
- 1Python中函数的参数定义和可变参数_python函数中的可变参数
- 2C++之最短路径算法(Dijkstra)_c++ 最短路径
- 3Android O 前期预研之二:HIDL相关介绍_export_generated_headers androidbp
- 4sqlserver 查询数据字段末尾存在空格 用等于号也会命中_sqlserver where 有空格和没空格
- 5已经会用stm32做各种小东西了,下一步学什么,研究stm32的内部吗?
- 6疲劳驾驶样本集_开车犯困怎么办?用TF机器学习制作疲劳检测系统
- 7Java实现WebSocket_java原生websocket的源码
- 8Android Studio中运行Android模拟器_android studio怎么运行模拟器
- 9android10.0(Q) 后台启动Activity白名单_background activity start [callingpackage:
- 10鸿蒙Harmony-数据持久化(Preferences)详解_鸿蒙preferences
python爬取链家房价消息_Python的scrapy之爬取链家网房价信息并保存到本地
赞
踩
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地。
先看链家网的源码。。房价信息 都保存在 ul 下的li 里面
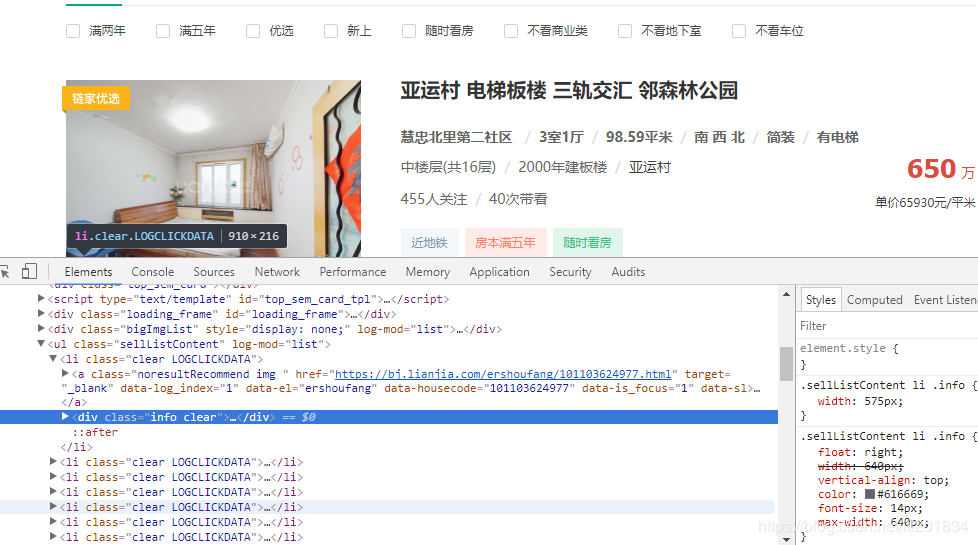
爬虫结构:
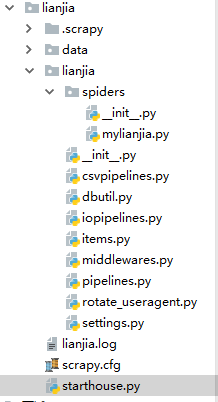
其中封装了一个数据库处理模块,还有一个user-agent池。。
先看mylianjia.py
#-*- coding: utf-8 -*-
importscrapyfrom ..items importLianjiaItemfrom scrapy.http importRequestfrom parsel importSelectorimportrequestsimportosclassMylianjiaSpider(scrapy.Spider):
name= 'mylianjia'
#allowed_domains = ['lianjia.com']
start_urls = ['https://bj.lianjia.com/ershoufang/chaoyang/pg']defstart_requests(self):for i in range(1, 101): #100页的所有信息
url1 = self.start_urls +list(str(i))#print(url1)
url = ''
for j inurl1:
url+= j + ''
yieldRequest(url, self.parse)defparse(self, response):print(response.url)'''response1 = requests.get(response.url, params={'search_text': '粉墨', 'cat': 1001})
if response1.status_code == 200:
print(response1.text)
dirPath = os.path.join(os.getcwd(), 'data')
if not os.path.exists(dirPath):
os.makedirs(dirPath)
with open(os.path.join(dirPath, 'lianjia.html'), 'w', encoding='utf-8')as fp:
fp.write(response1.text)
print('网页源码写入完毕')'''infoall=response.xpath("//div[4]/div[1]/ul/li")#infos = response.xpath('//div[@class="info clear"]')
#print(infos)
#info1 = infoall.xpath('div/div[1]/a/text()').extract_first()
#print(infoall)
for info ininfoall:
item=LianjiaItem()#print(info)
info1 = info.xpath('div/div[1]/a/text()').ex

