
- 1算法基础 |【01】K-近邻算法_n neighbours参数
- 2Spring Boot 3.0 升级小指南_springboot3升级
- 3vue前端直接使用element-ui的upload组件上传到阿里云OSS存储_elemtui上传文件到阿里oss
- 4【数学模型】层次分析_数学建模层次分析法例题及答案
- 5推荐开源项目: Nuxt-Auth —— 安全便捷的Nuxt 3认证解决方案
- 6stable diffusion如何下载模型?_stable diffusion模型下载
- 7【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 最小配对和(100分) - 三语言AC题解(Python/Java/Cpp)
- 8二次封装 element-plus的Table 表格组件,减少代码臃肿_tableplus 二次封装
- 9Python教程:读取文件有三种方法:(read、readline、readlines)详细用法_简述读文件的三种方式
- 10腾讯优图NCNN详细分析及实践操作(含Yolov5实践)
论文阅读—— BiFormer(cvpr2023)
赞
踩
论文:https://arxiv.org/abs/2303.08810
github:GitHub - rayleizhu/BiFormer: [CVPR 2023] Official code release of our paper "BiFormer: Vision Transformer with Bi-Level Routing Attention"
一、介绍
1、要解决的问题:transformers可以捕捉长期依赖,但是它具有很高的计算复杂性,并占用大量内存。
2、之前研究者解决这个问题的做法,一般都是稀疏注意力:
1)基于手动设计的稀疏模式:在局部窗口或空洞窗口的限制注意力
2)使得稀疏性可以自适应于数据

上面这些方法使用不同的策略融合或者选择和查询无关的键值token,这些token对所有查询共享。但是根据VIT和DETR的可视化结果,不同语义区域的查询对应不同的键值对。
3、所以作者的方法是动态的、查询相关的query-aware,找到最有相关性的键值对。
本文的想法:主要想法是先在区域级别粗略的过滤掉和查询不相关的键值对,这样留下一小部分topk选好的区域routed regions,然后在这些区域上使用细粒度token到token的细粒度注意力机制。
二、方法:
1、Bi-Level Routing Attention

1)输入图片HxWxC,分成SxS个区域,reshape到![]() ,然后求出Q,K,V
,然后求出Q,K,V
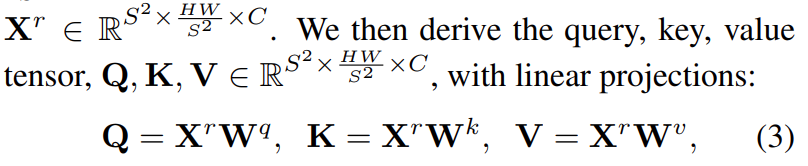
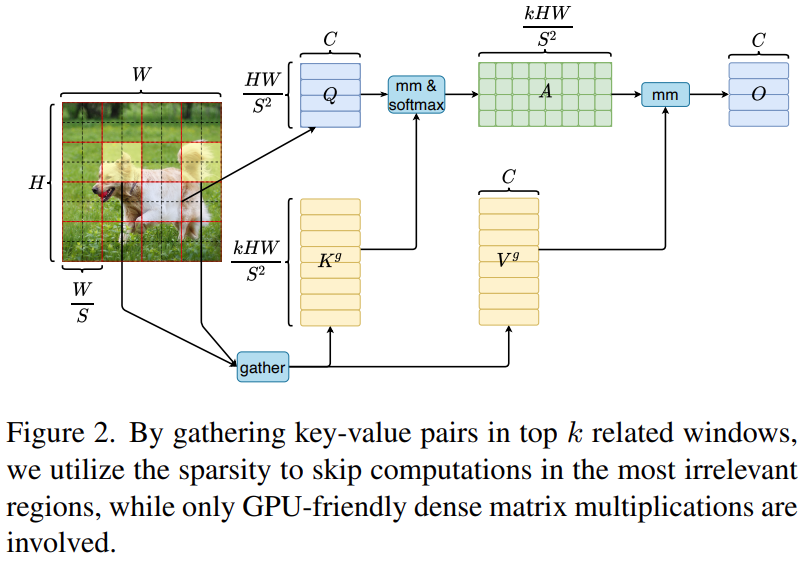
2)求相关区域
每个区域的![]() ,求区域之间的相似性矩阵,文中称为通过矩阵相乘得到的region-to-region affinity graph:
,求区域之间的相似性矩阵,文中称为通过矩阵相乘得到的region-to-region affinity graph:![]() ,衡量了两个区域之间的语义相关性大小。然后选出topk个区域
,衡量了两个区域之间的语义相关性大小。然后选出topk个区域![]() ,I的第i行是最相关的k个区域的索引。
,I的第i行是最相关的k个区域的索引。
3)Token-to-token attention
为了能在GPU并行计算,先把K和V聚集在一起,然后再计算注意力:
![]()
![]()
4)分析得到的提出的BRA(Bi-Level Routing Attention)复杂度![]() ,而一般的注意力复杂度为
,而一般的注意力复杂度为![]() 。
。
2、BiFormer
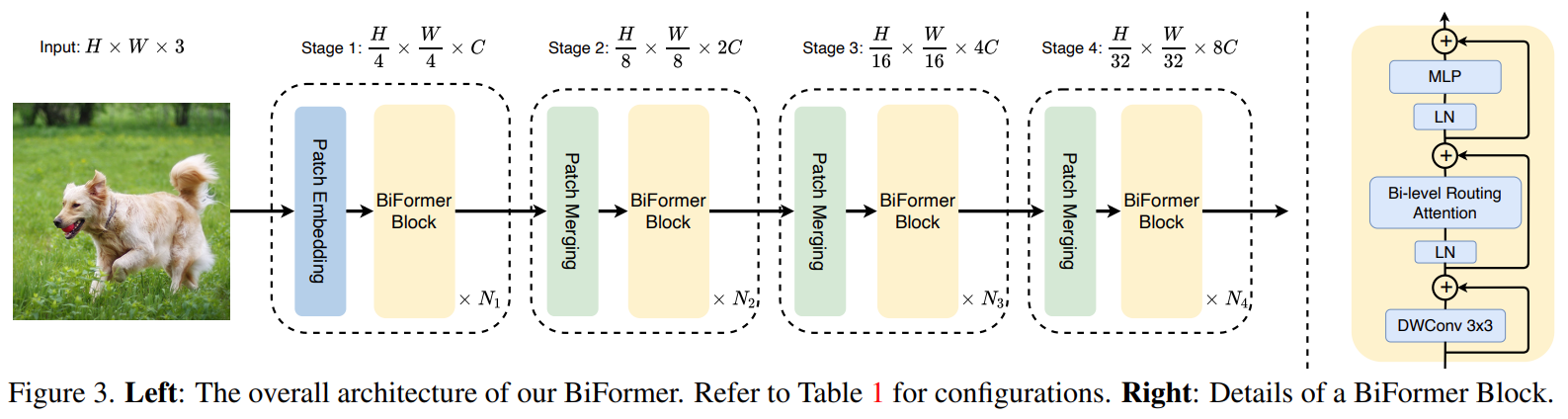
BRA作为基础模块,采用四层金字塔结构。
patch merging module用来减少空间分辨率同时增加通道数。
- 相关标签

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

