
- 1m基于遗传优化算法的公式参数拟合matlab仿真_优化的遗传算法matlab程序
- 2java集合面试题:说说 List,Set,Map 三者的区别?三者底层的数据结构?
- 3java11的新特性_java11新特性
- 4C++如何重构操作符_c++重写操作符
- 524张宇八套卷数一复盘(二)_张宇八套卷24
- 6python微信公众号自动推送(十分简单的教程)_python向微信公众号推送消息
- 7AWS学习(一)——AWS云技术基础_aws基础知识
- 8通过Java获取宿主机的资源占用状态。
- 9h5页面内嵌到app,解决ios无法使用左右侧滑返回上一页
- 10 创建前端平移动画为何 translate() 优于 top/right/bottom/left
计算机视觉的应用8-基于ResNet50对童年数码宝贝的识别与分类_resnet50 识别相似度原理
赞
踩
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用8-基于ResNet50对童年数码宝贝的识别与分类,想必做完90后的大家都看过数码宝贝吧,里面有好多类型的数码宝贝,今天就给大家简单实现一下,他们的分类任务。

目录
- 引言
- ResNet50模型简介
- ResNet50模型原理
- ResNet50模型的应用项目
- ResNet50模型用于数码宝贝的识别分类
- 代码实现
- 结论
1. 引言
随着深度学习的发展,卷积神经网络(CNN)在图像识别、语音识别等领域取得了显著的成果。其中,ResNet50模型是一种深度残差网络,以其深度和准确性在众多模型中脱颖而出。本文将详细介绍ResNet50模型的原理,并探讨其在实际项目中的应用。
2. ResNet50模型简介
ResNet50是由微软研究院的Kaiming He等人在2015年提出的深度残差网络(ResNet)。ResNet50中的"50"表示该网络包含50层深度。ResNet模型的主要特点是引入了"残差学习"的概念,有效地解决了深度神经网络中的梯度消失和网络退化问题。
3. ResNet50模型原理
3.1 残差学习
ResNet的核心思想是残差学习。在传统的神经网络中,每一层都在学习输入到输出的映射关系。而在ResNet中,每一层都在学习输入到输出的残差映射,即输出与输入的差值。这样做的好处是,当添加更多的层时,即使新添加的层没有学习到有效的映射,也不会影响已有层的性能,因为新添加的层可以学习到一个接近于零的残差映射。
3.2 残差块
ResNet50模型由多个残差块组成。每个残差块包含三个卷积层,分别是1x1、3x3和1x1的卷积,用于降维、处理特征、升维。这种设计使得模型在保持相同复杂性的情况下,能够有更深的网络结构。
4. ResNet50模型的应用项目
4.1 图像分类
ResNet50模型在图像分类任务中表现出色。例如,可以使用ResNet50模型对CIFAR-10数据集进行分类。通过预训练的ResNet50模型,可以在短时间内达到很高的分类准确率。
4.2 物体检测
ResNet50模型也常用于物体检测任务。例如,可以使用ResNet50作为Faster R-CNN的基础网络,进行物体检测。ResNet50的深度和准确性使得它在这种任务中表现优秀。
4.3 人脸识别
ResNet50模型在人脸识别任务中也有广泛应用。通过对ResNet50模型进行微调,可以用于人脸识别任务,实现高精度的人脸识别。
5. ResNet50模型用于数码宝贝的识别分类
ResNet50在ImageNet数据集上取得了很好的性能,并且可以用于其他类似的图像分类问题,包括数码宝贝的识别分类。
数码宝贝的识别分类是指将不同种类的数码宝贝图像分为不同的类别。使用ResNet50模型进行数码宝贝的识别分类可以通过以下步骤进行:
数据准备:收集数码宝贝的图像数据集,并将其分为训练集和测试集。确保数据集中包含各种不同种类的数码宝贝图像,并且每个类别都有足够数量的样本。
数据集下载地址:
链接:https://pan.baidu.com/s/1_s4HLhDoKplsxvzaK3vQ6A?pwd=32cn
提取码:32cn
模型训练:使用训练集的图像数据来训练ResNet50模型。在训练过程中,模型将学习从图像中提取有用的特征,并将这些特征用于分类任务。训练过程可能需要较长的时间,特别是在大型数据集上。
模型评估:使用测试集的图像数据来评估已训练的ResNet50模型的性能。通过计算模型在测试集上的准确率、精确率、召回率等指标,可以了解模型在数码宝贝识别分类任务上的表现。
预测和应用:使用已训练的ResNet50模型对新的数码宝贝图像进行预测和分类。将待分类的图像输入到模型中,模型将输出一个预测结果,表示该图像属于哪个数码宝贝类别。
需要注意的是,为了成功应用ResNet50模型进行数码宝贝的识别分类,需要有足够的训练数据,并且数据集应该具有良好的类别平衡,即每个类别的样本数量应该相对均衡。此外,模型的性能还受到训练参数的选择、数据预处理方法等因素的影响。
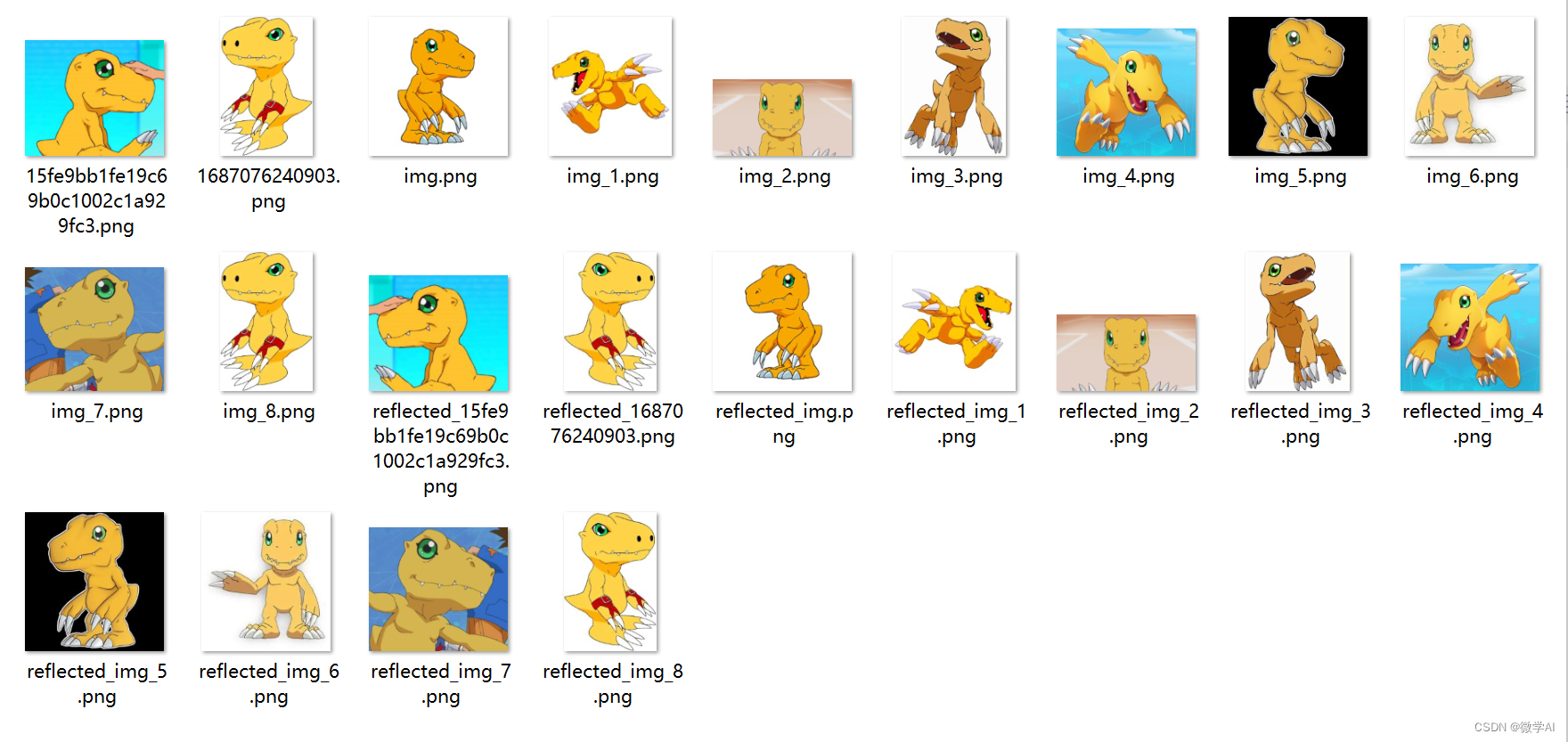
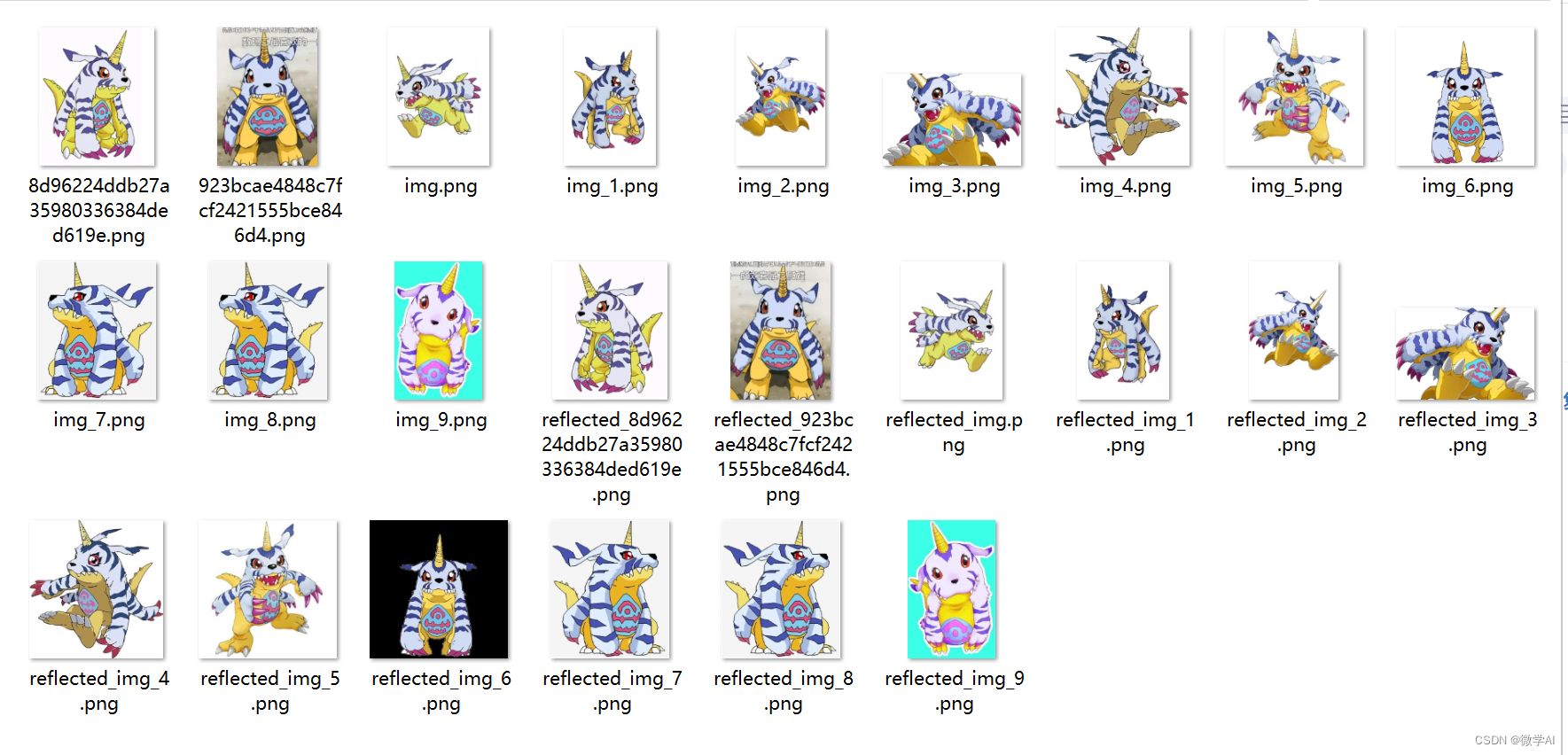
6. 代码实现
import torch from torchvision import datasets, transforms, models from torch.utils.data import DataLoader import matplotlib.pyplot as plt import numpy as np # 设置随机种子以保证结果可复现 np.random.seed(1) torch.manual_seed(1) data_dir = "Digital_baby" data_dir_val = "Digital_baby_val" # 定义图像转换 train_transforms = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) # val_transforms = transforms.Compose([ # transforms.Resize((224, 224)), # transforms.ToTensor(), # transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # ]) # 使用ImageFolder加载数据集 train_dataset = datasets.ImageFolder(data_dir, transform=train_transforms) val_dataset = datasets.ImageFolder(data_dir, transform=train_transforms) # 使用图像数据集和转换定义dataloaders train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=8) # 加载预训练的ResNet50模型 model = models.resnet50(pretrained=True) # 冻结参数,这样我们就不会通过它们进行反向传播 for param in model.parameters(): param.requires_grad = False # 改变ResNet50模型的最后一层以进行迁移学习 fc_inputs = model.fc.in_features model.fc = torch.nn.Sequential( torch.nn.Linear(fc_inputs, 2048), torch.nn.ReLU(), torch.nn.Dropout(0.4), torch.nn.Linear(2048, 2), # 假设我们有2个类 torch.nn.LogSoftmax(dim=1) # 用于NLLLoss() ) # 定义优化器和损失函数 loss_func = torch.nn.NLLLoss() optimizer = torch.optim.Adam(model.parameters(),lr=1e-5) # 开始训练循环 num_epochs = 15 for epoch in range(num_epochs): model.train() # 设置模型为训练模式 train_loss = 0.0 train_corrects = 0 for inputs, labels in train_loader: optimizer.zero_grad() outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = loss_func(outputs, labels) loss.backward() optimizer.step() train_loss += loss.item() * inputs.size(0) train_corrects += torch.sum(preds == labels.data) epoch_loss = train_loss / len(train_dataset) epoch_acc = train_corrects.double() / len(train_dataset) print('{}/{}: Train Loss: {:.4f} Acc: {:.4f}'.format(epoch,num_epochs,epoch_loss, epoch_acc)) model.eval() # 设置模型为评估模式 val_loss = 0.0 val_corrects = 0 for inputs, labels in val_loader: outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = loss_func(outputs, labels) val_loss += loss.item() * inputs.size(0) val_corrects += torch.sum(preds == labels.data) epoch_loss = val_loss / len(val_dataset) epoch_acc = val_corrects.double() / len(val_dataset) print('Val Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc)) print('') # 加载一张图片进行预测 from PIL import Image img = Image.open("img_2.png") # 请替换为你的图片路径 img = train_transforms(img).unsqueeze(0) model.eval() with torch.no_grad(): output = model(img) _, predicted = torch.max(output, 1) print('Predicted: ', ' '.join('%5s' % train_dataset.classes[predicted[j]] for j in range(1)))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
7. 结论
ResNet50模型以其深度和准确性,在图像分类、物体检测、人脸识别等任务中都表现出色。其引入的残差学习概念,有效地解决了深度神经网络中的梯度消失和网络退化问题。未来,ResNet50模型在更多领域的应用,值得我们期待。

