
- 1扫雷-源码_/!d6f0316kz4!:/
- 2Android activity简单介绍_activity_1docj5nlzj8
- 3LeetCode 第11题:盛最多水的容器(Python3解法)_盛水最多的容器题解python
- 4AI视频分析技术的工作原理
- 5Python.win32gui.获取窗体_try: win32gui.findwindow(none, windowname)
- 6每日一题|2022-10-19|1700. 无法吃午餐的学生数量|Golang
- 7buildroot/package中增加patch_buildroot新增patch
- 8Java项目:医院挂号管理系统(java+SpringBoot+Vue+ElementUI+Layui+Mysql)_springboot医院管理系统设计与实现
- 9使用pip命令安装Python外部的模块_pip install pandas openpyxl
- 10fir fpga 不同截止频率_毕设:基于FPGA的FIR数字滤波器设计
初步了解SequoiaDB巨杉数据库
赞
踩
1.SequoiaDB 简介
2.整体架构
3.数据库存储引擎
4.核心特性
SequoiaDB 简介
SequoiaDB 巨杉数据库是一款金融级分布式数据库,主要面对高并发实时处理型场景提供高性能、可靠稳定以及无限水平扩展的数据库服务。
用户可以在 SequoiaDB 巨杉数据库中创建多种类型的数据库实例,以满足上层不同应用程序各自的需求。
SequoiaDB 巨杉数据库支持 MySQL、MariaDB、PostgreSQL 和 SparkSQL 四种关系型数据库实例、JSON 文档类数据库实例、以及 S3 对象存储的非结构化数据实例。
整体架构
SequoiaDB 巨杉数据库作为分布式数据库,由数据库存储引擎与数据库实例两大模块构成。
其中,数据库存储引擎模块是数据存储的核心,负责提供整个数据库的读写服务、数据的高可用与容灾、ACID 与分布式事务等全部核心数据服务。
数据库实例模块则作为协议与语法的适配层,用户可根据需要创建包括 MySQL、MariaDB、PostgreSQL 与 SparkSQL 在内的结构化数据实例;以及 JSON 和 S3 对象存储的非结构化实例。
通过使用 SequoiaDB 巨杉数据库,用户可以通过创建不同类型的数据库实例,使应用程序从传统数据库进行无缝迁移,大幅度降低应用程序开发者的学习成本。
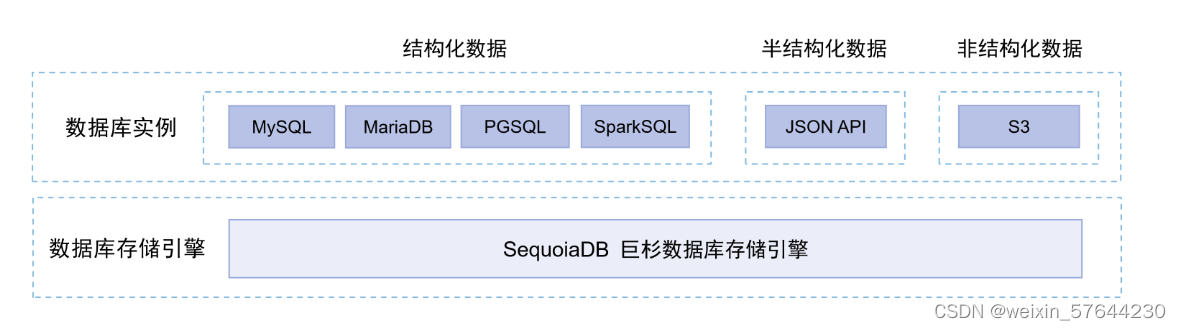
数据库存储引擎
SequoiaDB 巨杉数据库存储引擎采用分布式架构。集群中的每个节点为一个独立进程,节点之间采用 TCP/IP 协议进行通讯。
同一个操作系统可以部署多个节点,节点之间采用不同的端口进行区分。
SequoiaDB 巨杉数据库的节点分为三种不同的角色:协调节点、编目节点与数据节点。
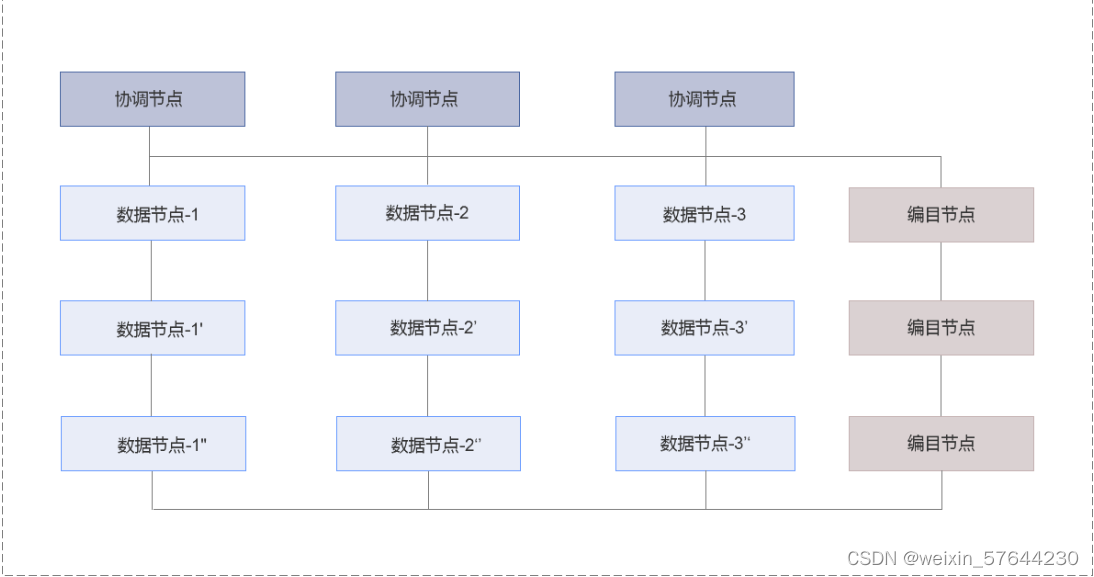
协调节点
协调节点不存储任何用户数据。作为外部访问的接入与请求分发节点,协调节点将用户请求分发至相应的数据节点,最终合并数据节点的结果应答对外进行响应。
编目节点
编目节点主要存储系统的节点信息、用户信息、分区信息以及对象定义等元数据。在特定操作下,协调节点与数据节点均会向编目节点请求元数据信息,以感知数据的分布规律和校验请求的正确性。
数据节点
数据节点为用户数据的物理存储节点,海量数据通过分片切分的方式被分散至不同的数据节点。在关系型与 JSON 数据库实例中,每一条记录会被完整地存放在其中一个或多个数据节点中;而在对象存储实例中,每一个文件将会依据数据页大小被拆分成多个数据块,并被分散至不同的数据节点进行存放。
核心特性
弹性水平扩展
作为一款分布式数据库,支持无限弹性水平扩展是 SequoiaDB 巨杉数据库的基本特性,其底层的分布式存储引擎与上层的数据库实例均支持无限弹性水平扩展能力。
SequoiaDB 巨杉数据库的数据库实例均无状态并使用 TCP/IP 协议对外提供服务。为了提升整体处理能力,用户可以通过增加服务器数量或创建额外的数据库实例实现对应用的水平弹性扩张。
高可用与容灾
由于 PC 服务器内置物理磁盘不同于传统小型机加存储设备的架构,在 PC 服务器出现物理故障时无法保障存储在本地磁盘的数据不丢不坏,因此所有基于 PC 服务器内置盘架构的数据库,必须采用多副本机制以保障数据库的高可用与容灾。
分布式事务
SequoiaDB 巨杉数据库支持强一致分布式事务功能。利用二段提交机制,SequoiaDB 巨杉数据库在分布式存储引擎实现了对结构化与半结构化数据的强一致分布式事务功能,不论用户创建哪种数据库实例,其底层均可提供完整的分布式事务及锁能力。
SequoiaDB 巨杉数据库完整支持四种隔离级别,同时支持读写锁等待以及读已提交版本机制。
多模式接口
SequoiaDB 巨杉数据库通过数据库实例的形式提供多种关系型以及非关系型数据库兼容引擎,支持结构化、半结构化以及非结构化数据。在当前版本中,SequoiaDB 巨杉数据库支持包括 MySQL、MariaDB、PostgreSQL 以及 SparkSQL 在内的四种关系型数据库引擎,同时支持 JSON API 的半结构化数据引擎,以及 S3 对象存储的非结构化数据引擎。
使用多模式接口机制,用户可以使用 SequoiaDB 巨杉数据库服务于任何类型的应用程序,真正做到分布式数据库的平台化服务。
多租户隔离
对于分布式数据库来说,其存在的价值不仅仅在于解决单点数据量大的问题。更是在应用程序微服务化的今天,分布式数据库需要以一种平台化(PaaS)的形式对上层大量的应用与微服务同时提供数据访问能力。在这种情况下,如何做到不同微服务之间所对应的底层数据逻辑与物理隔离,是保障云环境中分布式数据库安全、可靠和性能稳定的前提。
在 SequoiaDB 巨杉数据库中,数据域可以用于复杂集群环境中对资源进行逻辑与物理划分隔离。例如,在极为重要的实时处理型账务类应用中,其物理资源往往需要与审计后督类业务完全隔离,以保障在任何情况下审计类业务的复杂压力不会影响到核心账务系统的稳定运行。同样,不同的数据域之间的数据安全性配置、硬件资源环境等往往也不尽相同。
通过包括数据域、多模式接口、水平弹性扩展在内的多种机制,SequoiaDB 巨杉数据库能够保障应用程序在云环境下的多租户隔离。

