
- 1【桥接模式】VMware虚拟机配置桥接模式_oracle vm虚拟机设置桥连
- 2净现值NPV分析_npv净现值分析
- 3贷款核算规则_借据账龄
- 41.Entity Framework Core 5.0教程,概述和准备_entityframework 5.0.0使用
- 5mysql关于utf8_unicode_ci与utf8mb4_unicode_ci的区别_utf8mb4_general_ci和utf8字符长度
- 6怎么用SPSS分析三组数据的差异是否显著?_组间差异分析spss
- 7C# 8.0 可空(Nullable)给ASP.NET Core带来的坑_suppressimplicitrequiredattributefornonnullableref
- 8软件发布版本命名规则_b发布版本是正式版吗
- 9sql注意_分页和排序谁在前
- 10uniapp实现筛选栏吸顶和点击筛选条件回到顶部的需求_hm-filterdropdown
Google开源OCR项目Tesseract安装版在Windows下的使用测试记录_google ocr
赞
踩
图像处理开发需求、图像处理接私活挣零花钱,请加微信/QQ 2487872782
图像处理开发资料、图像处理技术交流请加QQ群,群号 271891601
开源OCR项目有很多,给大家一个链接,这个链接列出了现有的比较出名的OCR开源项目,链接如下:
https://en.wikipedia.org/wiki/Comparison_of_optical_character_recognition_software
从上面的排名可以看到,Tesseract是排在第一名的,所以咱们就先研究和测试它吧!
首先下载Tesseract在Windows下的安装版。(因为在国外访问不了谷歌,所以我翻墙下载了下来,这里给大家百度网盘链接)
tesseract-ocr-setup-3.02.02.exe_免费高速下载|百度网盘-分享无限制
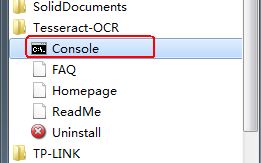
下载下来之后一路Next安装好,然后在开始菜单找到其控制台引导程序,如下图所示:
上面的安装包里自带了已经训练好的英文-拉丁文识别数据~所以我们先来测试一下英文字符的识别吧~识别图像如下:

上面这幅图片的下载链接:03.jpg_免费高速下载|百度网盘-分享无限制
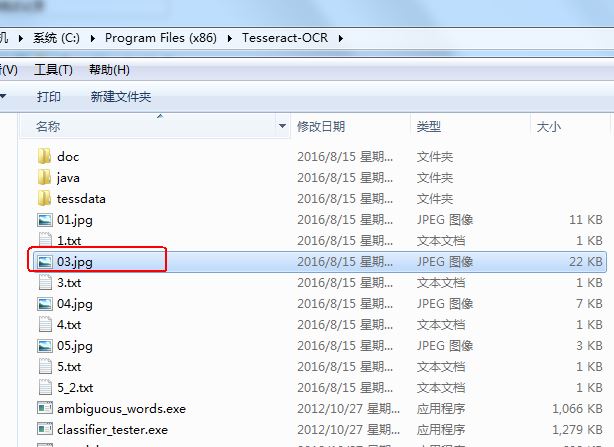
把上面的图片放到Tesseract的安装目录下,如下图所示:
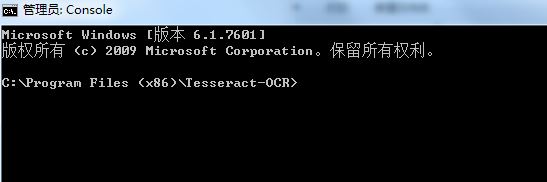
然后打开上面提到的控制台窗口,如下图所示:
在窗口中输入命令:“tesseract.exe 03.jpg 3”,并回车,如下图所示:

解释一下:03.jpg代表待识别的源文件,3代表输出文件名,默认输出格式是txt文件格式!
如果你不知道命令的参数格式,可以像下面这样查询:
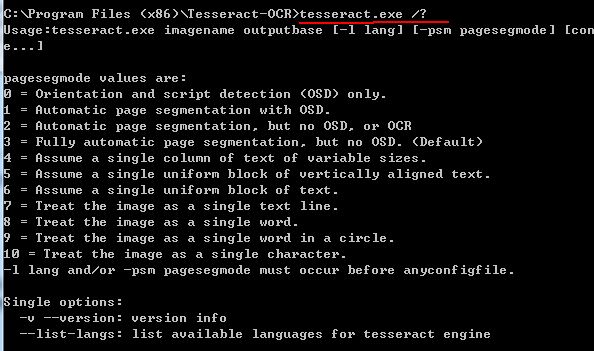
注意,上面的 lang之前是-l 而不是-1!
输入命令“tesseract.exe 03.jpg 3”后,在安装目录下生成了3.txt文件,这是识别结果,如下图所示:
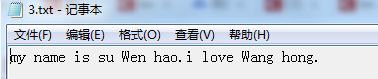
可见,对英文字符的识别率还是挺不错的。
接下来,我们测试下对中文的识别。首先要把中文训练数据放到目录C:\Program Files (x86)\Tesseract-OCR\tessdata 下边,如下图所示:
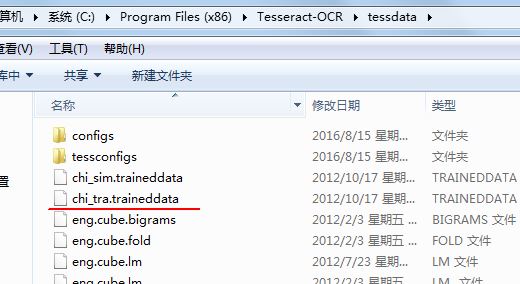
图片中的chi_tra.traineddata下载链接:tesseract-ocr-3.02.chi_tra.tar.gz_免费高速下载|百度网盘-分享无限制
然后在目录中放入测试图片04.jpg 05.jpg 这两幅图的下载链接为:04.jpg_免费高速下载|百度网盘-分享无限制
如下图所示:


然后在CMD窗口中分别输入如下命令:
tesseract.exe 04.jpg 5 -l chi_tra
tesseract.exe 05.jpg 5_2 -l chi_tra
运行结果如下图所示:
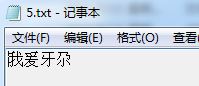
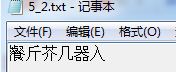
可见,结果非常不理想,所以接下来的任务就是要研究怎样提高识别率了,当然这是后话了,本文就先写到这样!

