
- 1深度神经网络 (第 IV 部)。创建, 训练和测试神经网络模型_神经网络模型如何测试
- 2远程办公并不难 cpolar轻松实现
- 3【linux】云服务器挂载数据盘_linux 挂载 腾讯云存储桶
- 4uniapp中的uni-file-picker组件上传多张图片到服务器,可添加,预览,删除图片_uni-file-picker详细使用教学
- 5【UTMB】My UTMB Account 注册步骤 | UTMB注册个人账户
- 6SpringBoot中的WebSocket搭建详解 通俗易懂_springboot搭建websocket
- 7新的地址http://www.civilianshop.com/blog/_最新发布网址
- 8Origin绘制上面和右边边框_origin右上角那个框框叫什么
- 9福利吧简约朴素网站地址发布页源码_fuliba
- 10Linux下基本指令_linux下的基本指令
视觉slam学习|基础篇02_slam建模摄像头技术
赞
踩
系列文章目录
计算机视觉基础
SLAM中使用的相机与我们平时见到的单反摄像头并不是同一个东西。它往往更加简单,不携带昂贵的镜头,以一定速率拍摄周围的环境,形成一个连续的视频流。普通的摄像头能以每秒钟 30 张图片的速度采集图像,高速相机则更快一些。按照相机的工作方式,我们把相机分为单目(Monocular)、双目(Stereo)和深度相机(RGB-D)三个大类:
- 单目相机 只使用一个摄像头进行 SLAM 的做法称为单目 SLAM(Monocular SLAM)。这种传感器结构特别的简单、成本特别的低,所以单目 SLAM 非常受研究者关注。平移之后才能计算深度,以及无法确定真实尺度,这两件事情给单目 SLAM 的应用造成了很大的麻烦。它们的本质原因是通过单张图像无法确定深度。
- 双目相机 (Stereo) 双目相机和深度相机的目的,在于通过某种手段测量物体离我们的距离,克服单目无法知道距离的缺点。如果知道了距离,场景的三维结构就可以通过单个图像恢复出来,也就消除了尺度不确定性。双目相机由两个单目相机组成,但这两个相机之间的距离(称为基线(Baseline))是已知的。我们通过这个基线来估计每个像素的空间位置——这和人眼非常相似。双目或多目相机的缺点是配置与标定均较为复杂,其深度量程和精度受双目的基线与分辨率限制,而且视差的计算非常消耗计算资源,需要使用 GPU 和 FPGA 设备加速后,才能实时输出整张图像的距离信息。因此在现有的条件下,计算量是双目的主要问题之一。
- 深度相机 深度相机(又称 RGB-D 相机)是 2010 年左
右开始兴起的一种相机,它最大的特点是可以通过红外结构光或 Time-of-Flight(ToF)原理,像激光传感器那样,通过主动向物体发射光并接收返回的光,测出物体离相机的距离。目前常用的 RGB-D 相机包括 Kinect/Kinect V2、Xtion live pro、Realsense 等。不过,现在多数 RGB-D 相机还存在测量范围窄、噪声大、视野小、易受日光干扰、无法测量透射材质等诸多问题,在 SLAM 方面,主要用于室内 SLAM,室外则较难应用。
相机模型
相机的成像原理可以简单的看成针孔模型(小孔成像)+镜头畸变两个部分。
像素坐标
针孔模型就是我们初中学的小孔成像。
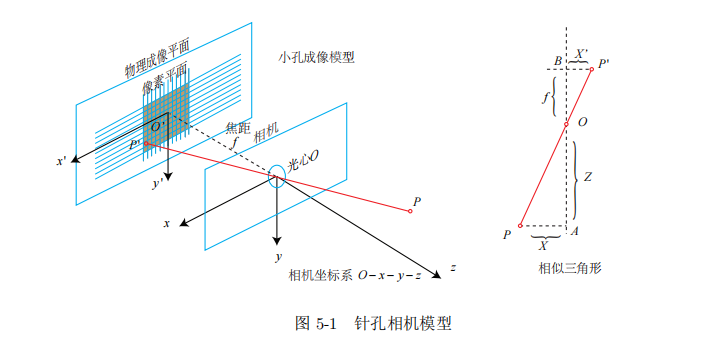
现在来对这个简单的针孔模型进行几何建模。设 O − x − y − z 为相机坐标系,习惯上我们让 z 轴指向相机前方,x 向右,y 向下。O 为摄像机的光心,也是针孔模型中的针孔。现实世界的空间点 P,经过小孔 O 投影之后,落在物理成像平面 O′ − x′ − y′ 上,成像点为 P′。设 P 的坐标为 [X, Y, Z]T,P′ 为 [X′, Y ′, Z′]T,并且设物理成像平面到小孔的距离为 f(焦距)。为了简化模型,我们把可以成像平面对称到相机前方,和三维空间点一起放在摄像机坐标系的同一侧,如下图所示:
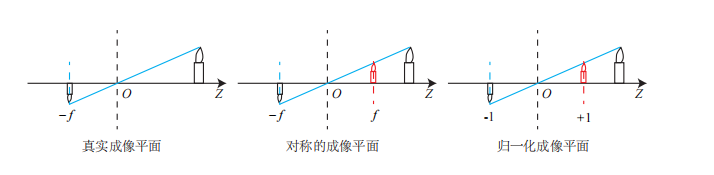
得到:
X
′
=
f
X
Z
Y
′
=
f
Y
Z
X′=fXZY′=fYZ
上式描述了点 P 和它的像之间的空间关系。不过,在相机中,我们最终获得的是一个个的像素,这需要在成像平面上对像进行采样和量化。为了描述传感器将感受到的光线转换成图像像素的过程,我们设在物理成像平面上固定着一个像素平面 o − u − v。我们在像素平面得到了 P′ 的像素坐标:[u, v]T。
像素坐标系通常的定义方式是:原点
o
′
o^{\prime}
o′ 位于图像的左上角,
u
u
u 轴向右与
x
x
x 轴平行,
v
v
v 轴向下与
y
y
y 轴平行。像素坐标系与成像平面之间, 相差了一个缩放和一个原点的平移。我 们设像素坐标在
u
u
u 轴上缩放了
α
\alpha
α 倍, 在
v
v
v 上缩放了
β
\beta
β 倍。同时, 原点平移了
[
c
x
,
c
y
]
T
\left[c_{x}, c_{y}\right]^{T}
[cx,cy]T 。那 么,
P
′
P^{\prime}
P′ 的坐标与像素坐标
[
u
,
v
]
T
[u, v]^{T}
[u,v]T 的关系为:
{
u
=
α
X
′
+
c
x
v
=
β
Y
′
+
c
y
.
\left\{u=αX′+cxv=βY′+cy
合并上面两个式子并把
α
f
\alpha f
αf 合并成
f
x
f_{x}
fx, 把
β
f
\beta f
βf 合并成
f
y
f_{y}
fy, 得:
{
u
=
f
x
X
Z
+
c
x
v
=
f
y
Y
Z
+
c
y
.
\left\{u=fxXZ+cxv=fyYZ+cy
其中,
f
f
f 的单位为米,
α
,
β
\alpha, \beta
α,β 的单位为像素每米, 所以
f
x
,
f
y
f_{x}, f_{y}
fx,fy 的单位为像素。把该式写 成矩阵形式, 会更加简洁, 不过左侧需要用到齐次坐标:
(
u
v
1
)
=
1
Z
(
f
x
0
c
x
0
f
y
c
y
0
0
1
)
(
X
Y
Z
)
≜
1
Z
K
P
.
\left(uv1
我们按照传统的习惯,把
Z
Z
Z 挪到左侧:
Z
(
u
v
1
)
=
(
f
x
0
c
x
0
f
y
c
y
0
0
1
)
(
X
Y
Z
)
≜
K
P
Z\left(uv1
这里我们K成为相机的内参数矩阵,在出厂之后就是固定的。P则是外参,表示点P在相机坐标系下的坐标也可记作
P
w
P_w
Pw
归一化坐标
根据相机的当前位姿,变换到相机坐标系下的结果。相机的位姿由它的旋转矩阵 R 和平移向量 t 来描述。那么有:
Z
P
u
v
=
Z
[
u
v
1
]
=
K
(
R
P
w
+
t
)
=
K
T
P
w
Z \boldsymbol{P}_{u v}=Z\left[uv1
可以看到, 右侧的
T
P
w
T P_{w}
TPw 表示把一 个世界坐标系下的齐次坐标, 变换到相机坐标系下。为了使它与
K
K
K 相乘, 需要取它的前 三维组成向量一一因为
T
P
w
T P_{w}
TPw 最后一维为 1 。此时, 对于这个三维向量, 我们还可以按照齐 次坐标的方式, 把最后一维进行归一化处理, 得到了
P
P
P 在相机归一化平面上的投影:
P
~
c
=
[
X
Y
Z
]
=
(
T
P
w
)
(
1
:
3
)
,
P
c
=
[
X
/
Z
Y
/
Z
1
]
.
\tilde{\boldsymbol{P}}_{c}=\left[XYZ
这时
P
c
\boldsymbol{P}_{c}
Pc 可以看成一个二维的齐次坐标, 称为归一化坐标。它位于相机前方
z
=
1
z=1
z=1 处 的平面上。该平面称为归一化平面。由于
P
c
P_{c}
Pc 经过内参之后就得到了像素坐标, 所以我们 可以把像素坐标
[
u
,
v
]
T
[u, v]^{T}
[u,v]T, 看成对归一化平面上的点进行量化测量的结果。
畸变
为了获得好的成像效果,我们在相机的前方加了透镜。透镜的加入对成像过程中光线的传播会产生新的影响: 一是透镜自身的形状对光线传播的影响,二是在机械组装过程中,透镜和成像平面不可能完全平行,这也会使得光线穿过透镜投影到成像面时的位置发生变化。
畸变可以分为径向畸变和切向畸变。径向畸变可以用和距中
心距离有关的二次及高次多项式函数进行纠正:
x
corrected
=
x
(
1
+
k
1
r
2
+
k
2
r
4
+
k
3
r
6
)
y
corrected
=
y
(
1
+
k
1
r
2
+
k
2
r
4
+
k
3
r
6
)
xcorrected =x(1+k1r2+k2r4+k3r6)ycorrected =y(1+k1r2+k2r4+k3r6)
其中
[
x
,
y
]
T
[x, y]^{T}
[x,y]T 是末纠正的点的坐标,
[
x
corrected
,
y
corrected
]
T
\left[x_{\text {corrected }} ,y_{\text {corrected }}\right]^{T}
[xcorrected ,ycorrected ]T 是纠正后的点的坐标, 注意它们 都是归一化平面上的点, 而不是像素平面上的点。
另一方面, 对于切向畸变, 可以使用另外的两个参数
p
1
,
p
2
p_{1}, p_{2}
p1,p2 来进行纠正:
x
corrected
=
x
+
2
p
1
x
y
+
p
2
(
r
2
+
2
x
2
)
y
corrected
=
y
+
p
1
(
r
2
+
2
y
2
)
+
2
p
2
x
y
xcorrected =x+2p1xy+p2(r2+2x2)ycorrected =y+p1(r2+2y2)+2p2xy
通过上面两个狮子可以对归一化平面的点进行径向和切向的畸变纠。然后通过内参数矩阵将其投影到像素平面,得到该点的在图像上的位置:
{
u
=
f
x
x
corrected
+
c
x
v
=
f
y
y
corrected
+
c
y
\left\{u=fxxcorrected +cxv=fyycorrected +cy
双目相机模型
测量像素距离(或深度)的方式有很多种,像人眼就可以根据左右眼看到的景物差异(或称视差)来判断物体与我们的距离。双目相机的原理亦是如此。通过同步采集左右相机的图像,计算图像间视差,来估计每一个像素的深度。
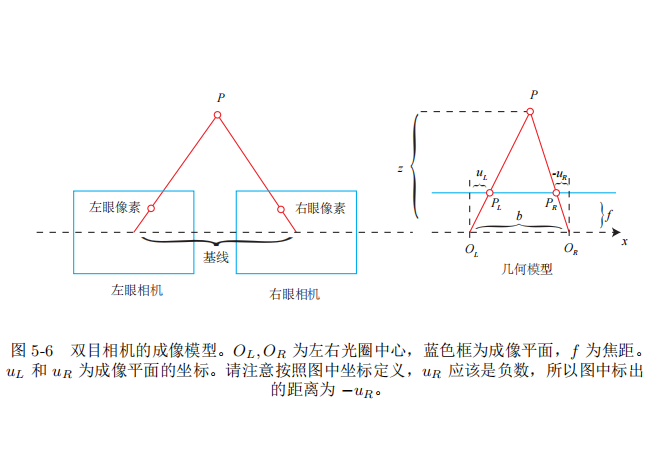
双目相机一般由左眼和右眼两个水平放置的相机组成。当然也可以做成上下两个目,但我们见到的主流双目都是做成左右的。在左右双目的相机中,我们可以把两个相机都看作针孔相机。它们是水平放置的,意味两个相机的光圈中心都位于 x 轴上。它们的距离称为双目相机的基线(Baseline, 记作 b),是双目的重要参数。
现在, 考虑一个空间点
P
P
P, 它在左眼和右眼各成一像, 记作
P
L
,
P
R
P_{L}, P_{R}
PL,PR 。由于相机基线的 存在, 这两个成像位置是不同的。理想情况下, 由于左右相机只有在
x
x
x 轴上有位移, 因此
P
P
P 的像也只在
x
x
x 轴 (对应图像的
u
u
u 轴) 上有差异。我们记它在左侧的坐标为
u
L
u_{L}
uL, 右侧坐标 为
u
R
u_{R}
uR 。那么, 它们的几何关系如图5-6右侧所示。根据三角形
P
−
P
L
−
P
R
P-P_{L}-P_{R}
P−PL−PR 和
P
−
O
L
−
O
R
P-O_{L}-O_{R}
P−OL−OR 的相似关系, 有:
z
−
f
z
=
b
−
u
L
+
u
R
b
.
\frac{z-f}{z}=\frac{b-u_{L}+u_{R}}{b} .
zz−f=bb−uL+uR.
稍加整理, 得:
z
=
f
b
d
,
d
=
u
L
−
u
R
.
z=\frac{f b}{d}, \quad d=u_{L}-u_{R} .
z=dfb,d=uL−uR.
这里
d
d
d 为左右图的横坐标之差, 称为视差 (Disparity)。根据视差, 我们可以估计一 个像素离相机的距离。视差与距离成反比: 视差越大, 距离越近 。同时, 由于视差最小为 一个像素, 于是双目的深度存在一个理论上的最大值, 由
f
b
f b
fb 确定。我们看到, 当基线越长 时, 双目最大能测到的距离就会变远; 反之, 小型双目器件则只能测量很近的距离。
相比于双目相机通过视差计算深度的方式,RGB-D 相机的做法更为“主动”一些,它能够主动测量每个像素的深度。目前的 RGB-D 相机按原理可分为两大类:
- 通过红外结构光(Structured Light)来测量像素距离的。例子有 Kinect 1 代、Project Tango 1 代、Intel RealSense 等;
- 通过飞行时间法(Time-of-flight, ToF)原理测量像素距离的。例子有 Kinect 2 代和一些现有的 ToF 传感器等
计算机中图像的表示
在数学中,图像可以用一个矩阵来描述;而在计算机中,它们占据一段连续的磁盘或内存空间,可以用二维数组来表示。我们从最简单的图像——灰度图开始说起。在一张灰度图中,每个像素位置 (x, y) 对应到一个灰度值 I,所以一张宽度为 w,高度为 h 的图像,数学形式可以记成一个矩阵:
I
(
x
,
y
)
∈
R
w
×
h
\boldsymbol{I}(x, y) \in \mathbb{R}^{w \times h}
I(x,y)∈Rw×h
,我们用 0-255 之间整数(即一个 unsigned char,一个字节)来
表达图像的灰度大小。那么,一张宽度为 640,高度为 480 分辨率的灰图度就可以这样表示:
unsigned char image[480][640];
- 1
它的第一个下标则是指数组的行,而第二个下标是列。在图像中,数组的行数对应图像的高度,而列数对应图像的宽度。左边显示了传统像素坐标系的定义方式。一个像素坐标系原点位于图像的左上角,X 轴向右,Y 轴向下(也就是前面所说的 u, v 坐标)。
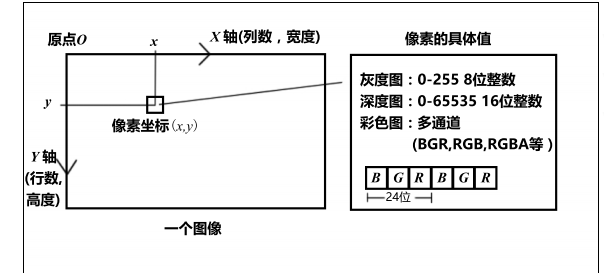
根据这种定义方式,如果我们讨论一个位于 x, y 处的像素,那么它在程序中的访问方式应该是:
1 unsigned char pixel = image[y][x];
- 1
它对应着灰度值 I(x, y) 的读数。请注意这里的 x 和 y 的顺序。虽然我们有些繁琐地向读者讨论坐标系的问题,但是像这种下标顺序的错误,会是新手在调试过程中经常碰到的,又具有一定隐蔽性的错误之一。
非线性优化基础
slam问题建模
经典Slam模型有一个状态方程和一个运动方程组成,如下式所示:
{
x
k
=
f
(
x
k
−
1
,
u
k
)
+
w
k
z
k
,
j
=
h
(
y
j
,
x
k
)
+
v
k
,
j
.
\left\{xk=f(xk−1,uk)+wkzk,j=h(yj,xk)+vk,j
这里,xk是相机的位姿,这里我们重点关注下观测方程。假设在 xk 处对路标 yj 进行了一次观测,对应到图像上的像素位置 zk,j,那么,观测方程可以表示成:
s
z
k
,
j
=
K
exp
(
ξ
∧
)
y
j
.
s \boldsymbol{z}_{k, j}=\boldsymbol{K} \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{y}_{j} .
szk,j=Kexp(ξ∧)yj.
根据上一讲的内容, 读者应该知道这里
K
K
K 为相机内参,
s
s
s 为像素点的距离。同时这里 的
z
k
,
j
z_{k, j}
zk,j 和
y
j
\boldsymbol{y}_{j}
yj 都必须以齐次坐标来描述, 且中间有一次齐次到非齐次的转换。如果你还不 熟悉这个过程, 请回到上一讲再仔细看一看。
现在, 考虑数据受噪声的影响后, 会发生什么改变。在运动和观测方程中, 我们通常 假设两个噪声项
w
k
,
v
k
,
j
\boldsymbol{w}_{k}, \boldsymbol{v}_{k, j}
wk,vk,j 满足零均值的高斯分布:
w
k
∼
N
(
0
,
R
k
)
,
v
k
∼
N
(
0
,
Q
k
,
j
)
.
\boldsymbol{w}_{k} \sim N\left(0, \boldsymbol{R}_{k}\right) , \boldsymbol{v}_{k} \sim N\left(0, \boldsymbol{Q}_{k, j}\right) .
wk∼N(0,Rk),vk∼N(0,Qk,j).
在这些噪声的影响下,我们希望通过带噪声的数据 z 和 u,推断位姿 x 和地图 y(以及它们的概率分布),这构成了一个状态估计问题。近年来普遍使用的非线性优化方法,使用所有时刻采集到的数据进行状态估计,并被认为优于传统的滤波器,成为当前视觉 SLAM 的主流方法。
在非线性优化中,我们把所有待估计的变量放在一个“状态变量”中:
x
=
{
x
1
,
…
,
x
N
,
y
1
,
…
,
y
M
}
\boldsymbol{x}=\left\{\boldsymbol{x}_{1}, \ldots, \boldsymbol{x}_{N}, \boldsymbol{y}_{1}, \ldots, \boldsymbol{y}_{M}\right\}
x={x1,…,xN,y1,…,yM}
现在, 我们说, 对机器人状态的估计, 就是求已知输入数据
u
\boldsymbol{u}
u 和观测数据
z
\boldsymbol{z}
z 的条件下, 计 算状态
x
x
x 的条件概率分布:
P
(
x
∣
z
,
u
)
.
P(\boldsymbol{x} \mid \boldsymbol{z}, \boldsymbol{u}) .
P(x∣z,u).
类似于
x
x
x, 这里
u
\boldsymbol{u}
u 和
z
z
z 也是对所有数据的统称。特别地, 当我们没有测量运动的传感器, 只有一张张的图像时, 即只考虑观测方程带来的数据时, 相当于估计
P
(
x
∣
z
)
P(x \mid z)
P(x∣z) 的条件概率 分布。如果忽略图像在时间上的联系, 把它们看作一堆彼此没有关系的图片, 该问题也称 为 Structure from Motion (SfM), 即如何从许多图像中重建三维空间结构 [22]。在这种情 况下, SLAM 可以看作是图像具有时间先后顺序的, 需要实时求解一个 SfM 问题。为了估 计状态变量的条件分布, 利用贝叶斯法则, 有:
P
(
x
∣
z
)
=
P
(
z
∣
x
)
P
(
x
)
P
(
z
)
∝
P
(
z
∣
x
)
P
(
x
)
.
P(x \mid z)=\frac{P(z \mid x) P(x)}{P(z)} \propto P(z \mid x) P(x) .
P(x∣z)=P(z)P(z∣x)P(x)∝P(z∣x)P(x).
贝叶斯法则左侧通常称为后验概率。它右侧的
P
(
z
∣
x
)
P(z \mid x)
P(z∣x) 称为似然, 另一部分
P
(
x
)
P(x)
P(x) 称 为先验。直接求后验分布是困难的, 但是求一个状态最优估计, 使得在该状态下, 后验概 率最大化 (Maximize a Posterior, MAP), 则是可行的:
x
∗
M
A
P
=
arg
max
P
(
x
∣
z
)
=
arg
max
P
(
z
∣
x
)
P
(
x
)
.
\boldsymbol{x}^{*}{ }_{M A P}=\arg \max P(\boldsymbol{x} \mid \boldsymbol{z})=\arg \max P(\boldsymbol{z} \mid \boldsymbol{x}) P(\boldsymbol{x}) .
x∗MAP=argmaxP(x∣z)=argmaxP(z∣x)P(x).
请注意贝叶斯法则的分母部分与待估计的状态
x
x
x 无关, 因而可以忽略。贝叶斯法则告 诉我们, 求解最大后验概率, 相当于最大化似然和先验的乘积。进一步, 我们当然也可以 说, 对不起, 我不知道机器人位姿大概在什么地方, 此时就没有了先验。那么, 可以求解
x
x
x 的最大似然估计(Maximize Likelihood Estimation, MLE):
x
∗
M
L
E
=
arg
max
P
(
z
∣
x
)
.
\boldsymbol{x}^{*}{ }_{M L E}=\arg \max P(\boldsymbol{z} \mid \boldsymbol{x}) .
x∗MLE=argmaxP(z∣x).
直观地说,似然是指“在现在的位姿下,可能产生怎样的观测数据”。由于我们知道观测数据,所以最大似然估计,可以理解成:“在什么样的状态下,最可能产生现在观测到的数据”。这就是最大似然估计的直观意义。
接下来的问题就是如何求最大似然估计。对于某一次观测:
z
k
,
j
=
h
(
y
j
,
x
k
)
+
v
k
,
j
,
\boldsymbol{z}_{k, j}=h\left(\boldsymbol{y}_{j}, \boldsymbol{x}_{k}\right)+\boldsymbol{v}_{k, j},
zk,j=h(yj,xk)+vk,j,
由于我们假设了噪声项
v
k
∼
N
(
0
,
Q
k
,
j
)
v_{k} \sim N\left(0, Q_{k, j}\right)
vk∼N(0,Qk,j), 所以观测数据的条件概率为:
P
(
z
j
,
k
∣
x
k
,
y
j
)
=
N
(
h
(
y
j
,
x
k
)
,
Q
k
,
j
)
.
P\left(\boldsymbol{z}_{j, k} \mid \boldsymbol{x}_{k}, \boldsymbol{y}_{j}\right)=N\left(h\left(\boldsymbol{y}_{j}, \boldsymbol{x}_{k}\right), \boldsymbol{Q}_{k, j}\right) .
P(zj,k∣xk,yj)=N(h(yj,xk),Qk,j).
它依然是一个高斯分布。为了计算使它最大化的
x
k
,
y
j
x_{k}, y_{j}
xk,yj, 我们往往使用最小化负对数的方 式, 来求一个高斯分布的最大似然。
高斯分布在负对数下有较好的数学形式。
取概率密度函数的负对数, 则变为:
−
ln
(
P
(
x
)
)
=
1
2
ln
(
(
2
π
)
N
det
(
Σ
)
)
+
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
.
-\ln (P(x))=\frac{1}{2} \ln \left((2 \pi)^{N} \operatorname{det}(\boldsymbol{\Sigma})\right)+\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{T} \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu}) .
−ln(P(x))=21ln((2π)Ndet(Σ))+21(x−μ)TΣ−1(x−μ).
对原分布求最大化相当于对负对数求最小化。在最小化上式的
x
x
x 时, 第一项与
x
x
x 无 关, 可以略去。于是, 只要最小化右侧的二次型项, 就得到了对状态的最大似然估计。代 入 SLAM 的观测模型, 相当于我们在求:
x
∗
=
arg
min
(
(
z
k
,
j
−
h
(
x
k
,
y
j
)
)
T
Q
k
,
j
−
1
(
z
k
,
j
−
h
(
x
k
,
y
j
)
)
)
.
x^{*}=\arg \min \left(\left(z_{k, j}-h\left(x_{k}, \boldsymbol{y}_{j}\right)\right)^{T} \boldsymbol{Q}_{k, j}^{-1}\left(\boldsymbol{z}_{k, j}-h\left(x_{k}, \boldsymbol{y}_{j}\right)\right)\right) .
x∗=argmin((zk,j−h(xk,yj))TQk,j−1(zk,j−h(xk,yj))).
我们发现, 该式等价于最小化噪声项 (即误差) 的平方(
Σ
\Sigma
Σ 范数意义下)。因此, 对于 所有的运动和任意的观测, 我们定义数据与估计值之间的误差:
e
v
,
k
=
x
k
−
f
(
x
k
−
1
,
u
k
)
e
y
,
j
,
k
=
z
k
,
j
−
h
(
x
k
,
y
j
)
,
ev,k=xk−f(xk−1,uk)ey,j,k=zk,j−h(xk,yj),
并求该误差的平方之和:
J
(
x
)
=
∑
k
e
v
,
k
T
R
k
−
1
e
v
,
k
+
∑
k
∑
j
e
y
,
k
,
j
T
Q
k
,
j
−
1
e
y
,
k
,
j
J(x)=\sum_{k} e_{v, k}^{T} R_{k}^{-1} e_{v, k}+\sum_{k} \sum_{j} e_{y, k, j}^{T} Q_{k, j}^{-1} e_{y, k, j}
J(x)=k∑ev,kTRk−1ev,k+k∑j∑ey,k,jTQk,j−1ey,k,j
这就得到了一个总体意义下的最小二乘问题(Least Square Problem)。我们明白它的最优解等价于状态的最大似然估计。直观来讲,由于噪声的存在,当我们把估计的轨迹与地图代入 SLAM 的运动、观测方程中时,它们并不会完美的成立。这时候怎么办呢?我们把状态的估计值进行微调,使得整体的误差下降一些。当然这个下降也有限度,它一般会到达一个极小值。这就是一个典型非线性优化的过程。
需要注意的是:如果使用李代数表示,则该问题是无约束的最小二乘问题。但如果用旋转矩阵(变换矩阵)描述位姿,则会引入旋转矩阵自身的约束(旋转矩阵必须是正交阵且行列式为 1)。额外的约束会使优化变得更困难。这体现了李代数的优势。其次,我们使用了平方形式(二范数)度量误差,它是直观的,相当于欧氏空间中距离的平方。但它也存在着一些问题,并且不是唯一的度量方式。我们亦可使用其他的范数构建优化问题。
非线性最小二乘
考虑一个简单的最小二乘问题:
min
x
1
2
∥
f
(
x
)
∥
2
2
2
\min _{x} \frac{1}{2}\|f(\boldsymbol{x})\|_{2^{2}}^{2}
xmin21∥f(x)∥222
对于一个简单的f(x),我们可以通过令其导数为零,找到x的最优解。但f(x)比较复杂,尤其是包含了之前提到的旋转矩阵,直接求导就不可行了,但我们可以用用迭代的方式,从一个初始值出发,不断地更新当前的优化变量,使目标函数下降。具体步骤为:
- 给定某个初始值 x 0 x_{0} x0 。
- 对于第 k k k 次迭代, 寻找一个增量 Δ x k \Delta \boldsymbol{x}_{k} Δxk, 使得 ∥ f ( x k + Δ x k ) ∥ 2 2 \left\|f\left(x_{k}+\Delta x_{k}\right)\right\|_{2}^{2} ∥f(xk+Δxk)∥22 达到极小值。
- 若 Δ x k \Delta \boldsymbol{x}_{k} Δxk 足够小, 则停止。
- 否则, 令
x
k
+
1
=
x
k
+
Δ
x
k
x_{k+1}=x_{k}+\Delta x_{k}
xk+1=xk+Δxk, 返回 2 .
下面的问题就是如何确定增量 ∆xk,视觉SLAM普遍采用两种方法:
一阶和二阶梯度法
将目标函数在x附近进行泰勒展开:
∥
f
(
x
+
Δ
x
)
∥
2
2
≈
∥
f
(
x
)
∥
2
2
+
J
(
x
)
Δ
x
+
1
2
Δ
x
T
H
Δ
x
.
\|f(\boldsymbol{x}+\Delta \boldsymbol{x})\|_{2}^{2} \approx\|f(\boldsymbol{x})\|_{2}^{2}+\boldsymbol{J}(\boldsymbol{x}) \Delta \boldsymbol{x}+\frac{1}{2} \Delta \boldsymbol{x}^{T} \boldsymbol{H} \Delta \boldsymbol{x} .
∥f(x+Δx)∥22≈∥f(x)∥22+J(x)Δx+21ΔxTHΔx.
这里
J
\boldsymbol{J}
J 是
∥
f
(
x
)
∥
2
\|f(\boldsymbol{x})\|^{2}
∥f(x)∥2 关于
x
\boldsymbol{x}
x 的导数 (雅可比矩阵), 而
H
\boldsymbol{H}
H 则是二阶导数 (海塞 (Hessian) 矩阵)。如果保留一阶梯度, 那么增量的方向为:
Δ
x
∗
=
−
J
T
(
x
)
.
\Delta x^{*}=-J^{T}(x) .
Δx∗=−JT(x).
它的直观意义非常简单, 只要我们沿着反向梯度方向前进即可。当然, 我们还需要该 方向上取一个步长
λ
\lambda
λ, 求得最快的下降方式。这种方法被称为最速下降法
6
{ }^{6}
6 另一方面, 如果保留二阶梯度信息, 那么增量方程为:
Δ
x
∗
=
arg
min
∥
f
(
x
)
∥
2
2
+
J
(
x
)
Δ
x
+
1
2
Δ
x
T
H
Δ
x
.
\Delta \boldsymbol{x}^{*}=\arg \min \|f(\boldsymbol{x})\|_{2}^{2}+\boldsymbol{J}(\boldsymbol{x}) \Delta \boldsymbol{x}+\frac{1}{2} \Delta \boldsymbol{x}^{T} \boldsymbol{H} \Delta \boldsymbol{x} .
Δx∗=argmin∥f(x)∥22+J(x)Δx+21ΔxTHΔx.
求右侧等式关于
Δ
x
\Delta \boldsymbol{x}
Δx 的导数并令它为零, 就得到了增量的解:
H
Δ
x
=
−
J
T
.
\boldsymbol{H} \Delta \boldsymbol{x}=-\boldsymbol{J}^{T} .
HΔx=−JT.
该方法称又为牛顿法。最速下降法过于贪心,容易走出锯齿路线,反
而增加了迭代次数。而牛顿法则需要计算目标函数的 H 矩阵,这在问题规模较大时非常困难,我们通常倾向于避免 H 的计算。所以,接下来我们详细地介绍两类更加实用的方法:高斯牛顿法和列文伯格——马夸尔特方法。
Gauss-Newton法
Gauss Newton 是最优化算法里面最简单的方法之一。它的思想是将 f(x) 进行一阶的泰勒展开(请注意不是目标函数 f(x)2):
f
(
x
+
Δ
x
)
≈
f
(
x
)
+
J
(
x
)
Δ
x
f(x+\Delta x) \approx f(x)+J(x) \Delta x
f(x+Δx)≈f(x)+J(x)Δx
为了求 ∆x,我们需要解一个线性的最小二乘问题:
Δ
x
∗
=
arg
min
Δ
x
1
2
∥
f
(
x
)
+
J
(
x
)
Δ
x
∥
2
\Delta x^{*}=\arg \min _{\Delta \boldsymbol{x}} \frac{1}{2}\|f(\boldsymbol{x})+\boldsymbol{J}(\boldsymbol{x}) \Delta \boldsymbol{x}\|^{2}
Δx∗=argΔxmin21∥f(x)+J(x)Δx∥2
先展开目标函数的平方项:
1
2
∥
f
(
x
)
+
J
(
x
)
Δ
x
∥
2
=
1
2
(
f
(
x
)
+
J
(
x
)
Δ
x
)
T
(
f
(
x
)
+
J
(
x
)
Δ
x
)
=
1
2
(
∥
f
(
x
)
∥
2
2
+
2
f
(
x
)
T
J
(
x
)
Δ
x
+
Δ
x
T
J
(
x
)
T
J
(
x
)
Δ
x
)
.
12‖f(x)+J(x)Δx‖2=12(f(x)+J(x)Δx)T(f(x)+J(x)Δx)=12(‖f(x)‖22+2f(x)TJ(x)Δx+ΔxTJ(x)TJ(x)Δx).
求上式关于
Δ
x
\Delta \boldsymbol{x}
Δx 的导数, 并令其为零:
2
J
(
x
)
T
f
(
x
)
+
2
J
(
x
)
T
J
(
x
)
Δ
x
=
0.
2 \boldsymbol{J}(\boldsymbol{x})^{T} f(\boldsymbol{x})+2 \boldsymbol{J}(\boldsymbol{x})^{T} \boldsymbol{J}(\boldsymbol{x}) \Delta \boldsymbol{x}=\mathbf{0} .
2J(x)Tf(x)+2J(x)TJ(x)Δx=0.
可以得到如下方程组:
J
(
x
)
T
J
(
x
)
Δ
x
=
−
J
(
x
)
T
f
(
x
)
\boldsymbol{J}(\boldsymbol{x})^{T} \boldsymbol{J}(\boldsymbol{x}) \Delta \boldsymbol{x}=-\boldsymbol{J}(\boldsymbol{x})^{T} f(\boldsymbol{x})
J(x)TJ(x)Δx=−J(x)Tf(x)
注意, 我们要求解的变量是
Δ
x
\Delta x
Δx, 因此这是一个线性方程组, 我们称它为增量方程, 也 可以称为高斯牛顿方程 (Gauss Newton equations) 或者正规方程 (Normal equations)。我 们把左边的系数定义为
H
H
H, 右边定义为
g
g
g, 那么上式变为:
H
Δ
x
=
g
.
\boldsymbol{H} \Delta \boldsymbol{x}=\boldsymbol{g} .
HΔx=g.
如果我们能够顺利解出该方程,那么 Gauss-Newton 的算法步骤可以写成:
- 给定初始值 x 0 x_{0} x0 。
- 对于第 k k k 次迭代, 求出当前的雅可比矩阵 J ( x k ) \boldsymbol{J}\left(\boldsymbol{x}_{k}\right) J(xk) 和误差 f ( x k ) f\left(\boldsymbol{x}_{k}\right) f(xk) 。
- 求解增量方程: H Δ x k = g \boldsymbol{H} \Delta \boldsymbol{x}_{k}=\boldsymbol{g} HΔxk=g.
- 若 Δ x k \Delta x_{k} Δxk 足够小, 则停止。否则, 令 x k + 1 = x k + Δ x k x_{k+1}=x_{k}+\Delta x_{k} xk+1=xk+Δxk, 返回 2 .
原则上,它要求我们所用的近似 H 矩阵是可逆的(而且是正定的),但实际数据中计算得到的
J
T
J
\boldsymbol{J}^{T} \boldsymbol{J}
JTJ却只有半正定性。也就是说,在使用 Gauss Newton 方法时,可能出现
J
T
J
\boldsymbol{J}^{T} \boldsymbol{J}
JTJ为奇异矩阵或者病态 (illcondition) 的情况,此时增量的稳定性较差,导致算法不收敛。更严重的是,就算我们假设 H 非奇异也非病态,如果我们求出来的步长 ∆x 太大,也会导致我们采用的局部近似不够准确,这样一来我们甚至都无法保证它的迭代收敛,哪怕是让目标函数变得更大都是有可能的。
Levenberg-Marquadt 方法在一定程度上修正了这些问题,一般认为它比 Gauss Newton 更为鲁棒。尽管它的收敛速度可能会比 Gauss Newton 更慢,被称之为阻尼牛顿法(Damped Newton Method),但是在 SLAM 里面却被大量应用。
Levenberg-Marquant方法
由于 Gauss-Newton 方法中采用的近似二阶泰勒展开只能在展开点附近有较好的近似效果,所以我们很自然地想到应该给 ∆x 添加一个信赖区域(Trust Region),不能让它太大而使得近似不准确。非线性优化种有一系列这类方法,这类方法也被称之为信赖区域方法 (Trust Region Method)。在信赖区域里边,我们认为近似是有效的;出了这个区域,近似可能会出问题。
我们使用
ρ
=
f
(
x
+
Δ
x
)
−
f
(
x
)
J
(
x
)
Δ
x
\rho=\frac{f(x+\Delta x)-f(x)}{J(x) \Delta x}
ρ=J(x)Δxf(x+Δx)−f(x)
来判断泰勒近似是否够好,进而确定信赖区域的范围。。ρ 的分子是实际函数下降的值,分母是近似模型下降的值。如果 ρ 接近于 1,则近似是好的。如果 ρ 太小,说明实际减小的值远少于近似减小的值,则认为近似比较差,需要缩小近似范围。反之,如果 ρ 比较大,则说明实际下降的比预计的更大,我们可以放大近似范围。
我们构建一个改良版的非线性优化框架,该框架会比 Gauss Newton 有更好的效果:
- 给定初始值 x 0 x_{0} x0, 以及初始优化半径 μ 。 \mu_{\text {。 }} μ。
- 对于第
k
k
k 次迭代, 求解:
min Δ x k 1 2 ∥ f ( x k ) + J ( x k ) Δ x k ∥ 2 , s.t. ∥ D Δ x k ∥ 2 ≤ μ , \min _{\Delta \boldsymbol{x}_{k}} \frac{1}{2}\left\|f\left(\boldsymbol{x}_{k}\right)+\boldsymbol{J}\left(\boldsymbol{x}_{k}\right) \Delta \boldsymbol{x}_{k}\right\|^{2}, \quad \text { s.t. }\left\|\boldsymbol{D} \Delta \boldsymbol{x}_{k}\right\|^{2} \leq \mu, Δxkmin21∥f(xk)+J(xk)Δxk∥2, s.t. ∥DΔxk∥2≤μ,
这里 μ \mu μ 是信赖区域的半径, D D D 将在后文说明。 - 计算 ρ \rho ρ 。
- 若 ρ > 3 4 \rho>\frac{3}{4} ρ>43, 则 μ = 2 μ \mu=2 \mu μ=2μ;
- 若 ρ < 1 4 \rho<\frac{1}{4} ρ<41, 则 μ = 0.5 μ \mu=0.5 \mu μ=0.5μ;
- 如果 ρ \rho ρ 大于某阈值, 认为近似可行。令 x k + 1 = x k + Δ x k x_{k+1}=x_{k}+\Delta x_{k} xk+1=xk+Δxk 。
- 判断算法是否收敛。如不收敛则返回 2 , 否则结束。
这里近似范围扩大的倍数和阈值都是经验值,可以替换成别的数值。在上述流程中,我们把增量限定于一个半径为 µ 的球中,认为只在这个球内才是有效的。带上 D 之后,这个球可以看成一个椭球。在 Levenberg 提出的优化方法中,把 D 取成单位阵 I,相当于直接把 ∆x 约束在一个球中。随后,Marqaurdt 提出将 D 取成非负数对角阵——实际中通常用 JT J 的对角元素平方根,使得在梯度小的维度上约束范围更大一些。
第二步其实是一个带约束的最小化问题,我们用Lagrange橙子将其转化为无约束优化问题:
min
Δ
x
k
1
2
∥
f
(
x
k
)
+
J
(
x
k
)
Δ
x
k
∥
2
+
λ
2
∥
D
Δ
x
∥
2
.
\min _{\Delta \boldsymbol{x}_{k}} \frac{1}{2}\left\|f\left(\boldsymbol{x}_{k}\right)+\boldsymbol{J}\left(\boldsymbol{x}_{k}\right) \Delta \boldsymbol{x}_{k}\right\|^{2}+\frac{\lambda}{2}\|\boldsymbol{D} \Delta \boldsymbol{x}\|^{2} .
Δxkmin21∥f(xk)+J(xk)Δxk∥2+2λ∥DΔx∥2.
这里
λ
\lambda
λ 为 Lagrange 乘子。类似于 Gauss-Newton 中的做法, 把它展开后, 我们发现 该问题的核心仍是计算增量的线性方程:
(
H
+
λ
D
T
D
)
Δ
x
=
g
.
\left(\boldsymbol{H}+\lambda \boldsymbol{D}^{T} \boldsymbol{D}\right) \Delta \boldsymbol{x}=\boldsymbol{g} .
(H+λDTD)Δx=g.
可以看到, 增量方程相比于 Gauss-Newton, 多了一项
λ
D
T
D
\lambda D^{T} D
λDTD 。如果考虑它的简化形 式, 即
D
=
I
D=I
D=I, 那么相当于求解:
(
H
+
λ
I
)
Δ
x
=
g
.
(\boldsymbol{H}+\lambda \boldsymbol{I}) \Delta \boldsymbol{x}=\boldsymbol{g} .
(H+λI)Δx=g.
我们看到, 当参数
λ
\lambda
λ 比较小时,
H
H
H 占主要地位, 这说明二次近似模型在该范围内是比 较好的, L-M 方法更接近于
G
−
N
\mathrm{G}-\mathrm{N}
G−N 法。另一方面, 当
λ
\lambda
λ 比较大时,
λ
I
\lambda \boldsymbol{I}
λI 占据主要地位, L-M 更接近于一阶梯度下降法 (即最速下降), 这说明附近的二次近似不够好。L-M 的求解方 式, 可在一定程度上避免线性方程组的系数矩阵的非奇异和病态问题, 提供更稳定更准确 的增量
Δ
x
\Delta x
Δx 。
小结
无论是 G-N 还是 L-M,在做最优化计算的时候,都需要提供变量的初始值。你也许会问到,这个初始值能否随意设置? 当然不是。实际上非线性优化的所有迭代求解方案,都需要用户来提供一个良好的初始值。由于目标函数太复杂,导致在求解空
间上的变化难以琢磨,对问题提供不同的初始值往往会导致不同的计算结果。这种情况是非线性优化的通病:大多数算法都容易陷入局部极小值。因此,无论是哪类科学问题,我们提供初始值都应该有科学依据,例如视觉 SLAM 问题中,我们会用 ICP,PnP 之类的算法提供优化初始值。总之,一个良好的初始值对最优化问题非常重要!

