
- 1《操作系统真象还原》第四章_lgdt
- 2华为三层、二层交换机实现不同vlan不同网段之间互通_三层交换机和二层交换机互通
- 3R语言ggplot2可视化:gghalves包可视化半边图、geom_half_boxplot函数可视化分组半边箱图、设置side参数为r或者right只显示右侧半边图像_r语言ggplot2如何画半边热图
- 4全局变量,外部变量,指针的简单表示和一些规范_全局变量指针指向的区间是全局变量吗
- 5git 从git log --graph命令输出结果中查看版本进化大致过程以分支合并原理
- 6关于python下划线命名的事儿以及magic变量相关_编程命名 magic
- 7vscode 配置 Remote-SSH_vscode remote ssh配置
- 8spring mvc 输出 json 异常日志、异常国际化处理_json转换异常,日志可以看到传递的参数吗
- 9不能输入某个字母或特殊符号的正则表达式_正则表达式不允许输入特殊符号
- 10CrossOver 23 .6 Mac中文版CrossOver 2024最新功能介绍
编程实现路由算法_“网络编程” 还是 “可编程网络”?
赞
踩
| 报文编码 | 基于目的IP地址的最长匹配做查询 |
| 软件结构 | 在软件算法上优化,使用Tree查找和Cache优化 |
| 硬件结构 | 大量基于MIPS指令集的CPU进行软件转发,后期逐渐出现了基于总线的分布式转发架构,例如Cisco的7500系列路由器 |
| 报文编码 | MPLS简化核心路由表条目数 |
| 软件结构 | 软件结构相对稳定没有太大变化 |
| 硬件结构 | 专用处理器繁荣的十年,各种专用芯片来做Offload,加密芯片,TCAM查表,各种基于微码的网络处理器,Fabric逐渐采用CLOS架构构建多机集群. |
| 报文编码 | VXLAN和Overlay的兴起 |
| 软件结构 | 软件转发的回归,DPDK/VPP等开源软件的出现 |
| 硬件结构 | 多核通用处理器性能越来越强,SR-IOV的出现,核心交换芯片越来越强并支持虚拟化 |
| 报文编码 | SegmentRouting,数据包即指令 |
| 软件结构 | 容器技术的出现,CNI触发Host Overlay,尽量采用协处理器或者网络设备卸载负担, P4等通用网络编程语言的出现 |
| 硬件结构 | 可编程交换芯片的出现,各种SmartNIC方案盛行,低延迟通信的需求日益增加,特别是AI带来的快速I/O响应 |
| 报文编码 | QUIC+SR |
| 软件结构 | 给更多的终端以后浪般的选择的权力 |
| 硬件结构 | 智能都在设备上了,网络可以简单一点了 |
一开始的路由器其实是叫服务器的,1986年思科发布的AGS(Advanced Gateway Server). 而Cisco IOS本质上不就是一个软件的操作系统么.

最早的报文处理系统就是软件的,当然密级高的资料我是不会说的,接下来每个资料我都会引用公开的文档以免惹来麻烦,第一本公开文档就是一本老书

那个年代也是极力的从软件算法上优化,最早的时候就是进程交换,如下图所示,在操作系统上执行一个转发进程,每个包进来都走这个进程去查询路由表,然后转发:
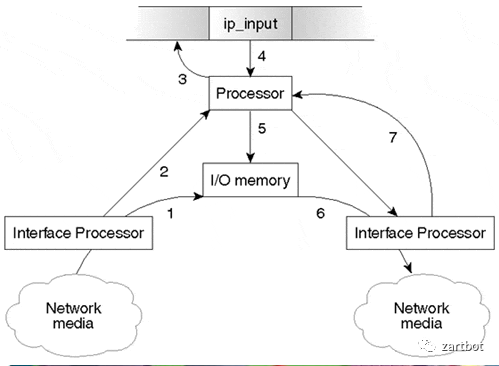
但是这样是不是太蠢了点,每个报文都要查询一次路由表,随着网络规模的扩大,路由表多了就发现性能有问题了,所以后面出现了所谓的快速交换,也就是增加了一个Cache用于路由查询,也就是我们常说的Fast Switching。后来随着路由表规模进一步加大,然后只能在数据结构上改了, 也就是逐渐出现的基于各种树的查询, 例如Linux Kernel很长一段时间都在使用Radix Tree,而Cisco也是从RadixTree到后期的CEF。
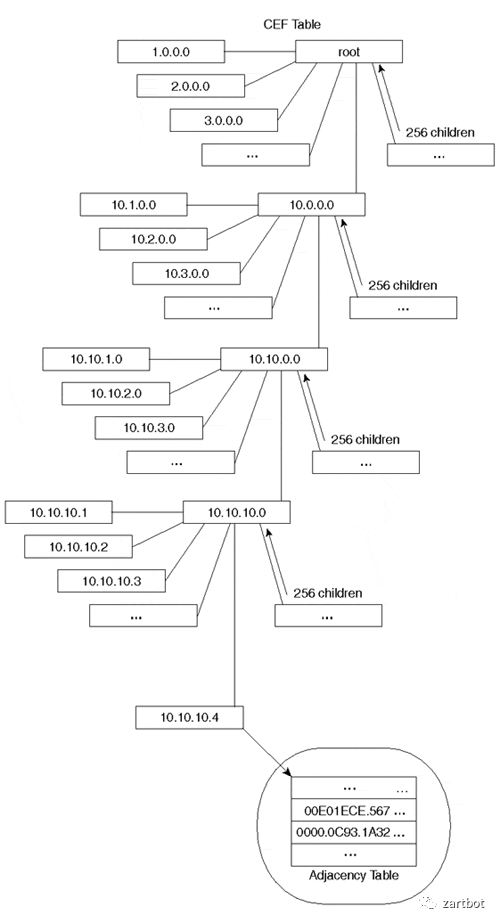
其实从这个时代来看,网络通信数据量并不是太大,协议也相对复杂,更多的是通过IP协议和其它各种协议互通互联,通信需求来看也基本上是在100Mbps处理能力以内,用软件转发是相对较好的解决方案,这一时代的很多产品都是基于MIPS处理器实现的,所以本质上CPU内部还是执行的标准的MIPS指令集, 而路由器的升级更多的就是CPU的升级,从最早AGS使用的Motorola 68000,到后面开始采用 R4600, R4700,到后期的R5000, 总线结构从最早的私有的Cisco Cbus到后期标准的PCI总线的PA卡,以及CyBus这些东西,本质上结构并没有太多的变化:
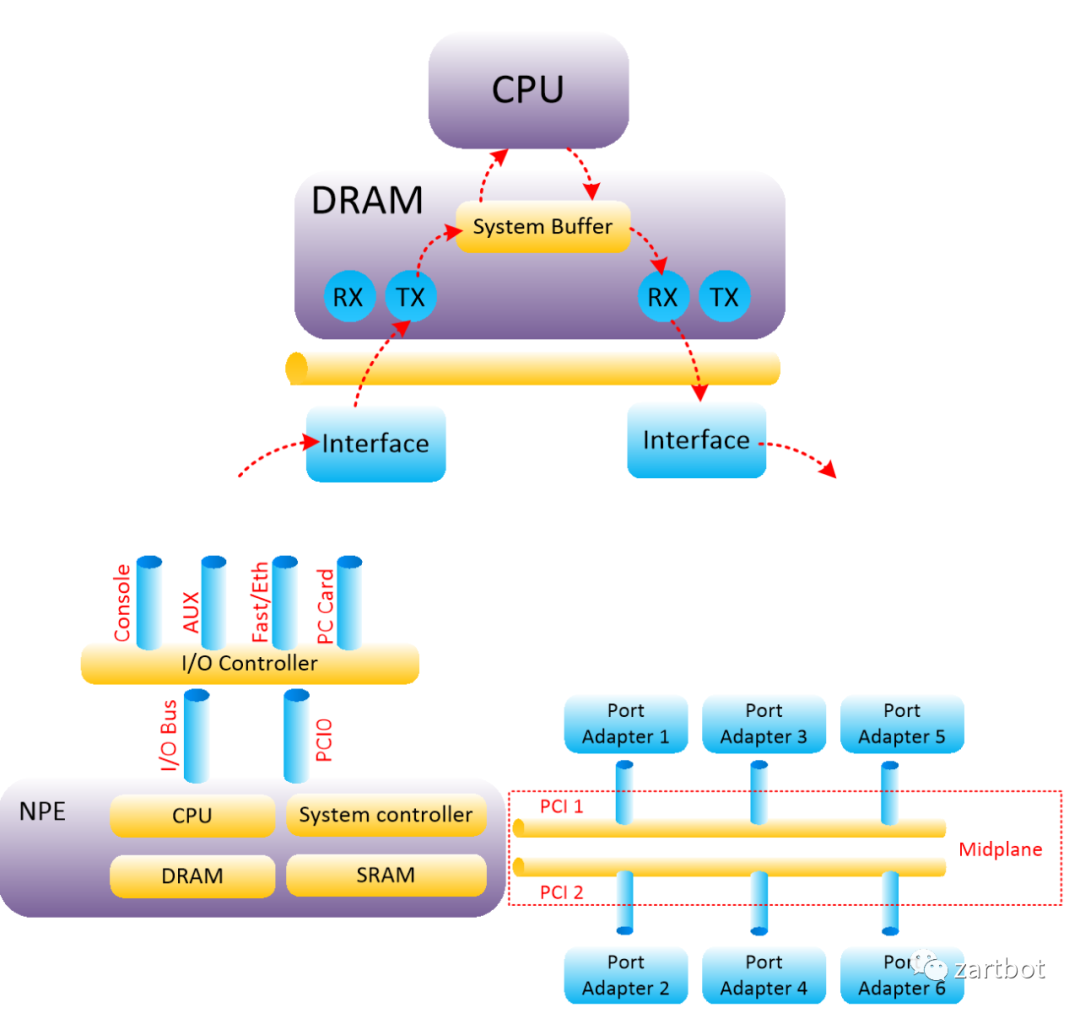
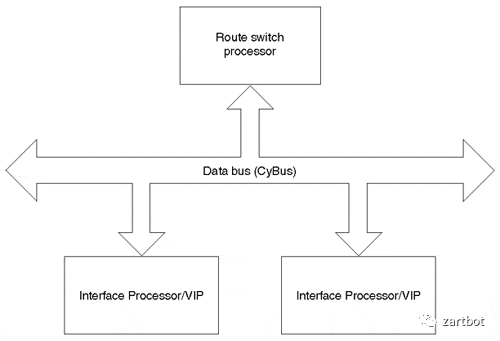
| 报文编码 | 基于目的IP地址的最长匹配做查询 |
| 软件结构 | 在软件算法上优化,使用Tree查找和Cache优化 |
| 硬件结构 | 大量基于MIPS指令集的CPU进行软件转发,后期逐渐出现了基于总线的分布式转发架构,例如Cisco的7500系列路由器 |
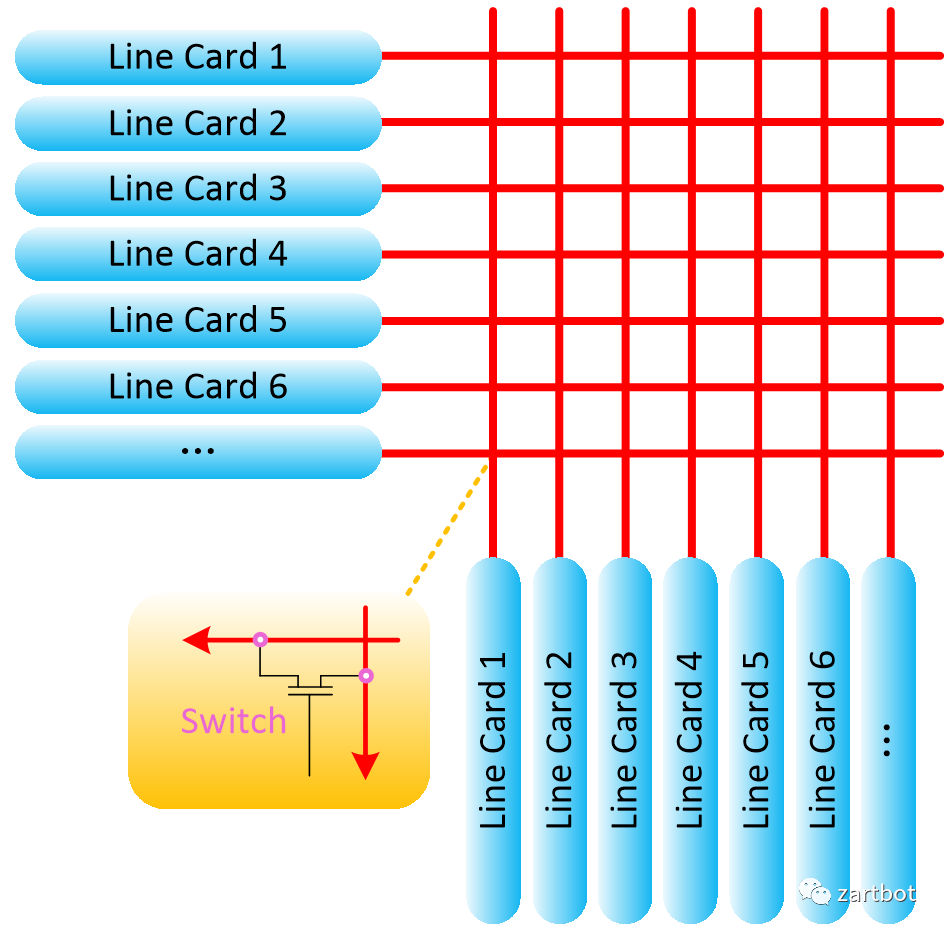
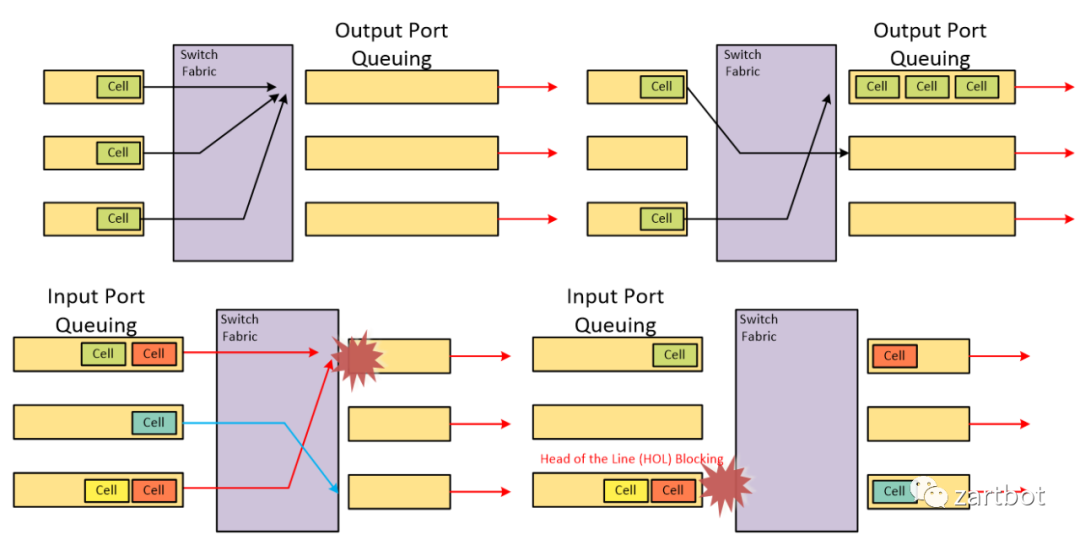
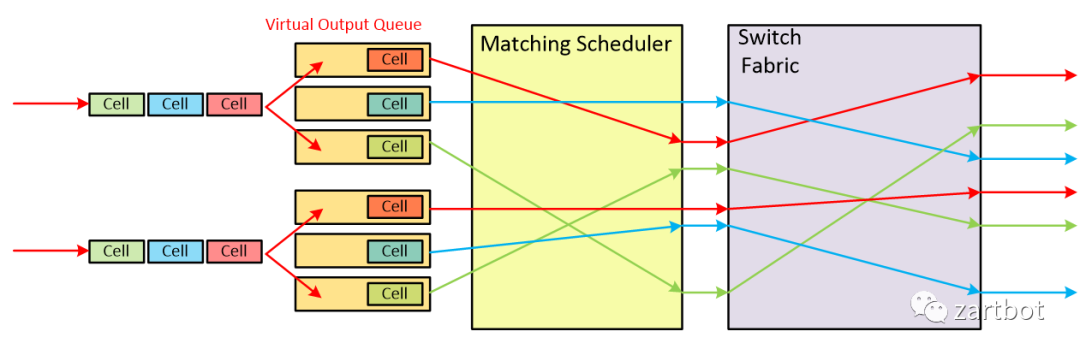
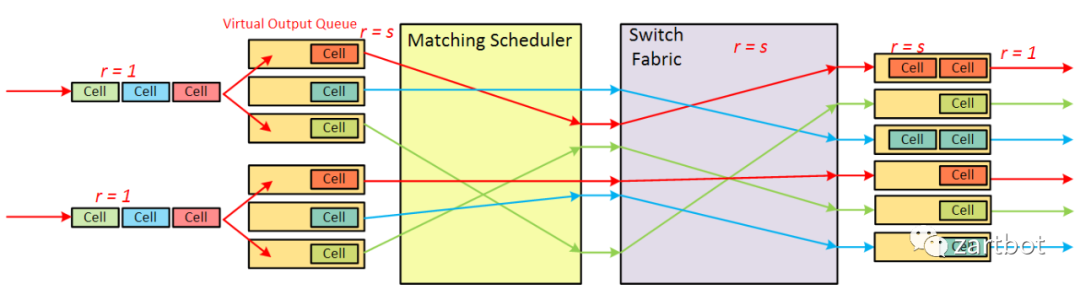
对于VOQ的解决方案, 核心部分在"matching Scheduler"上, 如何调度将是一个难题. 其数学模型实质上是一个二分图匹配的问题. (敲黑板:华为任总说的数学很重要)通常调度算法被分为两类, 最大匹配(maximum size matching, MSM)是指边数达到最大,而最大权重匹配(maximum weight matching, MWM)是指边的权重之和达到最大.由于这两种算法具有复杂度高、硬件实现复杂等缺点, 在实际应用中, 我们一般用极大匹配(maximal matching)近似最大匹配. 所谓的极大匹配是指在当前已完成的匹配下, 无法再通过增加未完成匹配的边的方式来增加匹配的边数或权重.
这也就是日后那个引领SDN的Nick教授搞的事情:Cisco GSR 12000上实现了基于VOQ+iSLIP调度的算法. 如下左图所示: 在使用共享总线的架构中, 仅有最大吞吐量的25%, 使用不带VOQ的FIFO队列时, 吞吐量为最大值的58.6%. 而如果使用变长报文而不使用Cell模式转发, 则吞吐量大约为最大值的60%. 使用VOQ+iSLIP的方式后, 吞吐量为100%, 非常接近理论的最大值.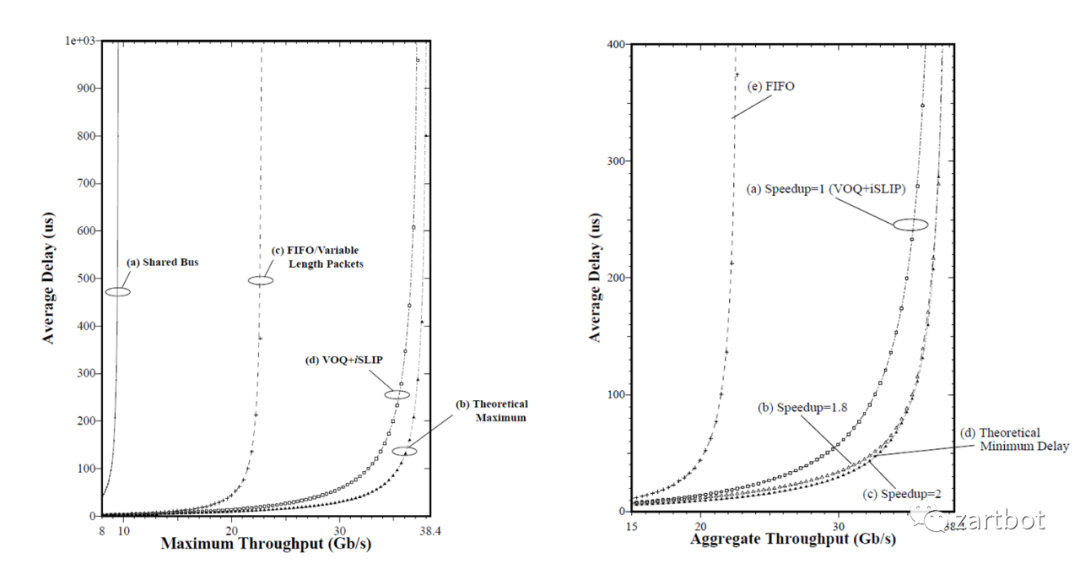
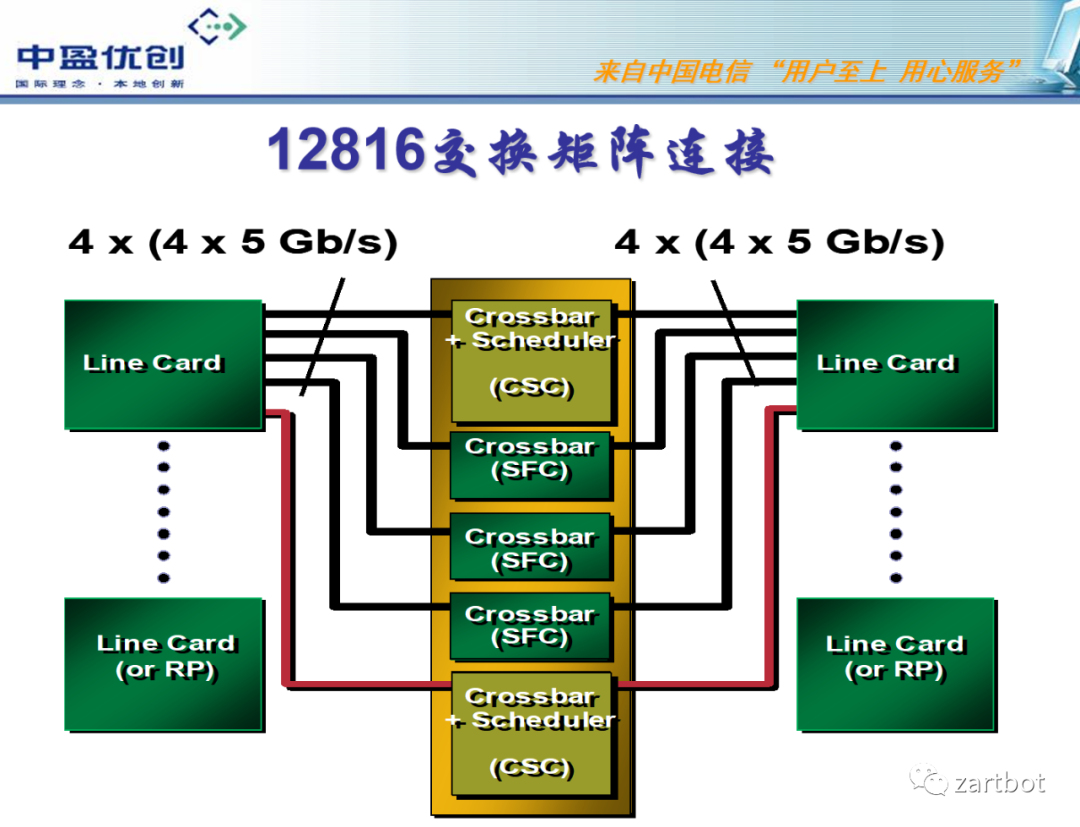
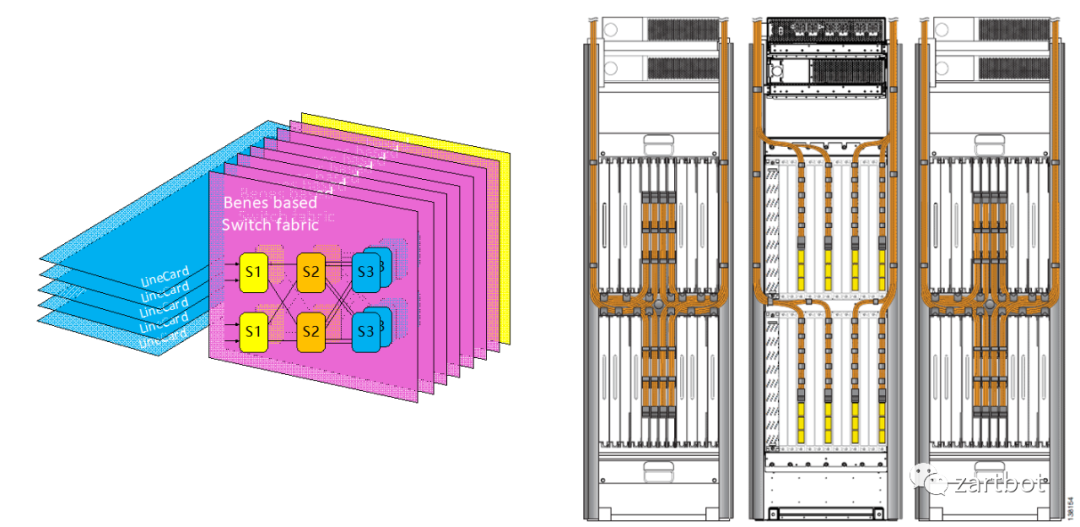
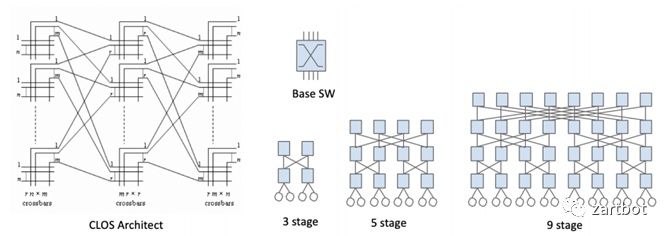 新的做法便是使用多级交换架构来替代原有的基于单级架构的crossbar技术. 多级交换结构的基本组成单位叫交换单元, 每个交换单元具有输入和输出功能. 各个交换单元通过一定的逻辑顺序相互连接, 形成一个巨大的、可扩展的交换网络. 多级交换结构的形式有很多种, 包括Clos、Banyan、Butterfly和Benes等, 各种交换结构的不同主要在于交换单元的互联方式.
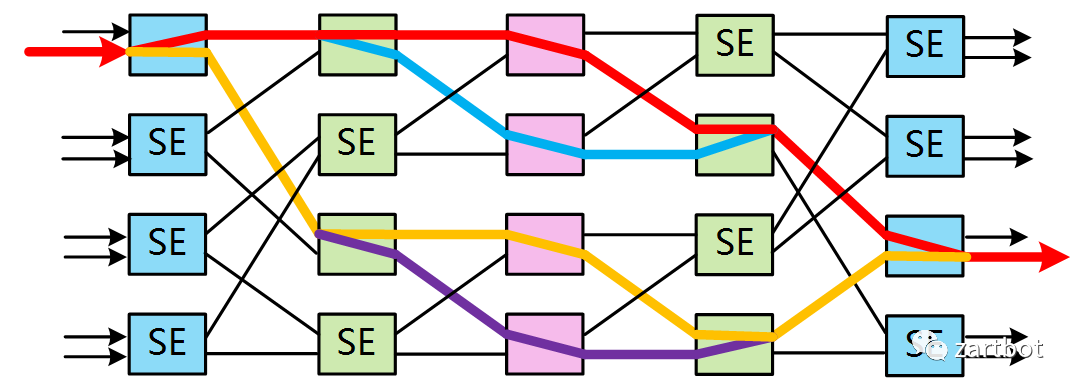
例如Cisco的CRS-1则采用了BENES架构:
新的做法便是使用多级交换架构来替代原有的基于单级架构的crossbar技术. 多级交换结构的基本组成单位叫交换单元, 每个交换单元具有输入和输出功能. 各个交换单元通过一定的逻辑顺序相互连接, 形成一个巨大的、可扩展的交换网络. 多级交换结构的形式有很多种, 包括Clos、Banyan、Butterfly和Benes等, 各种交换结构的不同主要在于交换单元的互联方式.
例如Cisco的CRS-1则采用了BENES架构:
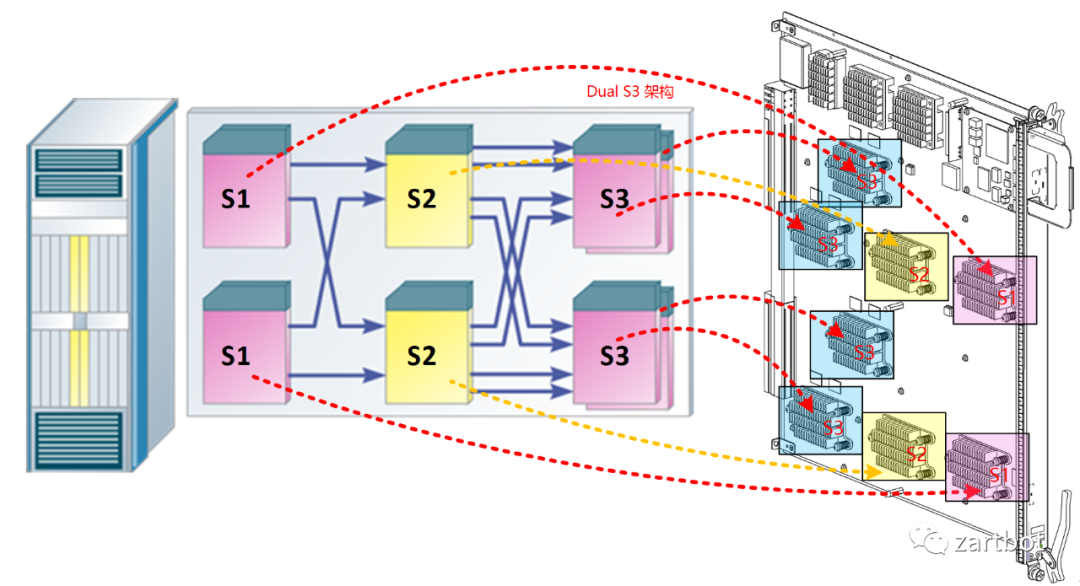
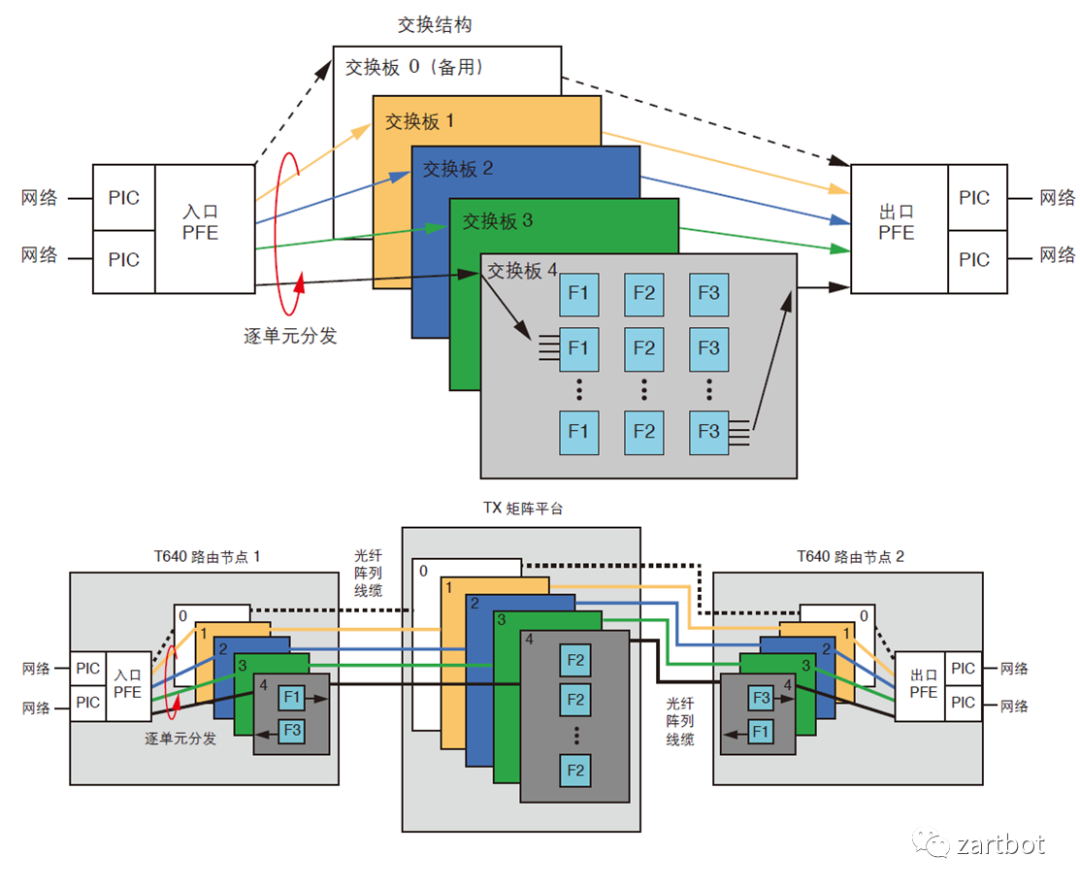
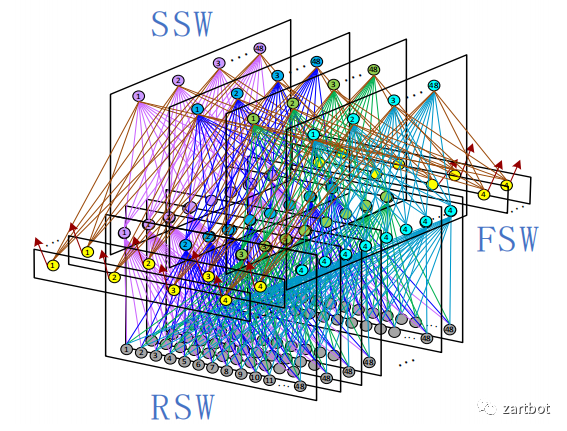
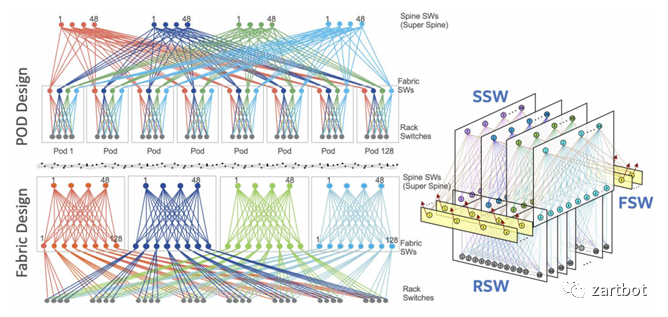

2.2 硬件转发之Linecard
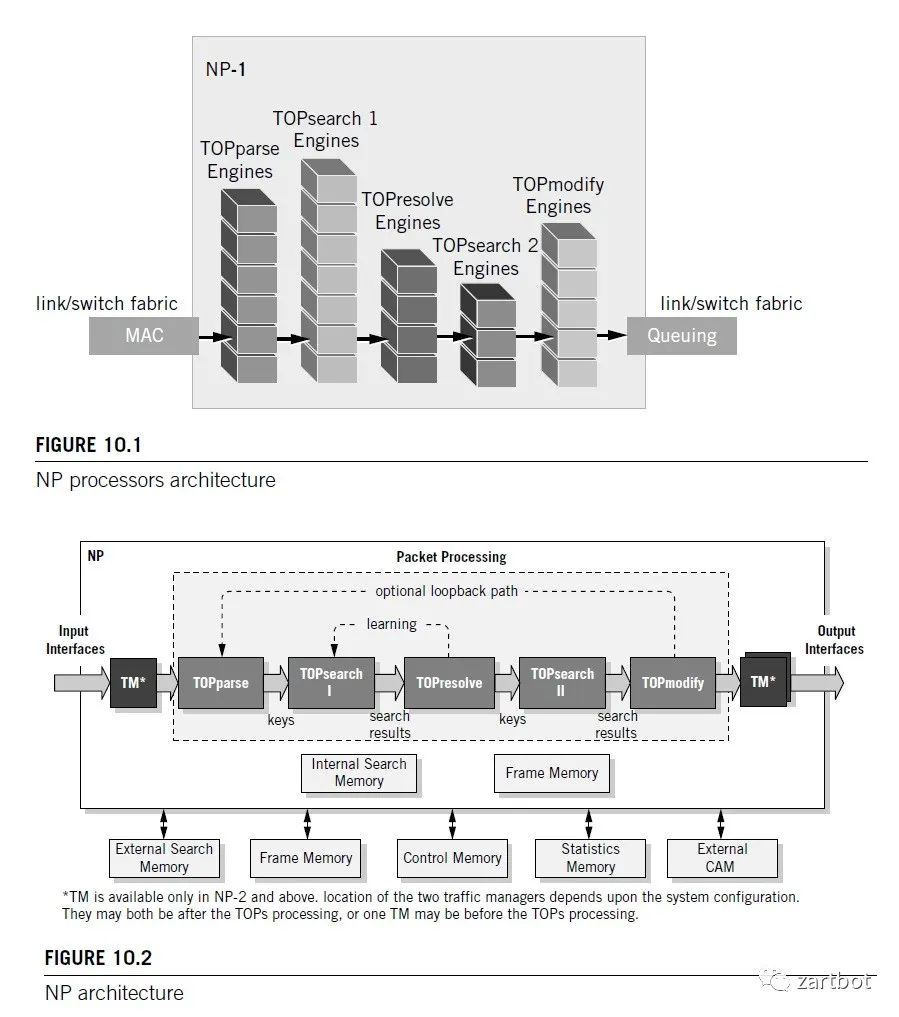
Fabric设计是相对简单的,困难的还是在线卡上,一方面是路由表的容量越来越大,另一方面是对功能的需求越来越多了。 线卡结构的发展历程参考Cisco可以清晰地看到, 从最早的路由器全部使用核心CPU转发. 到后来在总线上使用控制器调度. 再到后期Cisco 7500上使用VIP接口卡, 实现分布式的CPU处理; 然后在基于Crossbar的平台上使用ASIC进行处理. 例如7600上OSM线卡和Cisco 10000系列所使用的PXF. 到最后在线卡上使用网络处理器(NP), 例如Cisco的SPA/SIP架构. 后期例如在CRS-1使用的SPP处理器以及使用全新QuantumFlow网络处理器构建的ASR1000边缘路由器平台等. 其实那些年有很多的争论也有很多的实现,真是百花齐放的年代:
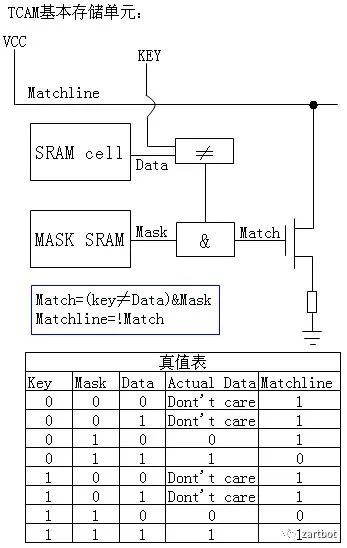
传统的表项查找方法都是基于SRAM的软件查找方法,共同特点是查找速度慢。线型查找法需要遍历表中的所有表项;二叉树查找法需要遍历树中大多数节点,而且查找速度受树的深度影响较大;基于硬件的TCAM查找法正是在这种背景下提出的,用此方法进行查找时,整个表项空间的所有数据在同一时刻被查询,查找速度不受表项空间数据大小影响。TCAM为啥叫Ternary Content呢,其实就是每个bit位有三种状态, 0,1,Don't care,这样不就很容易去做一些匹配了么,特别是路由器那样的Longest Match
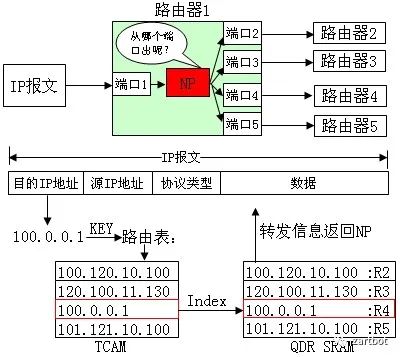
一般来说的做法如下,通过TCAM查询然后获取Index,然后再到内存里面把index对应的信息返回给路由器。
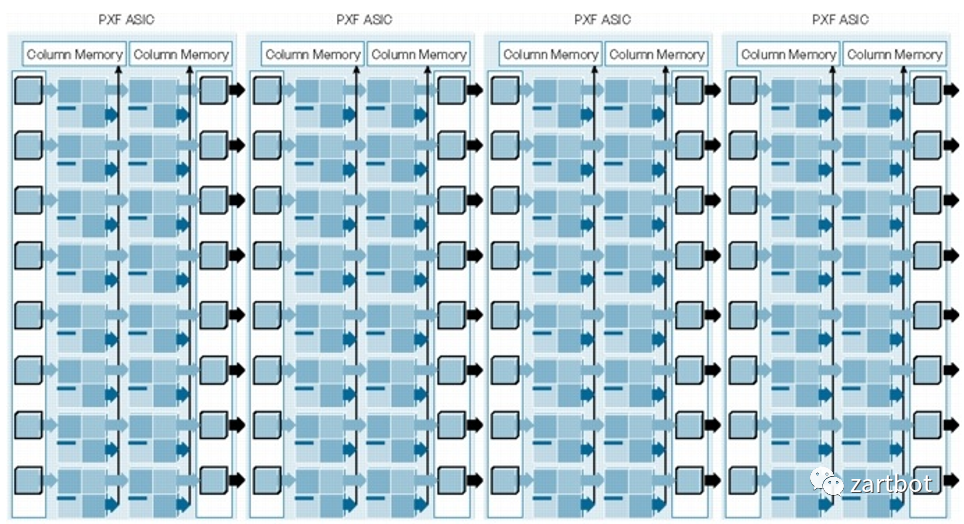
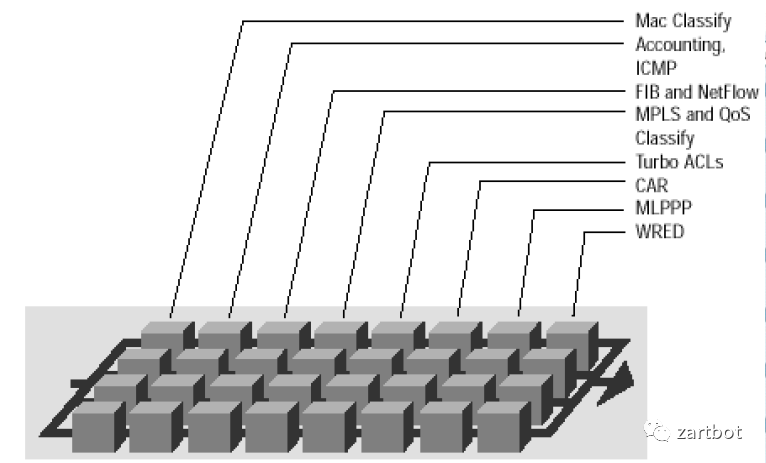 有个教授写了一段话,原文摘录,:
“The PXF consists of a pair of ICs, each comprised of 16 processors arranged in 4 pipelines. When used together, the pair of PXFs results in a 4x8 systolic array. Each of the 32 processors is a 2-issue VLIW with special instructions for packet processing. Each processor has an independent memory and each column of processors has access to its own separate memory (off-chip). Each of the 8 stages in the pipeline is responsible for a different packet forwarding function. ”
文章来源
《Understanding Network Processors,Niraj Shah》更多的东西就不多透露了也不是本文的重点
2.2.2 RTC的网络处理器(SPP/QFP)
固定流水线的网络处理器会面临一些问题, Feature的使用并不是那么的均衡的,可能有些资源放在那里,功能没用上,但是还是要走,而且可能还会存在某些功能用的多,资源不够的状况, 另外一方面随着那个年代MPLS VPN的兴起,路由表容量的需求也越来越大, 另外针对不同功能例如BRAS/DSLAM/Cable接入也推出了大量的硬件平台,使得研发难以维护,微码编程也逐渐的无法满足丰富的市场需求,在这个年代发生的一些事情,不得不提Will Eatherton,最开始有一篇论文,然后通过这样的方法避免了IP路由查询受限于TCAM, Will设计了思科的SPP和QFP,然后又去Juniper 设计了Trio系列处理器。但是2019年一次测试碰到华X的NXXX,还在用TCAM,而且似乎还丝毫没有意识到路由表容量大有那么多好处,同时也可把TCAM的资源节省出来给ACL用。
有个教授写了一段话,原文摘录,:
“The PXF consists of a pair of ICs, each comprised of 16 processors arranged in 4 pipelines. When used together, the pair of PXFs results in a 4x8 systolic array. Each of the 32 processors is a 2-issue VLIW with special instructions for packet processing. Each processor has an independent memory and each column of processors has access to its own separate memory (off-chip). Each of the 8 stages in the pipeline is responsible for a different packet forwarding function. ”
文章来源
《Understanding Network Processors,Niraj Shah》更多的东西就不多透露了也不是本文的重点
2.2.2 RTC的网络处理器(SPP/QFP)
固定流水线的网络处理器会面临一些问题, Feature的使用并不是那么的均衡的,可能有些资源放在那里,功能没用上,但是还是要走,而且可能还会存在某些功能用的多,资源不够的状况, 另外一方面随着那个年代MPLS VPN的兴起,路由表容量的需求也越来越大, 另外针对不同功能例如BRAS/DSLAM/Cable接入也推出了大量的硬件平台,使得研发难以维护,微码编程也逐渐的无法满足丰富的市场需求,在这个年代发生的一些事情,不得不提Will Eatherton,最开始有一篇论文,然后通过这样的方法避免了IP路由查询受限于TCAM, Will设计了思科的SPP和QFP,然后又去Juniper 设计了Trio系列处理器。但是2019年一次测试碰到华X的NXXX,还在用TCAM,而且似乎还丝毫没有意识到路由表容量大有那么多好处,同时也可把TCAM的资源节省出来给ACL用。
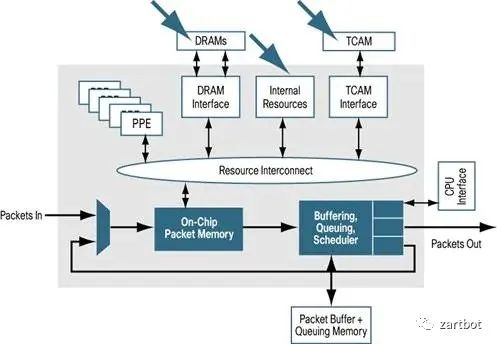
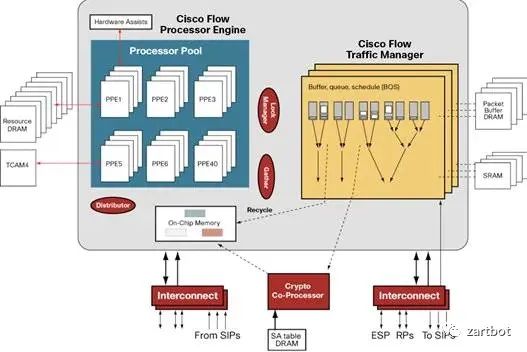
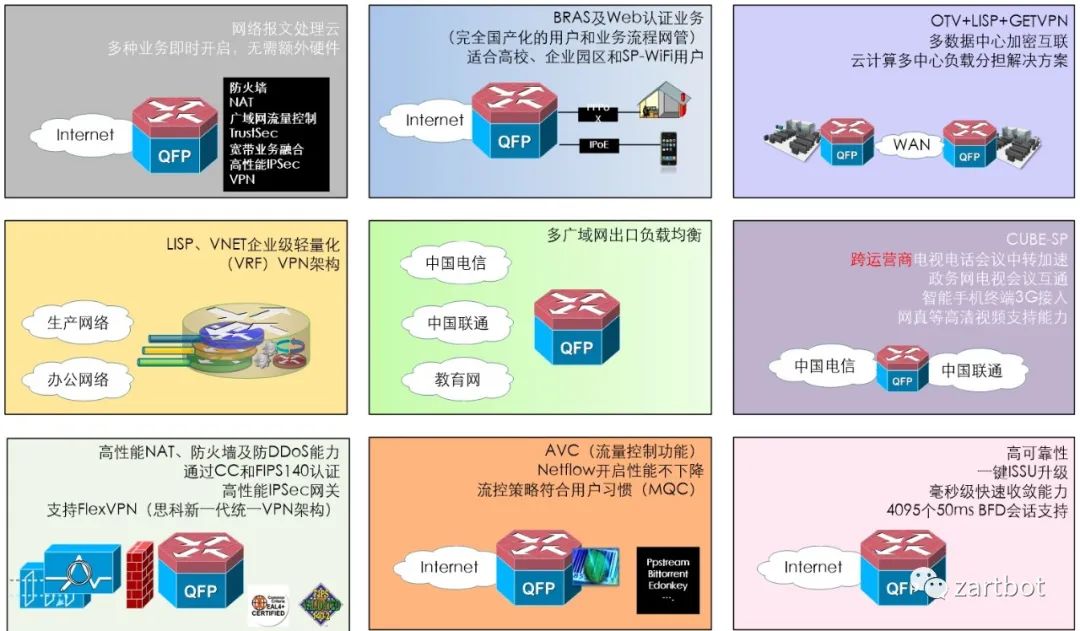

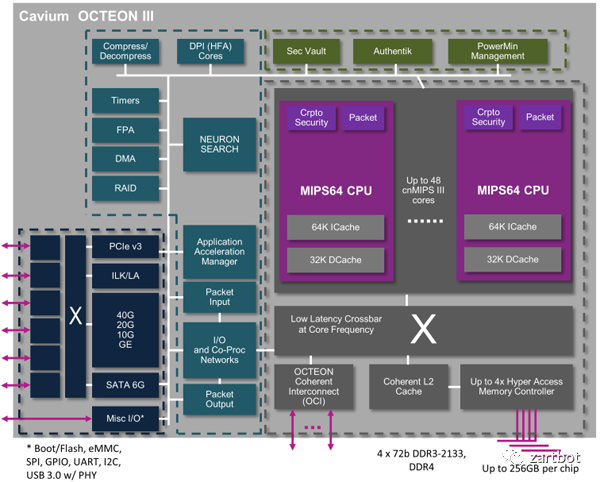
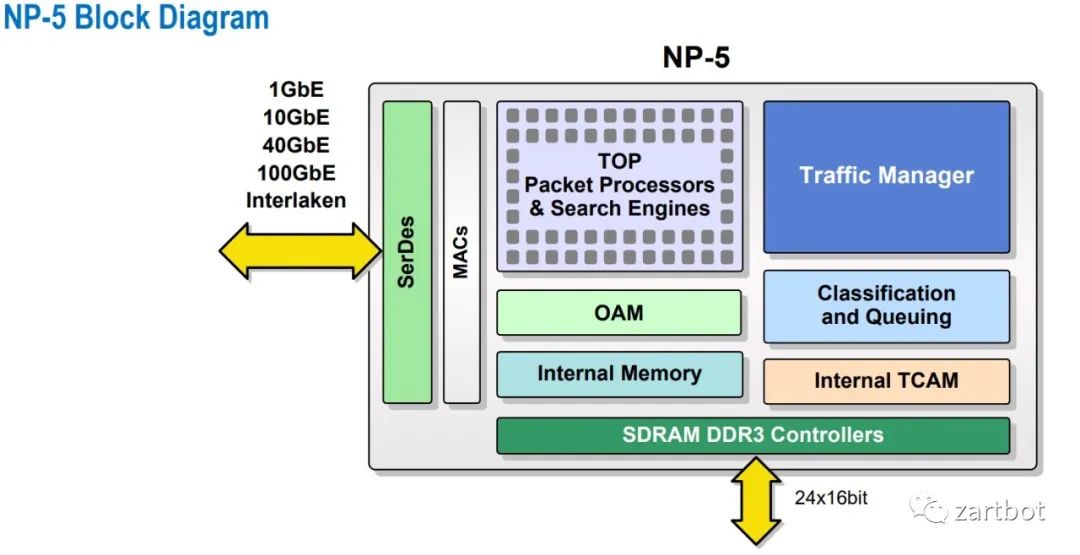

挑出两三页挺重要的贴个图就好,意会一下,详细的宝宝不说~~

1995~2010 由软向硬的过渡
| 报文编码 | MPLS简化核心路由表条目数 |
| 软件结构 | 软件结构相对稳定没有太大变化 |
| 硬件结构 | 专用处理器繁荣的十年,各种专用芯片来做Offload,加密芯片,TCAM查表,各种基于微码的网络处理器,Fabric逐渐采用CLOS架构构建多机集群. |
3. 软件定义的网络
分分合合,合合分分,谁都没想到随着虚拟化的兴起,虚拟机内互相通信的网络成为网络设备再一次软件化的开端,当然开始的时候只有交换机, 于此同时为了大量的虚拟交换机编程和转发方便,openflow和openvswtich诞生了,然后公有云和私有云的部署使得网络设备进一步虚拟化,虚拟云路由器也随之诞生, 后面伴随着VDC/VPC的发展,更多的设备虚拟化了: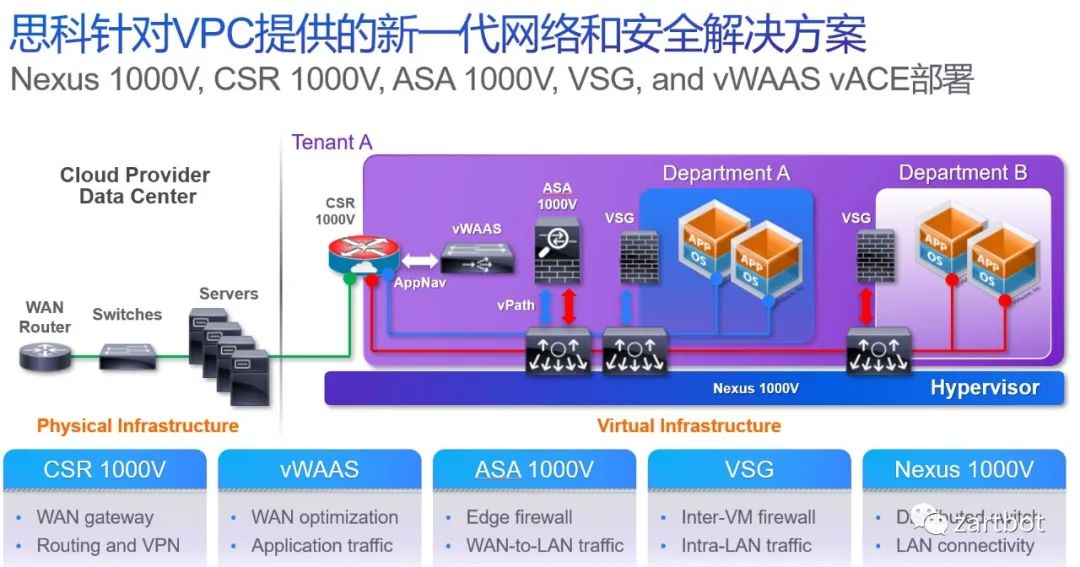
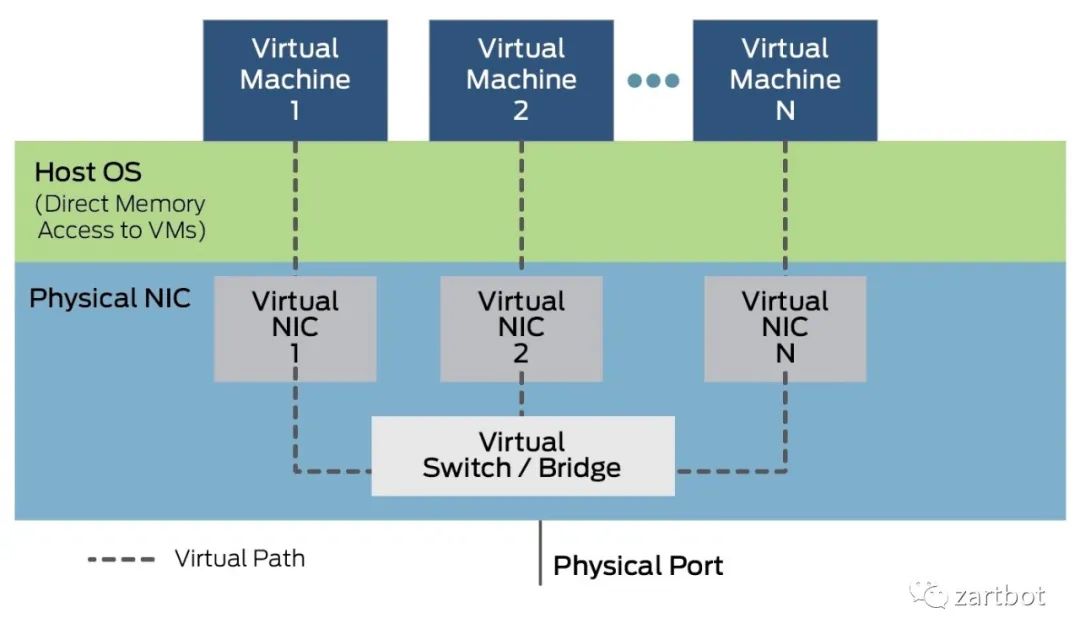
经过演化,最后形成了如下的标准架构:
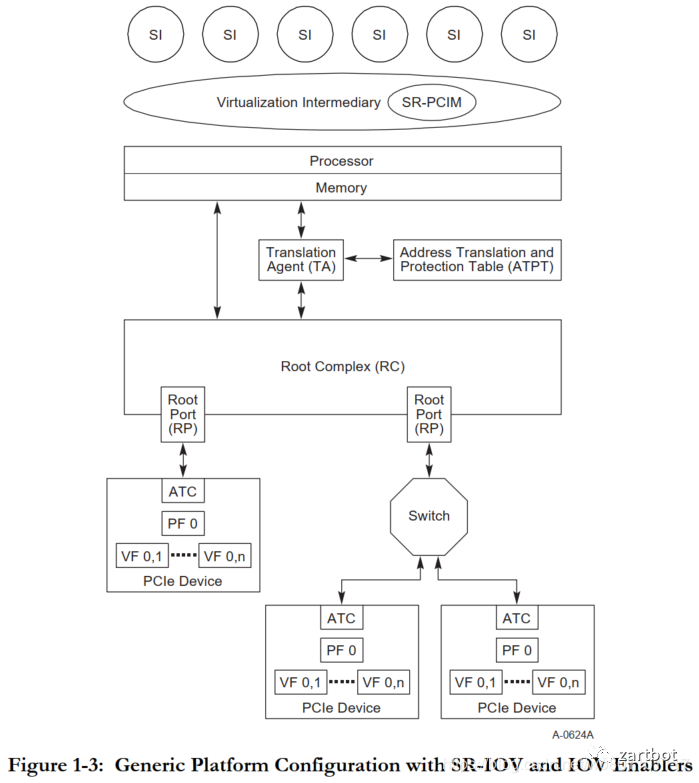
数据包到达网卡设备。
网卡设备依据配置进行DMA操作。
网卡发送中断,唤醒处理器。
驱动软件填充读写缓冲区数据结构。
数据报文达到内核协议栈,进行高层处理。
如果最终应用在用户态,数据从内核搬移到用户态。
如果最终应用在内核态,在内核继续进行。
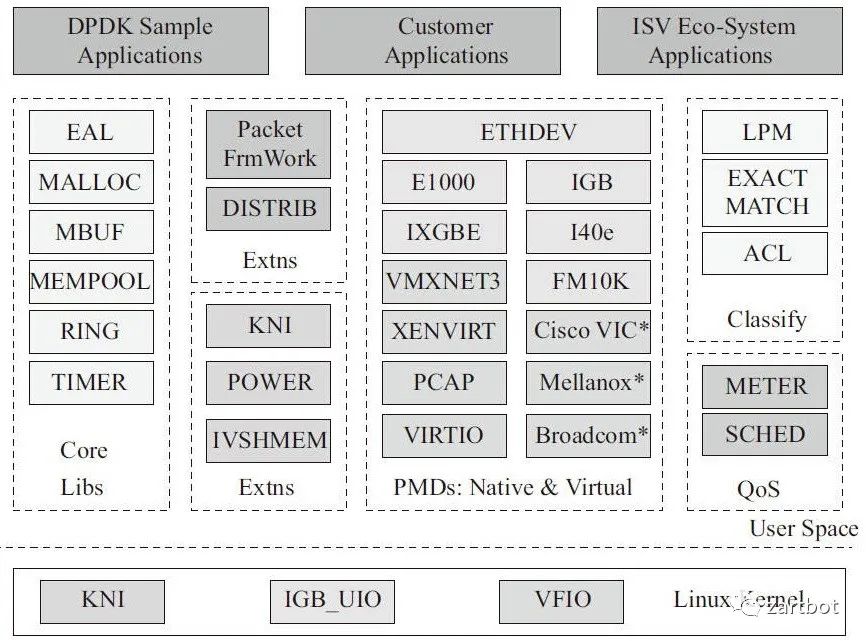
具体去看一本书撸一圈代码都会了:
3.3 VPP 本质上就是对报文编程一个向量,然后批量处理,同时它定义了灵活的转发链状结构,可以很容易的在转发链条上添加新的软件特性: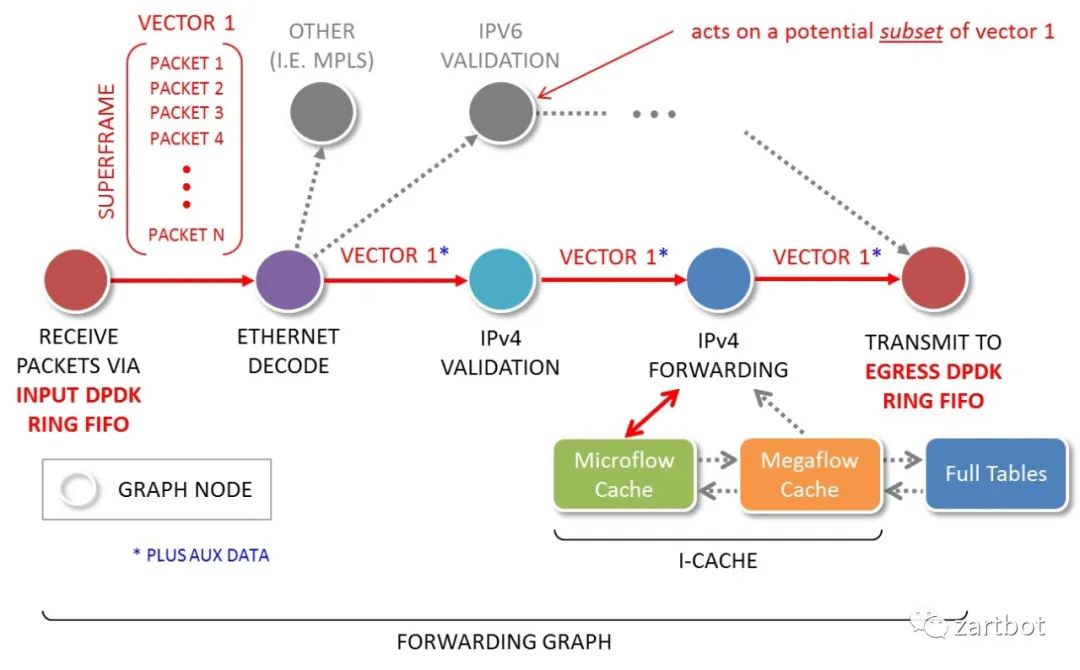
| 报文编码 | VXLAN和Overlay的兴起 |
| 软件结构 | 软件转发的回归,DPDK/VPP等开源软件的出现 |
| 硬件结构 | 多核通用处理器性能越来越强,SR-IOV的出现,核心交换芯片越来越强并支持虚拟化 |
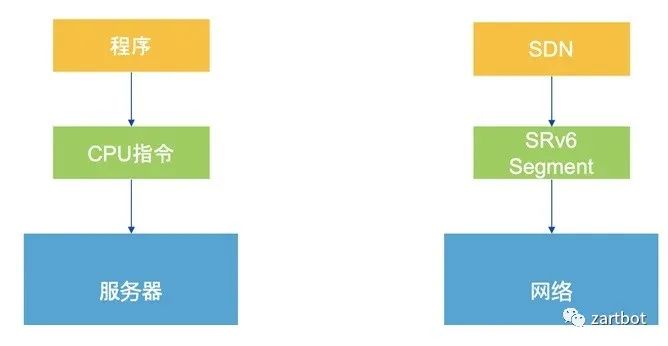

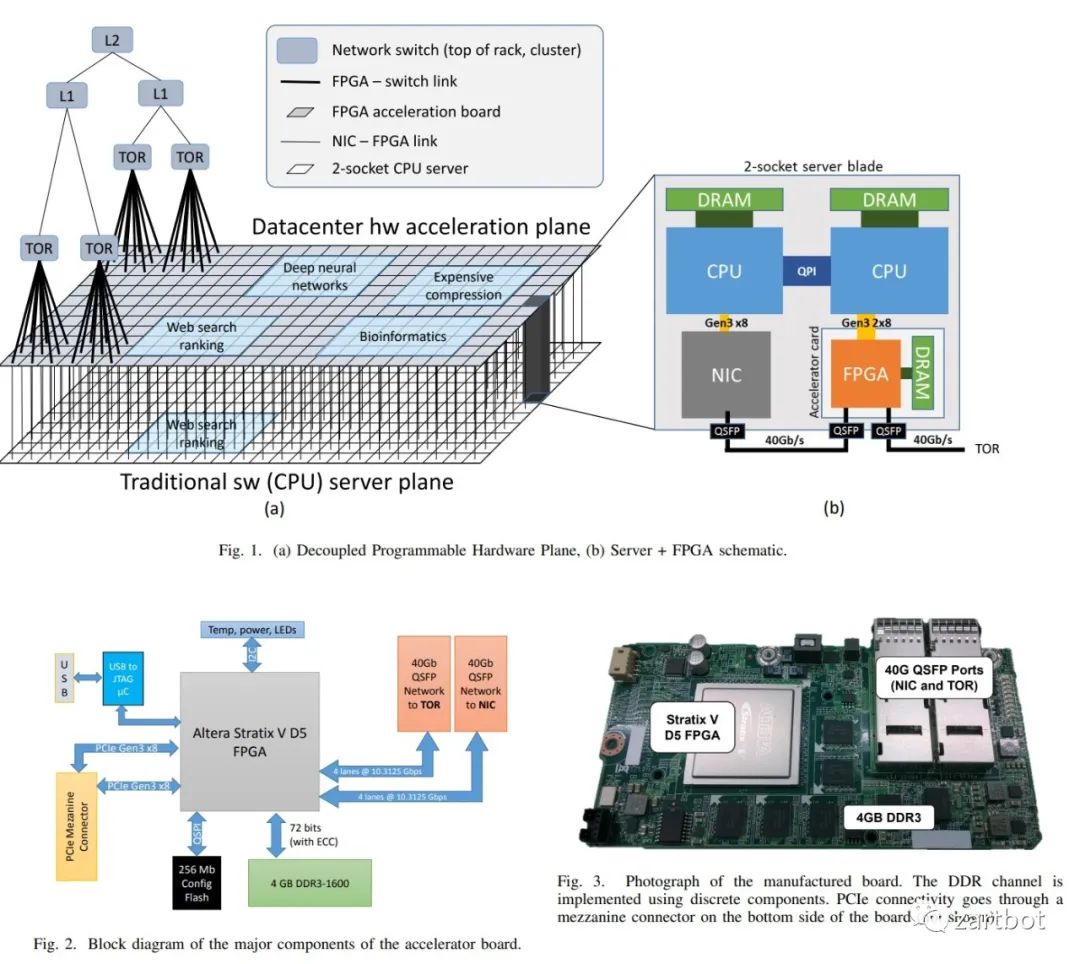
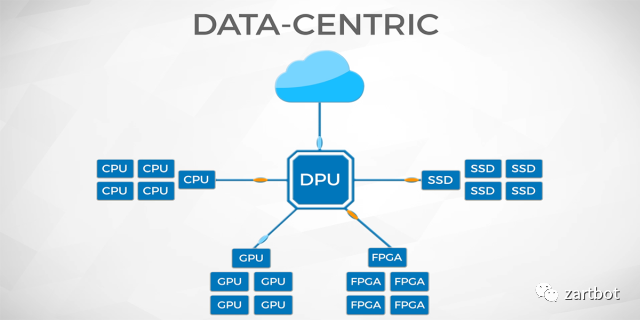

| 报文编码 | SegmentRouting,数据包即指令 |
| 软件结构 | 容器技术的出现,CNI触发Host Overlay,尽量采用协处理器或者网络设备卸载负担, P4等通用网络编程语言的出现 |
| 硬件结构 | 可编程交换芯片的出现,各种SmartNIC方案盛行,低延迟通信的需求日益增加,特别是AI带来的快速I/O响应 |
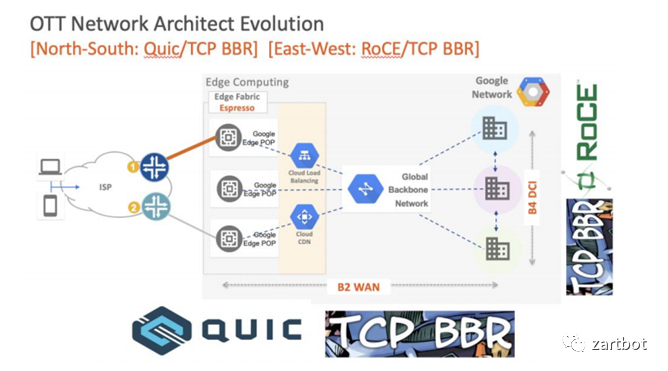
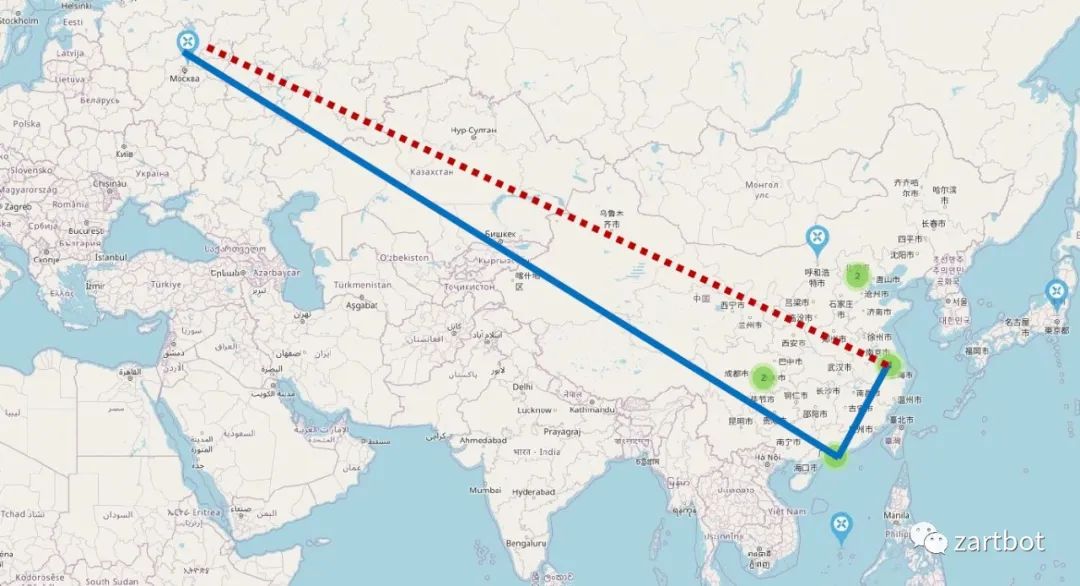
丢包的统计如下图:
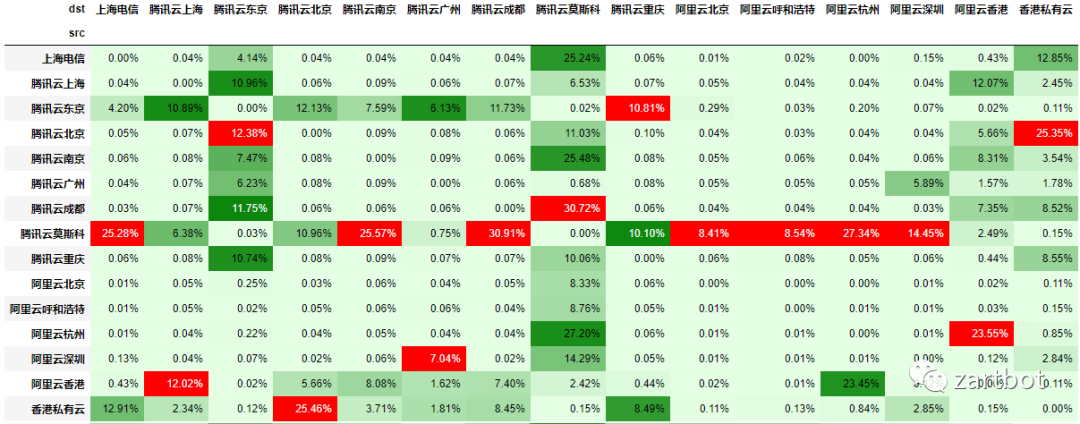
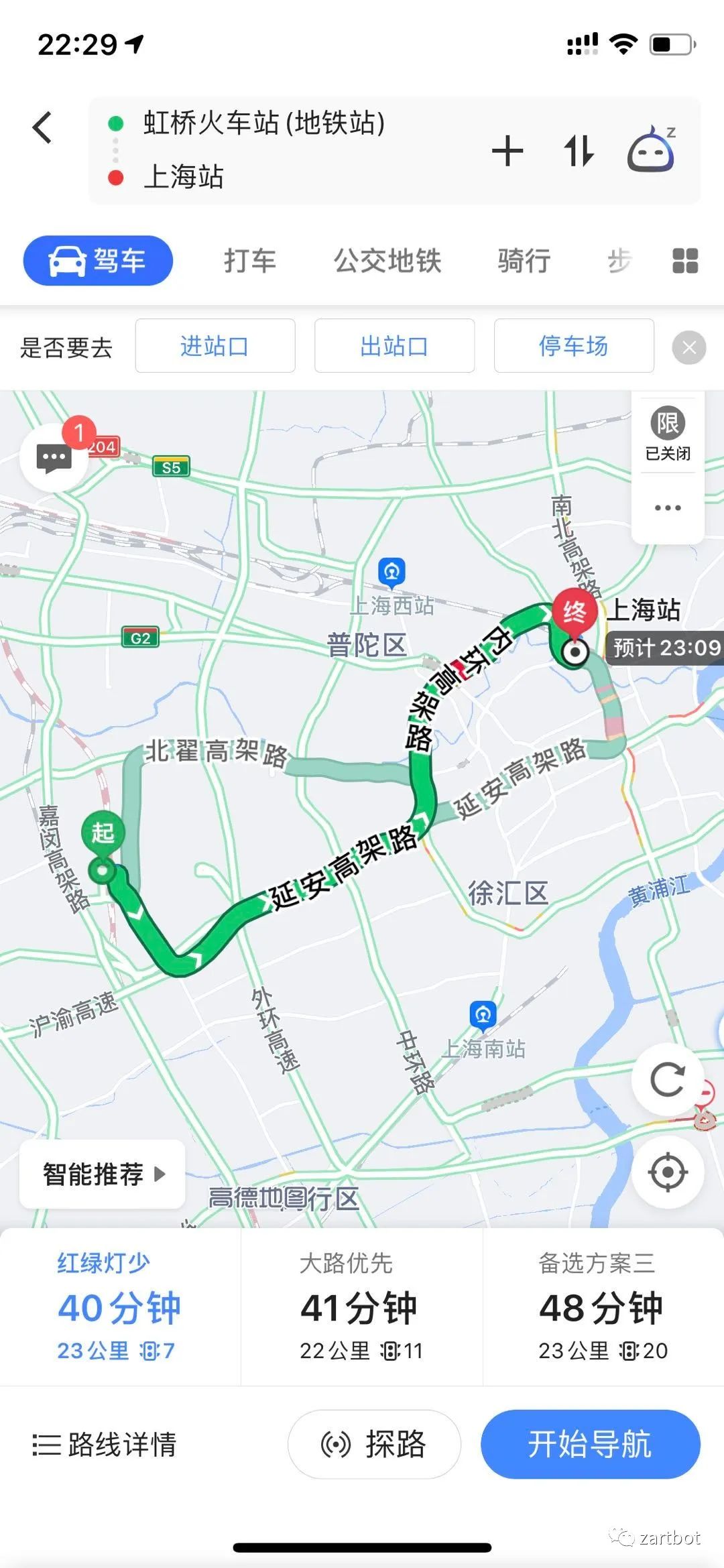

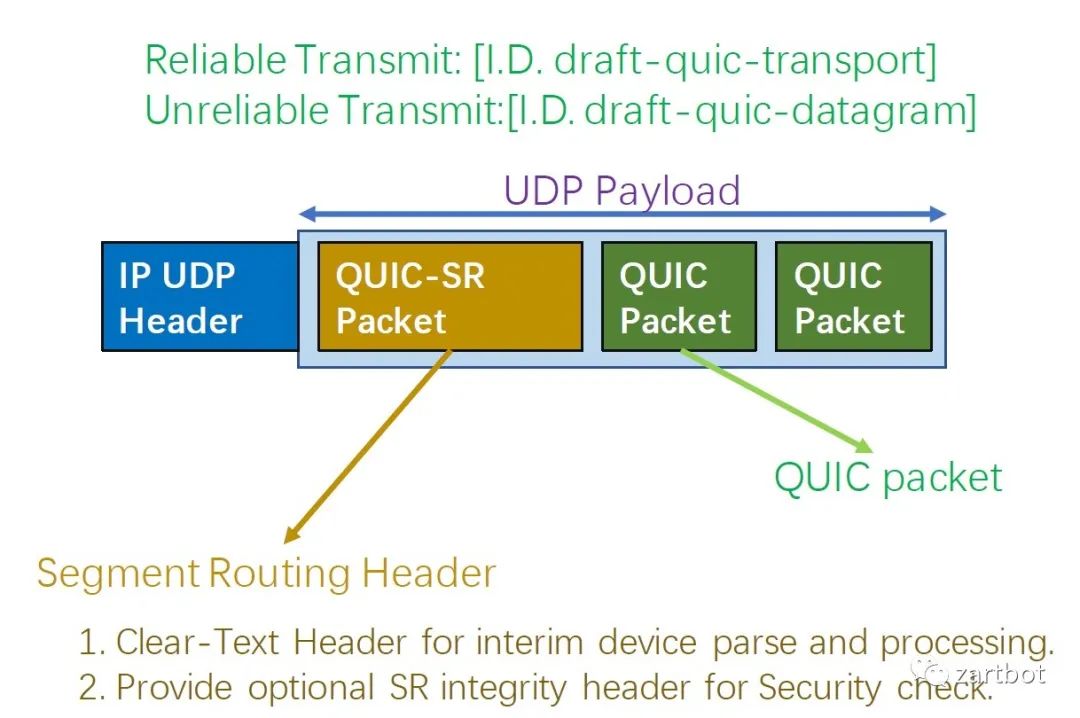
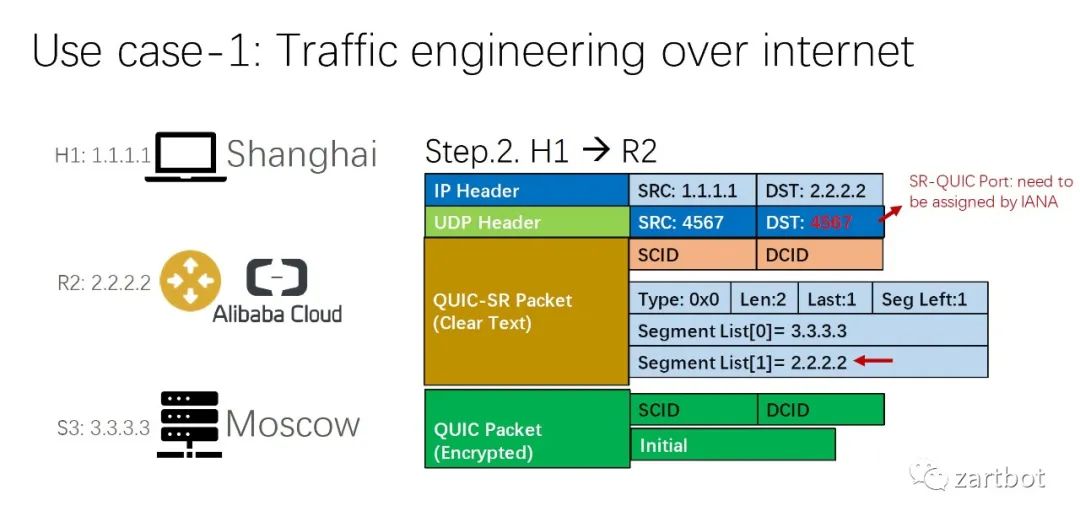
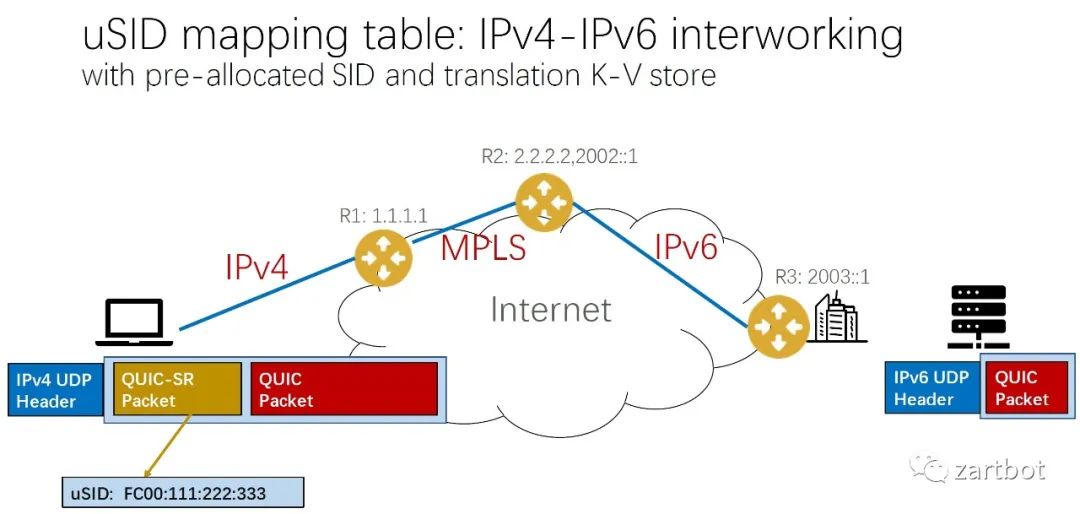
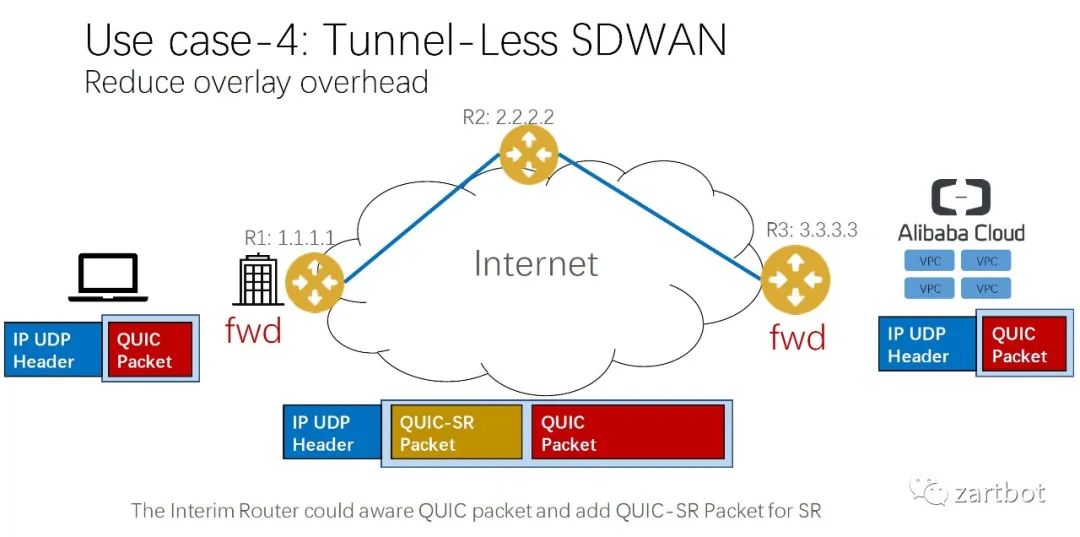
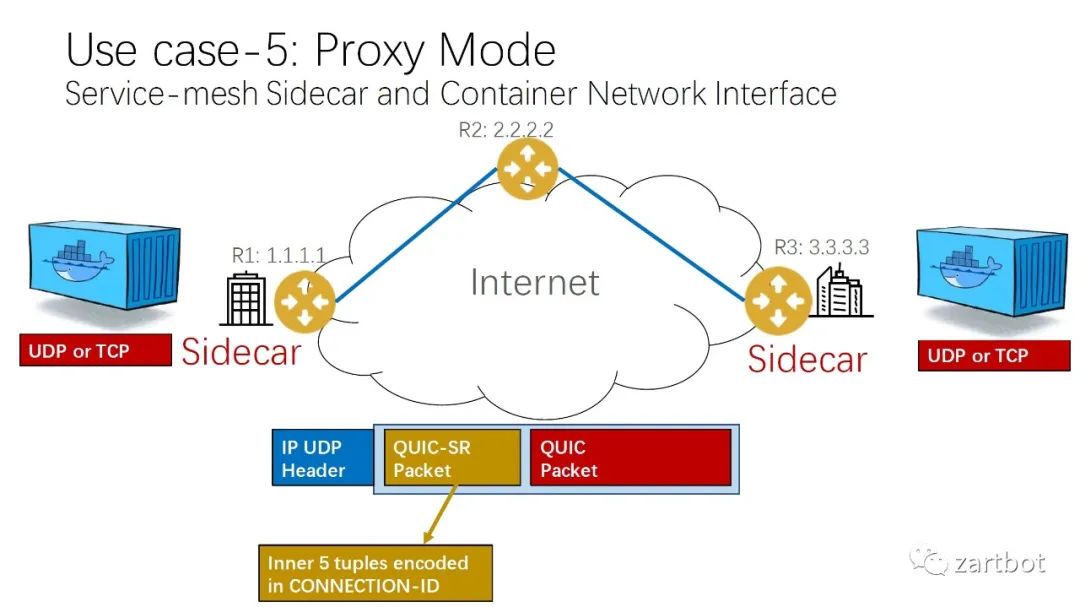
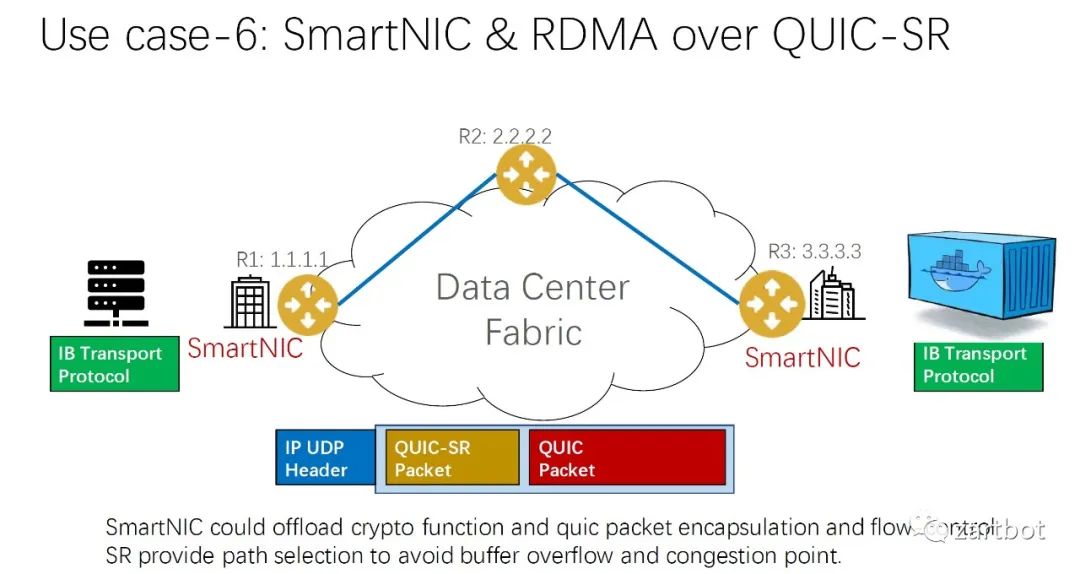
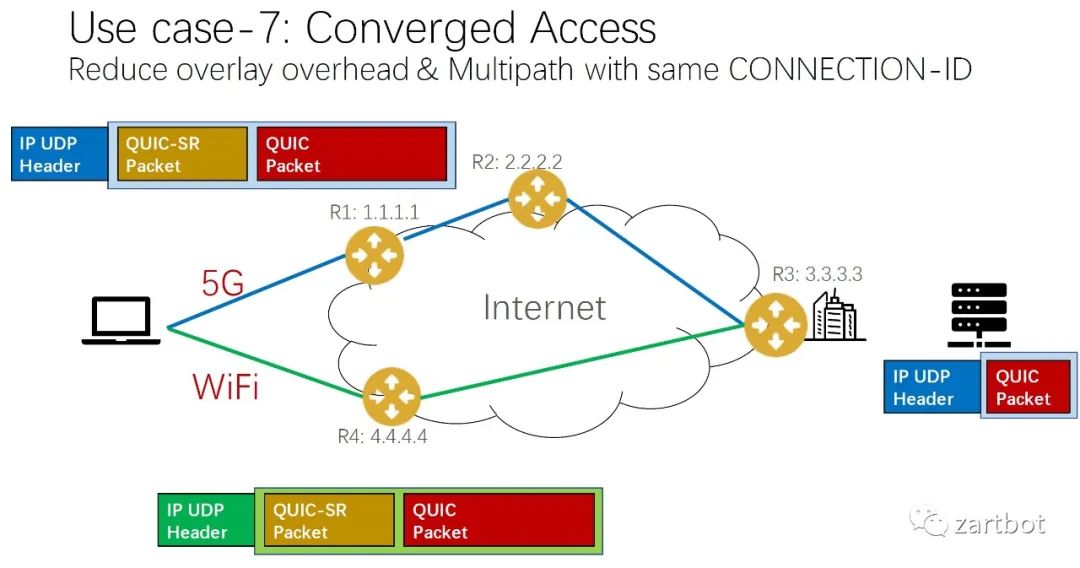
做安全,微分段也可以给你加字段啊:

这就是一个前浪过去10多年的从业经验和见到的盛世繁华,以及给后浪的选择的权力。
2020~未来 :NewIP:后浪:给更多的终端可以智能选择的权力| 报文编码 | QUIC+SR |
| 软件结构 | 给更多的终端以后浪般的选择的权力 |
| 硬件结构 | 智能都在设备上了,网络可以简单一点了 |

