
- 1油猴的简介和安装
- 2.NET 异步多线程
- 3活动星投票技能创意大赛网络评选微信的投票方式线上免费投票_利用微信小程序 创新评选方式
- 4格子游戏——并查集+二维坐标映射成一维方法_二维到一维的映射不是单射
- 5汇编 | 屏幕显示数字_汇编语言在屏幕上显示数字
- 6docker镜像仓库详解(Docker Registry)_docker load和镜像仓
- 7分治的概念_分治法解题的一般步骤如下: (2.0分) a、 分解,将要解决的问题划分成若干规模较小
- 8学习笔记(2)——使用MATLAB将图像转为灰度图像的批量化处理_matlab批量生成灰度图
- 9【粉丝福利社】AI提示工程实战:从零开始利用提示工程学习应用大语言模型(文末送书-完结)
- 10掌握AI智能化办公:ChatGPT使用方法与技巧指南_chatgpt使用方法与技巧从入门到精通
「多线程大杀器」Python并发编程利器:ThreadPoolExecutor,让你一次性轻松开启多个线程,秒杀大量任务!_threadpoolexecutor 执行多个线程
赞
踩
随着程序复杂度和数据量的不断增加,传统的同步编程方式已经无法满足开发人员的需求。异步编程随之产生,能够提供更高的并发性能和更好的资源利用率。
Python的concurrent.futures模块是一个很好的异步编程工具,它提供了一组接口,可以方便地进行并发编程。
Python中已经有了threading模块,为什么还需要这些线程池、进程池处理呢?以Python爬虫为例,需要控制同时爬取的线程数,比如我们创建了20甚至100个线程,而同时只允许5-10个线程在运行,但是20-100个线程都需要创建和销毁,线程的创建是需要消耗系统资源的,有没有更好的方案呢?
其实只需要同时创建运行5-10个线程就可以,每个线程各分配一个任务,剩下的任务排队等待,当某个线程完成了任务的时候,排队任务就可以安排给这个线程继续执行。

然而自己编写线程池很难写的比较完美,还需要考虑复杂情况下的线程同步,很容易发生死锁。而从Python3.2 开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对 threading 和 multiprocessing 的进一步抽象,不仅可以帮我们自动调度线程,还可以做到:

-
• 主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
-
• 当一个线程完成的时候,主线程能够立即知道。
-
• 让多线程和多进程的编码接口一致。
简介
concurrent.futures 模块是 Python3.2 中引入的新模块,用于支持异步执行,以及在多核CPU和网络I/O中进行高效的并发编程。这个模块提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,简化了跨平台异步编程的实现。
首先,让我们先来理解两种并发编程的方式:
1、多进程
当通过多进程来实现并发编程时,程序会将任务分配给多个进程,这些进程可以在不同的CPU上同时运行。进程之间是独立的,各自有自己的内存空间等,可以实现真正的并行执行。不过,进程之间的通信比较耗时,需要使用IPC(进程间通信)机制,而且进程之间的切换比线程之间的切换耗时,所以创建进程的代价较高。
2、多线程
当通过多线程来实现并发编程时,程序会将任务分配给多个线程,这些线程可以在同一个进程中的不同CPU核上同时运行。线程之间共享进程的内存空间,因此开销比较小。但是需要注意,在Python解释器中,线程是无法实现真正的并行执行,因为Python有GIL(全局解释器锁),它确保同时只有一个线程运行Python代码。因此,一个Python进程中的多个线程并不能并行执行,在使用多线程编程时不能完全利用多核CPU。
简单使用(案例及使用参数说明)
concurrent.futures 是Python中执行异步编程的重要工具,它提供了以下两个类:
1、ThreadPoolExecutor
ThreadPoolExecutor 创建一个线程池,任务可以提交到这个线程池中执行。ThreadPoolExecutor 比ProcessPoolExecutor 更容易使用,且没有像进程那样的开销。它可以让我们在一个Python解释器中进行跨线程异步编程,因为它规避了GIL。
示例:
from concurrent.futures import ThreadPoolExecutor
def test(num):
print("Threads" num)
# 新建ThreadPoolExecutor对象并指定最大的线程数量
with ThreadPoolExecutor(max_workers=3) as executor:
# 提交多个任务到线程池中
executor.submit(test, 1)
executor.submit(test, 2)
executor.submit(test, 3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出结果:
Thread 1
Thread 2
Thread 3
- 1
- 2
- 3
2、ProcessPoolExecutor
ProcessPoolExecutor 创建一个进程池,任务可以提交到这个进程池中执行。当对于单个任务的处理开销很大,例如大规模计算密集型应用,应该使用这个线程池。
示例:
from concurrent.futures import ProcessPoolExecutor
def test(num):
print("Processs" num)
# 新建ProcessPoolExecutor对象并指定最大的进程数量
with ProcessPoolExecutor(max_workers=3) as executor:
# 提交多个任务到进程池中
executor.submit(test, 1)
executor.submit(test, 2)
executor.submit(test, 3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出结果:
Process 2
Process 1
Process 3
- 1
- 2
- 3
等待任务完成
1、ThreadPoolExecutor构造实例的时候,传入max_workers参数来设置线程池中最多能同时运行的线程数目。
2、使用submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄,注意submit()不是阻塞的,而是立即返回。
3、通过submit函数返回的任务句柄,能够使用done()方法判断该任务是否结束。
4、使用cancel()方法可以取消提交的任务,如果任务已经在线程池中运行了,就取消不了。
5、使用result()方法可以获取任务的返回值。查看内部代码,发现这个方法是阻塞的。
在提交任务之后,我们通常需要等待它们完成,可以使用如下方法:
1、result()
用于获取 submit() 方法返回的 Future 对象的结果。该方法是同步的,Block主线程,直至得到结果或者抛异常。
示例:
from concurrent.futures import ThreadPoolExecutor
def test(num):
print("Tasks" num)
# 新建ThreadPoolExecutor对象并指定最大的线程数量
with ThreadPoolExecutor(max_workers=3) as executor:
# 提交多个任务到线程池中,并使用result方法等待任务完成
future_1 = executor.submit(test, 1)
future_2 = executor.submit(test, 2)
future_3 = executor.submit(test, 3)
print(future_1.result())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出:
Task 1
Task 2
Task 3
None
- 1
- 2
- 3
- 4
2、add_done_callback()
给每个 submit() 返回的 Future 对象添加一个“完成时”的回调函数。主线程运行完毕而不需要等待任务完成,这个回调函数会在任务完成时自动执行。
示例:
from concurrent.futures import ThreadPoolExecutor
def callback(future):
print("Task done? ", future.done())
print("Result: ", future.result())
# 新建ThreadPoolExecutor对象并指定最大的线程数量
with ThreadPoolExecutor(max_workers=3) as executor:
# 提交多个任务到线程池中,并添加“完成时”回调函数
future_1 = executor.submit(pow, 2, 4)
future_2 = executor.submit(pow, 3, 4)
callback_future_1 = executor.submit(callback, future_1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
ThreadPoolExecutor类常用方法
ThreadPoolExecutor、ProcessPoolExecutor类下方法名大多都是同样的,只不过因为一个是线程方式、一个是进程方式,底层逻辑实现可能不同。由于我们在日常开发过程中,线程 ThreadPoolExecutor 使用的较多,所以以 ThreadPoolExecutor 为主要使用对象进行说明讲解
当使用 ThreadPoolExecutor 创建的线程池对象后,我们可以使用 submit、map、shutdown等方法来操作线程池中的线程以及任务。
1、submit方法
ThreadPoolExecutor的submit方法用于将任务提交到线程池中进行处理,该方法返回一个Future对象,代表将来会返回结果的值。submit方法的语法如下:
submit(fn, *args, **kwargs)
- 1
其中,fn参数是要执行的函数,*args和**kwargs是fn的参数。
示例:
from concurrent.futures import ThreadPoolExecutor
def multiply(x, y):
return x * y
with ThreadPoolExecutor(max_workers=3) as executor:
future = executor.submit(multiply, 10, 5)
print(future.result()) # 50
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、map方法
ThreadPoolExecutor的map方法用于将函数应用于迭代器中的每个元素,该方法返回一个迭代器。map方法的语法如下:
map(func, *iterables, timeout=None, chunksize=1)
- 1
其中,func参数是要执行的函数,*iterables是一个或多个迭代器,timeout和chunksize是可选参数。
示例:
from concurrent.futures import ThreadPoolExecutor def square(x): return x * x def cube(x): return x * x * x with ThreadPoolExecutor(max_workers=3) as executor: results = executor.map(square, [1, 2, 3, 4, 5]) for square_result in results: print(square_result) results = executor.map(cube, [1, 2, 3, 4, 5]) for cube_result in results: print(cube_result)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3、shutdown方法
ThreadPoolExecutor的shutdown方法用于关闭线程池,该方法在所有线程执行完毕后才会关闭线程池。shutdown方法的语法如下:
shutdown(wait=True)
- 1
其中,wait参数表示是否等待所有任务执行完毕后才关闭线程池,默认为True。
示例:
from concurrent.futures import ThreadPoolExecutor
import time
def task(num):
print("Task {} is running".format(num))
time.sleep(1)
return "Task {} is complete".format(num)
with ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(task, i) for i in range(1, 4)]
executor.shutdown()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
源码分析
cocurrent.future模块中的future的意思是未来对象,可以把它理解为一个在未来完成的操作,这是异步编程的基础 。在线程池submit()之后,返回的就是这个future对象,返回的时候任务并没有完成,但会在将来完成。也可以称之为任务的返回容器,这个里面会存储任务的结果和状态。
那ThreadPoolExecutor内部是如何操作这个对象的呢?下面简单介绍 ThreadPoolExecutor 的部分代码:
1、init方法
init方法中主要重要的就是任务队列和线程集合,在其他方法中需要使用到。
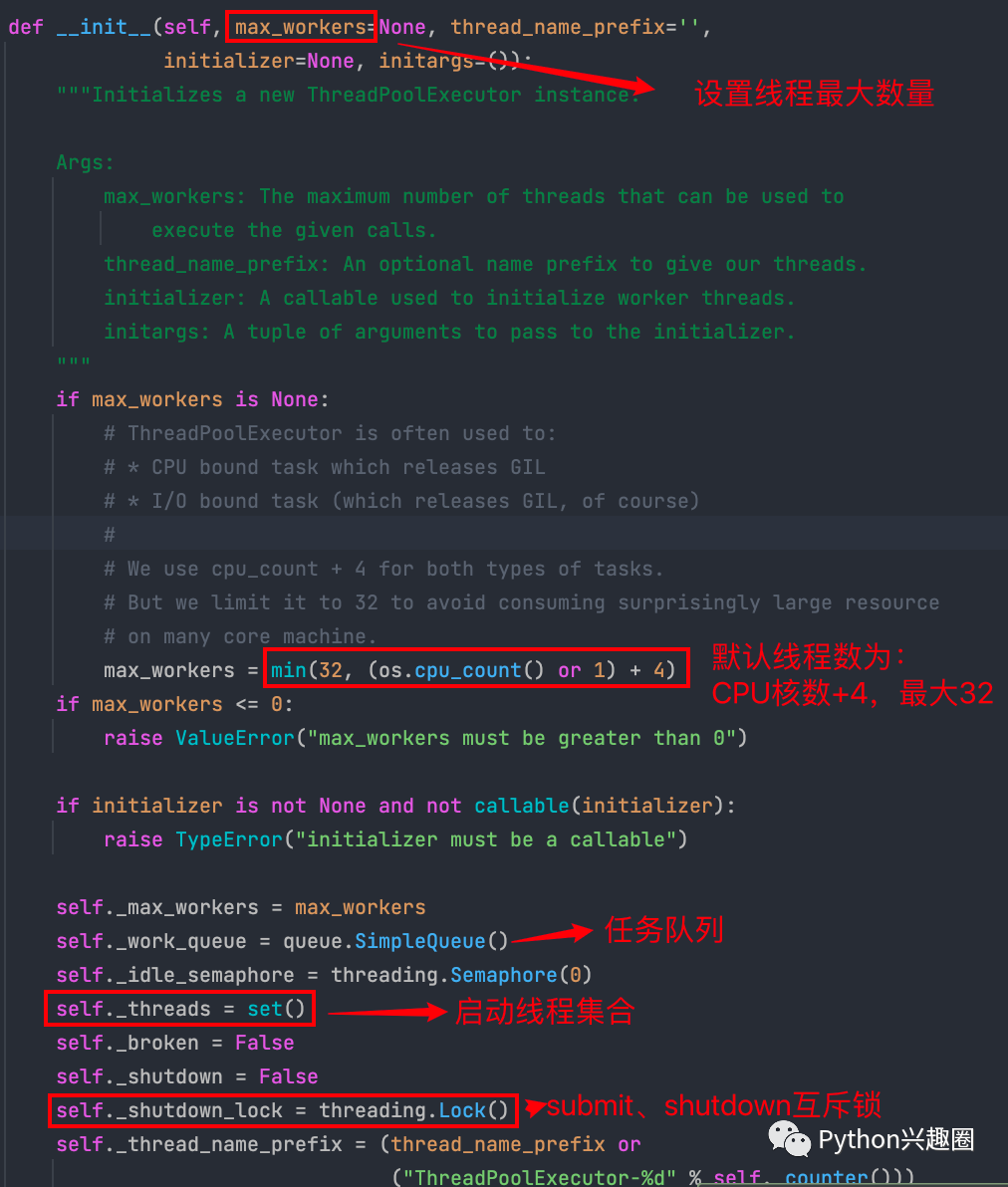
init源码解析
2、submit方法
submit中有两个重要的对象,_base.Future()和_WorkItem()对象,_WorkItem()对象负责运行任务和对**future对象进行设置,最后会将future对象返回,可以看到整个过程是立即返回的,没有阻塞。
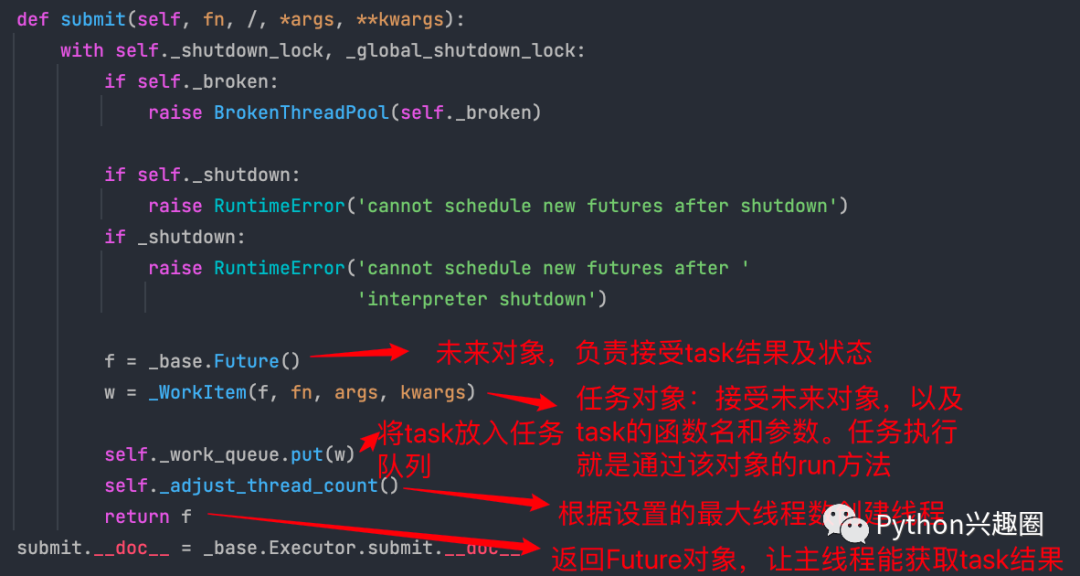
submit源码解析
总结
在Python asyncio模块的基础之上,concurrent.futures模块为Python提供了一种简单高效的异步编程方式,它支持同步、线程、进程等多种并发执行方式,为开发人员提供了更加灵活高效的并发解决方案。我们可以使用submit、map、shutdown等方法来操作线程池中的线程以及任务,使用**Future对象(异步编程的核心)**来管理任务状态,更加方便地进行任务提交、状态管理和线程池的管理和控制。
在实际开发过程中,我们需要根据具体的应用场景,选择适当的异步编程工具和方式,以获得更好的效果。总之,concurrent.futures模块是Python异步编程中一个非常好的利器。
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除

