
- 1php telnet ros,python telnet登陆RouterOS执行相关命令,并返回命令执行结果,pythonrouteros,#Telnet Rout...
- 2美团面试官让我简单介绍下自己,我说:我是一个很普通的人,结果....._美团面试自我介绍的简文
- 32022年CSP-J组入门级初赛考试题目_cspj2022初赛试题
- 4第三章:深入浅出理解分布式一致性协议Gossip和Redis集群原理_分布式一致性协议 gossip 和 redis 集群原理解析_redis集
- 5Vitalik香港峰会演讲后思考:以太坊正在追求密码学的极限
- 6假期离校必备:Mac远程连接Win10桌面(设置断电自动重启、Win10配置远程桌面、Microsoft Remote Desktop Beta远程桌面连接、将Win作为服务器可以conda跑代码)_microsoft remote desktop 如何配置
- 7软件测试二面技术问题,腾讯测试二面(4.25)
- 8大型语言模型(LLM)中的token_llm中的token
- 9axios教程_axios.get
- 10记录安装apollo6.0中遇到的几个问题_bash docker/scripts/dev_start.sh
SLS 查询新范式:使用 SPL 对日志进行交互式探索
赞
踩
作者:无哲
引言
在构建现代数据和业务系统的过程中,可观测性已经变得至关重要,日志服务(SLS)为 Log/Trace/Metric 数据提供了大规模、低成本、高性能的一站式平台服务,并提供数据采集、加工、投递、分析、告警、可视化等功能,从而全面提升企业在研发、运维、运营和安全等各种场景的数字化能力。
日志数据天然是非结构化的
日志(Log)数据作为可观测场景中最基础的数据类型之一,其最大的特点在于,日志数据是天然是非结构化的,具体与多种因素有关:
- 来源多样性:日志数据种类繁多,不同来源的数据难以具有统一的 Schema
- 数据随机性:比如异常事件日志、用户行为日志,往往天然就是随机的,难以预测的
- 业务复杂度:不同的参与方对数据的理解不同,比如开发流程中打日志的一般是开发者,但分析日志的往往是运营和数据工程师,写日志过程中难以预见到后期具体的分析需求

这些因素导致很多情况下可能并不存在一个理想的数据模型可以用来预先处理好日志数据,更常见的做法往往是直接存储原始数据,这可以称为是一种 Schema-on-Read 的做法,或者是所谓的寿司原则(The Sushi Principle:Raw data is better than cooked, since you can cook it in as many different ways as you like)。而这种“杂乱无章”的原始日志数据也给分析人员增加了难度,因为往往是需要对数据模型具有一定的先验知识,才能对数据进行比较好的结构化分析。
来自 Unix 管道的启发:交互式探查
在各种日志分析系统与平台出现之前,开发运维人员最传统的日志分析方式,是直接登录到日志文件所在的机器上去 grep 日志,并配合一系列 Unix 命令对日志进行分析处理。
比如要查看访问日志中 404 的来源 host,可能就会用到这样的命令:
grep 404 access.log | tail -n 10 | awk '{print $2}' | tr a-z A-Z
- 1
这条命令中通过 3 个管道操符,将 4 个 unix 命令行工具(关键词查找、日志截断、字段提取、大小写转换)连成了一条完整的处理栈。
值得注意的是,在使用这样的命令的时候,我们往往并不是一次性就写出完整的命令,而是写完一个命令之后就按下回车,观察执行输出的结果,然后再通过管道追加下一步的处理命令,继续执行,如此一直进行下去。

这个过程中充分体现了 Unix 的设计哲学,通过管道将一个个小而美工具组合成强大的程序。同时从日志分析的角度看,我们可以获得这样的启发:
1)交互式、递进式的探查,每次在上一次的基础上叠加执行
2)探查的过程中往往不会处理全量数据,而是截取一小部分样本数据进行分析
3)探查过程中进行的各种处理操作,只影响本次查询的输出,并不改变原始数据
可以感受到,这种交互式探查的操作,对于日志数据是一种很好的探索方式,那么在 SLS 这样的云上日志平台,当面对海量的原始日志数据的时候,我们期望也能使用类似 Unix 管道这样的方式,在查询时先通过多级管道对数据一步步递进式的探查处理,帮助我们在杂乱无序的日志中挖掘出数据的规律,进而就可以更加带有目的性的去完成后续的加工清洗、消费投递、SQL 聚合分析等操作。
SPL-日志的统一处理语法
SPL(详见 SPL 概览 [ 1] ),即 SLS Processing Language,是 SLS 对日志查询、流式消费、数据加工、Logtail 采集、以及数据 Ingestion 等需要数据处理的场景,提供的统一的数据处理语法,这种统一性使得 SPL 可以在整个日志处理的生命周期内,实现 “Write Once,Run Anywhere” 的效果。

SPL 基本语法如下:
<data-source> | <spl-expr> ... | <spl-expr> ...
- 1
其中< data-source >是数据源,对于日志查询的场景,指的就是索引查询语句。
< spl-expr >是 SPL 指令,支持正则取值、字段分裂、字段投影、数值计算等多种操作,具体参考 SPL 指令介绍 [ 2] 。
从语法定义上可以看到,SPL 天然是支持多级管道的。对于日志查询的场景来说,在索引查询语句之后,可以根据需要通过管道符不断追加 SPL 指令,每一步都可以点击查询查看当前的处理结果,从而获得类似 Unix 管道处理的体验。并且相比于 Unix 指令,SPL 具备更丰富的算子和函数,可以对日志进行更为灵活的调试分析和探索分析。
使用 SPL 查询日志
在日志查询场景中,SPL 是工作在扫描模式下的,可以直接针对非结构化的原始数据进行处理,不受是否创建索引以及索引类型的限制。扫描的时候按照实际扫描的数据量计费,详见扫描查询概述 [ 3] 。
统一的查询交互
扫描查询和索引查询虽然背后是不同的工作原理,但是在对用户的界面(控制台查询、GetLogs API)上,都是完全统一的交互。
在查询日志的时候,当输入索引查询语句的时候,就是通过索引查询。

再继续输入管道符和 SPL 指令,就会直接自动按照扫描模式对索引过滤的结果进行处理(无须再通过一个“扫描模式”的按钮来额外指定),并且会提示当前处于 SPL 输入模式。

更友好的语法提示
此外,在控制台查询的时候,会自动识别当前所处的语法模式,并对 SPL 相关指令和函数进行智能提示。
随着输入,下拉框自动提示相应的语法关键词、函数。


如果你一时忘记了某个语法怎么写,不用离开当前界面再去查找文档。直接移动光标放在某个关键词上,就会弹出详细的帮助信息。

筛选字段获得更精简的视图
在打日志的时候,为了将来潜在的分析需求,我们一般会尽量多打一些相关信息到日志里,因此往往会发现最终单条日志中会存在比较多的字段。
这种情况下,在 SLS 控制台查询的时候,一条日志占据的空间太多,即使将顶部的柱状图和侧边的快速分析栏都折叠起来,在日志原文区域也只能同时看到一两条日志,要不断地滚动鼠标翻页才能看其他日志,使用起来较为不便。

然而实际上我们在查询日志的时候,往往是带着某个目的去检索,这个时候一般是只关心其中的部分字段。这时就可以使用 SPL 中的 project 指令,只保留自己关心的字段(或者使用 project-away 指令,移除不需要看到的字段。这样不仅可以移除干扰,将注意力集中在当前要关注的字段上,而且由于字段精简了,也可以同时预览到更多条的日志。)

实时计算出新的字段
前面提到过,由于写入日志的时候无法完全预见分析的需求,因此分析日志的时候,常常会需要对已有字段加工提取出新的字段,这可以通过 SPL 的 Extend 指令实现。
使用 Extend 指令,可以调用丰富的函数(这些大部分是和 SQL 语法通用的)进行标量处理。
Status:200 | extend urlParam=split_part(Uri, '/', 3)
- 1
同时也可以根据多个字段计算出新的字段,比如计算两个数字字段的差值。(注意字段默认是被视为 varchar,进行数字类型计算的时候要先通过 cast 转换类型)
Status:200 | extend timeRange = cast(BeginTime as bigint) - cast(EndTime as bigint
- 1
灵活的进行多维度过滤
索引查询只能根据进行关键词、多个关键词组成的短语、关键词末尾模糊等搜索方式,在扫描模式下,可以通过 where 质量可以按照各种条件过滤,这个是当前扫描查询已经具备的能力,在升级到 SPL 之后,where 可以放在任意一级管道,对计算出的新字段进行过滤,从而具备更灵活更强大的过滤能力。
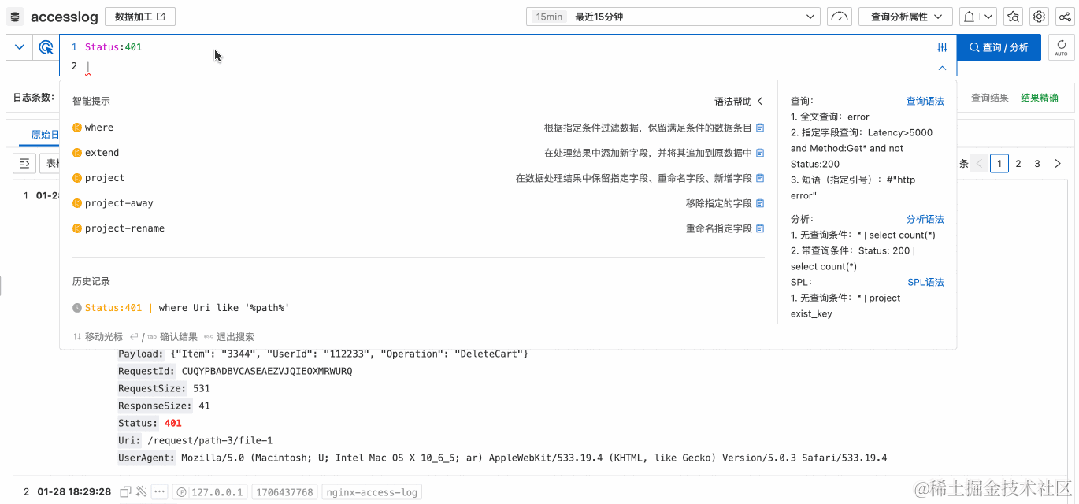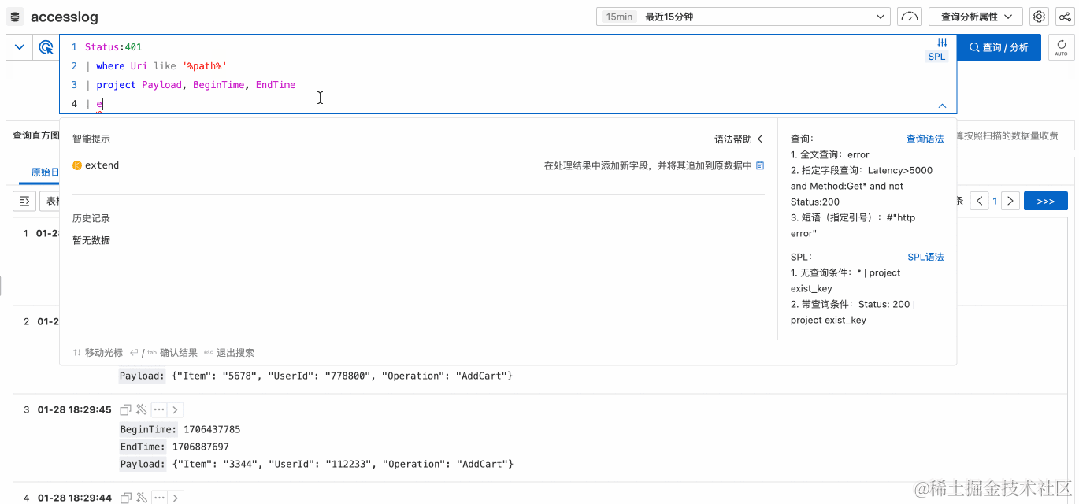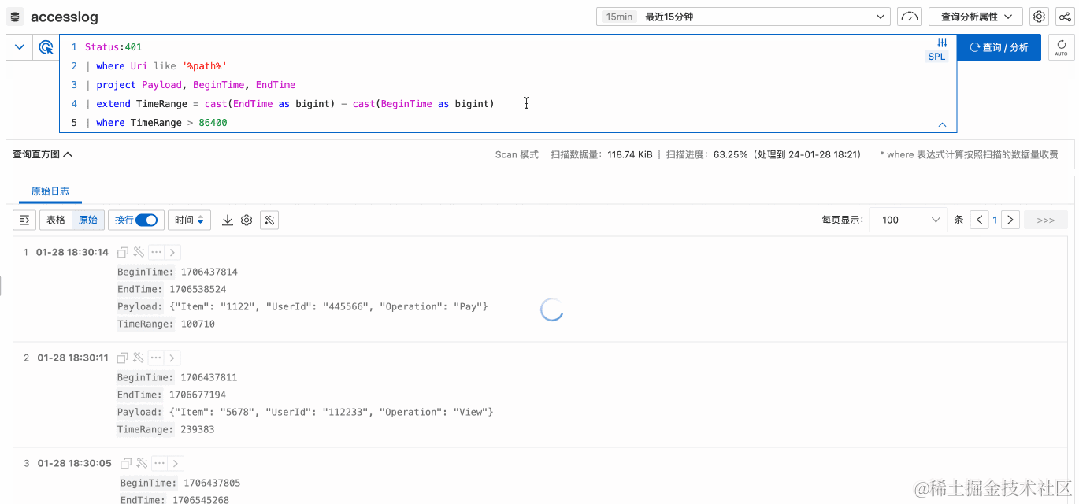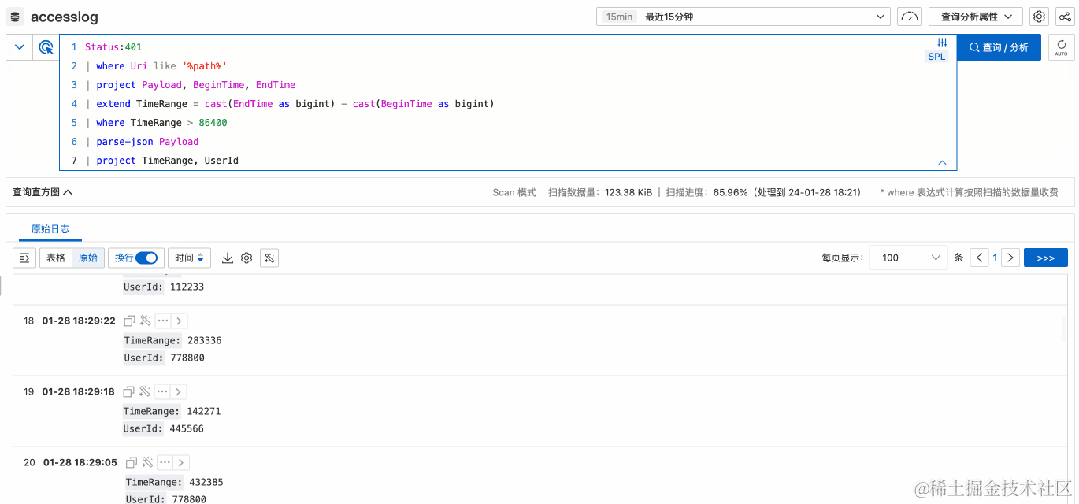
比如,根据 BeginTime 和 EndTime 计算出 TimeRange 之后,可以再对这个计算后的值进行判断过滤。
Status:200
| where UserAgent like '%Chrome%'
| extend timeRange = cast(BeginTime as bigint) - cast(EndTime as bigint)
| where timeRange > 86400
- 1
- 2
- 3
- 4
自由的展开半结构化数据
我们的日志中有的时候会存在某个字段本身是 json、csv 这种半结构化数据的情况,我们可以使用 extend 指令去提取其中某个子字段,但是如果要分析的子字段比较多,就会需要写大量的 json_extract_scalar 或者 regexp_extract 这样的字段提取函数,较为不便。
SPL 提供了 parse-json、parse-csv 这样的指令,可以将 json、csv 类型的字段,直接完全展开出为独立的字段,之后就可以直接对这些字段进行操作。省去了书写字段提取函数的开销,在交互式查询场景中这种写法是更为便捷的。

所思即所见的沉浸式探索体验
让我们再通过一张动图来感受下,在探索日志的过程中,通过管道随着 SPL 指令的不断输入,对数据进行抽丝剥茧的逐级处理,每一步都可以将脑海中思考的处理步骤,物化在查询结果页面视图上,所思即所见,所见即所得,在一步步的交互式探索中,最终提取出我们需要分析的结构化信息。
总结
由于数据来源的多样性和分析需求的不确定性,日志数据往往是直接以非结构化的原始数据存储,这为查询分析带来了一定挑战。
SLS 推出日志统一处理语言 SPL,在日志查询场景下,可以通过多级管道对数据进行交互式、递进式的探索,从而更便捷的发现数据特征,并更好的进行后续的结构化分析和加工消费等处理流程。
目前查询支持 SPL 的功能已经在各个地域上线,欢迎大家使用。如果有任何问题和需求,可以通过工单和支持群反馈给我们。SLS 将持续不断努力,打造一个更易用、更稳定、更强大的可观测分析平台。
相关链接:
[1] SPL 概览
https://help.aliyun.com/zh/sls/user-guide/spl-overview
[2] SPL 指令介绍
https://help.aliyun.com/zh/sls/user-guide/spl-instruction?spm=a2c4g.11186623.0.0.197c59d4pRrjml
[3] 扫描查询概述
https://help.aliyun.com/zh/sls/user-guide/scan-based-query-overview
参考链接:
[1] The Sushi Principle
https://www.datasapiens.co.uk/blog/the-sushi-principle
[2] Unix Commands, Pipes, and Processes
https://itnext.io/unix-commands-pipes-and-processes-6e22a5fbf749
[3] SPL 概述
https://help.aliyun.com/zh/sls/user-guide/spl-overview
[4] 扫描查询概述
https://help.aliyun.com/zh/sls/user-guide/scan-based-query-overview
[5] SLS 架构升级-更低成本、更高性能、更稳定和易用
https://login.alibaba-inc.com/ssoLogin.htm?APP_NAME=ata&BACK_URL=https%3A%2F%2Fata.atatech.org%2Farticles%2F11020158038&CONTEXT_PATH=%2F


