
- 1解决VB6程序打开时不能加载控件的问题_vb6不能加载foxitpdfsdk_ax_pro.ocx
- 2计算机缩写术语完全介绍_qpabms
- 3Mybatis使用selectKey返回插入数据的id_selectkey 注解返回新插入数据的id
- 4HarmonyOS端云体化开发—创建端云一体化开发工程_鸿蒙端云一体化开发教程
- 5langchain==win11搭建使用GPU_langchain通过gpu启动
- 6Android内存泄漏的检测流程、捕捉以及分析_android 内存泄漏捕捉
- 7k8s 安全机制详解
- 8虚函数表_虚函数表里面装的什么
- 9浅记Android开发中遇到的bug合集_android系统开发bug
- 10Android 图片裁剪并批量上传视频图片到阿里云OSS
Springboot项目使用Elastic Search教程(完整步骤)_springboot使用es
赞
踩
Springboot项目使用Elastic Search教程(完整步骤)
最近的项目需要用到Elastic Search,上网查资料的时候发现内容比较分散,搜索起来的时候比较费力,
于是最近入门配置成功之后,稍微总结一下吧。
先给出一些网上的教程
(152条消息) Spring Boot整合Elasticsearch,最新最全教程_spring elasticsearch_Cloud-Future的博客-CSDN博客
这一篇代码是写的挺清晰的
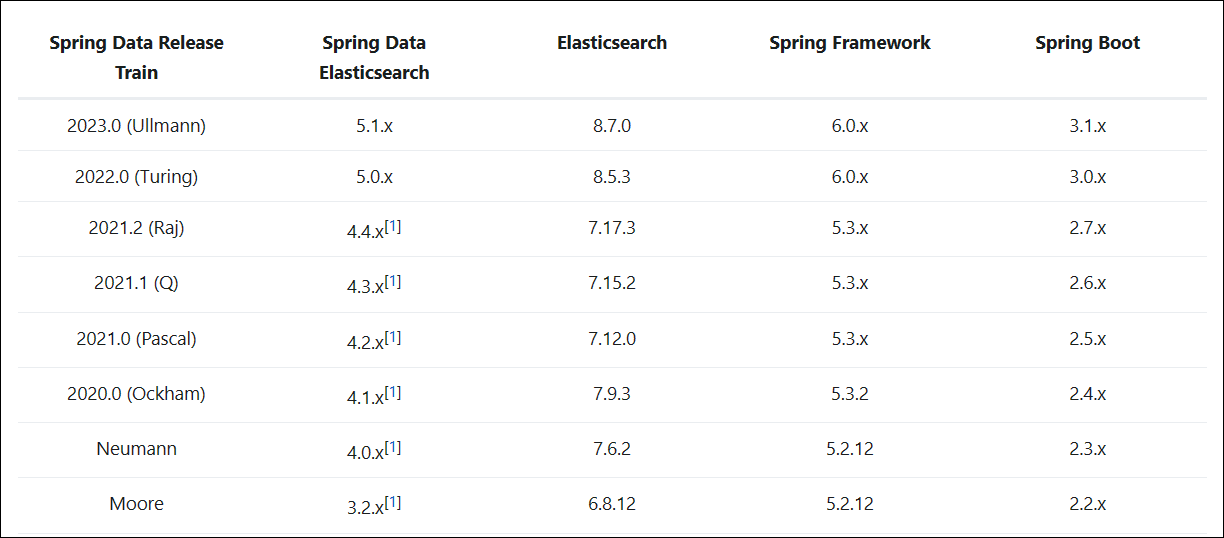
查看对应的spring data es和es和springboot对应的版本
Spring Data Elasticsearch - Reference Documentation
(152条消息) spring data elasticsearch 对应 elasticsearch 版本_elasticsearch版本兼容_悟能的师兄的博客-CSDN博客
安装ES的教程
spring-data-elasticsearch官方文档
1. 安装Elastic Search
这个比较简单,先直接去官网上面找到对应的Springboot的版本,然后下载Zip,解压
例如我的springboot版本是2.7.5,所以ES我下的是7.17.3
ES官网Download Elasticsearch | Elastic
主页右边可以选择过去的版本
解压后直接运行bin文件下的elasticsearch.bat的批处理文件
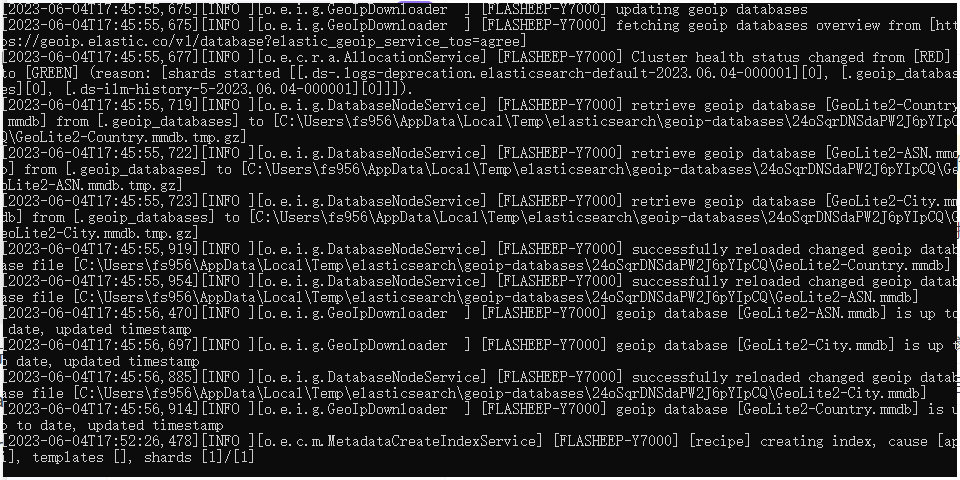
然后等待CMD输出一些指令即可运行成功了!
cmd运行内容如图
在后面运行springboot的时候记得也要同时运行着这个Elastic Search
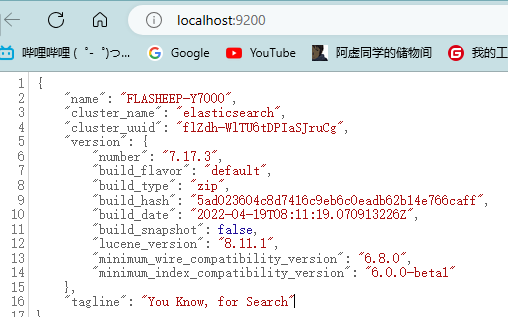
可以去localhost:9200处查看是否正确的运行;
2. 安装IK分词器(这个索引当中用了ik_max_word的话就要装)
IK分词器是es的一个插件
我在后面配置好了springboot之后才发现要配置这个
运行spring boot的时候发现有reason=analyzer [ik_max_word] has not been configured in mappings]]的报错
然后搜了一下发现还需要安装分词器
因为在实体类索引当中我使用了分词

github下载网址 medcl/elasticsearch-analysis-ik: The IK Analysis plugin integrates Lucene IK analyzer into elasticsearch, support customized dictionary. (github.com),在页面的右侧的release可以查看过去的版本
注意版本要和ElasticSearch的一致!!
分词器也是安装好对应版本(和ES版本一致)的zip文件后,直接解压到ES的plugin文件夹下即可
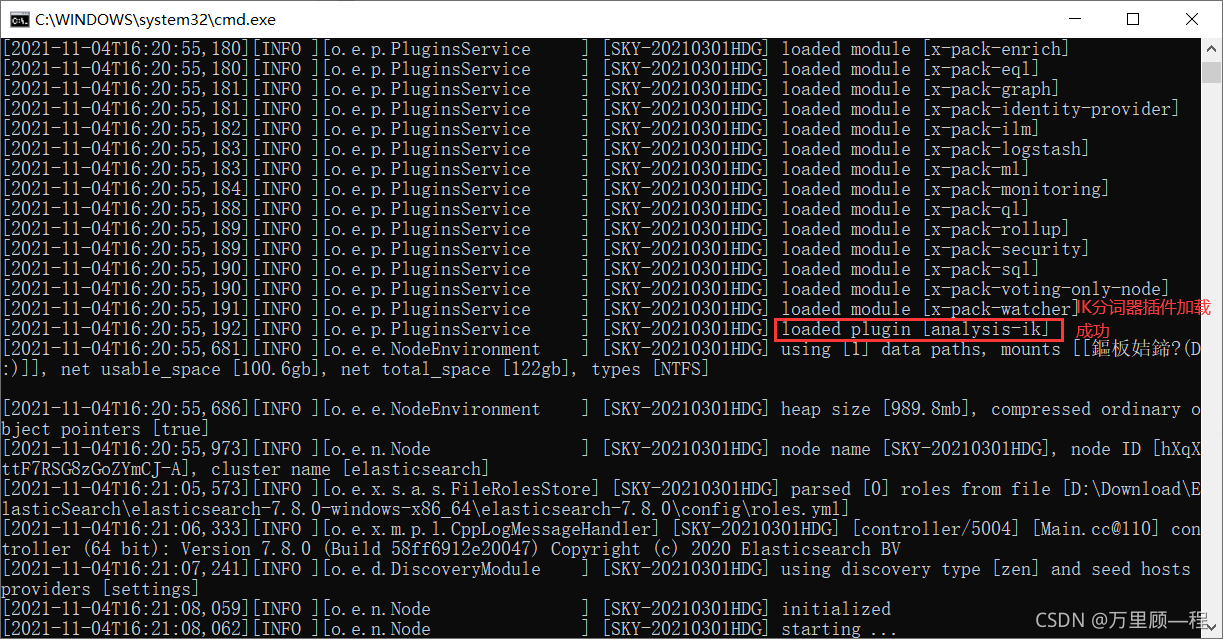
安装好后再次运行Elastic Search即可。
3. springboot配置相关依赖
从这个步骤往后都是可以参照我最上面给出的教程网址,跟着走即可
我这里只讲一下大概
3.1 pom导入依赖
只配这个data-elasticsearch就可以了,那个client可以不用,那个有什么用目前我还不会
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- 1
- 2
- 3
- 4
- 5
3.2 java 编写相关配置类
这个配置类也很简单,所有的都是这样配置,网上直接找就可以了
/** * ElasticSearch 客户端配置 * * @author geng * 2020/12/19 */ @Configuration public class RestClientConfig extends AbstractElasticsearchConfiguration { @Override @Bean public RestHighLevelClient elasticsearchClient() { final ClientConfiguration clientConfiguration = ClientConfiguration.builder() .connectedTo("localhost:9200") .build(); return RestClients.create(clientConfiguration).rest(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.3 实体类entity与Dao层
实体类Recipe
@Data @NoArgsConstructor @AllArgsConstructor @Document(indexName = "recipe",createIndex = true) public class Recipe { @Id @Field(type = FieldType.Integer) private Integer id; //菜谱id @Field(type = FieldType.Integer) private Integer categoryId;//菜谱种类,外键ID @Field(type = FieldType.Text,analyzer = "ik_max_word") private String title; @Field(type = FieldType.Keyword) private String coverUrl; //食谱封面 @Field(type = FieldType.Text,analyzer = "ik_max_word") private String mainIngredient;//添有主要食材的名字 .................. }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
关于这些注解的介绍可参考官方文档,或者csdn教程(153条消息) Spring Data Elasticsearch篇(1):常用注解_spring data elasticsearch @field_mykefei的博客-CSDN博客
对应的DAO层非常简单,spring的data-elasticsearch都已经提供好了
public interface ESRecipeDao extends ElasticsearchRepository<Recipe,String> {
List<Recipe> findByTitleOrMainIngredient(String title,String mainIngredient);
List<Recipe> findByTitle(String title);
}
- 1
- 2
- 3
- 4
- 5
这里dao定义了两个函数,都是它自动提供好的,只要你的实体类里面有这些参数,这个函数就可以被自动构建出来,比MybatisPlus还要高级,更详细的用法这里就不介绍了,这个只能实现简单的搜索,还没有分词功能
service层什么的就直接调用Dao层的接口就好了,这里也不展开了。
正确运行后,索引如果正确建立了,也是可以通过接口访问的
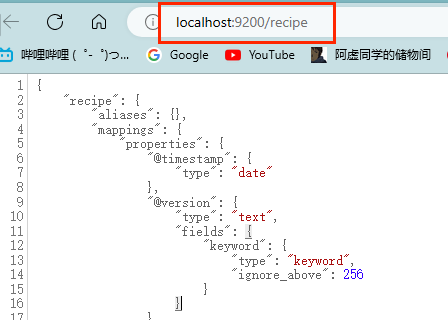
端口后面加上你新建的index(索引)的名称,可以校对一下里面的数据是否和实体类的一一对应
4. 用logstash将Elastic Search和mysql连接起来
4.1 : 下载配置
当所有配置完成后,代码也可以正常运行了,接口可以正常测试了
但是发现返回的什么都没有,原来是忘记了给es本身添加数据了,毕竟ES和MYSQL可没有连接到一起
那么如何往Elastic Search当中添加数据呢?
为了方便,可以使用logstash直接和数据库关联起来,logstash可以很方便的获取各个地方的数据源,并且导入到ES当中
下载地址:
Download Logstash Free | Get Started Now | Elastic
下载教程:
(152条消息) 安装 ElasticSearch 并连接mysql数据库_elasticsearch怎么和数据库关联_liyongbing1122的博客-CSDN博客
注意教程里面还需要下载一个mysql的JDBC驱动,自己去Oracle下载就好了,
下好后直接将jar包放入下载logstash的路径\logstash-7.17.3\logstash-core\lib\jars
(不过网上好像说也不一定要放这个位置,反正我是放了)
在logstash的bin目录下新建logstash-mysql.conf配置文件,感觉logstash本身就是面向各种数据源进行配置的
input { stdin { } jdbc { # 数据库 数据库名称为elk,表名为book_table jdbc_connection_string => "jdbc:mysql://localhost:3306/elk" # 用户名密码 jdbc_user => "admin" jdbc_password => "password" # jar包的位置 jdbc_driver_library => "/usr/elastic/logstash-6.5.3/mysql-connector-java-8.0.13.jar" # mysql的Driver jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_paging_enabled => "true" jdbc_page_size => "50000" #statement_filepath => "config-mysql/book.sql" statement => "select * from book_table" schedule => "* * * * *" #索引的类型 type => "book" } } filter { json { source => "message" remove_field => ["message"] } } output { elasticsearch { hosts => "127.0.0.1:9200" # elasticsearch当中你要用的那个index名,对应数据库的数据表 index => "recipe" # 需要关联的数据库中有有一个id字段,对应索引的id号 document_id => "%{id}" } stdout { codec => json_lines } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
4.2 运行
一开始以为一定要先用这条指令
./logstash -e 'input { stdin { } } output { stdout {} }'
- 1
但是这条一直无法运行
报错类似于 JAVA JDK的问题
一开始说不支持当前版本,8.0以前的已经弃用,然后要9.0以上的版本
然后现在又说
删掉了1.8的Java之后,变成如下报错
DEPRECATION: The use of JAVA_HOME is now deprecated and will be removed starting from 8.0.
- 1
接着我使用了logstash捆绑自带的jdk,然后放到环境变量LS_JAVA_HOME还是报错,
Using LS_JAVA_HOME defined java: D:\RookieCODE\Tools\LogStash\logstash-7.17.3\jdk
WARNING: Using LS_JAVA_HOME while Logstash distribution comes with a bundled JDK.
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
- 1
- 2
- 3
这里那不就是9.0也要弃用吗
然后其实换了捆绑的jsk之后
直接用数据库配置的命令就成功了
logstash -f logstash-mysql.conf
- 1
不过记得要先启动elasticsearch,然后再用上面的指令,即可正确导入数据
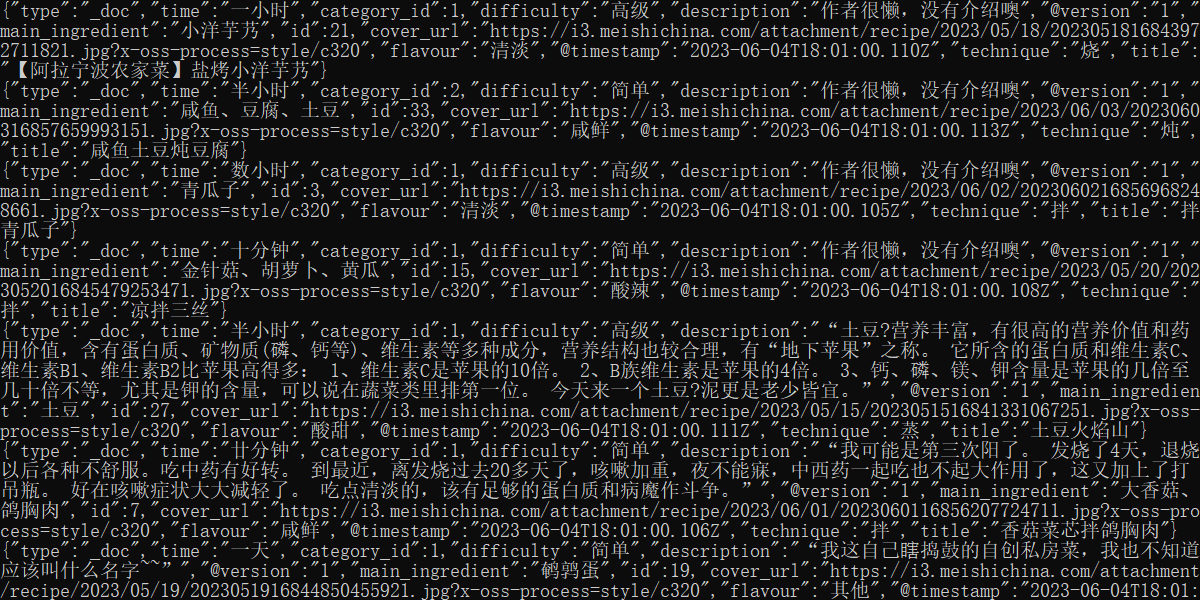
导入成功的话会有数据记录显示在控制台
如果没有更新那么重新运行程序也不会导入(即使你修改了config文件)
如果每次更新了数据库就重新在logstash的bin目录cmd下重新运行上面的那条配置指令即可
5. 总结
经过上面的步骤就配置完成了,运行成功后sprinboot的cmd如下

使用apifox进行测试
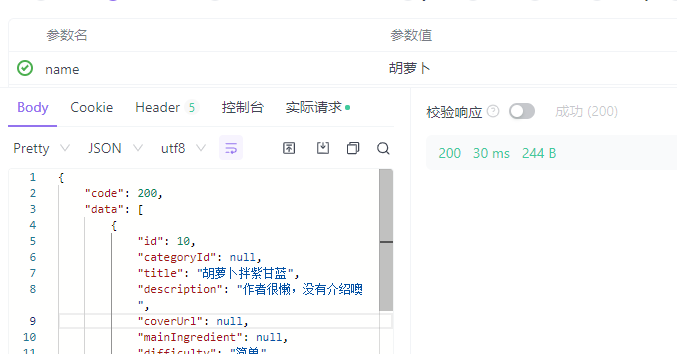
其实从零开始的话要配置的东西还是挺多的,也要查挺多文章,但是所幸elasticsearch和它的插件还有相关的工具的下载和安装并不麻烦(解压即可用),使用起来难度还是不高的。
当时搜了挺多文章的资料的,想着把他们整合到一起,希望能够帮助到需要的小伙伴。
d下重新运行上面的那条配置指令即可
5. 总结
经过上面的步骤就配置完成了,运行成功后sprinboot的cmd如下
[外链图片转存中…(img-sOj2CV5n-1685955517620)]
使用apifox进行测试
[外链图片转存中…(img-EwGGVFwu-1685955517620)]
其实从零开始的话要配置的东西还是挺多的,也要查挺多文章,但是所幸elasticsearch和它的插件还有相关的工具的下载和安装并不麻烦(解压即可用),使用起来难度还是不高的。
当时搜了挺多文章的资料的,想着把他们整合到一起,希望能够帮助到需要的小伙伴。

