
热门标签
热门文章
- 12024年最全Java微服务框架选型,Dubbo和Spring Cloud全解析,满满的干货,netty权威指南_好用的微服务框架
- 2蓝桥杯比赛的语言有php吗,你真的要参加蓝桥杯吗?
- 3Hive函数 date_format 使用示例总结_hive dateformat
- 4PaliGemma视觉大模型目标检测任务微调教程
- 5MongoDB在window上的安装与使用教程_mongodb window 上使用
- 6痞子衡嵌入式:恩智浦i.MX RT1xxx系列MCU启动那些事(8)- 从Raw NAND启动
- 7C语言链表模板,学生管理系统(链表数据写入文本) 。_学生管理系统c语言链表,录入txt文件
- 8SQL server 2012安装教程_sqlserver2012安装如何避免有试用期
- 9vue3从精通到入门3:patch函数源码实现方式_.$patch
- 10Taro开发小程序如何跳转H5页面及踩过的深坑_taro开发h5页面跳转问题
当前位置: article > 正文
Qwen-VL:A versatile vision-language model for understanding,localization,text reading and beyond_qwen-vl: a versatile vision-language model for und
作者:Cpp五条 | 2024-06-11 19:51:21
赞
踩
qwen-vl: a versatile vision-language model for understanding, localization,
1.introduction
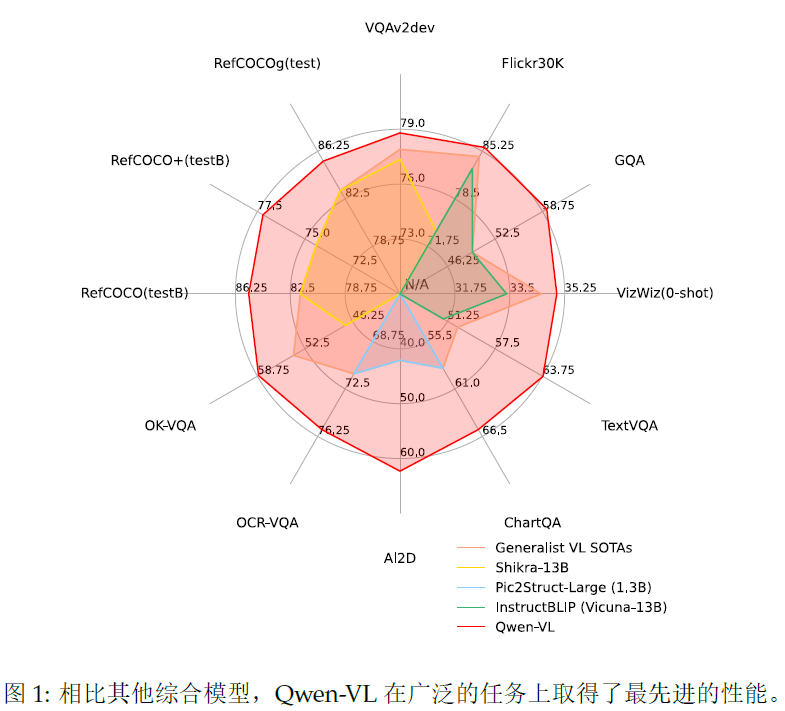
Qwen-VL和QWen-VL-chat,QWen-VL是一个预训练模型,通过连接一个视觉编码器扩展了QWen-7B语言模型的视觉能力,经过三个阶段训练后,QWen-VL具有感知和理解多层次尺度视觉信号的能力,QWen-VL-chat是基于Qwen-VL的交互式视觉语言模型,使用对齐机制。

2.Methodology
2.1 Model architecture
QWen-VL整体网络由三个组件组成,
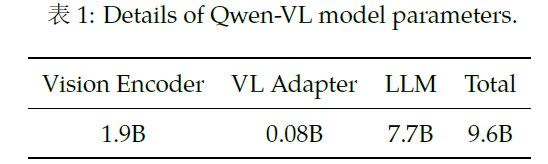
大语言模型:QWen-7B;视觉编码器:ViT,openclip的ViT-bigG的预训练权重初始化,在训练和推理阶段,输入图像会被调整为特定的分辨率,视觉编码器通过将图像划分为大小为14的patch并进行处理,生成一组图像特征;Position-aware Vision-Language adapter&#x
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/704574
推荐阅读
相关标签

