
- 1优化GSYVideoPlayer进度条跳动的问题_standardgsyvideoplayer 播放一会后卡顿
- 2FreeSwitch v1(1),开源至上_mac redis make sentinel.c:34:10: fatal error: 'ope
- 3代谢组数据分析六:其他分析
- 4Flask的虚拟环境_flask开发 虚拟环境
- 5ChatGPT 开源替代项目整理_text-generation-webui
- 6数据转换 | Matlab基于GASF格拉姆角和场一维数据转二维图像方法_格拉姆角场转换代码
- 7【计算机毕设文章】基于Spring Boot的美食分享系统设计与实现_i21mn_美食分享系统数据设计
- 8Open-falcon技术实践V1.0_open-falcon官网
- 9【FPGA & Verilog】手把手教你实现一个DDS信号发生器_dds的方波信号
- 10使用机器学习/深度学习进行时间序列预测:第 3 部分基于xgboost时间序列建模以及如何提高模型精度_数据集 标签 滑窗 平滑处理 xgboost
【基于BasicSR的GCFSR复现踩坑】_nameerror: name 'fused_act_ext' is not defined
赞
踩
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除!
前言
超分辨率是指将低分辨率图像通过算法提升其分辨率,使其看起来更加清晰、细腻。在计算机视觉领域,超分辨率技术应用广泛,包括图像处理、视频压缩、安防监控等。
为了进行超分辨率项目开发,需要配置相应的环境。一般来说,超分辨率算法需要依赖于深度学习框架和图像处理库等多个组件。
GCFSR是一种无需GAN先验的生成式超分辨率方法,旨在提高人脸图像的分辨率。该方法采用了Encoder-Generator架构,并设计了样式调制模块和特征调制模块。其中,样式调制模块用于生成逼真的面部细节,特征调制模块用于动态融合多级编码特征和生成特征,进而实现超分辨率。
相较于其他超分辨率方法,GCFSR的一个优点在于无需预训练的GAN模型,以及不需要设计额外的模块来利用GAN先验中的信息。此外,GCFSR还可以实现自适应调整不同强度的样式来生成不同的超分辨率结果,更具有灵活性。
GCFSR的源代码已在Github(GCFSR)上公开发布,并提供了相关论文、项目页面和演示。该方法为人脸超分辨率提供了一种新的思路,也为其他超分辨率领域的研究提供了借鉴和参考。
BasicSR
BasicSR是一款基于PyTorch框架开发的超分辨率(SR)和图像恢复模型库。它提供了大量预训练模型和用于训练新模型的代码和工具,以帮助研究人员和工程师高效地进行SR和图像恢复任务的研究和应用。
basicSR的优点包括:
多种超分辨率和图像恢复算法:basicSR支持多种流行的SR算法,如SRCNN、ESPCN、EDSR等,还提供了多种其他的图像恢复算法,例如去噪、去卷积等。
可扩展性:基于PyTorch框架的设计使得basicSR可以方便地进行扩展和自定义,用户可以按需添加自己的算法或改进现有算法。
高效性:basicSR实现了诸多加速技术,如混合精度训练、异步数据加载等,以在保持高精度的同时提高训练和推理效率。
丰富的文档和教程:在GitHub上,basicSR提供了详尽的文档和使用教程,指导用户如何使用库中的不同算法和API,并以图像超分辨率为例介绍了其基本原理和应用。

快速开始
Pytorch与cuda
查看cuda版本
查看自身的cuda版本,很重要,否则算力框架不匹配:
nvcc --versionnvcc -V
或者利用torch查看
import torch
print(torch.__version__) # 查看torch当前版本号
print(torch.version.cuda) # 编译当前版本的torch使用的cuda版本号
print(torch.cuda.is_available()) # 查看当前cuda是否可用于当前版本的Torch
- 1
- 2
- 3
- 4
还不会的参考这里 这个比较详细,应该可以帮到你。
安装对应的Pytorch
建议去查询与之对应的pytorch版本:torch与cuda版本匹配网址
这里以10.2为例,选择其中cudatoolkit=10.2即可。千万别就看requirement中的torch版本,单独pip或者conda install torch==xxx,容易出现cudatoolkit与cuda不匹配的情况。
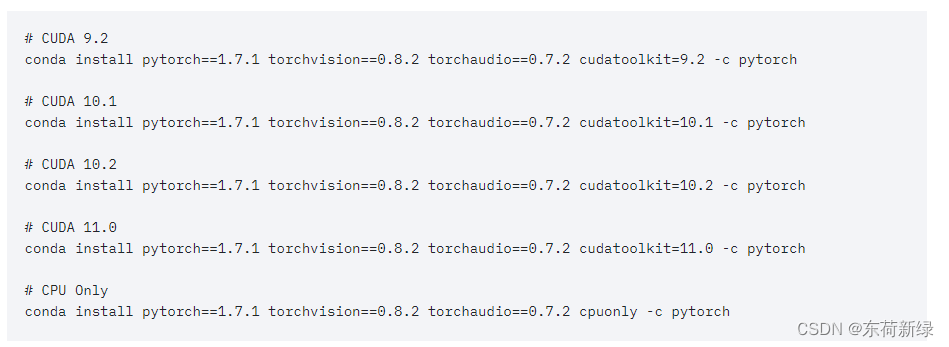
运行其中的命令就等着ok就好了。
GCFSR的项目配置
哟,看着readme.md还简单,照着步骤走就行了。let us go!
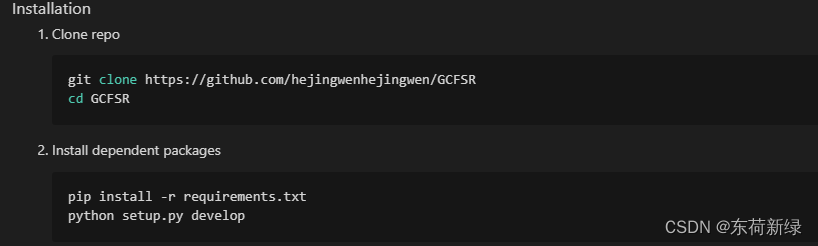
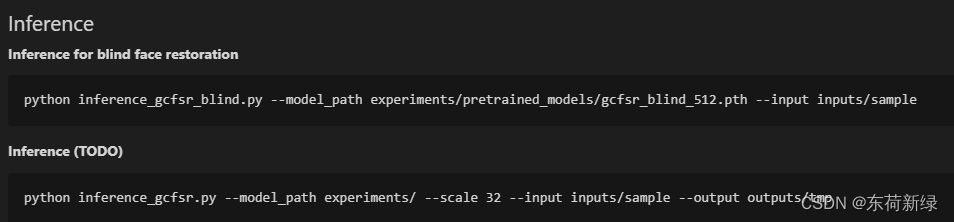
无法推理只能倒回去看过程:
按照以上步骤是半可行的:
- 首先:有git就克隆,没有就下载压缩包。
注意:如果自行安装了torch就把requirement的中的torch去掉,避免版本变更。 - 编译:setup编译呗。
- 推理:如果说cuda,kernel,或者sm_86之列的计算框架问题,恭喜你,torch和cuda版本不一致,考虑计算框架的能力。即如cuda和gpu矛盾,如A5000系列显卡就是sm_86.
sm_xx代表NVIDIA GPU架构的编译选项,其中xx为两位数字。通常情况下,sm_xx与PyTorch版本之间并没有明确的匹配关系,而是与CUDA版本和GPU架构有关。一般来说,PyTorch版本需要与CUDA版本匹配,而CUDA版本需要与GPU架构匹配。需要注意的是,不同的GPU架构支持的CUDA版本可能存在差异,因此在选择GPU、CUDA和PyTorch版本时需要仔细考虑。如果您遇到了版本兼容性问题,可以尝试升级或降级相关的软件包
此时,参考上述安装对应的cuda版本有可能解决问题。
训练命令
python basicsr/train.py -opt options/train_gcfsr_gan.yml
- 1

- root_path: 可自己指定项目路径。
获取训练可选的参数,使用参数-h:
python basicsr/train.py -opt options/train_gcfsr_gan.yml -h
- 1
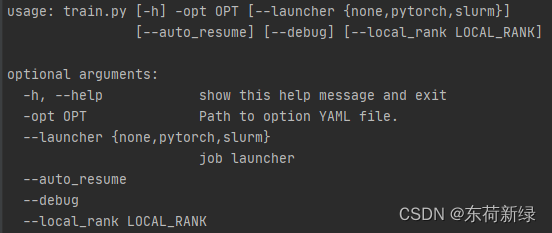
- –opt:配置文件路径
- –launcher:分布式训练,用于指定 distibuted training的,比如 pytorch或者slurm。单卡训练不用设置。
- –auto_resume:是否自动继续训练。即自动查找最近的权重,然后加载权重进行训练。程序中断或者继续训练,可在命令行中添加这个参数。
- –debug:用于调试,确保能正常的前向传播、反向,日志和权重保存等没有问题,及时发现问题进行修改。
- –local_rank:不用管,是distributed training中程序自动会传入。
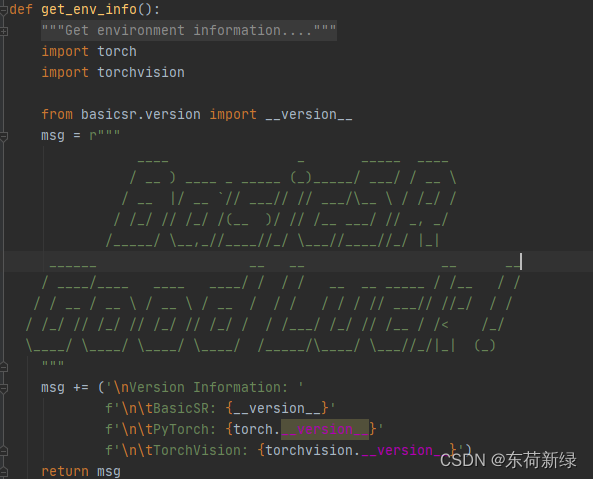
Train_pipeline 函数
主要的函数,参考图中注释。主要包括了解析配置文件,断点训练,日志系统、tensorboard、以及创建模型进行训练。
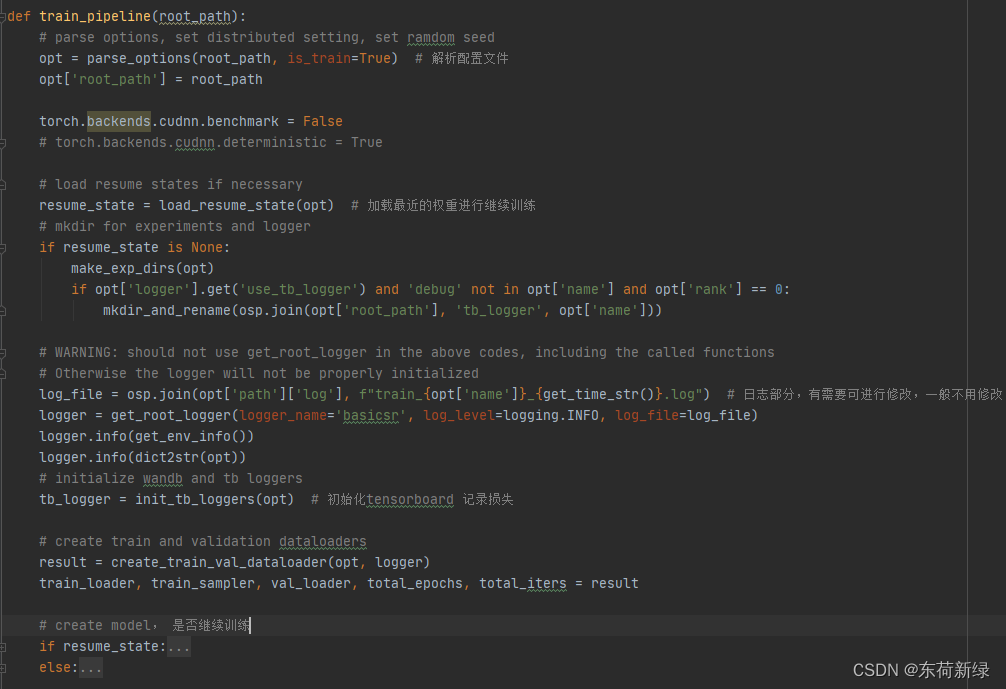
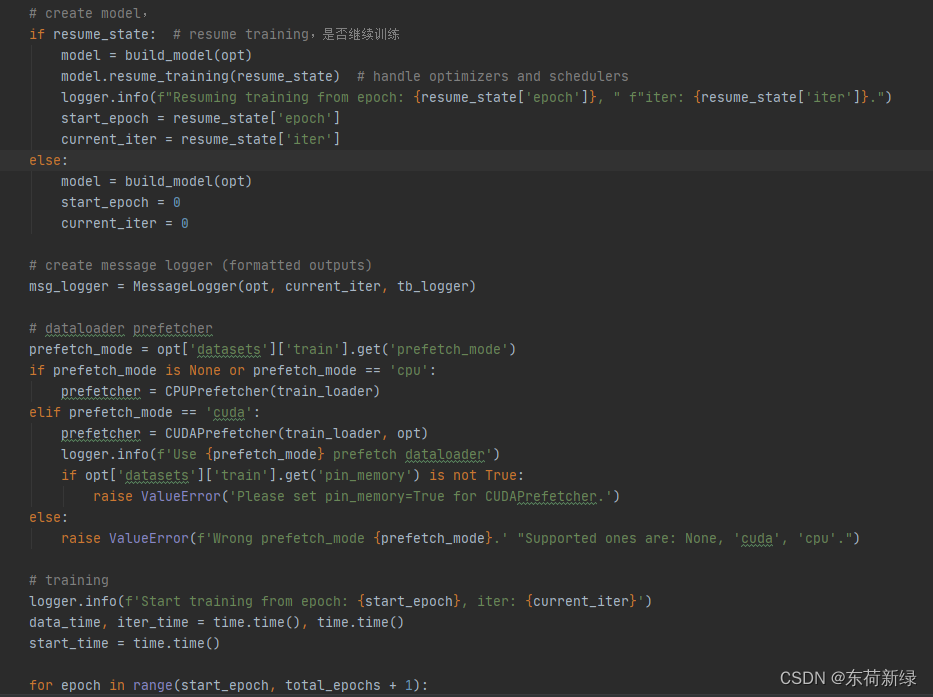
参数解析
这部分和使用-h是差不多的。
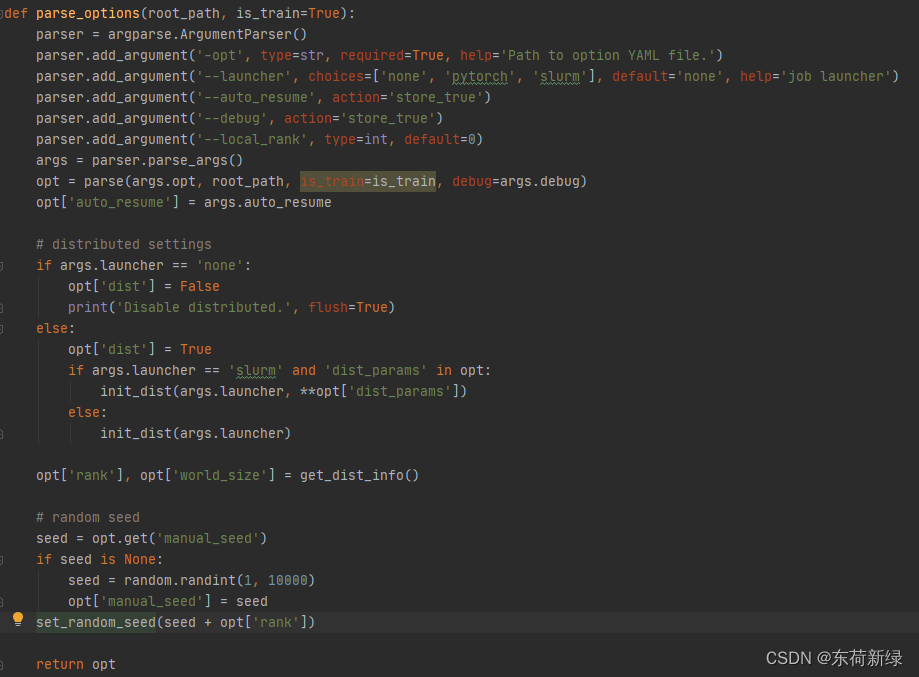
Resume
主要使用到配置文件中:auto_resume 选项。
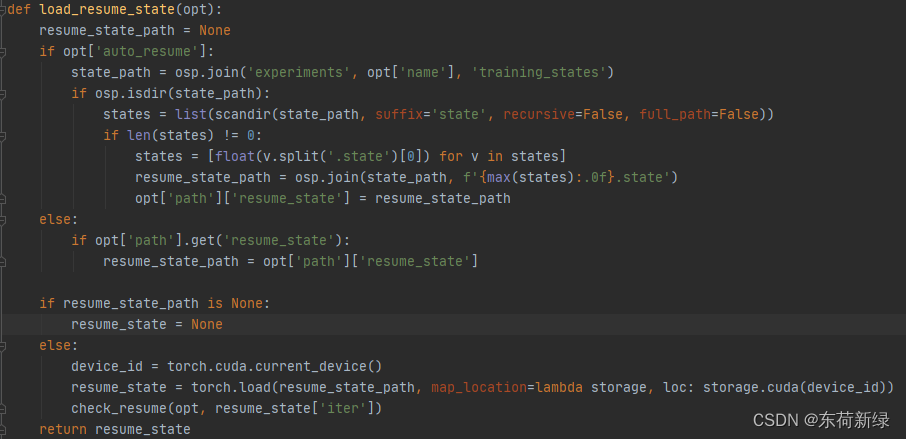
Logger
主要进行写日志以及保存。

Good Luck logo
如果对这个BasicSR有想法,可以自己改哈。
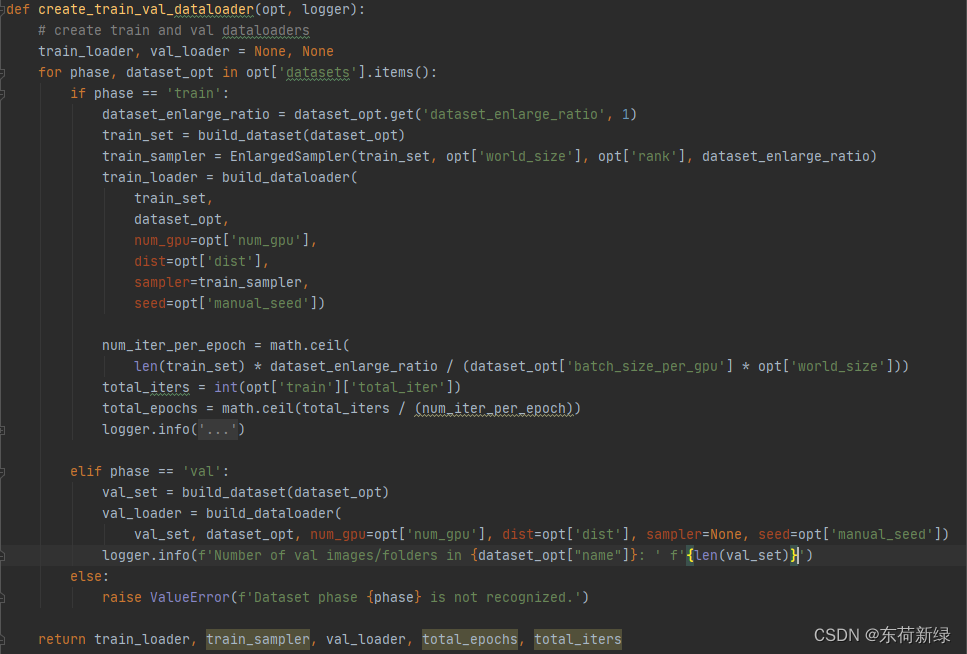
Dataloader
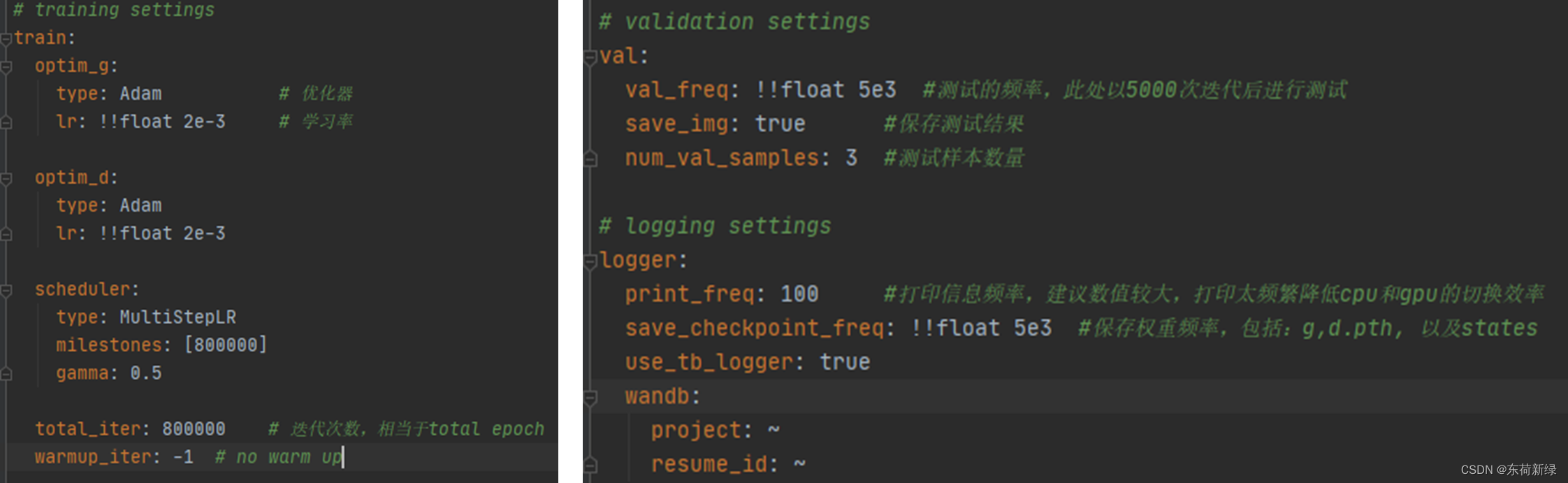
主要使用到配置文件中:datasets、dataset_enlarge_ratio、batch_size_per_gpu、total_iter、num_gpu等选项。
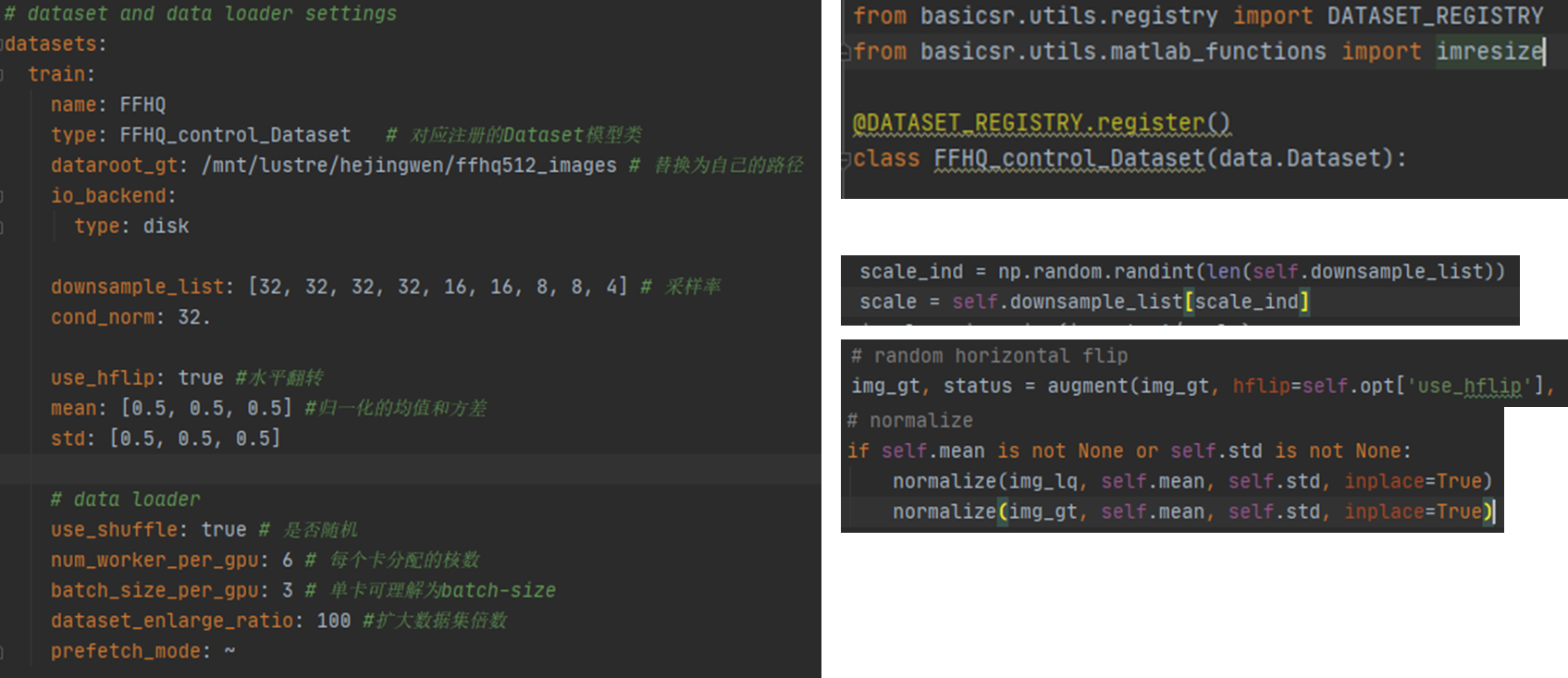
配置文件详解
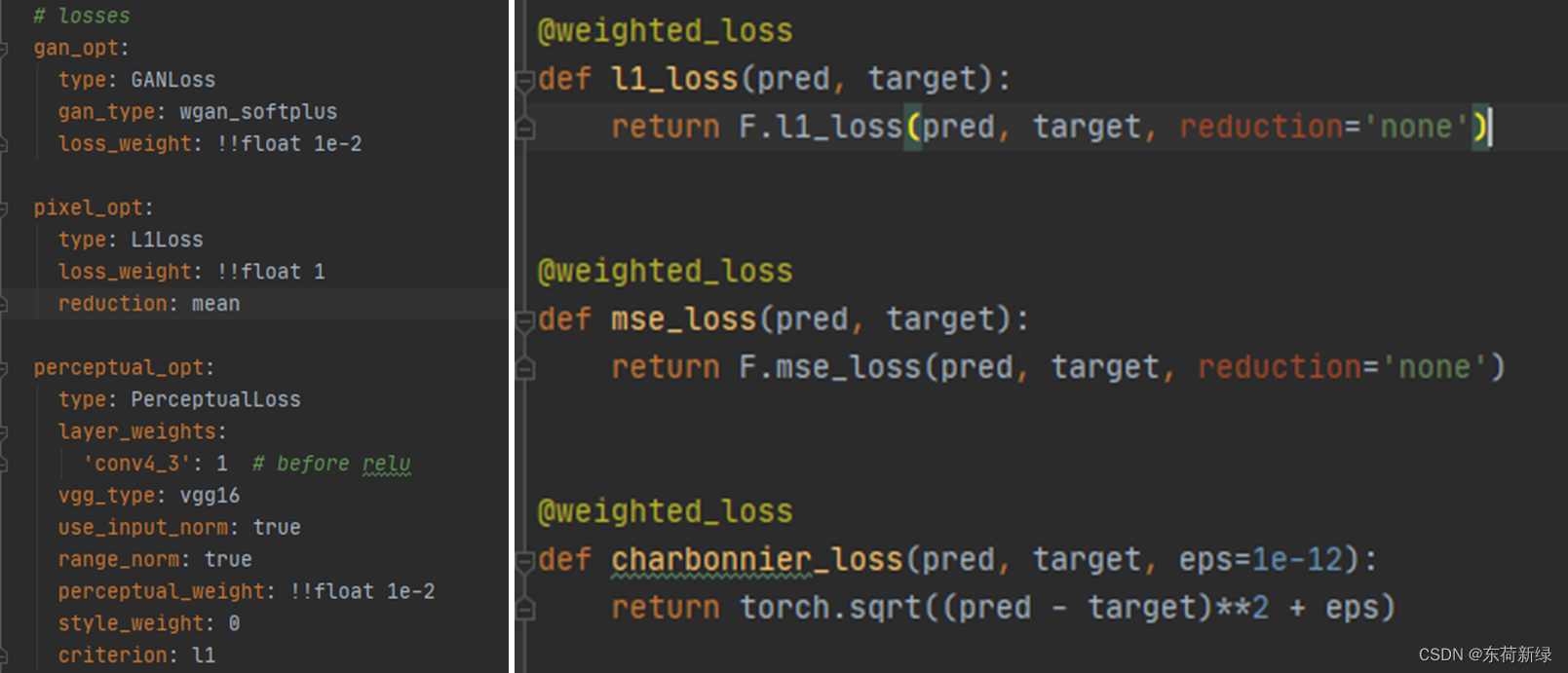
左侧为配置文件,右侧为注册的对应名字类,主要是想说明配置文件要和使用的类名对应。配置的解释,见绿色注释。

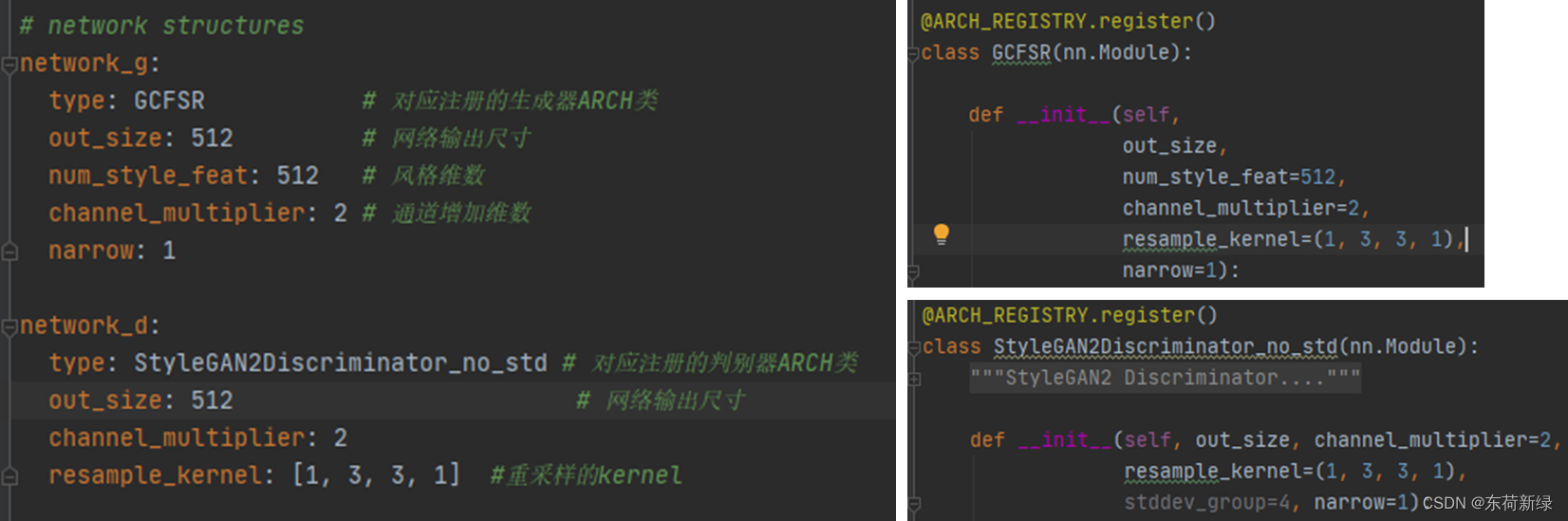
损失函数可替换为右侧文件中的其他损失。
动态实例化与REGISTER注册机制
膜拜Xintao大佬,有所参考,宣传BasicSR。
动态实例化
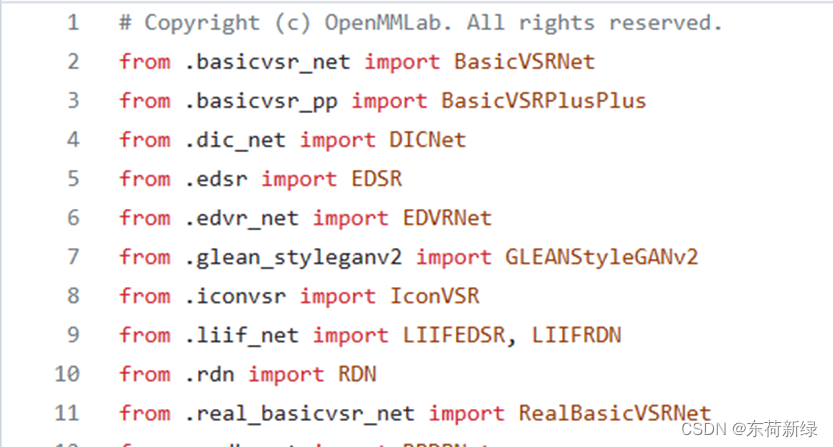
传统的OpenMMlab,需要__init__.py 中把写好的网络结构显式地import进来。每写一个新的网络结构,就要去更新 init.py,很繁琐。
因此在 BasicSR,约定凡是网络结构的文件都以 _arch.py 结尾,模型都以以_model.py结尾,数据集以 _dataset.py结尾,然后python在import的时候,会自动扫描以 _arch.py、 _model.py结尾的脚本,自动把所有的符合命名的类都import进去。
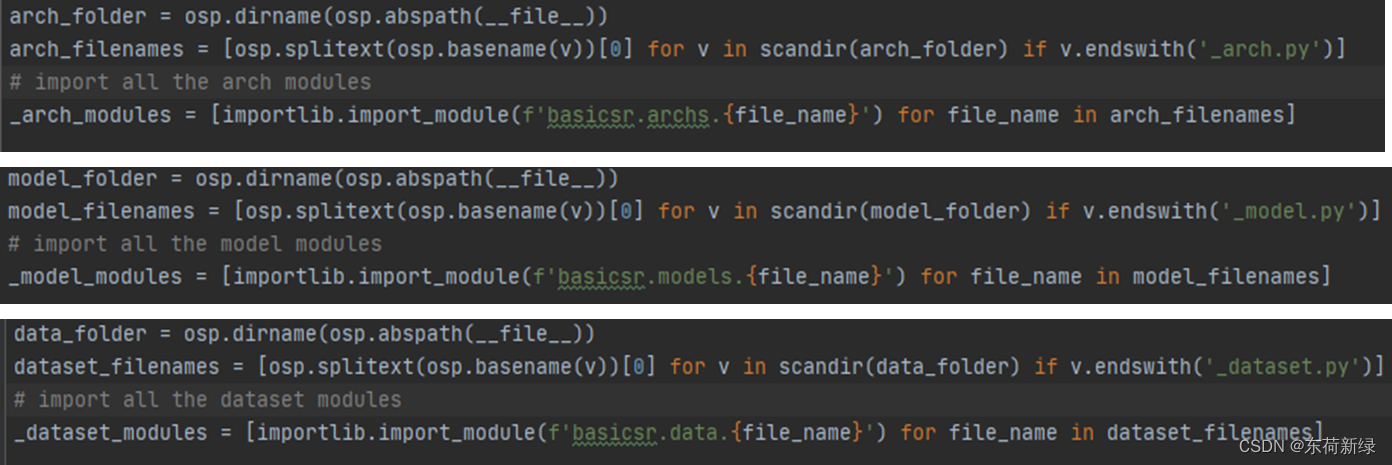
这样一来,写网络结构本身、模型和修改配置文件,就改动三个文件就ok了,也就是下文的三步走。
注册机制
动态实例化存在问题:
- 类重名会导致加载错误
- Init会把所有的类、函数都import进来,这是冗余的,因为很多类和函数都是中间的量
注册以解决上述问题:
- 会强制检查有没有同名的,减少了bug。
- 只有在需要注册的类或函数 register,其他中间量就不会被注册了。
注册借助于下面两个函数:
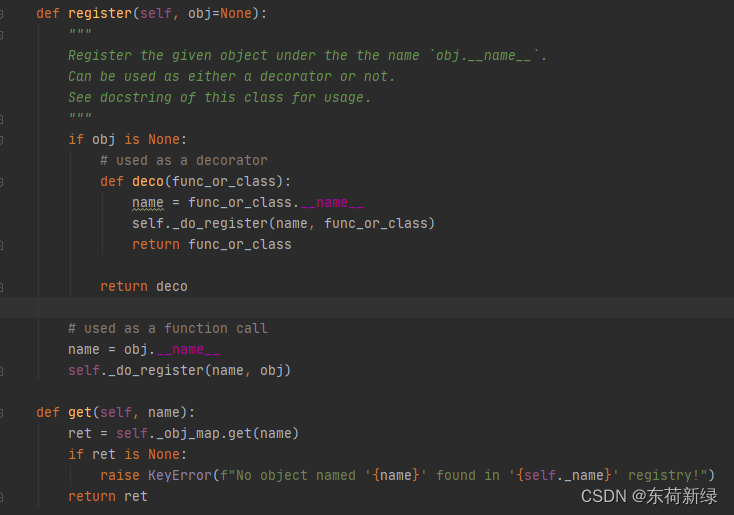
模型修改(三步走)
第一步:修改网络结构
此处简单的示意了修改通道,具体修改还看自己的想法。
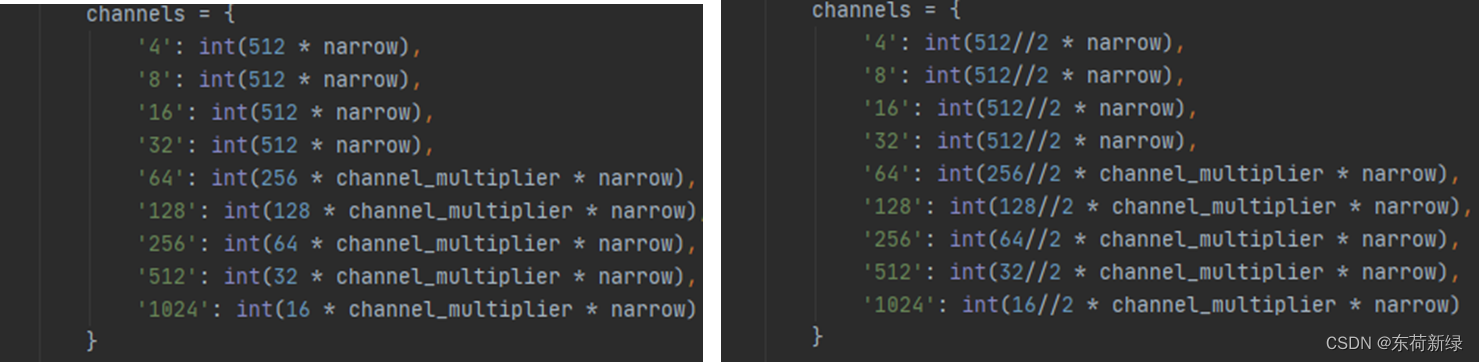
需要修改其中的通道。
self.final_linear = EqualLinear(参数要改)
- 1
第二步:修改配置文件
此处示意了修改了退化的类型,需要因地制宜。

第三步:修改模型文件
此处简单示意了修改保存内容和非分布式验证方式。
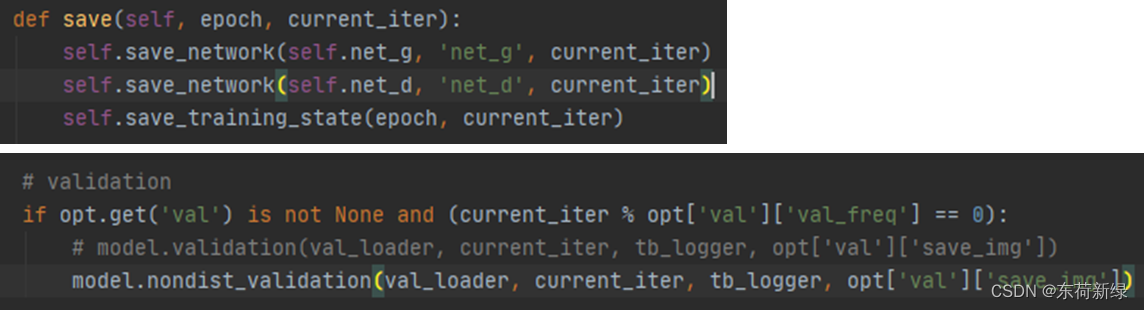
基本上根据这三步走,只要能正确修改,就可以开始玄学炼丹了。
GCFSR踩坑及解决
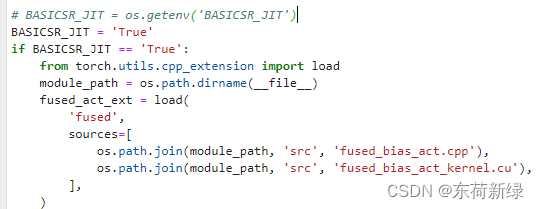
NameError: name ‘fused_act_ext’ is not defined
- 有解决办法说下面这个,测试没有用,大哭
pip3 install ninja
- 1
- 到
basicsr\ops\fused_act\fused_act.py修改下列第一个语句为Ture
参考: python 学习笔记18 GFPGAN人脸(图片)修复

- 再次运行:NameError: name ‘upfirdn2d_ext’ is not defined
解决:到\basicsr\ops\upfirdn2d\upfirdn2d.py修改下列第一个语句为Ture
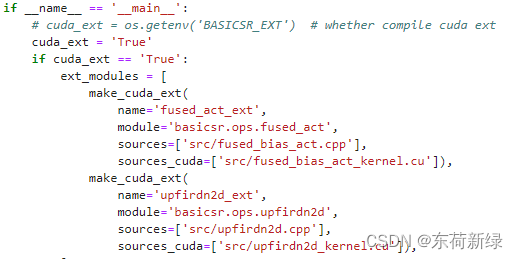
最后推理主程序,也设置为ture就欧克了。
特征图尺寸小于卷积核
train_pipeline(root_path)
File "basicsr/train.py", line 173, in train_pipeline
model.optimize_parameters(current_iter)
File "/home/tang/work/QXD/GCFSR/basicsr/models/model.py", line 222, in optimize_parameters
fake_pred = self.net_d(fake_img.detach())
File "/home/tang/work/Anaconda/env/sr-gan/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/home/tang/work/QXD/GCFSR/basicsr/archs/arch.py", line 1006, in forward
out = self.conv_body(x)
RuntimeError: Calculated padded input size per channel: (2 x 2). Kernel size: (3 x 3). Kernel size can't be greater than actual input size
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
一看就是特征图小了,直接定位到下面的代码,为什么?因为to_rgb()设置了upsample=True是会上采样的,但是输出还是16x16,显然没有进入该循环。
for conv1, conv2, noise1, noise2, to_rgb in zip(self.style_convs[::2], self.style_convs[1::2], noise[1::2], noise[2::2], self.to_rgbs):
out = conv1(out, latent[:, i], noise=noise1)
out = conv2(out, latent[:, i + 1], noise=noise2)
skip = to_rgb(out, latent[:, i + 2], skip)
- 1
- 2
- 3
- 4
- 5
self.to_rgbs.append(ToRGB(out_channels, num_style_feat, upsample=True, resample_kernel=resample_kernel))
- 1
分析原因,zip函数能够把多个可迭代对象打包成一个元组构成的可迭代对象,但是却取决于其中最短的迭代对象,发现noise长度是0,因此不会进循环。解决办法就是把noise去掉。
for conv1, conv2, to_rgb in zip(self.style_convs[::2], self.style_convs[1::2], self.to_rgbs):
out = conv1(out, latent[:, i], noise=None)
out = conv2(out, latent[:, i + 1], noise=None, scale1=scales1[j], scale2=scales2[j], shift=shifts[j])
skip = to_rgb(out, latent[:, i + 2], skip)
- 1
- 2
- 3
- 4
或者另外的途径:
由下列图像发现,noise是none是会生成层数相等的none的列表,是可以实现进入循环的。

进一步,发现实际输入的noise是来之数据加载中的in_size,因此直接在数据处理后不返回in_size也可以实现相同的效果。
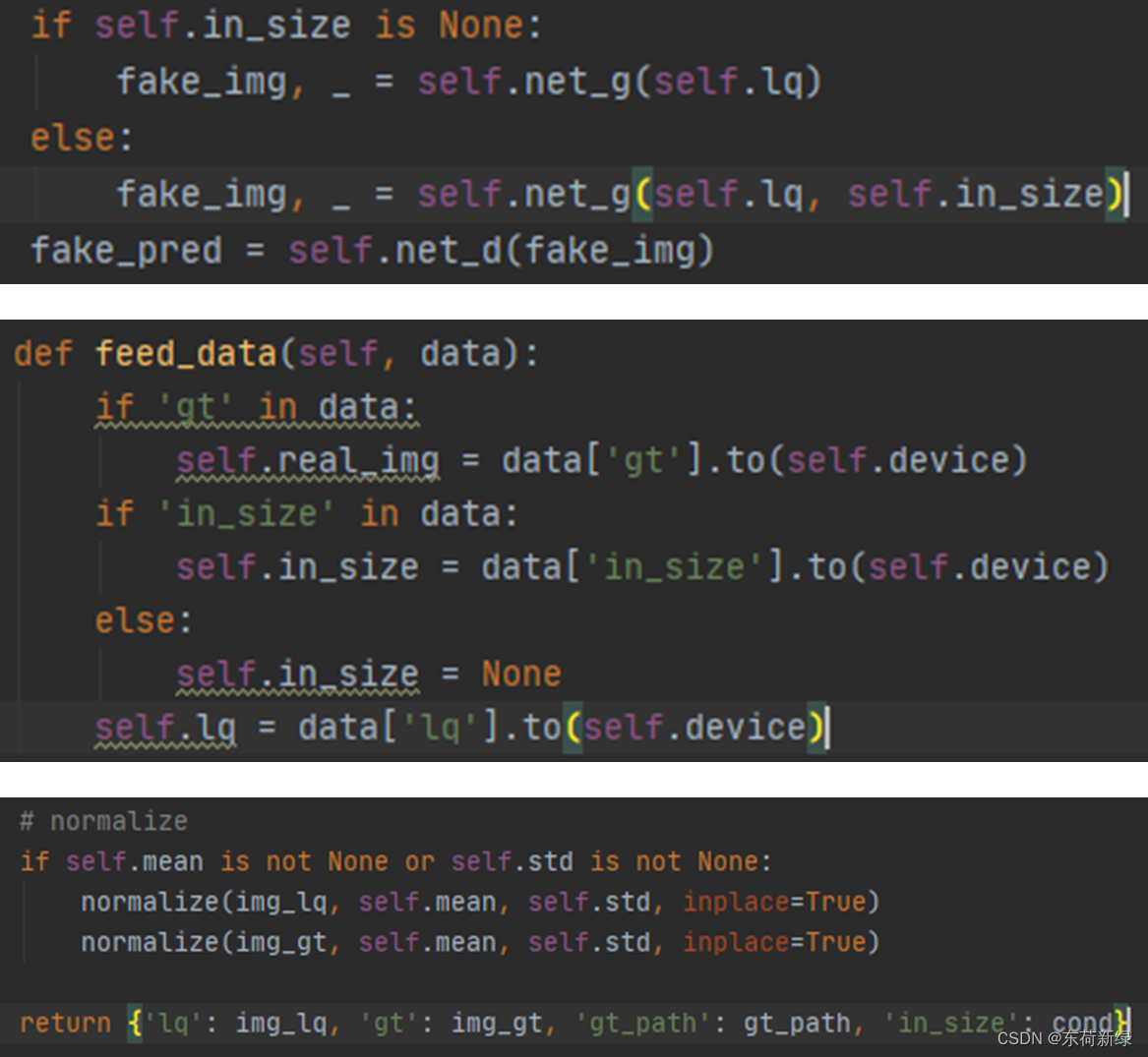
但是在val阶段会导致生成的图像尺寸还是16x16,在不使用val是可以这么做的,具体原因留给后面。
无法加载自己训练的权重
三步走后,顺顺利利的训练和保存了权重,本就打算测试下效果,没曾想加载不了,就是下图的错。
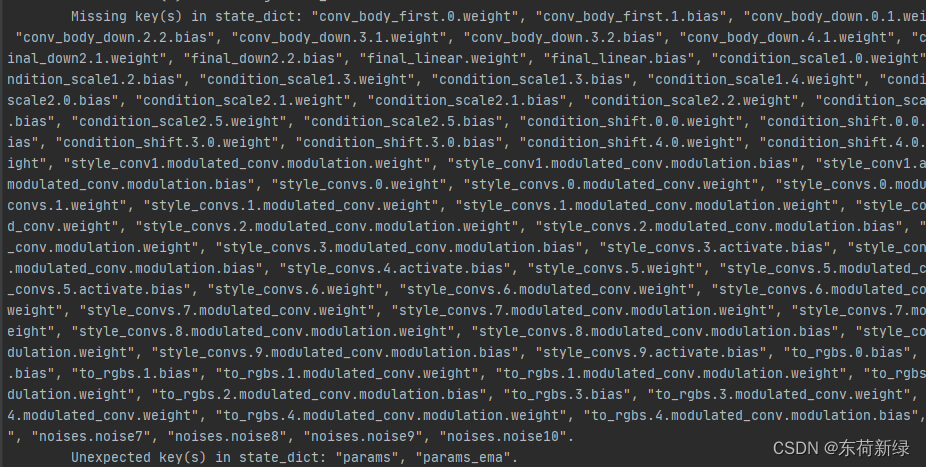
不仅不能加载,还多了给ema的键,没办法,打印下看看有些什么键值对。
net = torch.load(args.model_path)
for k in net.keys():
print(k)
#'params', 'params_ema'
- 1
- 2
- 3
- 4
确实,由参数和ema,因此只需要加载参数即可,像下面一样。
model.load_state_dict(torch.load(args.model_path, map_location=device)['params'], strict=True)
- 1
这样了不得不看下怎么保存的权重,果然是保存的问题,保存的不仅仅是网络参数还有ema的参数。

简单百度下:EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。大概是为了断点训练把,不保存ema也能加载,影响的是ema的效果。
恢复效果
这是GCFSR的效果,不是自己跑出来的,效果还不错。

复现代码平台推荐
对于自己的数据集,无法直接引用别人论文结果,需要自己复现进行比较,极力推荐AutoDL,一个小时几毛,很良心。
致谢
欲尽善本文,因所视短浅,怎奈所书皆是瞽言蒭议。行文至此,诚向予助与余者致以谢意。

