
- 1使用pycharm操作git_pycharm git
- 2wpf绘图第三方库livechart曲线颜色和宽度设置_lvgl chart的曲线宽度怎么设置
- 3Win11 下通过Anaconda安装tensorflow_anaconda win11安装tensorflow
- 4flutter开发中遇到的问题总结_expanded singlechildscrollview column 不显示
- 5uniapp app端跳转到应用商店
- 6nodejs里npm运行无响应解决_nodejs项目运行没有反应
- 7android开发中遇到的问题汇总【九】_cannot import 'getapplication', functions and prop
- 8域名和自定义DNS解析规则_域名解析规则
- 9Gradle入门_graddle allprojects mavenlocal mavencentral
- 10Android真机调试不打印日志解决方式
linux nvme ssd性能降低分析_linux固态磁盘性能差
赞
踩
本文简介:
由于linux内核版本升级(4.19到5.10),驱动移植完成后,测试发现ssd读性能下降了接近50%。经过blktrace、ftrace等一系列工具分析,确定在5.10内核中,dd命令所映射的物理地址超过了pcie的dma寻址范围,而内核使用了swiotlb来解决该问题,导致性能下降。本文主要讲如何分析与最终定位问题。
1. 问题描述
保证uboot,文件系统相同,只替换dtb与Image。测试命令如下:
mount /dev/nvme0n1p1 /disk
dd if=/dev/zero of=/disk/test.file bs=1M count=512 conv=fsync
echo 3 > /proc/sys/vm/drop_caches
dd of=/dev/null if=/disk/test.file bs=1M
- 1
- 2
- 3
- 4
在4.19版本linux kernel上测试下:
root@a1000:~# dd of=/dev/null if=/disk/test.file bs=1M
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 0.829908 s, 647 MB/s
- 1
- 2
- 3
- 4
在5.10版本linux kernel上测试下:
root@a1000:~# dd of=/dev/null if=/disk/test.file bs=1M
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 1.37402 s, 391 MB/s
- 1
- 2
- 3
- 4
2. 初步分析
2.1 strace
strace是一个可用于诊断、调试和教学的Linux用户空间跟踪器。我们用它来监控用户空间进程和内核的交互,比如系统调用、信号传递、进程状态变更等,分别用strace对4.19内核和5.10内核ssd测试命令进行追踪。
简单介绍下strace的安装与使用:
git clone https://github.com/strace/strace.git
cd strace/
./bootstrap
./configure --host=aarch64-linux-gnu --target=aarch64-linux-gnu --enable-mpers=no
make install
- 1
- 2
- 3
- 4
- 5
在4.19版本linux kernel上测试下:
root@a1000:~# dd of=/dev/null if=/disk/test.file bs=1M& [1] 490 root@a1000:~# ./strace -c -p 490 ./strace: Process 490 attached 2048+0 records in 2048+0 records out 2147483648 bytes (2.1 GB, 2.0 GiB) copied, 3.57607 s, 601 MB/s % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 99.54 1.414739 1333 1061 read 0.42 0.006031 5 1064 write 0.04 0.000534 76 7 7 openat 0.00 0.000027 9 3 close ------ ----------- ----------- --------- --------- ---------------- 100.00 1.421331 665 2135 7 total [1]+ Done dd of=/dev/null if=/disk/test.file bs=1M

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在5.10版本linux kernel上测试下:
root@a1000:~# dd of=/dev/null if=/disk/test.file bs=1M& [1] 443 root@a1000:~# ./strace -c -p 443 ./strace: Process 443 attached 2048+0 records in 2048+0 records out 2147483648 bytes (2.1 GB, 2.0 GiB) copied, 6.28807 s, 342 MB/s % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 99.30 2.286588 1418 1612 read 0.68 0.015602 9 1615 write 0.02 0.000533 76 7 7 openat 0.00 0.000032 10 3 close ------ ----------- ----------- --------- --------- ---------------- 100.00 2.302755 711 3237 7 total [1]+ Done dd of=/dev/null if=/disk/test.file bs=1M
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
对比可以看出,每次read系统调用的时间相差无几,此时怀疑dd命令中执行了其他操作导致时间增加。
2.2 dd命令
从官网下载dd源码,在代码各部分加上调试信息后重新编译,确定时间差异还是在read系统调用上(ps:strace统计的系统调用的时间为何和实际read之间存在差异,待后续追踪)。如下所示
do { process_signals (); read_before_time = gethrxtime (); nread = read (fd, buf, size); read_after_time = gethrxtime (); fprintf (stderr,"read time difference :%llu\n",read_after_time - read_before_time); /* Ignore final read error with iflag=direct as that returns EINVAL due to the non aligned file offset. */ if (nread == -1 && errno == EINVAL && 0 < prev_nread && prev_nread < size && (input_flags & O_DIRECT)) { errno = 0; nread = 0; } } while (nread < 0 && errno == EINTR);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
总结:分别在4.19 与 5.10 内核下,可以得出时间差异确实是在每次read系统调用中。
2.3 ftrace追踪系统调用
利用ftrace追踪系统调用,在内核打开ftrace相关的配置选项
cd /sys/kernel/debug/tracing/
echo 0 > tracing_on
echo nop > current_tracer
echo function_graph > current_tracer
echo funcgraph-tail > trace_options
echo ksys_read > set_graph_function
- 1
- 2
- 3
- 4
- 5
- 6
输入测试命令后’ ctrl-z ‘挂起该进程,记录pid号
dd of=/dev/null if=/disk/test.file bs=1M
- 1
讲对应的进程pid设置到set_ftrace_pid,开始追踪
echo 4838 > set_ftrace_pid
echo 1 > tracing_on
fg
- 1
- 2
- 3
这里贴出ftrace的部分内容:
4.19:
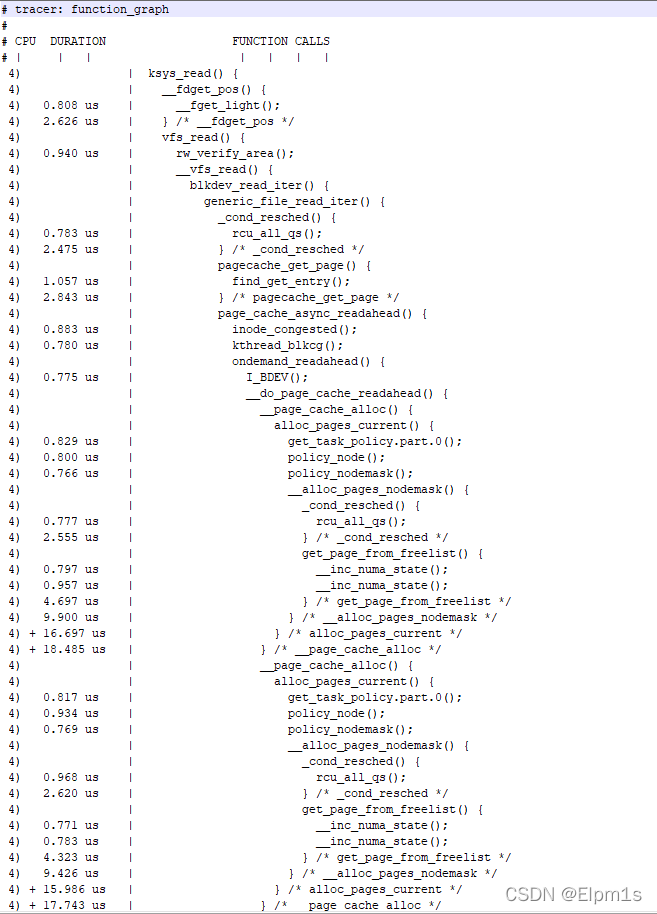
5.10:
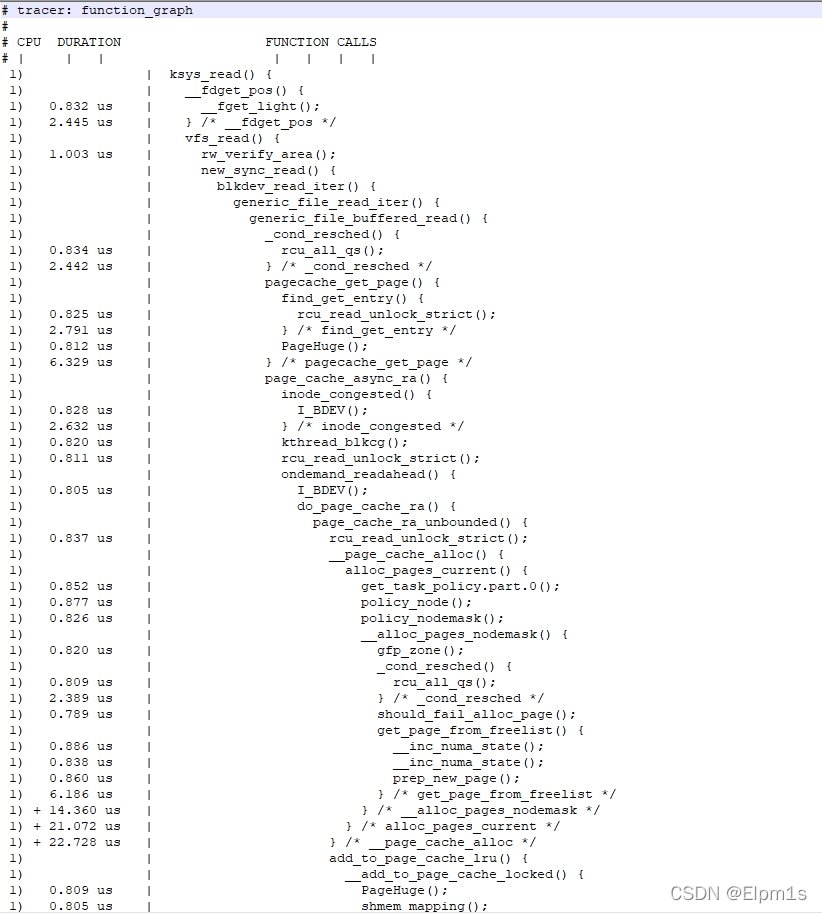
总结:由于整个read调用经历了文件系统 bio nvme驱动,过程较为复杂。4.19与5.10内核版本跨度较大,流程之间差异也较大。经过分析之后,并没有实际的发现(这里同2.4小节,分析不够仔细,此时的信息已经足够发现5.10内核使用了swiotlb,但在两个版本启动项中加入了swiotlb=force后发现速率皆下降,但4.19版本速率仍然更快,便没在没有深究,此时并没有去想5.10不使用swiotlb后速率是否会提升到同4.19)。
2.4 ftrace追踪系统调用(跳过文件系统与内存管理)
对上述read系统调用流程进行分析之后,决定对测试命令进行修改,采用
dd of=/dev/null if=/dev/nvme0n1p1 bs=1M count=512 iflag=direct
- 1
来跳过文件系统和内存管理的影响,测试数据如下:
在4.19版本linux kernel上测试下:
root@a1000:~# dd of=/dev/null if=/dev/nvme0n1p1 bs=1M count=512 iflag=direct
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 0.490441 s, 1.1 GB/s
- 1
- 2
- 3
- 4
在5.10版本linux kernel上测试下:
root@a1000:~# dd of=/dev/null if=/dev/nvme0n1p1 bs=1M count=512 iflag=direct
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 1.02014 s, 526 MB/s
- 1
- 2
- 3
- 4
在利用2.3小节ftrace对系统调用进行追踪,两个版本的部分截图如下:
4.19:
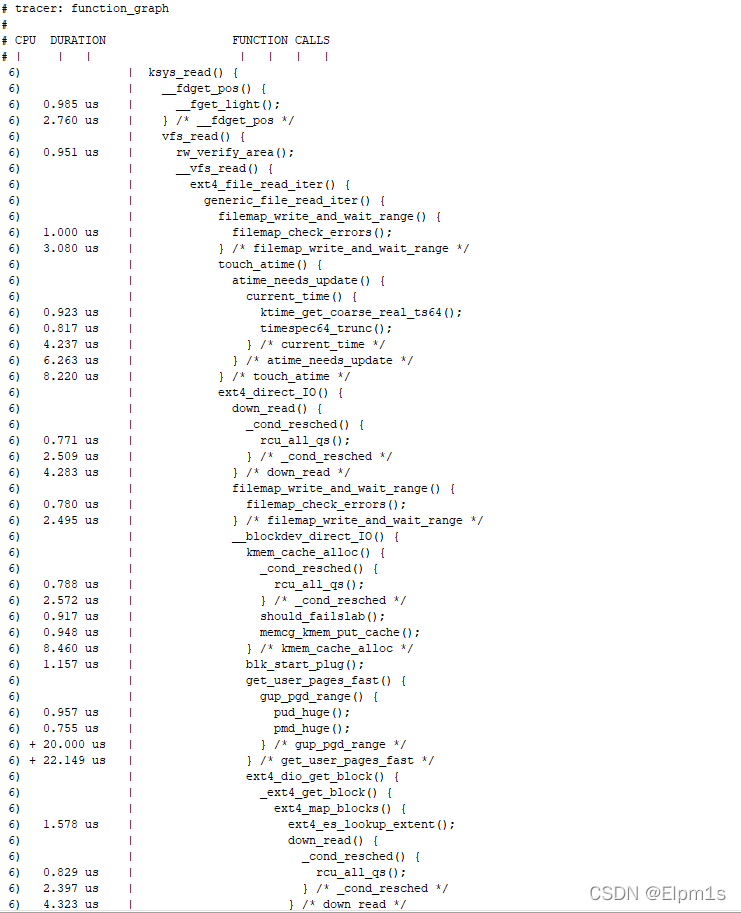
5.10:

2.5 blktrace
利用btt的分析结果如下:
4.19:
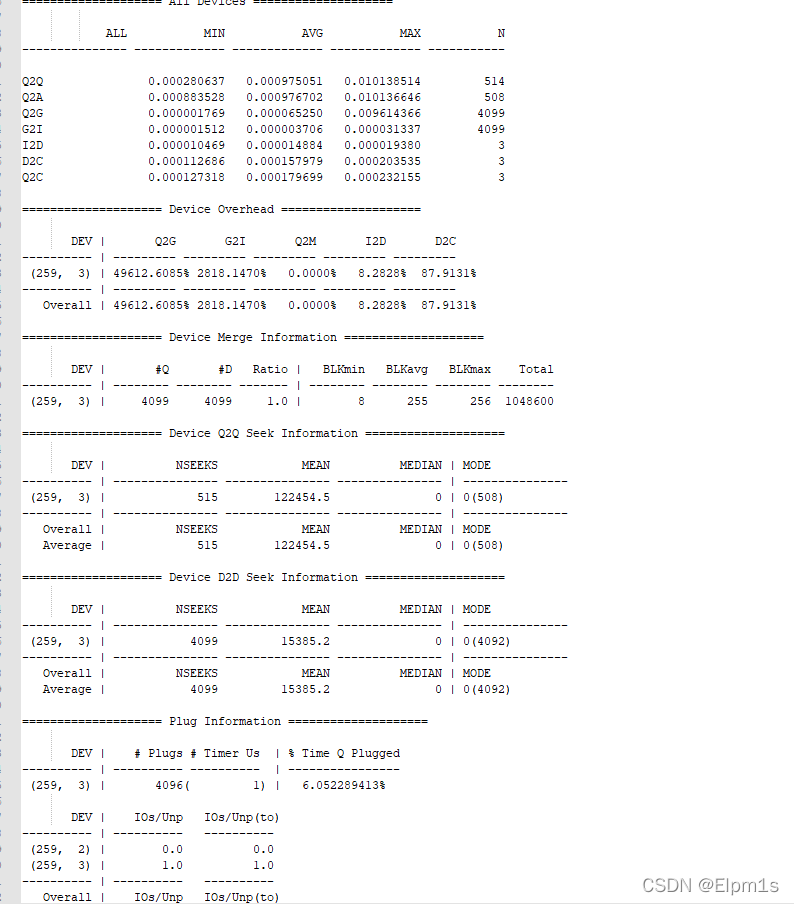
5.10:
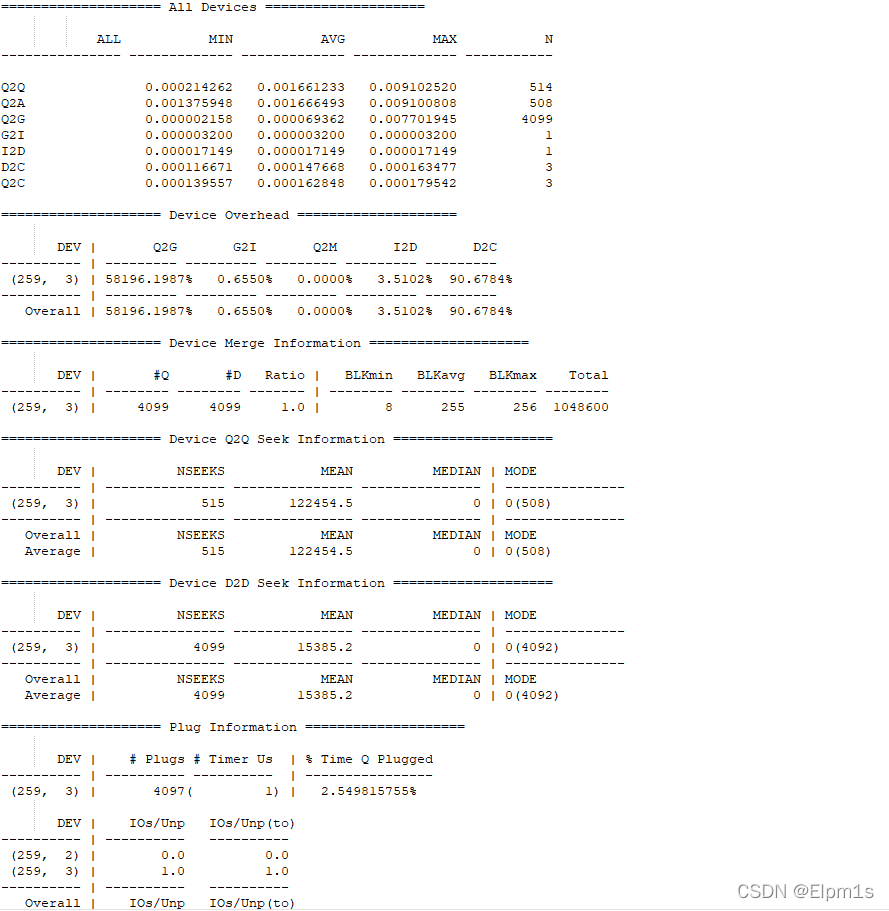
总结:一般重点需要关注d2c时间,又称service time,也就是反应块设备处理能力的指标。不知道什么原因,btt统计的d2c的次数很少,但是经过对blkpars源文件的分析及时间计算,发现5.10内核就是慢在d2c上。
2.6 ftrace分析d2c
D2C大概流程如下:
ISSUE ->IRQ --> ISR --> Kthread --> complete
在内核nvme/pci.c驱动中,添加打印信息,记录nvme写入命令,到触发中断时间(SSUE ->IRQ --> ISR --> Kthread)对比测出4.19与5.10耗时相同,此时可以定位到Kthread --> complete期间操作导致了5.10性能较低。
利用ftrace对整个流程进行分析:
cd /sys/kernel/debug/tracing
echo 0 > tracing_on
echo 1 > events/block/block_rq_issue/enable
echo 1 > events/block/block_rq_complete/enable
echo 1 > events/sched/sched_switch/enable
echo 'next_pid==177' > events/sched/sched_switch/filter #这个next_pid要根据情况更改
echo "((sector >= 0) && (sector <= 2048))" > events/block/block_rq_complete/filter
echo "((sector >= 0) && (sector <= 2048))" > events/block/block_rq_issue/filter
echo 177 > set_ftrace_pid
echo function > current_tracer
dd of=/dev/null if=/dev/nvme0n1 iflag=direct bs=1M count=10
echo 0 > tracing_on
echo 0 > events/enable
cp trace_pipe /userdata/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
此时ftrace出来的流程就较为简单,便于分析了
4.19:
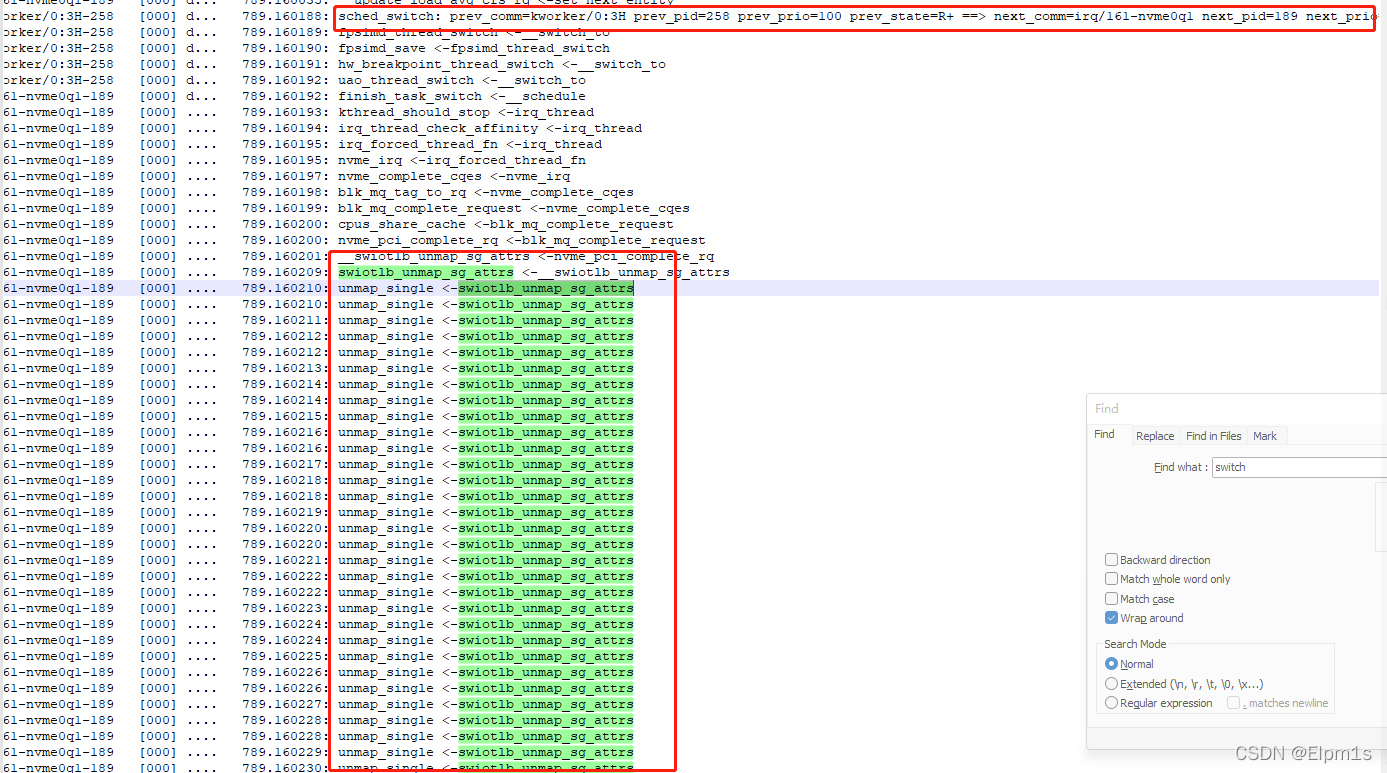
5.10:
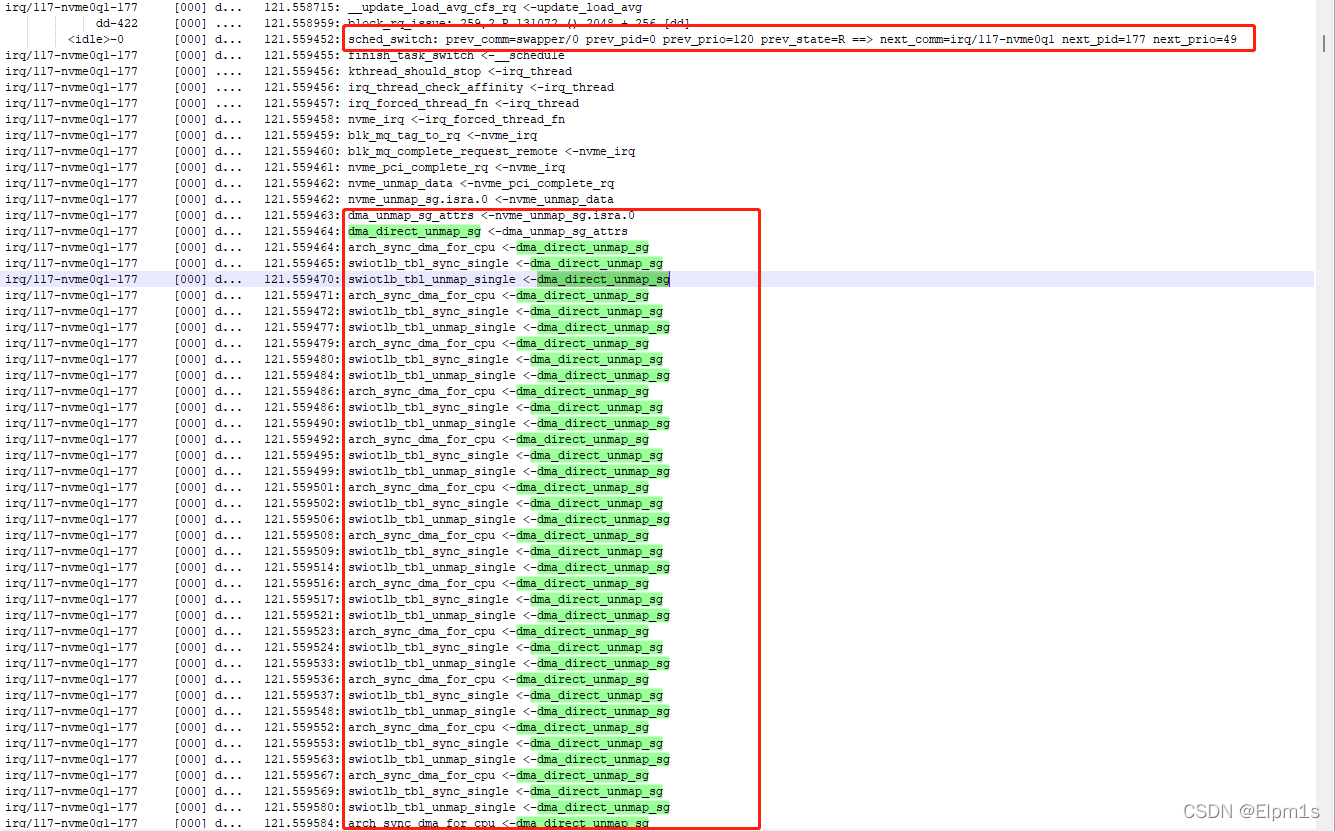
总结:此时经过无数的弯路,通过时间等比对,已经可以确定5.10内核性能下降的原因是使用了swiotlb,修改设备树中pcie节点的dma-ranges属性,扩大size。编译测试发现速率已经到达了4.19的同样水平。
3. 尝试过的其他方式
在此分析过程中还尝试过很多其他方式,在此记录一下
3.1 提升dd命令优先级
nice -n -20 dd of=/dev/null if=/dev/nvme0n1p1 bs=1M count=512 iflag=direct
- 1
3.2 更改nvme queue scheduler
root@a1000:~# cat /sys/block/nvme0n1/queue/scheduler
[none] mq-deadline kyber
root@a1000:~# echo mq-deadline > /sys/block/nvme0n1/queue/scheduler
root@a1000:~# echo kyber > /sys/block/nvme0n1/queue/scheduler
- 1
- 2
- 3
- 4
3.3 更改nvme queue read_ahead_kb
root@a1000:~# cat /sys/block/nvme0n1/queue/read_ahead_kb
128
root@a1000:~# echo 1024 > /sys/block/nvme0n1/queue/read_ahead_kb
- 1
- 2
- 3
3.4 使用threadirq
setenv bootargs '.......... threadirq'
- 1
3.5 更改transparent_hugepage
echo always > /sys/kernel/mm/transparent_hugepage/enabled
- 1
3.6 top,iostat等性能工具分析
3.7 使用nosmp排除多核影响
setenv bootargs '.......... nosmp'
- 1
3.8 更改nvmeq中断数量(drivers/nvme/host/pci.c)
for (i = dev->online_queues; i <= 1; i++) {
bool polled = i > rw_queues;
ret = nvme_create_queue(&dev->queues[i], i, polled);
if (ret)
break;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.9 将kworker替换dd
对event ftrace分析过程中,还发现5.10用dd去发block_rq_issue,也总是会比4.19用kworker去发block_rq_issue,要慢一些。修改源码使其强制走该分支
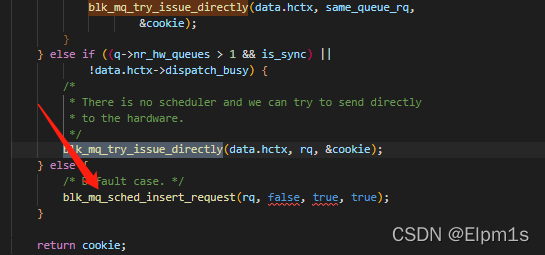
3.10 cpu isolation
setenv bootargs '......... isolcpus=3'
- 1
先让这个cpu3隔离出来啥也不跑,然后把中断和dd一起绑到这个cpu来跑,引用:宋宝华:谈一谈Linux让实时/高性能任务独占CPU的事
4. nvme command执行流程


