
热门标签
热门文章
- 1uniapp微信小程序自定义刘海屏头部兼容问题_unipp 刘海屏幕 兼容写法
- 2MyBatisPlus与MyBatis的对比与联系_mymatisplus 和mymatis 对比图
- 3Mac安装多个Java环境_mac air m2 安装多个java
- 4linux逻辑卷/dev/mapper/centos-root扩容增加空间
- 5云服务器迁移 (全网最省钱最详细攻略)_服务器迁移难吗
- 6黑客学习手册(自学网络安全)_黑客学习资料
- 7css实现两行或多行显示省略号_css双行省略号怎么写
- 8linux ssh连接问题总结与解决方案_ssh无法连接linux服务器
- 9【Unity组件知识】如何在Unity2020以后版本中打包图集_unity 打包图集
- 102023年最新Java八股文面试题,面试应该是够用了(吊打面试官)_java面试八股文2023
当前位置: article > 正文
用sql解析通达信二进制day文件,得到历史股价数据_通达信数据解析
作者:Cpp五条 | 2024-03-01 04:36:34
赞
踩
通达信数据解析
炒股软件通达信把日k线存放在vipdoc\sz\lday下面。sz表示深圳交易所的证券。sz000002.day表示万科的日k线数据,它是二进制的,不能直接阅读,需要一个解析的规则。网络上有一些用python的struct库解析的方法,这里尝试用spark sql来解析。
先看一下二进制文件长啥样:
- val df = spark.read.format("binaryFile").load("C:/zd_xdzq/vipdoc/sz/lday/sz000002.day")
- df.select("content").show()
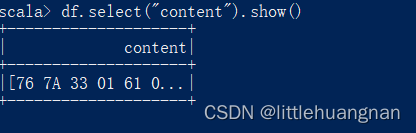

读出来是字节数组。每32个字节是一天的数据。这32个字节中,1-4是日期,5-8是开盘价,9-12是最高价,13-16是最低价,17-20是收盘价,21-24是成交额,25-28是成交量。
这个[76 7A 33 01]用python struct解析出来是20150902,用sql
select hex(20150902)得到的结果是

1 33 7A 76跟[76 7A 33 01]刚好是反的(每个字节是反的)。所以sql解析的思路是,
第一步,把这长串二进制字符每32个字节切成一段
第二步,把每一段按字节反过来
第三步,转成十进制
每32个字节切成一段,没有现成的函数,split只能按标点符号或表达式来切,所以要写一个udf
- def splitOnLength(len: Int) = udf((str: String) => {
- str.grouped(len).toSeq
- })
-
- spark.udf.register("splitOnLen64", splitOnLength(64))
- spark.udf.register("splitOnLen2", splitOnLength(2))
splitOnLen64就是每32个字节切一段。如果day文件有200个交易日,则生成一个包含200个元素的序列。然后用explode函数转成200行。
然后把每一段切成32小段,这可以用splitOnLen2函数。然后用slice函数,1-4是日期,5-8是开盘价等等。接着用reverse函数完成反转,用array_join函数完成拼接,最后用conv函数转成十进制。
完整sql如下
- select conv(array_join(reverse(slice(v,1,4)),''),16,10) ymd,
- conv(array_join(reverse(slice(v,5,4)),''),16,10) open,
- conv(array_join(reverse(slice(v,9,4)),''),16,10) high,
- conv(array_join(reverse(slice(v,13,4)),''),16,10) low,
- conv(array_join(reverse(slice(v,17,4)),''),16,10) close,
- intBits2f(conv(array_join(reverse(slice(v,21,4)),''),16,10)) turnover,
- conv(array_join(reverse(slice(v,25,4)),''),16,10) volume
- from
- (select splitOnLen2(value) v
- from
- (select explode(splitOnLen64(hex(content))) value
- from wanke
- )
- )
其中成交额是浮点数,需要一个额外的udf
- val intBits2f = udf((bits:Int) => java.lang.Float.intBitsToFloat(bits))
- spark.udf.register("intBits2f",intBits2f)
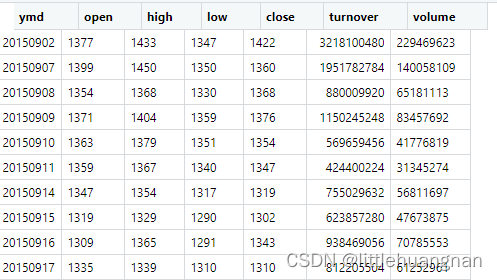
得到结果如下
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/171015
推荐阅读
相关标签

