
- 1pip安装airtest (pip+镜像 安装步骤(纵享丝滑))_python 3.6.8 第一次安装airtest,觉得pip安装实在是太慢了,遇到几十兆的大小,下
- 2使用yolo-seg模型实现自定义自动动态抠图_yolov8 segment 抠图
- 3Android Studio配置svn时提示需要证书:authentication required的解决方法_android studio authentication required
- 4springcloud整合oauth2-----异常配置总结_msg": "authentication failed:authorization cannot
- 5mac安装adb报错Unknown command: cask_error: unknown command: cask
- 6几句话让你明白:分析ARP协议、图文拆解交换机/路由器转发原理_几句话让你明白:分析arp协议、图文拆解交换机/路由器转发原理
- 7卡尔曼滤波matlab程序实现_extractball函数
- 8Axios跨域请求处理
- 9aspectj's load-time instrumentation_weaveinfo join point 'method-execution(void com.ly
- 10打开android studio新建项目时报错的可能的解决办法_androidstudio 新建项目 报错lass jdk.internal.loader.clas
NLP实践|CCKS2020金融知识图谱自动化构建技术方法总结
赞
踩
每天给你送来NLP技术干货!
编辑:AI算法小喵
写在前面
文本是参加2020CCKS评测 基于本体的金融知识图谱自动化构建技术 之后的一篇总结博客,笔者查阅了大量文献,并做了大量采用深度学习模型的实验,但最终提交时效果最好的方法还是规则匹配。
文本中总结了笔者在最终提交时所使用的方案,以及在参加评测过程中所尝试的各种实验,另外还有评测结束后还没有来得及实现的一些想法。
1. 评测任务介绍
1.1 介绍

金融研报是各类金融研究结构对宏观经济、金融、行业、产业链以及公司的研究报告。报告通常是由专业人员撰写,对宏观、行业和公司的数据信息搜集全面、研究深入,质量高,内容可靠。报告内容往往包含产业、经济、金融、政策、社会等多领域的数据与知识,是构建行业知识图谱非常关键的数据来源。
另一方面,由于研报本身所容纳的数据与知识涉及面广泛,专业知识众多,不同的研究结构和专业认识对相同的内容的表达方式也会略有差异。这些特点导致了从研报自动化构建知识图谱困难重重,解决这些问题则能够极大促进自动化构建知识图谱方面的技术进步。
本评测任务参考 TAC KBP 中的 Cold Start 评测任务的方案,围绕金融研报知识图谱的自动化图谱构建所展开。评测从预定义图谱模式(Schema)和少量的种子知识图谱开始,从非结构化的文本数据中构建知识图谱。
其中图谱模式包括 10 种实体类型,如机构、产品、业务、风险等;19 个实体间的关系,如(机构,生产销售,产品)、(机构,投资,机构)等;以及若干实体类型带有属性,如(机构,英文名)、(研报,评级)等。在给定图谱模式和种子知识图谱的条件下,评测内容为自动地从研报文本中抽取出符合图谱模式的实体、关系和属性值,实现金融知识图谱的自动化构建。

1.2 其他相关信息
笔者GitHub代码[1],最终排名为第五名 :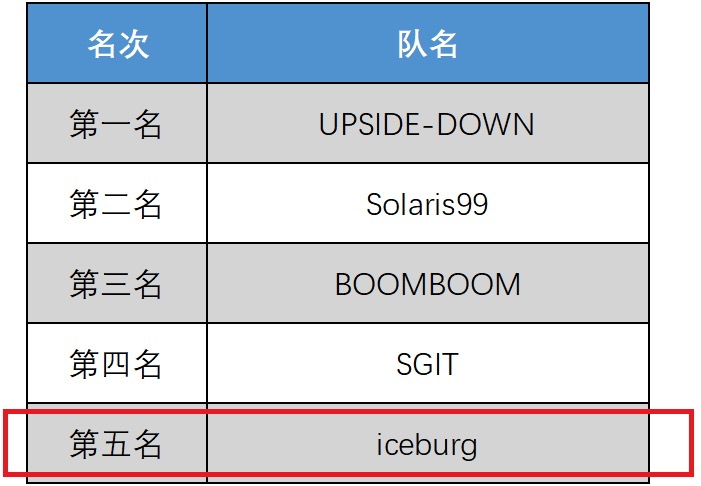
2.目前方案
由于评测包含的子任务比较多,有实体识别、关系抽取和属性抽取;可使用的技术也非常多,有监督,无监督,半监督等等;所以笔者在做评测的过程中尝试了很多方法,但是大部分的模型都不如规则,所以笔者最终提交的方案中使用了大量规则匹配方法。
2.1 方案整体流程图
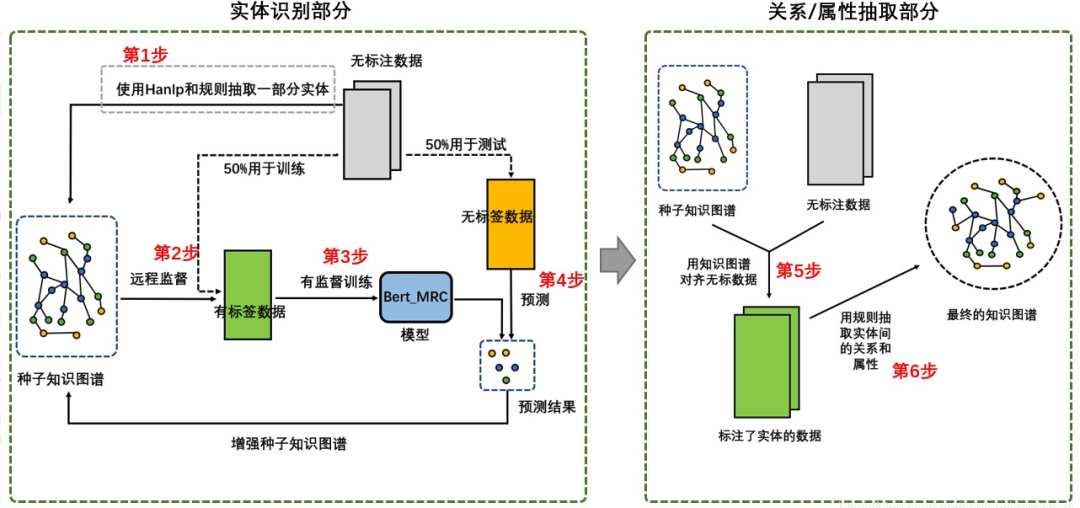
整体结构可以分为实体识别和关系、属性抽取两部分;流程可以分为6步,其中2、3和4步会重复执行多次。
第1步:通过Hanlp和规则匹配的方式抽取部分实体;
第2步:采用远程监督方法,用种子知识图谱对齐无标数据得到标出了实体的数据;
第3步:用上一步得到的标出了实体的数据训练模型;
第4步:用上一步训练的实体识别模型抽取无标数据中的实体,并将抽取出的实体加入到种子知识图谱中,增加种子知识图谱的规模,重复2,3,4步多次不断使种子知识图谱规则不断扩大;
第5步:通过重复2,3,4步多次后得到扩展了大量实体的知识图谱,用种子知识图谱对齐无标数据,将无标数据中的实体都找出来;
第6步:通过上一步得到无标数据中的实体后,使用规则的方法判断实体间的关系和属性。
2.2 实体抽取部分
1)外部工具
通过Hanlp实体识别工具,抽取“人物”和“机构”两种类型的实体。Hanlp工具的实体识别模型是其他有标语料上训练的,这里使用外部工具本质上是使用了迁移学习方法。
2)规则
通过规则,抽取“研报“,“文章“,“风险“,“ 机构“四种类型的实体。
3)深度学习(远程监督实体识别)
除了规则匹配外,还可以采用远程监督的方法,主要用于抽取研报中的实体,具体流程如下图所示:
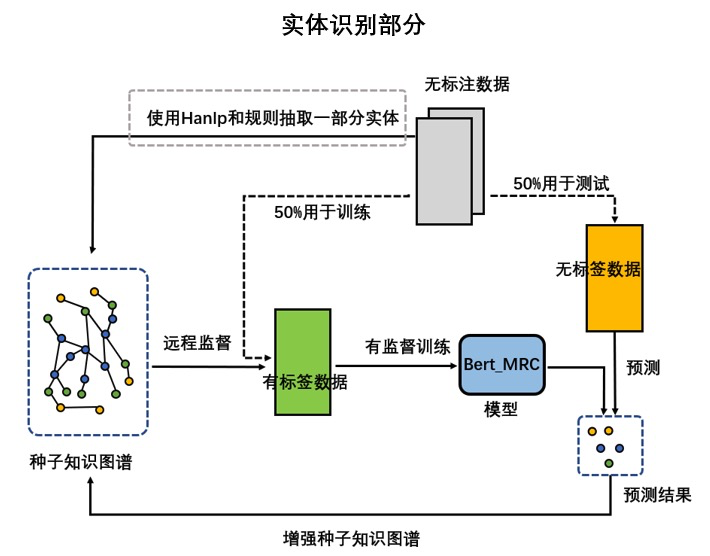
使用规则和外部工具抽取一部分实体;
将原始数据平均分成两半,一半用于训练,一半用于测试,对用于训练的一半数据使用远程监督进行标注;
采用将远程监督方法标注的数据按4:1划分,分别作为训练和验证集,训练模型;
使用上一步训练出的模型在测试集上进行预测,抽取出一部分实体;
通过规则匹配的方法筛选掉一些实体,剩下的实体加入种子知识图谱,然后从第2步开始,重复上一次训练,迭代进行实体抽取。
2.3 关系抽取、属性抽取部分
关系抽取和属性抽取方法非常相似,可以使用同样的方案来解决。
在做评测的过程中,考虑到没有给出有标注的关系抽取数据集,所以最初我计划采用远程监督关系抽取的相关方法,首先使用经典的模型PCNN做了相关实验,在实验过程中发现语料中有大量的关系需要通过跨句的抽取方法才能识别,所以又查看了文档级关系抽取的相关方法。但是,目前文档级关系抽取方法几乎都使用有监督训练,所以笔者最后对数据做了一些处理后,还是使用了PCNN+ATT模型。在进行了相关实验后并与使用规则的方法做比较之后,笔者发现深度学习模型在对关系的准确率上还是差的比较远,所以在评测的最后阶段还是采用的规则匹配方法。
3.相关实验
下面是在参加评测的过程中,笔者做的采用深度学习方法的一些实验,笔者比较了各种方法的优劣,选了几种在评测给定的场景下较优的方法,但是在最终的效果都不如采用规则匹配的方法。这里笔者把在评测中做的一些实验,采用的一些模型做一个总结。
3.1 实体抽取部分
3.1.1 BERT-MRC模型
该评测的实体识别模型就采用的该方法,BERT-MRC模型是目前实体识别领域的SOTA模型(2020年),在数据量较小的情况下效果较其他模型要更好,原因是因为BERT-MRC模型可以通过问题加入一些先验知识,减小由于数据量太小带来的问题。在实际实验中,在数据量比较小的情况下,BERT-MRC模型的效果确实要较其他模型要更好些。BERT-MRC模型很适合用在本评测这种缺乏标注数据的场景下。
(1)方法概述
任务定义:给定一个文本序列 ,它的长度为 ,要抽取出其中的每个实体,其中实体都属于一种实体类型。
模型思想:假设该数据集的所有实体标签集合为 ,那么对其中的每个实体标签 ,比如地点“国家”,都有一个关于它的问题 。这个问题可以是一个词,也可以是一句话等等。使用上述MRC中片段抽取的思想,输入文本序列 和问题 , 是需要抽取的实体,BERT_MRC通过建模 来实现实体抽取。
提示信息(问题构造):对于问题 的构造是建模 的重要环节。BERT_MRC使用“标注说明”作为每个标签的问题。所谓“标注说明”,是在构造某个数据集的时候提供给标注者的简短的标注说明。比如标注者要去标注标签为“国家”的所有实体,那么对应“国家”的标注说明就是 “指拥有共同的语言、文化、种族、血统、领土、政府或者历史的社会群体。
(2)模型输入与模型损失
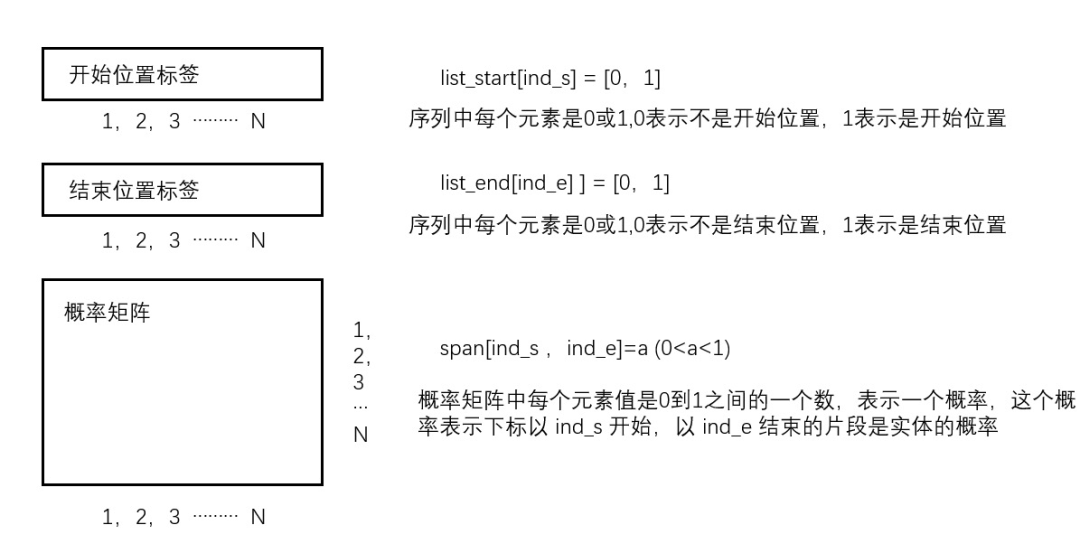
将问题和语料中的句子合并成一句话作为输入,问题和语料句之间用BERT的句子级特殊符号“[SEP]”隔开,下图中红色框线框出的为问题:

在用BERT编码得到词向量之后,训练三个分类器,得到开始、结束位置标签以及一个概率矩阵。上述两个标签一个矩阵共可以求三个loss,模型的总loss是上述三个loss之和 :
3.1.2 BERT-CRF、LSTM-CRF模型
将实体识别看做一个序列标注问题,设计BIO和实体类型的联合标签,每个字符对应一个标签。在训练时,采用标注了标签的字符序列作为语料训练模型,预测阶段使用模型预测字符对应的标签,然后通过标签得到实体的片段的具体位置以及实体片段的类型。
命名实体识别经典的baseline LSTM-CRF采用的就是这种方法,18年之后BERT代替了LSTM,b变成了一个重要的实体识别baseline。采用CRF的原因是CRF能对标签的转移状态建模,减小一些错误的标签序列出现的概率,增加模型的准确率。

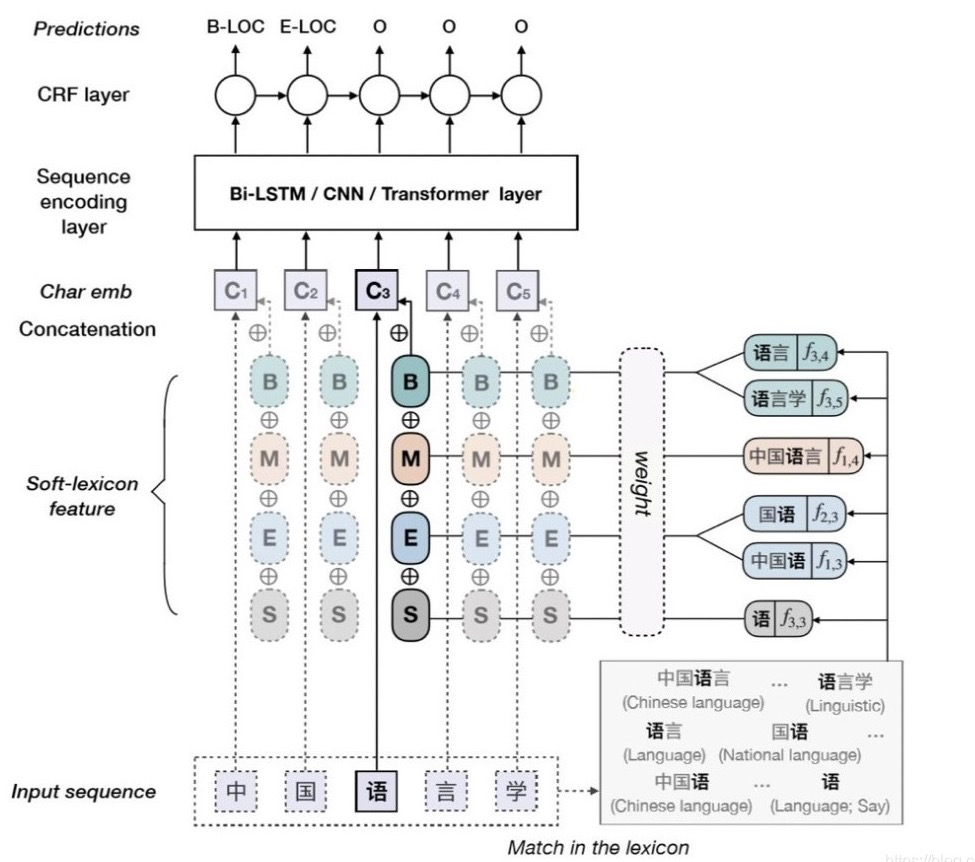
3.1.3 Simple-Lexicon模型
以LatticeLSTM为代表的词汇增强模型,其主要目的是解决中文分词的问题。实体识别任务经常被转换为一个序列标注问题,序列标注问题以字为单位,预测每个字对应的标签,模型的输入是以字序列作为输入,而以字序列的形式进行编码和解码,会忽略中文中重要的分词信息。如何分词在中文NLP任务中是非常重要的,会很大地影响模型的性能。
词汇增强模型的目的就是为了解决以如何让以字作为输入的模型使用词汇信息,在该评测中笔者只简单的做了一些和Simple-Lexicon模型相关的实验。笔者发现Simple-Lexicon模型并没有比BERT-CRF模型的效果好很多,分析原因是由于任务的特殊性,影响远程监督实体识别模型性能的比较重要的因素还是在于远程监督和迭代增强带来的错误传递和召回率低等问题,采用什么样的实体识别模型对能否解决以上两个问题其实影响并不大。
3.2 关系抽取、属性抽取部分
3.2.1 远程监督关系抽取与多示例学习
远程监督假设是指,假如两个实体之间存在某种关系,那么所有这两个实体共现的句子都有可能表达这种关系。这一假设过强,有些两个实体共现的句子并不能表达实体间的这种关系,例如下图中的两个句子,以及关系三元组 (“比尔盖茨,创建者 , 微软”)。
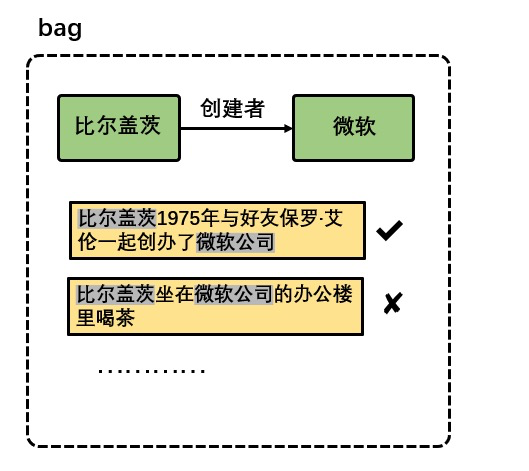
上图中的两个句子有一个可以体现三元组表达的关系,另一个不能表达这种关系。这些不能表达两个实体间关系信息的句子根据远程监督假设也会被进行标注然后当做训练语料,这些句子就是噪声数据,噪声数据严重影响了远程监督关系抽取模型的性能。
目前能够有效地在使用远程监督方式标注的数据集上进行关系抽取的模型,基本都采用了多示例学习的方法(小喵以前也在小组内分享过这个方法)。多示例学习的具体做法是,将训练集划分成多个具有分类标签的多实例包(bag),每个包含有若干个实例(instance)。多示例学习通过对包中实例的学习,训练出一个能够对包进行分类的分类器,并将该分类器应用于对未知标签的多示例包的预测。
上图就是一个多示例包,这个包的标签是“创建者”类型,包中有两个实例。其中第一个实例可以表达“创建者”这种关系,而第二个实例则无法体现这种关系,使用多示例学习方式训练的分类器想要达到一定的性能,需要能够很好地分辨出哪些实例是正实例(能够体现包的标签的含义),哪些实例是负实例(不能体现包的标签的含义)。
3.2.2 PCNN-One模型、PCNN-ATT模型
在多示例学习的训练过程中,关于如何从包中选择出正实例用于关系分类,主要有三种思想:
一种是基于“至少一个”假设,即假设包中至少有一个句子实例可以代表实体对之间的关系,这时任务目标就是训练一个分类器,将包中最有可能代表实体间关系的句子作为输入,对关系进行分类。这种思想就是PCNN-One模型采用的方法。
另一种方法基于注意力机制,使用一个能代表实体间关系的向量和包中的句子实例求相似度,得到一个权重参数,对不同的实例分配以不同的权重再求和,通过注意力的方式减小噪声数据的影响。这种思想是PCNN-ATT模型采用的方法。
还有一种是使用强化学习的方式,筛选出正实例进行关系分类。由笔者没有接触过强化学习,所以没有做采用强化学习方法去噪的相关实验。
在实验过程中远程监督关系模型在其他的一些语料上表现还可以,但是在评测的数据集上效果很不理想,主要是因为评测语料数据是以金融研报文章为单位,和标准的远程监督关系抽取语料(以句子为单位,需要分类的两个实体都会在句子中出现)差别较大,所以笔者在最终提交时还是使用的规则匹配的方法,没有使用PCNN-One模型和PCNN-ATT模型。
4.相关问题
4.1 实体抽取部分
4.1.1 使用Snowball方法在迭代过程中产生错误传递
使用迭代训练的方法,在一次训练过程中模型抽取出了错误的实体片段,这个错误的片段加入到种子知识图谱去标注语料会造成错误传递,为了提高Snowball方法的抽取效果,需要设计过滤方法,将模型抽取出的实体经过筛选后再加入进种子知识图谱中。
在做评测的过程中,笔者使用了规则的方法,观察模型抽取的结果,然后设计规则,过滤错误片段。这种方法不是很有效,因为模型做一些调整后,抽取的结果就不同了,规则也需要做相应的修改。而且错误片段的种类非常多,规则的方法很难全部覆盖到。
4.1.2 远程监督训练召回率低
如下图所示,种子知识图谱中有比尔盖茨和微软两个实体,通过实体对齐之后,无标数据中的比尔盖茨和微软两个实体被标注出来,但是,由于知识图谱的规模限制,实体 保罗·艾伦 不在知识图谱中,通过远程监督的方式不能将该实体标注出来。
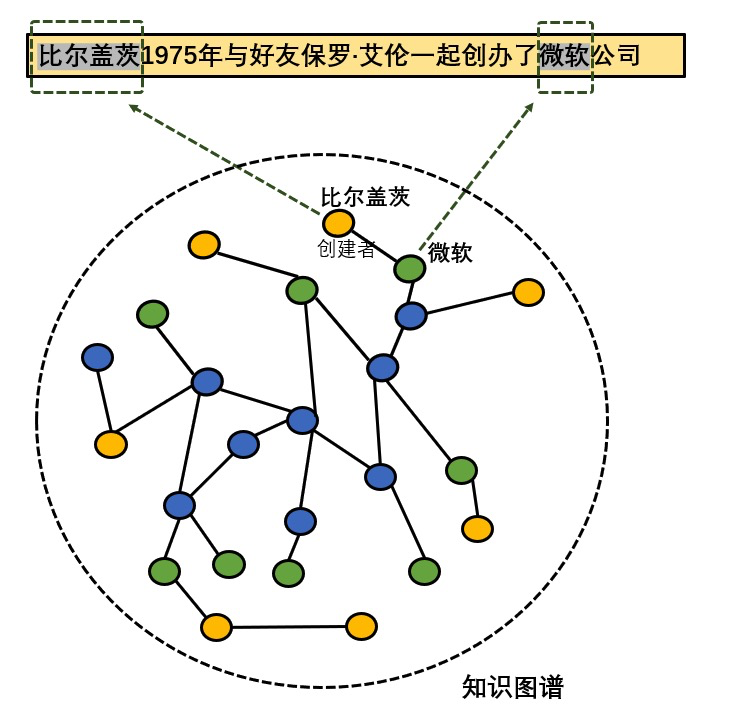
采用知识图谱对齐的方式会出现大量的目标实体未被标注的情况,所以使用远程监督标注的数据集训练的模型召回率比较低。
Snowball方法理论上是解远程监督实体识别召回率低的一个比较好的方案,但是实际实验结果却不是非常好。笔者打算在未来的改进方案中结合少量人工标注的数据,解决由于远程监督造成的召回率低的问题。
4.2 关系抽取、属性抽取部分
由于语料的问题,必须从句子级的关系抽取扩展到文档级别的关系抽取。
5.改进方案
这部分内容笔者正在尝试突破的方向,也是笔者研究生毕设的内容,现在已经有一些想法但还不好直接写出来,如果之后有一定的成果我再来完善。
5.1 实体抽取部分
在现有的方案上主要做两点改进:
1)加入使用深度学习方法训练的实体判别器
2)使用迁移学习的方法,在训练过程中加入相关领域的人工标注数据集,以及自己标注的部分数据,解决远程监督训练召回率低的问题
5.2 关系抽取/属性抽取部分
在现有的方案上主要做两点改进:
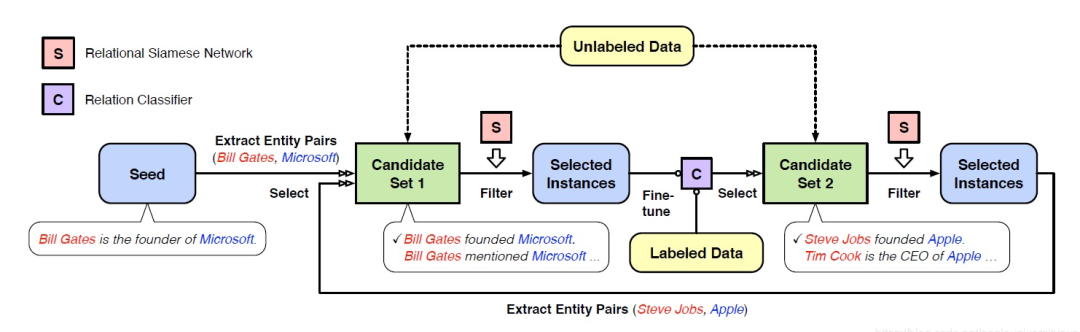
1)增加关系分类器,解决远程监督关系抽取的噪声问题
主要是参考AAAI2020年的一篇论文NeuralSnowball,增加一个像RSN关系分类器的模块,增强模型对噪声数据的区分,同时用人工标注一部分数据,使用其他领域大规模有标数据,少量人工标注的任务数据和大量无标注的任务数据做迁移学习。
2)使用文档级关系抽取模型
参考资料
[1]
笔者GitHub代码: https://github.com/JavaStudenttwo/ccks_kg
文章来源:https://blog.csdn.net/eagleuniversityeye/article/details/109587815
作者:iceburg-blogs
编辑:@公众号 AI算法小喵

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

