
- 1go 利用channel实现定时任务
- 2spring boot应用程序接口调优记录_spring boot 压测
- 33D抓取算法的网络结构原理及作用
- 4【Python自动化Excel】多个excel文件,按列匹配数据_用python实现将多个excel按某列匹配合并
- 5github 2fa中国认证及TOTP App_two-factor authentication (2fa) is required for yo
- 6NVIC中断分组和配置
- 7ambari全攻略流程,认识ambari(一)
- 8git推送时密码出错无法重新输入出现Authentication failed for解决_git push authentication failed for
- 9uni-app总结_猫眼电影播放 uniapp
- 10超详细的Guava RateLimiter限流原理解析_ratelimiter 分钟限流
【论文精读】Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement_retinexformer: one-stage retinex-basedtransformer
赞
踩
代码链接:https://github.com/caiyuanhao1998/retinexformer

目录
3.1. One-stage Retinex-based Framework(ORF)
3.1.6. illumination estimator()
3.2. Illumination-Guided Transformer
Abstract
任务:增强低光照图片
背景:很多算法使用Retinex理论
痛点:
①很多Retinex模型没有考虑到损坏(corruptions)现象(噪声、伪影、色彩失真等现象),这种损坏藏在黑暗中or在光照的过程中被引入;
②这些算法需要繁琐的多步骤训练pipeline,它们依赖于卷积神经网络,在捕获long-range的依赖的时候存在局限性。
本文方法:
①提出一个简单但有规则的基于Retinex的单阶段框架(ORF):
- 首先,ORF估计照明信息来使低光照图像变亮
- 然后,恢复损坏来生成增强图像
②设计一个光照引导的transformer(IGT):利用光照特征来指导不同光照条件区域的non-local相互作用的建模
③将IGT插入ORF得到算法Retinexformer
实验:
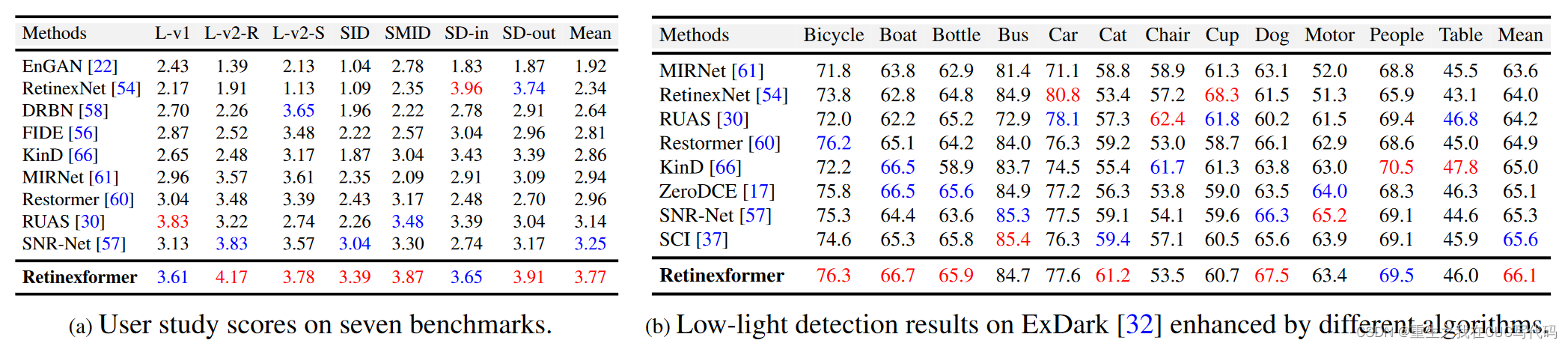
全面的定量和定性实验表明,我们的 Retinexformer 在 13 个基准测试中显着优于最先进的方法。
低光物体检测的用户研究和应用也揭示了我们的方法的潜在实用价值。
1. Introduction
低光照增强任务:
它的目的是改善低光图像的可见度差和对比度低的问题,并恢复隐藏在黑暗中或由点亮过程引入的损坏(例如噪声、伪影、颜色失真等)。
低光照增强算法:
| 方法类别 | 方法 | 介绍 | 缺点 |
| 简单方法 | 直方图均衡、伽马矫正 | 简单方法直接放大曝光不足图像的低可见度和对比度。几乎不考虑光照因素 | 会产生不需要的伪影,和真实正常光场景下的图像在感知上不一致 |
| 传统认知方法 | 基于Retinex理论的方法 | 将彩色图像分为两个部分:反射率和光照强度,假设图像无噪声和颜色失真,聚焦于光照强度估计 | ①会引入噪声or局部颜色失真,与真实曝光不足的场景不一致;②依赖于手工设计的先验,调参工作细致繁琐且泛化能力较差 |
| 基于CNN的方法 | 直接使用CNN来学习从低光照到正常光照图像的强力映射函数的方法 | 忽略人类的颜色感知 | 缺乏可解释性和理论上可证明的特性,在捕获long-range依赖性和非局部自相似性方面表现出局限性。 |
| 多步骤训练pipeline方法 | 分别采用不同的 CNN 来分解彩色图像、对反射率进行降噪并调整照明。这些 CNN 首先独立训练,然后连接在一起进行端到端微调。 | 训练过程繁琐耗时,在捕获long-range依赖性和非局部自相似性方面表现出局限性。 | |
| 深度学习模型 | transformer | 可能提供解决基于 CNN 的方法的这一缺点的可能性。然而,直接应用原始视觉 Transformer 进行低光图像增强可能会遇到问题。计算复杂度与输入空间大小成二次方。计算消耗大。 | |
| CNN-Transformer混合算法 | SNR-Net等 | Transformer 在弱光图像增强方面的潜力仍未得到充分开发。 |
本文贡献:
提出Retinexformer进行低光照增强,将IGT作为corruption restorer插入ORF得到Retinexformer
基于Retinex的单阶段架构ORF,估计光照强度信息,将低光照图像变亮
向反射率和光照强度引入扰动项(perturbation terms)来修改原始Retinex模型
使用损坏恢复器(corruption restorer)抑制噪声、伪影、曝光不足/过度以及颜色失真。
引入光照引导transformer(IGT),建模long-range依赖性
光照引导多头自注意力(IG-MSA),用光照特征引导自注意力的计算and增强不同曝光水平区域的交互
实验(略,大概就是实验效果很牛13的意思)见图1

2. Related Work
2.1. 低光照图像增强
普通方法、传统方法、深度学习方法(略,详见1.introduction中的低光照增强部分and论文原文)
2.2. 视觉transformer
transformer方法(略,详见1.introduction中的低光照增强的部分)
3. Method
整体架构如图2所示。
- Retinexformer基于ORF
- ORF由光照强度估计器(illumination estimator)(i)和一个损坏重建器(corruption restorer)(ii)组成。
- 光照引导的transformer(IGT)用来充当corruption restorer的角色,如图2(b)所示
- IGT的基本单元是光照引导的注意力块(IGAB)
- IGAB由两个标准化层(LN)、一个光照引导的多头注意力模块(IG-MSA,如图2(c)所示)和一个前馈网络组成(FFN)

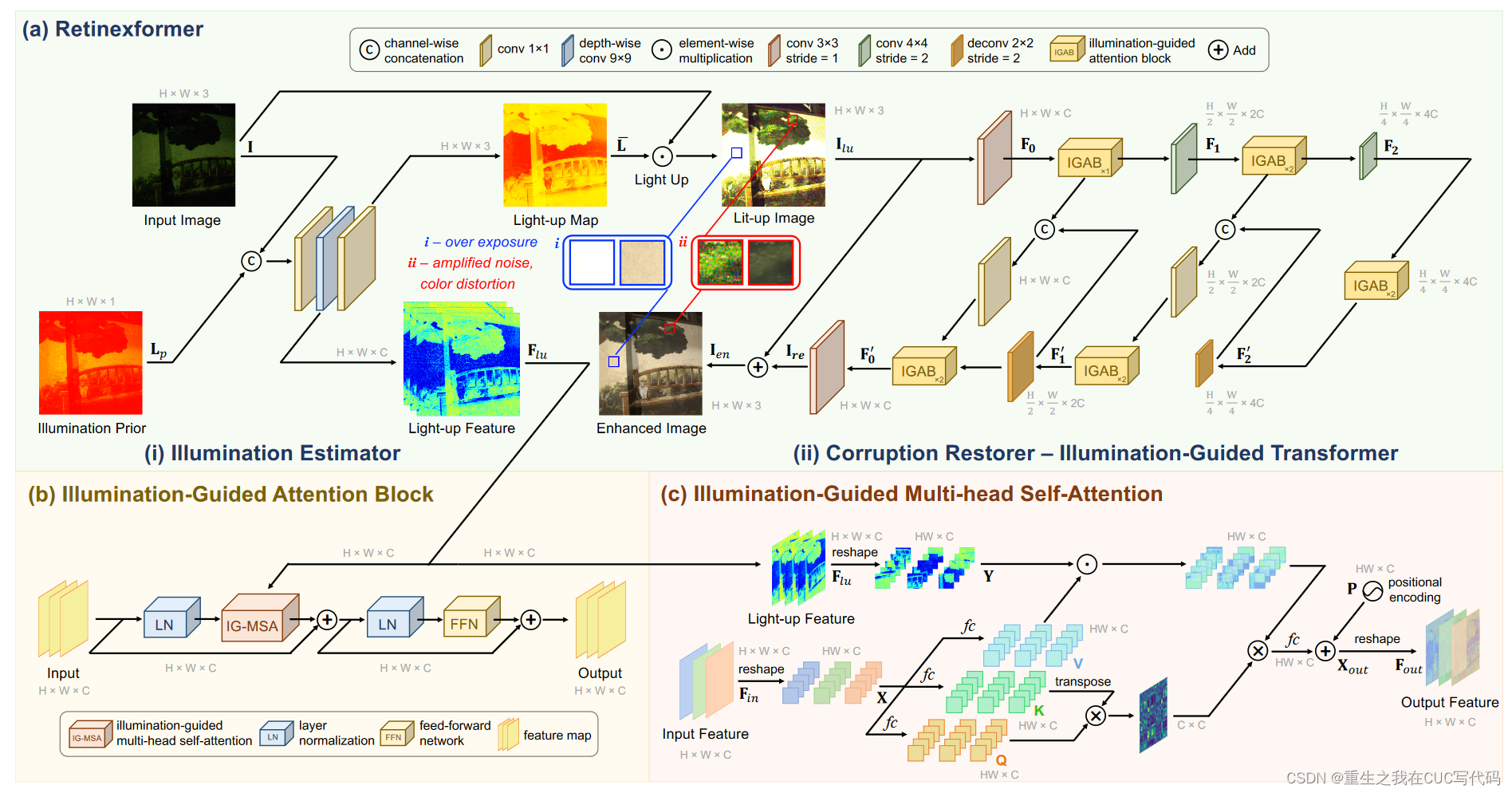
3.1. One-stage Retinex-based Framework(ORF)
3.1.1. 基于的retinex模型
retinex原理:低光照图片可以分解成反射值图片
和光照强度图

:逐元素的乘积
该模型假设I无curruption
3.1.2. corruption的来源
(1)暗场景的高ISO和长曝光成像设置引入噪声和伪影
(2)将暗场景变亮的过程也会造成曝光不足/过曝光和颜色失真(图2(a)中i和ii)
3.1.3. 建模corruption
如公式(2),分别为R和L引入扰动项
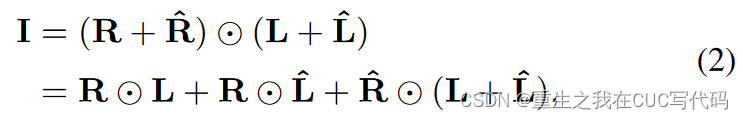
:是边缘扰动
3.1.4. 将低光照图像变亮
在公式(2)的两边同时逐元素相乘一个点亮图(light-up map),如公式(3)所示。
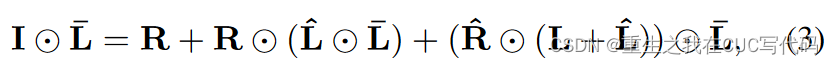
:暗场景中的噪声和伪影
:表示由light-up过程引起的过曝光/曝光不足和颜色失真
简化(3)得到公式(4)
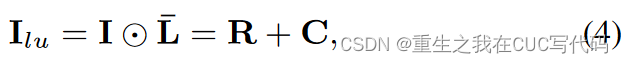
:点亮项 lit-up image/item
:完整的corruption项
3.1.5. ORF数学表达式
ORF设计如公式(5)所示:
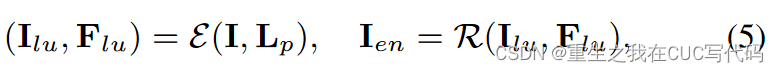
:光照估计(illumination estimator)
:corruption restorer
:I的光照先验图,
,
表示沿着通道维度计算每个像素的平均值。
:light-up feature
:增强后的图
3.1.6. illumination estimator( )
)
如图2(a)(i)所示
①先用kernel size=1的卷积conv1×1:融合I和Lp的级联
②用一个深度可分离的卷积conv9×9:模拟不同光照条件下区域的相互作用,来生成light-up特征。因为曝光良好的区域可以动态的提供上下文信息给曝光不充足的区域
③conv1×1:聚合生成light-up map
,将
设置为三通道RGB张良来提高其在模拟RGB通道之间的非线性来进行颜色增强方面的representation capacity。
④用来light up公式(3)中的I
3.1.7. discussion
(1)先前的基于retinex的深度学习网络方法估计光照图L,而ORF估计light-up map。
- 因为如果估计L,lit-up image将通过逐像素的除法得到(I./L),计算机对这种操作的处理非常的薄弱,张良的值将会变得很小,有时候甚至等于0。除法容易造成数据溢出问题。
- 此外,计算机随机产生的小误差会被该运算放大,导致估计不准确。
因此,建模鲁棒性更好
(2)先前的基于retinex的深度学习方法主要聚焦于在反射图上抑制噪音这样的corruptions,容易导致点亮过程中过曝或曝光不足以及颜色失真的问题,而ORF考虑所有corruptions并使用corruption restorer来解决问题。
3.2. Illumination-Guided Transformer
问题:
- 之前的深度学习方法主要依赖于CNN,在捕获long-range依赖性方面表现出了局限性
- 一些CNN-transformer混合工作仅在U-shaped CNN的最低分辨率下使用全局transformer层。transformer的潜力尚未得到充分挖掘。
解决方法:
设计光照应道的transformer(IGT)来起到公式(5)中corruption restorer的作用
3.2.1. 网络架构
如图2(a)(ii)所示,IGT采用三尺度U形架构。
- IGT的输入是lit-up iamge
- 降采样分支中,
经过一个步长为2的3×3的卷积、一个IGAB、一个步长为2的4×4卷积、两个IGAB和一个步长为2的4×4的卷积层生成分层特征
。
经过两个IGBA
- 上采样分支是一个对称结构,用步长为2的反卷积操作deconv2×2来升级特征。跳跃连接用来减轻下采样分支带来的信息损失。上采样分支输出一个残差图像
,然后增强的图像
3.2.2. IG-MSA
如图2(c)所示,IG-MSA的输入是通过光照估计得到的light-up特征
注意:使用stride=2的conv4×4层来缩小的尺寸来匹配空间大小(该部分在图2中被省略了)
问题:全局MSA的巨大计算成本限制了transformer在低光照图像增强中的应用
解决方法:IG-MSA将单通道特征视为token然后计算自注意力机制
①将输入的特征重塑为tokens
②将X分成k个head,如公式(6)所示

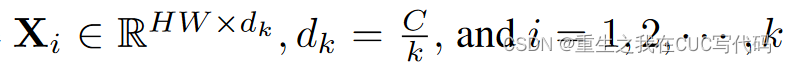
③对于每个,使用三个无偏差的全连接层(
)将
线性投影到query元素
,key元素
和value
元素,如公式(7)所示
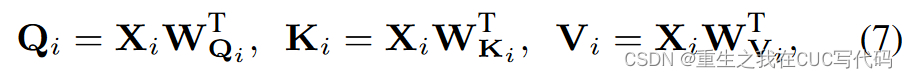
:全连接层可学习的参数
T:转置矩阵
光照条件更好的区域能够帮助增强黑暗的区域,因此,使用光照特征编码光照信息和不同光照条件下区域的交互来引导自注意力的计算。
④为了与X的形状保持一致,将重塑为
,并将其分成k个head,如公式(8)所示

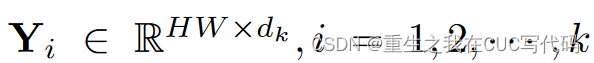
⑤每个的自注意力定义如公式(9)所示
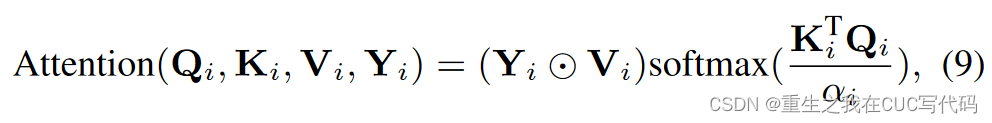
:可学习的参数,可自适应缩放矩阵乘法
⑥k个head连接起来通过全连接层,然后加上位置编码(可学习的参数)来生成输出tokens
⑦最终,重塑来获得输出特征
3.2.2. 复杂性分析
(主要就是说IG-MSA计算复杂性降低成本减少,能够插入网络的每个基本单元中。略,详情见论文)
4.Experiment
4.1. 数据集和实验细节
LOL(包含v1 和 v2)、SID 、SMID、SDSD和 FiveK 数据集。
4.2. 实验结果
4.2.1. 定量实验



4.2.2. 定性实验




