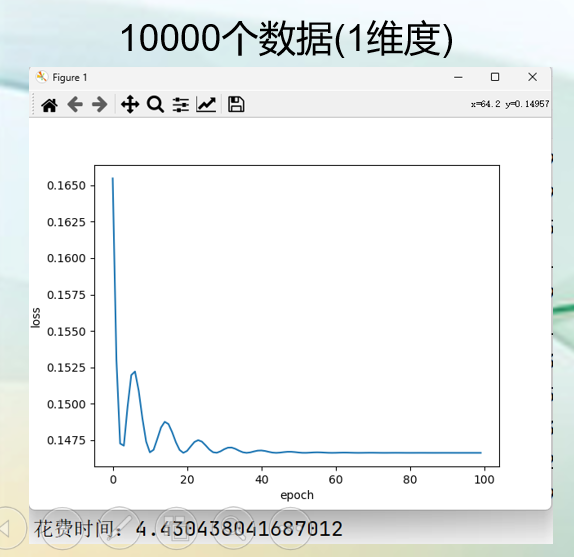
随机梯度下降(SGD)
随机梯度下降(SGD)(Stochastic Gradient Descent):是一种优化模型的算法,SGD每次迭代只随机选择一个样本来计算损失函数的梯度,并更新模型参数。因此其计算量最小,更新速度最快,但是会引发一些随机性。与BGD相比,在大数据集上SGD的优势格外明显。
应用场景与特点:
- 深度学习模型训练:SGD优化器常用于训练神经网络模型,包括卷积神经网络(CNN),循环神经网络(RNN),生成对抗网络(GAN)等;
- 大规模的数据集:SGD优化器通常比传统的批量梯度下降(Batch Gradient Descent)更具优势。因为SGD每次只使用部分样本计算梯度,减少了计算开销,因此适合大规模数据。
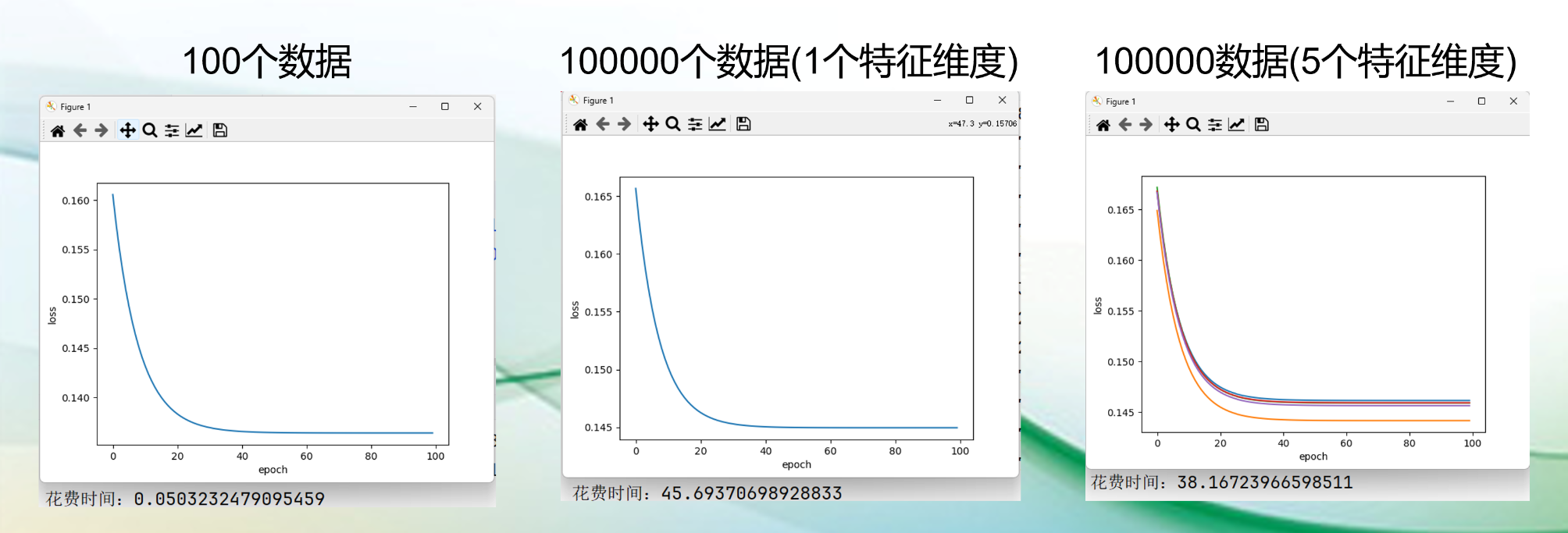
小批量梯度下降(MBGD)
小批量梯度下降(MBGD)(Mini-Batch Gradient Descent):是批量梯度下降(BGD)与随机梯度下降(SGD)的这种方案,即在每一次迭代中使用一小批数据而不是全部数据来更新模型参数。
就是将训练数据集按照较小的批次分割,每次迭代时从这些批次中随机抽取一个进行计算并更新模型参数。这个在训练过程中,每次迭代计算量较小,同时兼顾准确性和随机性,有利于加快收敛速度。
应用场景与特点:
- 大规模数据集,高纬度特征空间,如图像分类,等等;
- 训练深度学习模型,卷积神经网络(CNN),循环神经网络(RNN)等,因为这些模型通常需要大量的数据来进行训练,而且MBGD能很好的接受大规模数据集。
| 优化器名称 | BGD | SGD | MBGD |
|---|---|---|---|
| 优点 | 1. 准确性高 2. 对梯度的估计是无偏的。样例越多,标准差越小。 3. 一次迭代是对所有样本进行计算,此时适用向量化进行操作,实现了并行。(向量化操作,可以参考Numpy的矩阵计算,无需进行for循环) | 1. 只用一个数据梯度更新快. 2. 更新时loss比较动荡,可能会跳出局部最优点,到一个更好的局部最优。 | 结合了BGD,SGD的优点。 |
| 缺点 | 1. 可能对内存要求高 2. 大规模数据集时,计算耗费太大 3. 每次的更新都是在遍历全部样例之后,这时会发现一些样例对于模型参数的更新是没有大用处的。 | 因为每次更新只用一个数据梯度,loss比较动荡,所以比较难收敛到一个准确的极小值,需要调整学习率。 | 1. 收敛速度慢;2. 需要选择合适的批次;3. 内存需求;4. 需要合适的学习率; |
| 使用场景 | 小型数据集,模型简单;准确性高;全局最优解(凸函数最好);并行计算 | 大规模数据。 | 大规模数据;高纬度特征空间。 |

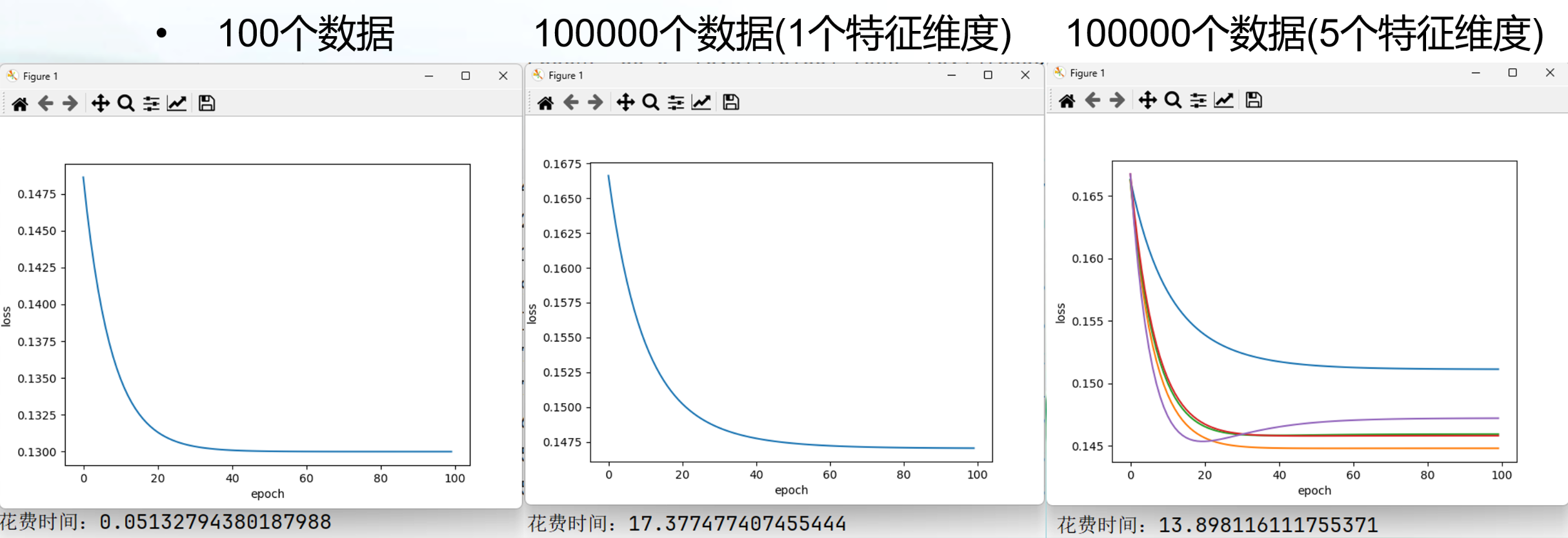
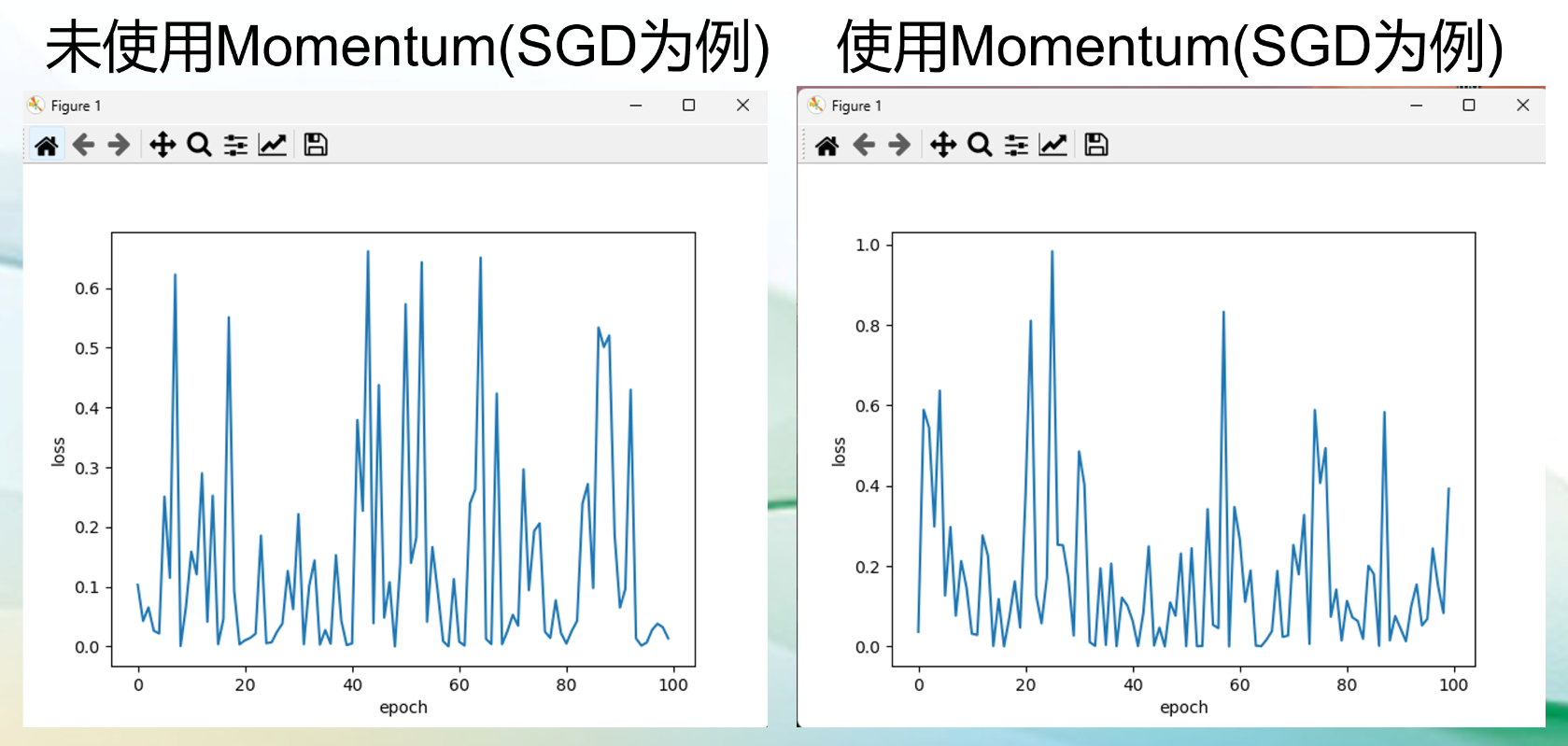
动量(Momentum法)
动量法(Momentum):在深度学习中是一种常用的优化算法,它的作用主要是减少训练过程中的摆动,加速收敛,并帮助模型摆脱局部最小值区域。概念上,动量法通过引入一个累计梯度的指数加权平均,将过去的梯度信息考虑进当前的参数更新中,从而增加稳定性和提高训练效率。
应用场景与特点:
- 用来改进一些优化器,比如随机梯度下降(SGD),小批量梯度下降(MBGD);
- 一些训练过程中摆动较大的模型,可以减少摆动。
SGD是每次选择一个数据进行梯度更新,loss经常反复震荡,这就好比这辆车每开一步就换一个司机(数据产生的梯度),每个司机的想法都不同。
而Momentum虽然使得SGD每一步都要换司机,但是,新的司机必须参考上一个司机的意见(主要是近几次),这样即使在局部最优,新司机觉得应该停止,但是前几位司机认为都应该冲过去,这时新司机就会冲过去,这就避免了局部最优。
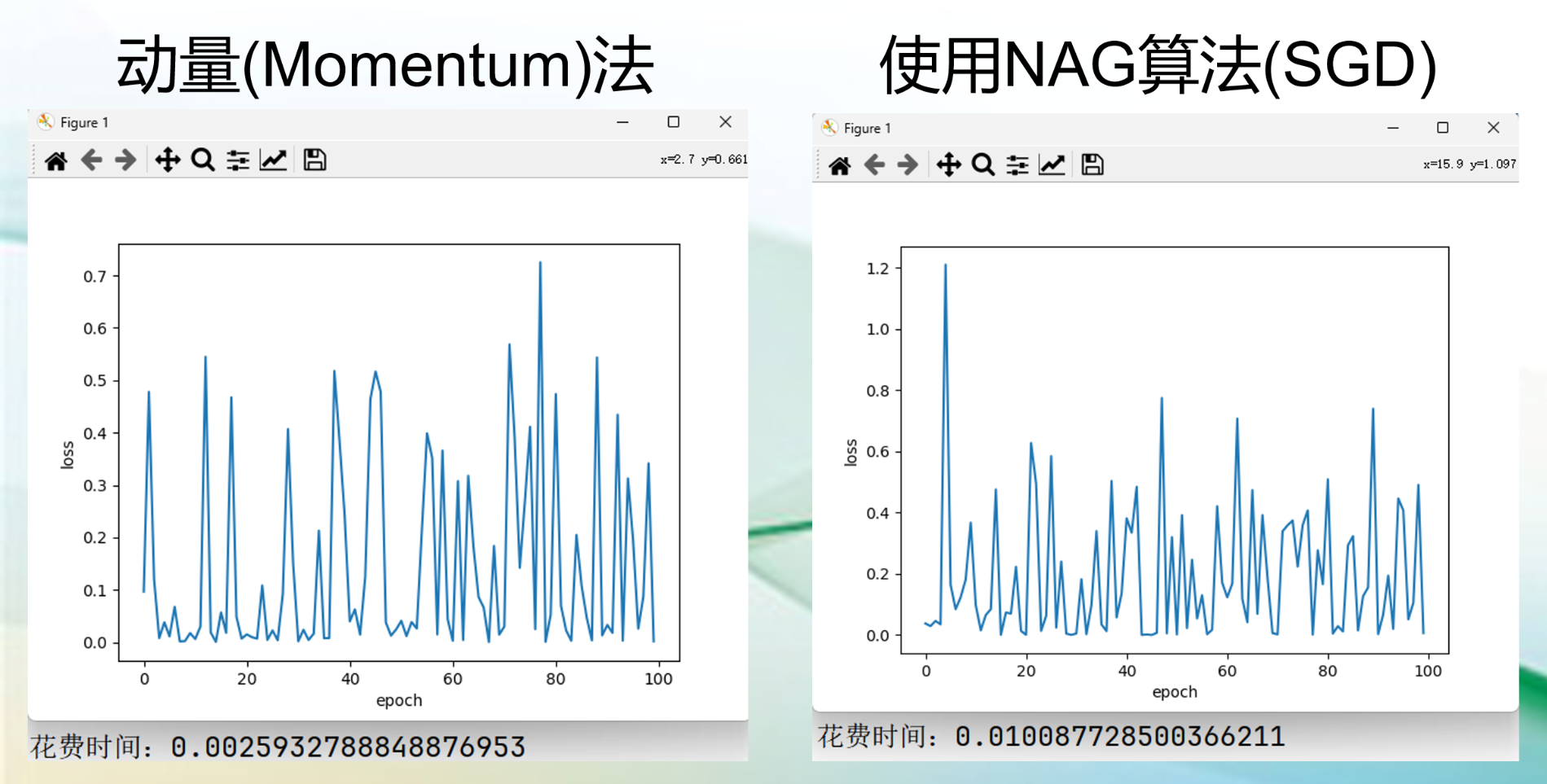
NAG(Nesterov Accelerated Gradient)
NAG(Nesterov Accelerated Gradient):是一种在动量法(Momentum)基础上进行改进的优化算法。它的作用主要是提高训练过程中的收敛速度和稳定性。概念上,NAG先按照之前的动量更新参数,再在这个新的位置计算梯度,并根据此调整更新方向,从而减少摆动,加快收敛。
应用场景与特点:
- 用来改进一些优化器,比如随机梯度下降(SGD),小批量梯度下降(MBGD);
- 一些训练过程中摆动较大的模型,可以减少摆动;
Adagrad(Adaptive Gradient)
Adagrad(Adaptive Gradient):是一种自适应梯度下降的优化器,它对不同参数使用不同的学习率,对于更新频率较低的参数施以较大的学习率,对于更新频率较高的参数使用较小的学习率。通过调整每个参数的学习率,使得模型能够更快的收敛到最优解。
应用场景与特点:
- 大规模的数据集:Adagrad通过自适应调整学习率,减少了在大规模数据集上手动调参的工作量;
- 特征提取:在图像识别和处理任务中,Adagrad可以加速模型对重要视觉特征的学习,尤其是在处理高纬度和稀疏的特征向量时。
Adam
Adam(Adaptive Moment Estimation):是一种梯度下降算法的变体,用于更新神经网络的权重,它结合了AdaGrad和Momemtum两种优化算法的优点,能够快速收敛并且减少训练时间。Adam优化器计算出每个参数的独立自适应学习率,不需要手动调整学习率的大小,因此在实践中被广泛应用(一阶矩估计,二阶矩估计)。
应用场景与特点:
- 处理大规模的数据:Adam优化器因为其计算效率搞而特别适合处理大规模数据。他能够在有限的计算资源下快速迭代更新神经网络权重,这对于处理大型数据集至关重要;
- 训练复杂模型:对于复杂模型,比如神经网络,Adam能够提供稳定而快速的收敛性能。
在训练过程中,loss值越来越小,说明了Adam优化器性能高。