
- 1每日一题:C语言经典例题之韩信点兵_c语言韩信点兵问题
- 2golang办公流程引擎初体验js-ojus/flow——系列四_flowprovider golang demoflow
- 3Zookeeper是什么
- 4K8S彻底卸载教程_卸载kubelet
- 5Window环境下mysql读写分离以及主从配置(不错可以的)_window mysql如何读写分离教程
- 6链表C++详解(知识点+相关LeetCode题目)_c++链表
- 7推荐一个在线stable-diffusion-webui,通过文字生成动画视频的网站-Ai白日梦_stablediffusion在线生成
- 8Qwen-14B Ai新手部署开源模型安装到本地_qwen本地部署
- 9静态IP代理哪个好用?_哪家的静态ip好
- 10大型语言模型 (LLM) 的系统消息框架和模板建议_llm下的智能客服的系统架构
Qwen-VL论文阅读
赞
踩
模型结构和参数大小
(1)LLM:Qwen-7B
(2)Vision Encoder:ViT架构,初始化参数是 Openclip’s ViT-bigG。
在训练和推理过程中,输入的图像都被调整到特定的分辨率。
视觉编码器通过将图像分割成步长为14 的块来处理图像,从而生成一组图像特征。
「 224 / 14 = 16 16 x 16 = 256」
(3)VL Adapter:Position-aware Vision-Language Adapter 位置感知 视觉-语言 适配器
主要作用是 压缩图像特征、减少由 长图像特征序列 引起的 效率问题。
这个Adapter 包括 一个 随机初始化的 单层交叉注意力模块 cross-attention
这个模块的 query 是一组可训练的向量,key 是 Vision Encoder 输出的图像特征
「这里的query 经过不断地训练,在图文的对齐上起到了 重要的作用」
这种机制将视觉特征序列压缩到 256 个固定长度。「查询向量的数量太少可能会导致部分视觉信息的丢失,而查询量过多则可能会增加收敛难度和计算成本」
整合 2D绝对位置编码 到 cross attention 中 query 和 key,以减轻图像压缩时的损失
随后,将256长度的压缩图像特征输入给 LLM

Qwen-VL训练的3个阶段
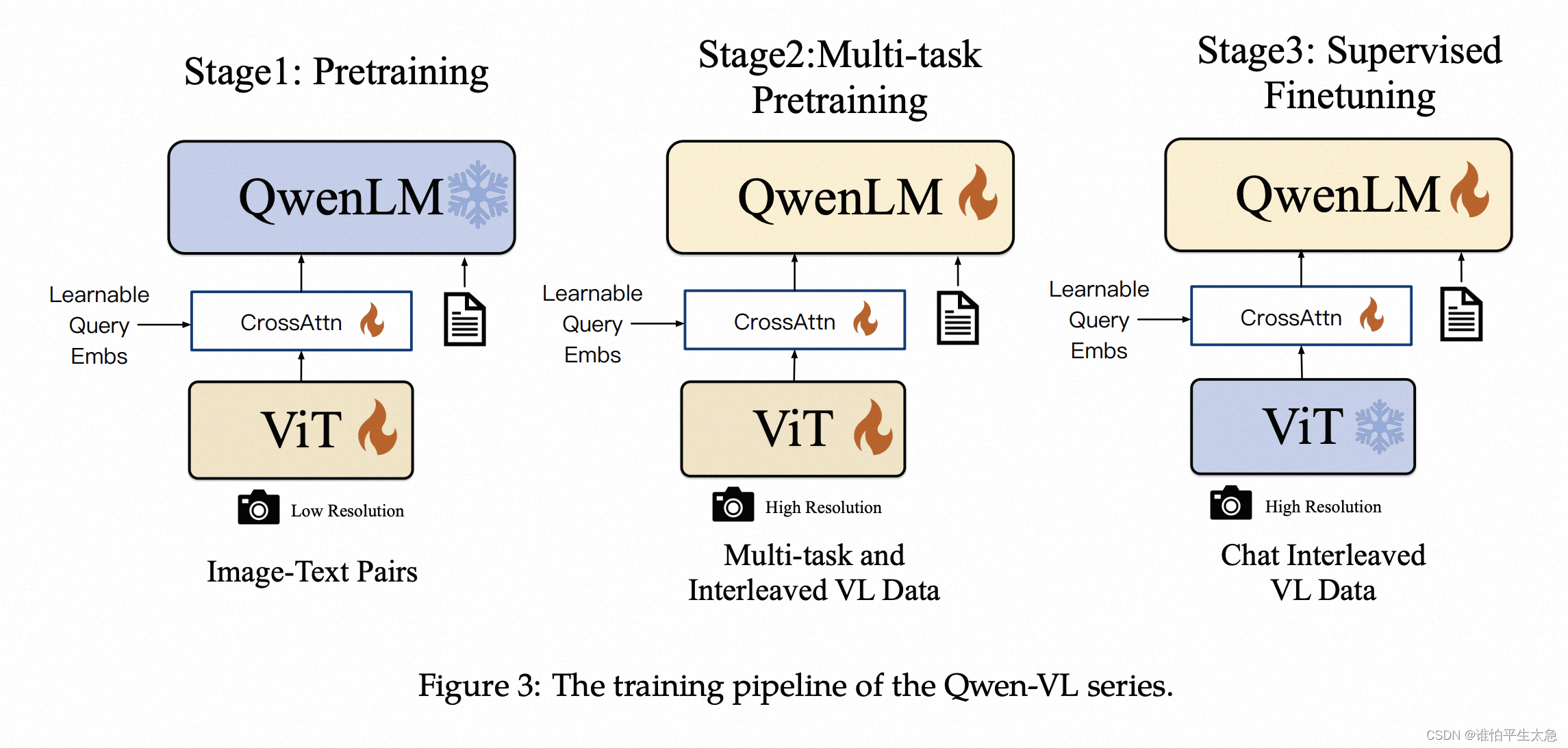
(1)预训练阶段
用 大规模、弱标注、网络爬虫抓取的 14亿图像文本对 数据集,其中 22.7% 中文数据
冻结 LLM的参数,仅对 Vision Encoder 和 VL Adapter 进行优化。
输入的图像大小调整为 224 x 224
训练目标是 文本 token 的交叉熵
最大学习率 2e-4
batchsize为 30720个 图像文本对
持续 50000步的训练
消耗约 15亿图像文本对的样本
这个阶段的目标是 对齐 Vision Encoder 和LLM的特征
(2)多任务训练阶段
用 高质量、细粒度的 VL 标注数据,采用 更大分辨率和交错的 图像文本对 同时进行 7个任务的 训练。
其中 简单地通过将同一任务的数据打包成长度为 2048 的序列来构造 交错的图像-文本数据 (不同训练集的数据)
并且将 Vision Encoder的输入分辨率 从 224 x 224 提升到 448 x 448,减少图像下采样造成的损失
训练目标和预训练阶段相同,但不冻结任一模块
这个阶段的目标是 强化模型的多模态能力
(3)有监督微调阶段
通过指令微调对Qwen-VL预训练模型进行了微调,以增强其遵循指令和多轮对话能力,从而得到了交互式的Qwen-VL-Chat模型
通过优化这个阶段的训练数据,使得模型具备定位和多图像理解能力
同时,通过混合纯文本数据,使得模型具有通用对话能力
这部分指令微调数据总量是 350k
此阶段冻结 Vision Encoder 模块,优化 LLM 和 VL Adapter 模块参数
训练数据示例:
训练目标:回答和特殊标记(如下图蓝色部分) 为了确保预测和训练之间的分布一致性

其他
注意:上述记录、忽略一些的细节,比如 input 和 output等

