
- 1官方推荐:6种Pandas读取Excel的方法
- 2Stable Diffusion:详细版安装教程!_stable difusion 安装包
- 3关于人工智能的60条趋势预测
- 4#数据结构 线性表的顺序存储
- 5Uniapp 和Vue3 小程序 获取页面dom 方法_uniapp vue3 获取dom元素
- 6python爬虫开源项目代码基于Python实现的租房数据分析和展示系统_基于python的租房信息的抓取与可视化系统的设计与实现
- 7由浅入深详解NLP中的Adapter技术
- 8[Pytorch01]Tensor的创建与复制:tensor(a),detach(a),clone(a),=a
- 9基于python的爬虫原理和管理系统实现(代码下载)
- 10软件开发之版本控制方式_软件可控版本怎么控制的
80、DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION
赞
踩
简介
官网:https://dreamfusion3d.github.io/

基础先验知识:Mip-NeRF 360、Ref-NeRF、Imagen
使用预训练的2D文本到图像扩散模型(Imagen)来执行文本到3d(Mip-NeRF 360)合成
基于概率密度蒸馏的损失,使用二维扩散模型作为参数图像生成器优化的先验,通过梯度下降优化随机初始化的3D模型(NeRF)
使其随机角度的2D渲染实现低损失,不需要3D训练数据,也不需要修改图像扩散模型,证明了预训练的图像扩散模型作为先验的有效性
HOW CAN WE SAMPLE IN PARAMETER SPACE, NOT PIXEL SPACE
扩散模型作用与像素空间,对图像进行加噪、去噪。
这里问题不在对像素采样,而是需要创建的3D模型在从随机角度渲染时看起来像好的图像
这样的模型可以指定为可微图像参数化(DIP),其中可微生成器 g 转换参数 θ以创建图像 x = g(θ)
对于3D模型,指定 θ 为 3 D体积参数,g 为体积渲染器参数
目标是优化参数 θ,使 x = g(θ) 看起来像来自冻结参数的扩散模型的样本
对于生成的数据点 x = g(θ),最小化扩散训练损失,得到 θ ∗ = a r g m i n θ L D i f f ( φ , x = g ( θ ) ) θ∗= arg min_θ L_{Diff}(φ, x = g(θ)) θ∗=argminθLDiff(φ,x=g(θ))。
但这种方法很难,这里参考 L d i f f L_{diff} Ldiff 的梯度
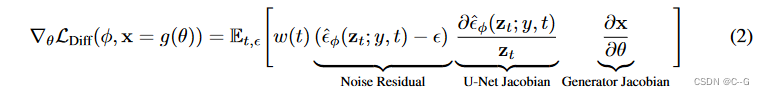
把常数
α
t
I
=
∂
z
t
/
∂
x
α_tI = ∂_{z_t} / ∂_x
αtI=∂zt/∂x 带入w(t),U-Net雅可比矩阵项的计算成本很高(需要通过扩散模型U-Net进行反向传播),并且在小噪声水平下条件不好,那么,省略U-Net雅可比项可以得到一个有效的梯度,用于使用扩散模型优化 DIPs
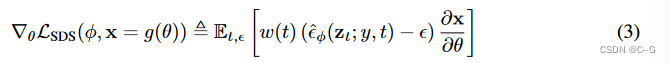
用时间步长 t 对应的随机噪声量扰动 x,并估计一个更新方向,该更新方向跟随扩散模型的分数函数移动到更高的密度区域
扩散模型学习 DIP 的梯度是使用从扩散模型学习的分数函数的加权概率密度蒸馏损失的梯度
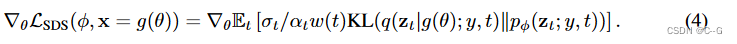
论文的抽样方法命名为分数蒸馏抽样(SDS),因为它与蒸馏有关,但使用分数函数而不是密度。
损失很容易实现,并且对于权重w(t)的选择相对稳健。

由于扩散模型直接预测了更新方向,我们不需要通过扩散模型进行反向传播;该模型就像一个有效的、冻结的评论家,预测图像空间的编辑。
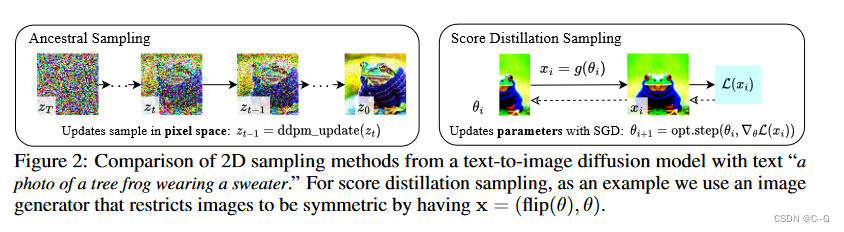
考虑到 L S D S L_{SDS} LSDS 的模态寻找性质,目前尚不清楚是否将这种损失最小化将产生良好的样本。
在上图中,证明了SDS可以生成具有合理质量的约束图像。根据经验,发现将引导权重 ω 设置为较大的无分类器引导值可以提高质量。
SDS产生的细节与 ancestral 采样相当,但由于它在参数空间中运行,因此可以实现新的迁移学习应用。

THE DREAMFUSION ALGORITHM
模型运行流程
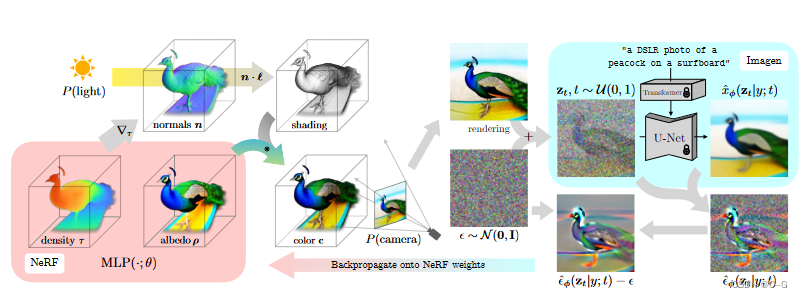
DreamFusion 通过预训练的、冻结权重参数的 Imagen 根据自然语言标题生成3D对象,例如“一只孔雀在冲浪板上的单反照片”。
场景由一个随机权重的Mip-NeRF 360表示,该场为每个标题随机初始化和从头训练。
Mip-NeRF 360用 MLP 参数化了体积密度和辐射度(颜色)。
从随机摄像机中渲染NeRF,使用从密度梯度中计算的法向量,以随机照明方向对场景进行着色。
阴影揭示了几何细节,从一个单一的观点是模糊的。
为了计算参数更新,DreamFusion对渲染进行扩散,并使用(冻结的)条件Imagen模型进行重建,以预测注入的噪声: ϵ ^ ϕ ( z t ∣ y ; t ) \hat{\epsilon}_\phi(z_t|y;t) ϵ^ϕ(zt∣y;t).
这包含了可以提高保真度的结构,但具有高方差。
ϵ ^ ϕ ( z t ∣ y ; t ) \hat{\epsilon}_\phi(z_t|y;t) ϵ^ϕ(zt∣y;t) 减去注入的噪声产生一个低方差的 update direction stopgrad [ ϵ ^ ϕ − ϵ ] [\hat{\epsilon}_\phi - \epsilon] [ϵ^ϕ−ϵ],该backpropagated 通过渲染过程反向传播以更新NeRF MLP参数。
nerf 公式
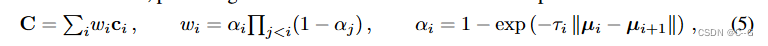
Shading
每个点使用RGB反照率ρ(材料的颜色)

τ 为体积密度,计算3D点的最终阴影输出颜色需要一个法向量,该法向量指示物体几何形状的局部方向
法向量可以通过公式 n = − ∇ μ τ / ∣ ∣ ∇ μ τ ∣ ∣ n = - \nabla_\mu \tau / ||\nabla_\mu \tau|| n=−∇μτ/∣∣∇μτ∣∣得到
通过表面法线 n,材料反照率 ρ,点光源3D坐标
l
l
l 和 颜色
l
p
l_p
lp,环境光的颜色
l
a
l_a
la,计算采样点颜色 c
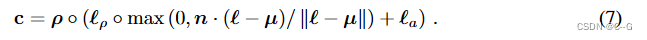
将采样点颜色 c 和 之前得到的体积密度 通过体渲染公式得到像素颜色
实验证明,将反照率颜色ρ随机替换为白色(1,1,1),以产生“无纹理”的阴影输出是有益的
这可以防止模型产生退化的解决方案,其中场景内容被绘制到平面几何上以满足文本条件。
例如,这鼓励优化生成3D松鼠,而不是包含松鼠图像的平面,两者从特定的视角和照明条件来看可能是相同的。
Scene Structure
只查询固定包围球内的NeRF场景表示是有帮助的,并使用从第二个MLP生成的环境地图,该MLP以位置编码的射线方向为输入来计算背景颜色
使用累积 α 值将渲染的光线颜色合成在背景颜色之上
可以防止NeRF模型填充空间密度非常接近相机,同时仍然允许它在生成的场景后面绘制适当的颜色或背景
Geometry regularizers
对每条光线的不透明度进行了正则化惩罚,防止对空白空间的不必要填充
使用方向损失的修正版本-Ref-NeRF,防止密度场中法向量背对相机
当包含无纹理的底纹时,这个惩罚是很重要的,因为密度场会试图将法线朝向远离相机,这样底纹就会变得更暗
TEXT-TO-3D SYNTHESIS

整体流程可以简化理解为:
- 随机采样相机和灯光
- 从该相机渲染NeRF的图像,并使用光线计算阴影
- 计算SDS损失相对于NeRF参数的梯度
- 使用优化器更新NeRF参数
Random camera and light sampling
从球坐标系中采样相机和灯光,仰角 ϕ c a m ∈ [ − 1 0 ∘ , 9 0 ∘ ] \phi_{cam} \in [-10^\circ,90^\circ] ϕcam∈[−10∘,90∘],方位角 θ c a m ∈ [ 0 ∘ , 36 0 ∘ ] \theta_{cam} \in [0^\circ,360^\circ] θcam∈[0∘,360∘],距原点的距离 [1,1.5],场景边界球的半径为1.4,还采样原点周围的一个“观察”点和一个“向上”向量,并将它们与摄像机位置结合起来创建摄像机姿态矩阵,还采样了一个焦距乘子 λ f o c a l ∈ μ ( 0.7 , 1.35 ) \lambda_{focal} \in \mu(0.7,1.35) λfocal∈μ(0.7,1.35),那么焦距为 λ f o c a l ω \lambda_{focal} \omega λfocalω,其中 ω = 64 \omega = 64 ω=64 是图像像素宽度
点光源位置 l l l 从以相机位置为中心的分布进行采样,使用大范围的相机位置对于合成连贯的3D场景至关重要,而大范围的相机距离有助于提高学习场景的分辨率
Rendering
渲染 64 × 64 64 \times 64 64×64 的图像,在照明颜色渲染、无纹理渲染和无任何阴影的反照率渲染之间随机选择
Diffusion loss with view-dependent conditioning
文本提示通常描述的是对象的规范视图,而在对不同视图进行采样时,这并不是很好的描述
根据随机采样相机的位置将依赖于视图的文本附加到所提供的输入文本中是有益的
对于高仰角 ϕ c a m > 60 ° \phi_{cam} > 60° ϕcam>60°,附加“俯视图”,对于 ϕ c a m ≤ 60 ° \phi_{cam} \leq 60° ϕcam≤60°,使用文本嵌入的加权组合来附加“正面视图”,“侧面视图”或“背面视图”,这取决于方位角 θ c a m θ_{cam} θcam 的值
使用预训练的64 × 64基础文本到图像模型。该模型在大规模的web-图像-文本数据上进行训练,并以T5-XXL文本嵌入为条件
定义加权函数 ω ( t ) = σ t 2 \omega(t) = \sigma^2_t ω(t)=σt2,但是实验发现这与均匀加权表现相似
均匀采样 t ∼ μ ( 0.02 , 0.98 ) t \sim \mu(0.02,0.98) t∼μ(0.02,0.98)
对于无分类器引导,设置 ω = 100 \omega = 100 ω=100,实验表明更高的引导权重可以提高样本质量
实验
使用4个芯片的TPUv4,每个芯片呈现一个单独的视图,并评估扩散U-Net,每个设备批量大小为1,训练迭代 15,000次,训练时间为1.5小时
Limitation
SDS在应用于图像采样时并不是一个完美的损失函数,相对于原始采样,它往往会产生过饱和和过平滑的结果
虽然动态阈值在将SDS应用于图像时部分改善了这个问题,但它并没有在NeRF上下文中解决这个问题
与 ancestral 采样相比,使用SDS生成的2D图像样本往往缺乏多样性,3D结果在随机种子之间显示出很少的差异
DreamFusion使用64 × 64 Imagen模型,因此3D合成模型往往缺乏细节
使用更高分辨率的扩散模型和更大的NeRF可能会解决这个问题,但合成会变得不切实际地慢


