
热门标签
热门文章
- 1全国青少年信息素养大赛图形化编程决赛·模拟三卷,含答案解析_全国青少年信息素养大赛题库
- 2上位机图像处理和嵌入式模块部署(h750 mcu和ad/da电路)
- 3python django web 开源项目,python项目开发案例集锦
- 42024年最新显卡天梯图来了!三种性能测试显卡排行榜_显卡天梯图2024最新排行榜
- 5yolov8实例分割Tensorrt部署C++代码,engine模型推理示例和代码详解_c++模型推理实例代码
- 6Chilloutmix版本升级记录_chilloutmix-ni-pruned-fp16-fix
- 7人工智能行业深度报告:AI下半场,应用落地,赋能百业———————————————— 版权声明:本文为博主原创文章,遵循 CC 4.0 B_国内人工智能技术研发现状
- 8OpenCV学习---级联分类器(人脸检测等)_faces = facecas.detectmultiscale(gray,scalefactor=
- 9Xilinx原语——FPGA学习笔记4_fpga 源语作用
- 10计算机学院毕业生祝福,暖心的毕业祝愿赠言
当前位置: article > 正文
强力推荐一个超级好用的大模型测评工具_大模型评测工具特征测试
作者:AllinToyou | 2024-06-11 20:42:02
赞
踩
大模型评测工具特征测试
在这个千模大战的AI时代,国内很多大厂都在做自己的基础大模型,比如Qwen、Baichuan、文心一言、星火、盘古等等;对于小玩家或者 个人来说使用大模型的最佳方式就是基于这些基础大模型来做微调。
但是对于微调后的大模型效果怎样呢?有没有好的工具去衡量、去评价判断呢?在这里给大家强力推荐一个非常好用的工具,那就是opencompass,中文名称司南,最近在项目中也刚好在使用它,非常方便好用,而且它是一个开源的大模型测试工具,支持很多常用的大模型,测试数据集也很丰富,可以从语言、知识、推理、考试、理解、长文本、安全、代码等多个维度测试大模型的能力。
官网网址:https://opencompass.org.cn/home
github网址: https://github.com/open-compass/opencompass
opencompass是一款面向大模型评测的一站式平台,特点如下:
-
开源:大家都可以方便地使用,而且可以根据自身需要做一些定制开发。
-
全面的能力维度:五大维度设计,提供 70+ 个数据集约 40万题的模型评测方案,全面评估模型能力。
-
丰富的模型支持:已支持 20+ HuggingFace ,同时还支持 模型的API方式。
-
分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测。
-
灵活扩展:可以新增自定义模型和数据集
数据集支

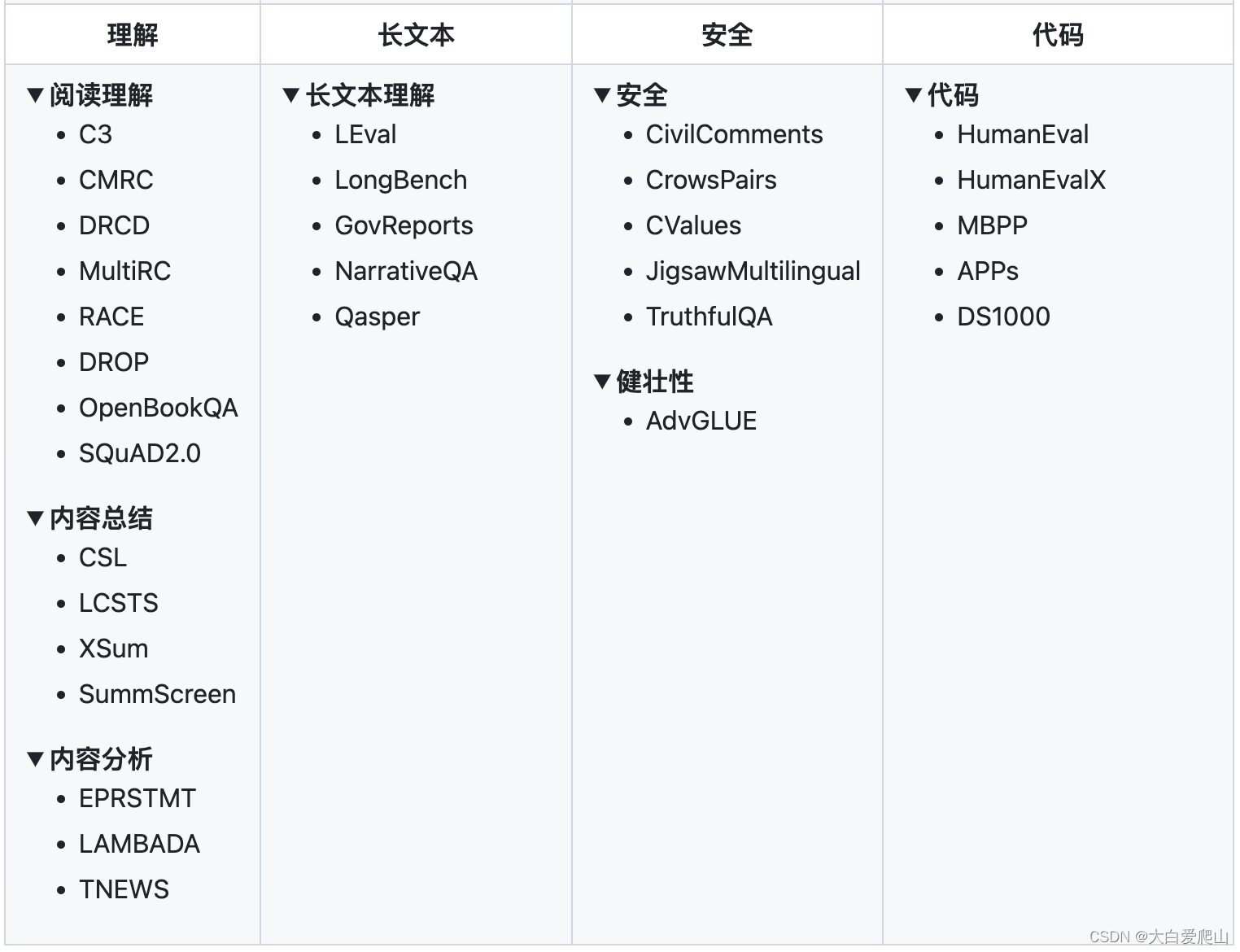
大模型及API支持
除了支持开源大模型本地支持测试,同时还支持已经部署好的大模型的API接口测试。
| 开源大模型 | API模型 |
| InternLM | OpenAI |
| LLaMA | Gemini |
| LLaMA3 | Claude |
| Vicuna | ZhipuAI(ChatGLM) |
| Alpaca | Baichuan |
| Baichuan | ByteDance(YunQue) |
| WizardLM | Huawei(PanGu) |
| ChatGLM2 | 360 |
| ChatGLM3 | Baidu(ERNIEBot) |
| TigerBot | MiniMax(ABAB-Chat) |
| Qwen | SenseTime(nova) |
| Qwen1.5 | Xunfei(Spark) |
| BlueLM | |
| Gemma |
安装使用
具体使用可以参考官方文档或者github。
官方文档:https://opencompass.org.cn/doc
更多最新文章,请关注公众号:大白爱爬山

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/704722
推荐阅读
相关标签

