
热门标签
热门文章
- 1java MD5算法返回数字型字串_java md5加密并将结果用十进制表示
- 2C++初识--------带你从不同的角度理解引用的巧妙之处
- 3【送书福利-第三十期】《Java面试八股文:高频面试题与求职攻略一本通》_java面试八股文高频面试题与求职攻略电子书
- 4Windows中redis怎么设置密码_windows redis设置密码
- 5Vue中组件生命周期过程详解_vue 子组件生命周期
- 6树莓派安装python3.9以及pip换源_树莓派安装pip
- 7python无人机路径规划算法_无人机集群——航迹规划你不知道的各种算法优缺点...
- 8卓越体验的秘密武器:评测ToDesk云电脑、青椒云、天翼云的稳定性和流畅度_青椒云评价
- 9Mybatis 注解实现基本 CRUD_mybatis mapper 注解方式编程:针对模型类设计基本的 crud 功
- 10数据结构-----二叉排序树
当前位置: article > 正文
RAG基础知识及应用_rag应用
作者:Cpp五条 | 2024-04-30 13:34:06
赞
踩
rag应用
简单介绍下RAG的基础知识和RAG开源应用 “茴香豆"
一. RAG 基础知识
1. RAG工作原理
RAG是将向量数据库和大模型问答能力的有效结合,从而达到让大模型的知识能力增加的目的。首先将知识源存储在向量数据库中,当提出问题时,去向量数据库检索,找到相关的部分后,一起送给大模型生成最终的回答。
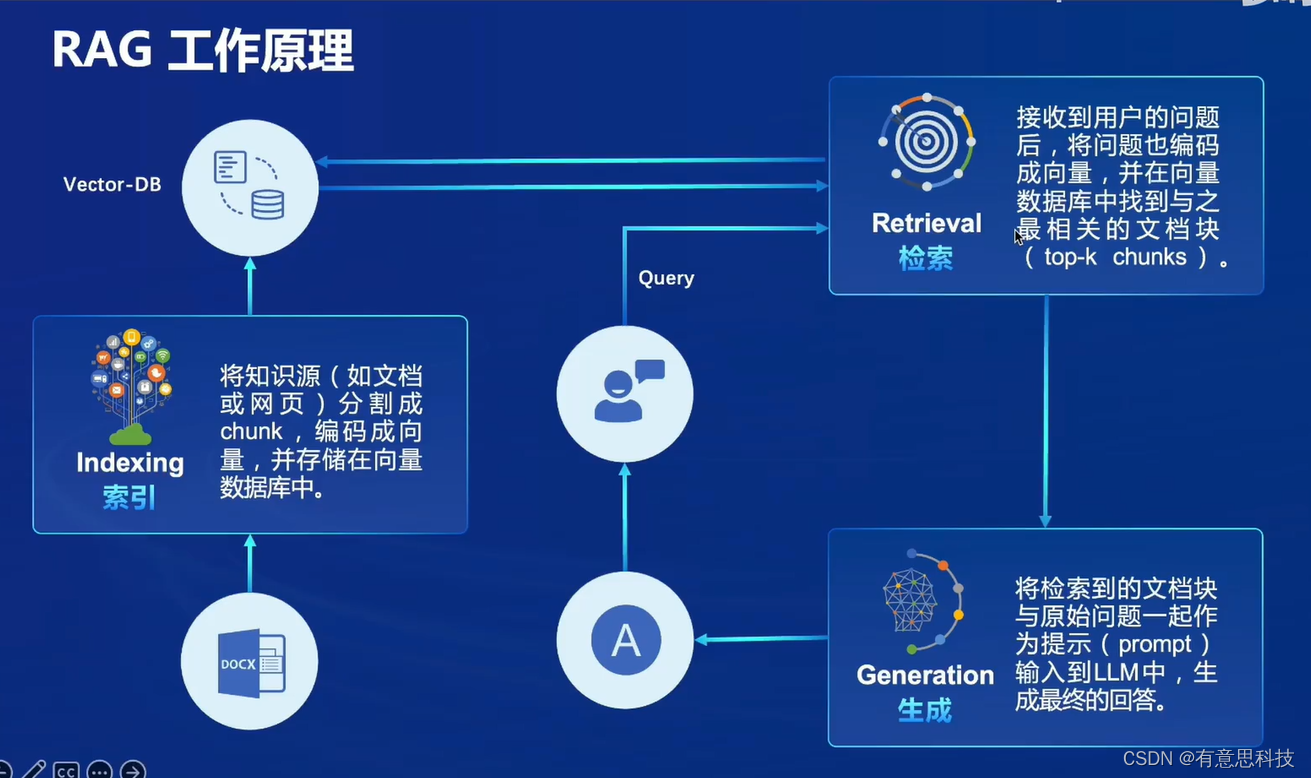
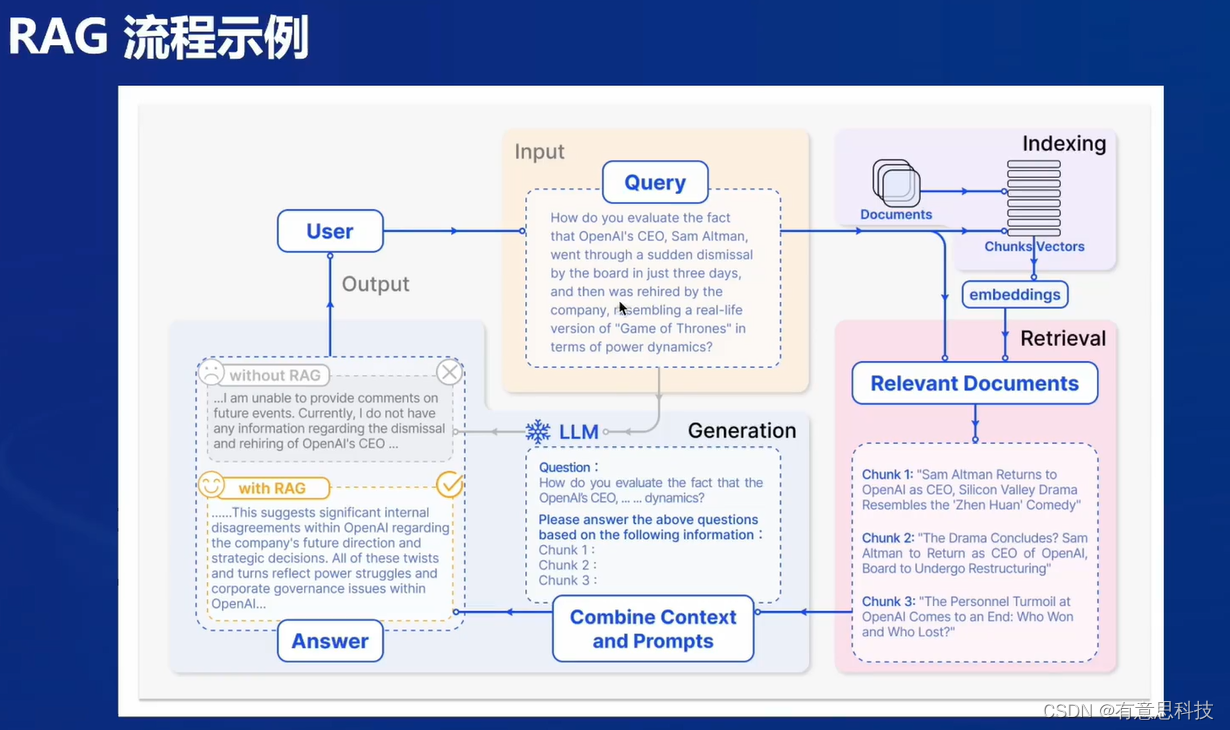
2.RAG工作流程
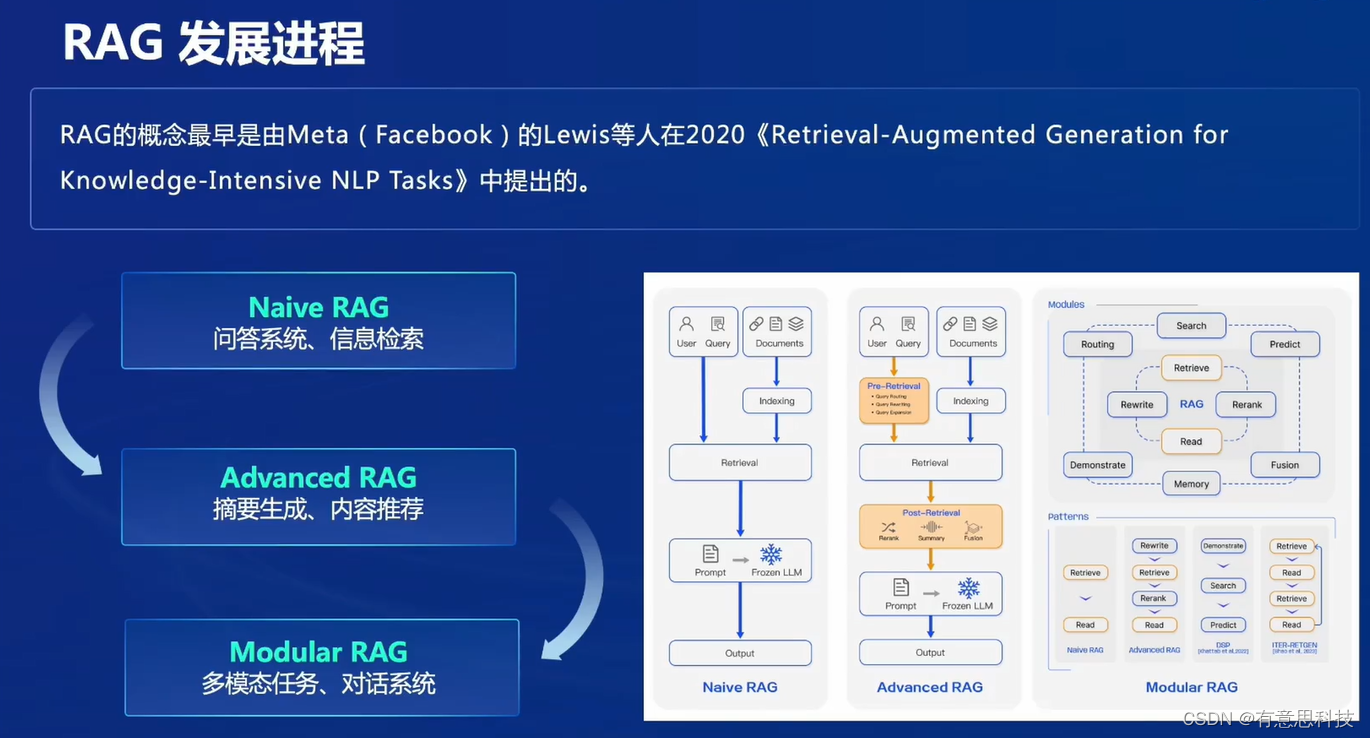
3.RAG发展进程
RAG最早由Meta的Lewis提出,其中有三类RAG,分别是Naive RAG,Advanced RAG, Modular RAG。
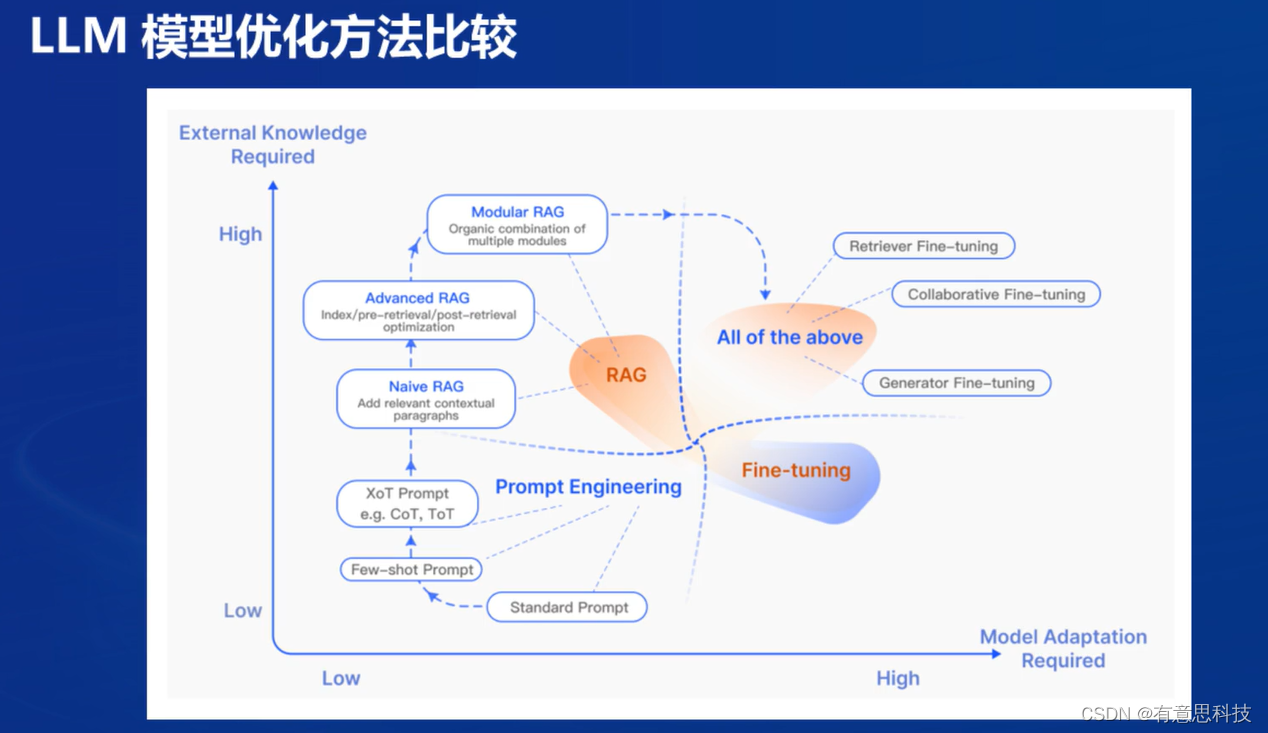
4. RAG常见优化方法
常见的优化方法有嵌入优化,索引优化,查询优化,上下文管理,迭代检索,递归检索,自适应检索,LLM微调等。

5. RAG对比大模型微调
使用的RAG的优势在于可以动态更新知识,处理长尾知识问题,但依赖外部知识库的质量和覆盖范围,依赖大模型能力。
大模型微调的优势可以让模型性能针对特定任务优化,但需要大量的标注主句,且对新任务的适应性较差。

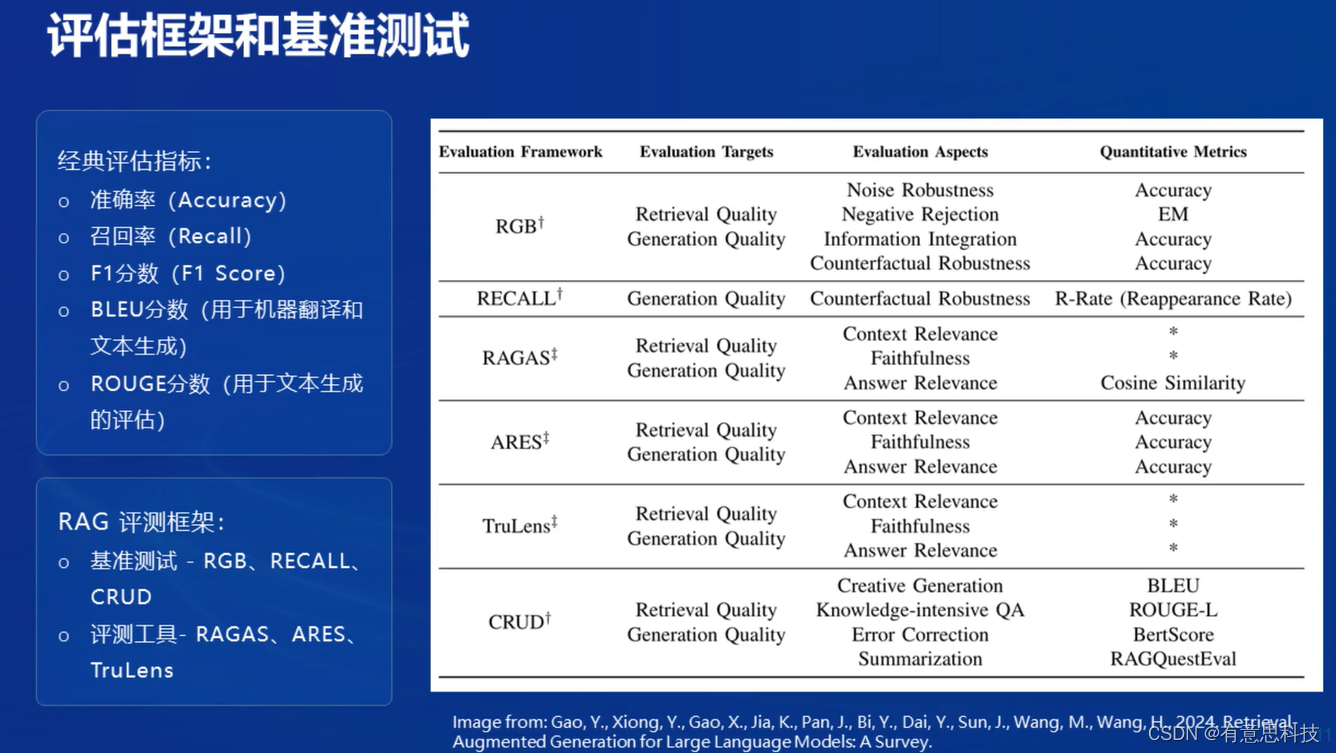
6. 评估框架和基准测试
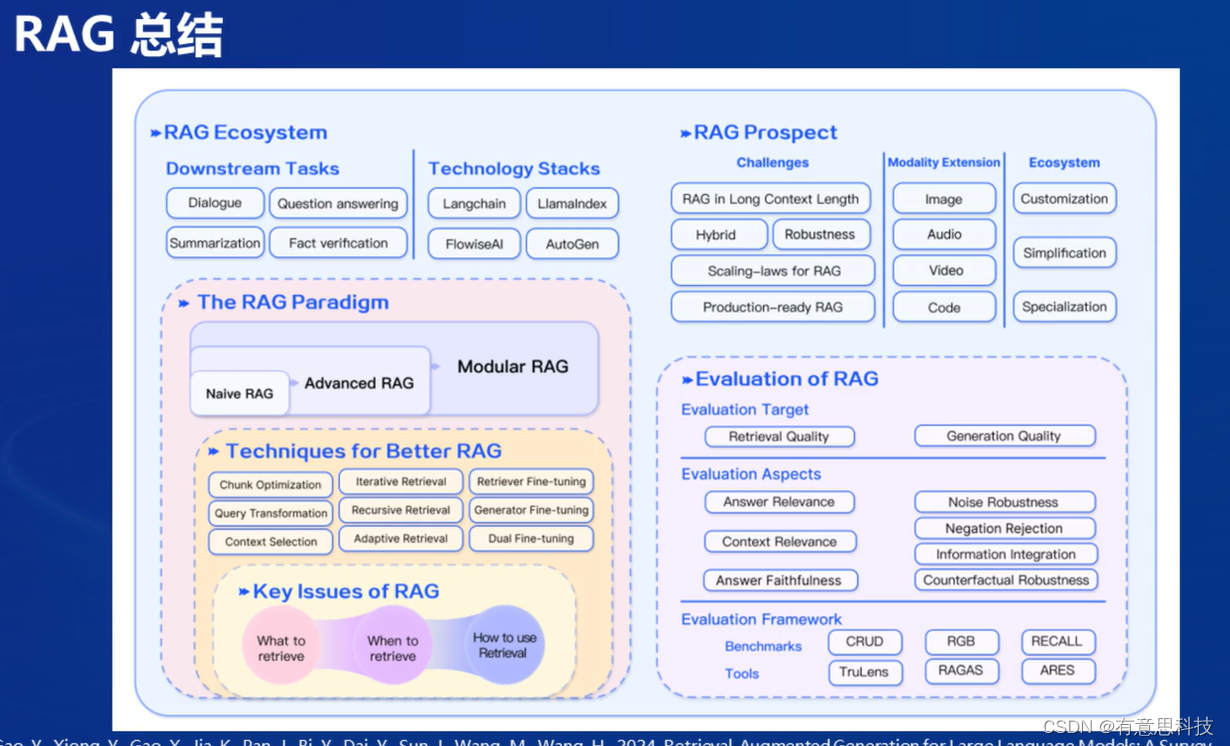
7. RAG总结
二. RAG开源项目 -- 茴香豆
1. 茴香豆介绍
茴香豆是一个基于LLMs的领域知识助手,由书生浦语团队开发的大模型应用。

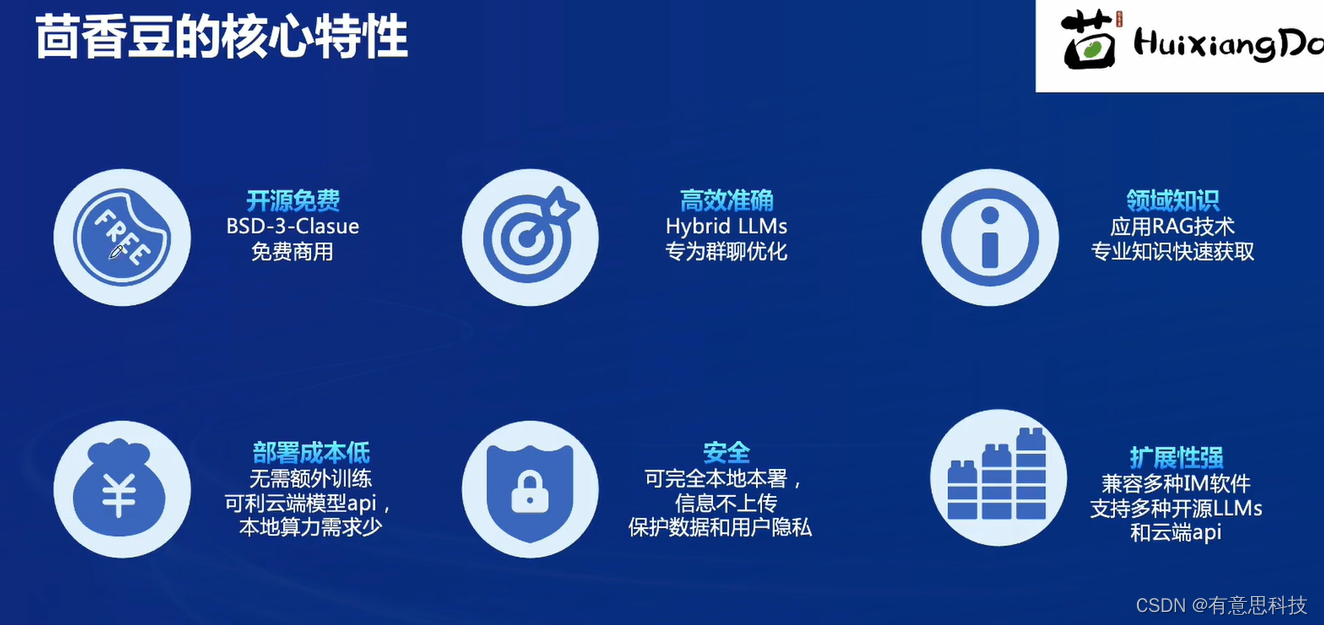
2. 茴香豆的特性
茴香豆具有 免费开源且可商用,高效准确,领域知识,部署成本低,安全,扩展性强等特点。
3. 茴香豆构建
构建一个基于茴香豆的RAG应用,需要前端如微信,飞书;知识库文档;大模型后端(可支持主流大模型远程或本地)

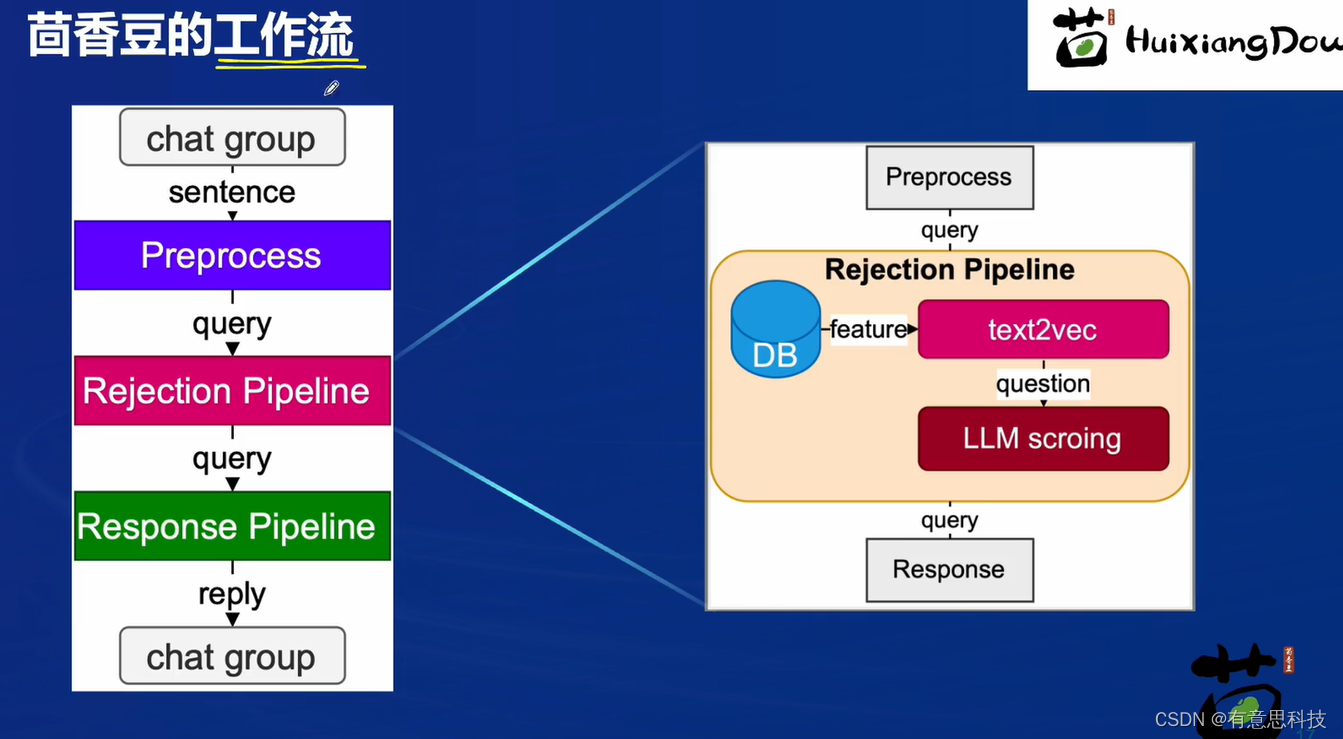
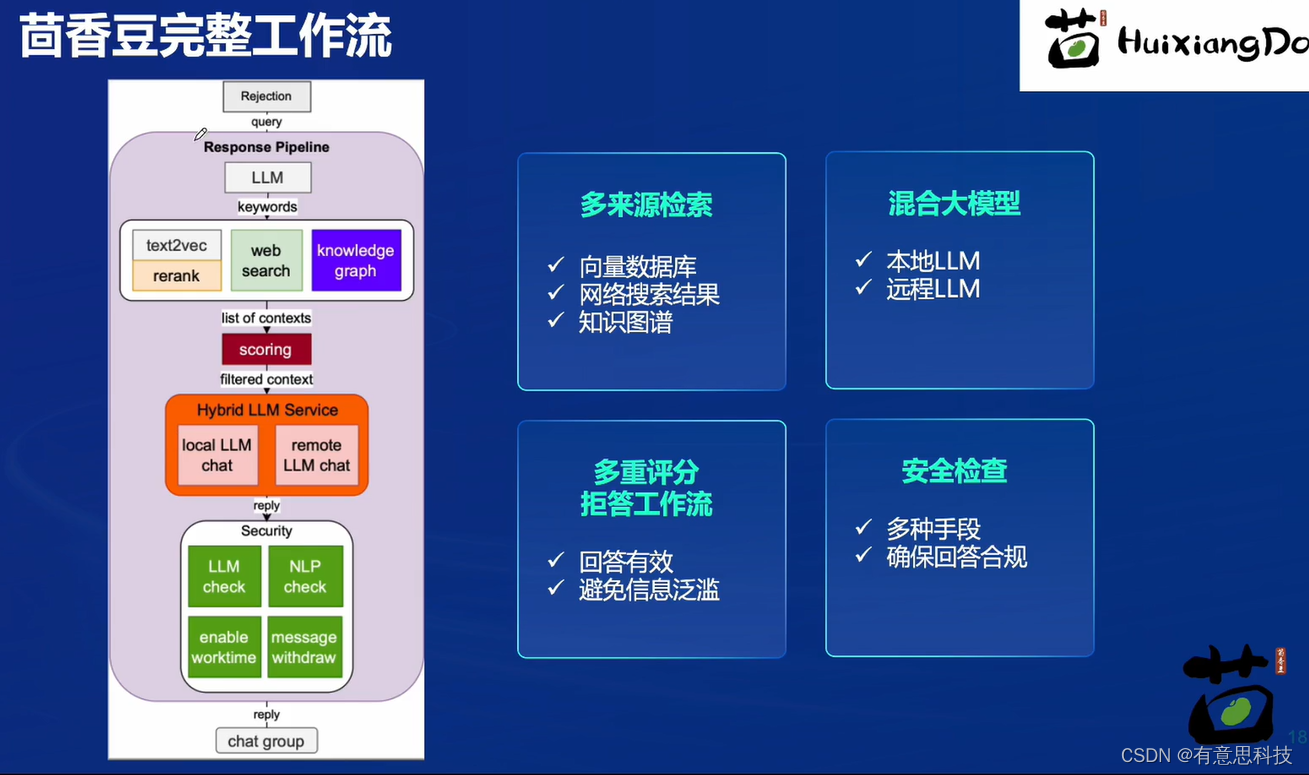
4. 茴香豆工作流
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/513611?site
推荐阅读
相关标签

