
- 1【sentry 到 ranger 系列】二、Sentry 的 Hadoop 鉴权插件
- 2常见的USB VID_vid 046b
- 3Locale 及Locale.getDefault()
- 4VUE实现轮播图案例_vue轮播图案例
- 5基于javaweb的宠物服务商城系统设计与开发_基于javaweb的宠物店业务管理系统的设计与实现
- 6微信公众平台测试号申请、使用HBuilder X与微信开发者工具实现授权登陆功能以及单点登录
- 7SQL语句,索引视图,存储过程与触发器_创建数据库,表,视图,索引,触发器,存储过程的关键语句是什么?
- 8生成3d模型的ai工具_user 有没有能根据三视图生成三维模型的ai
- 9GsonFormat插件使用报错 String index out of range -1_gsonformat报错
- 10PS CC2018 命令大全
200字带你看完一本书,GPT-3已经会给长篇小说写摘要了_怎么让gpt拆书稿
赞
踩
现在,AI能帮你200字看完一段12万词的长篇小说了!
比如这样一段121567词的《傲慢与偏见》原文:
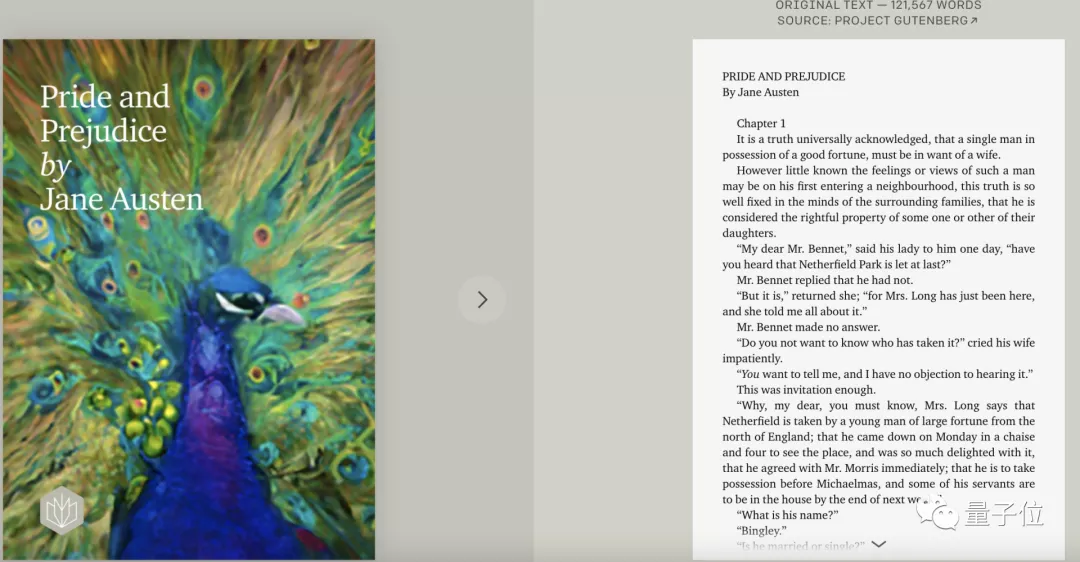
△图源OpenAI官网
AI分四个阶段来总结:
先把原文总结成276个摘要(24796词),然后进一步压缩成25个摘要(3272词),再到4个摘要(475词)。
最终得到一段175词的摘要,长度只有原片段的千分之一:

粗略翻译下看看,关键的几个情节都点到了:

这理解力,不禁让人望着某泡面压留下了泪水。
这就是OpenAI最新推出的能给任意长度书籍写摘要的模型。
平均10万词以上的训练文本,最终能压缩到400字以内。
而且这也是源自OpenAI精妙的刀法:没错,就是把GPT-3数据集里的书籍/小说部分抽出来进行训练所得到的模型。
话不多说,一起来看看这个微调版的GPT-3模型。
递归任务分解
首先,现将“总结一段文本”这一任务进行算法上的分解。
如果该文本足够短,就直接进行总结;如果它比较长,就把文本分成小块,并递归地对每一块进行总结。
这就形成了一棵总结任务树:
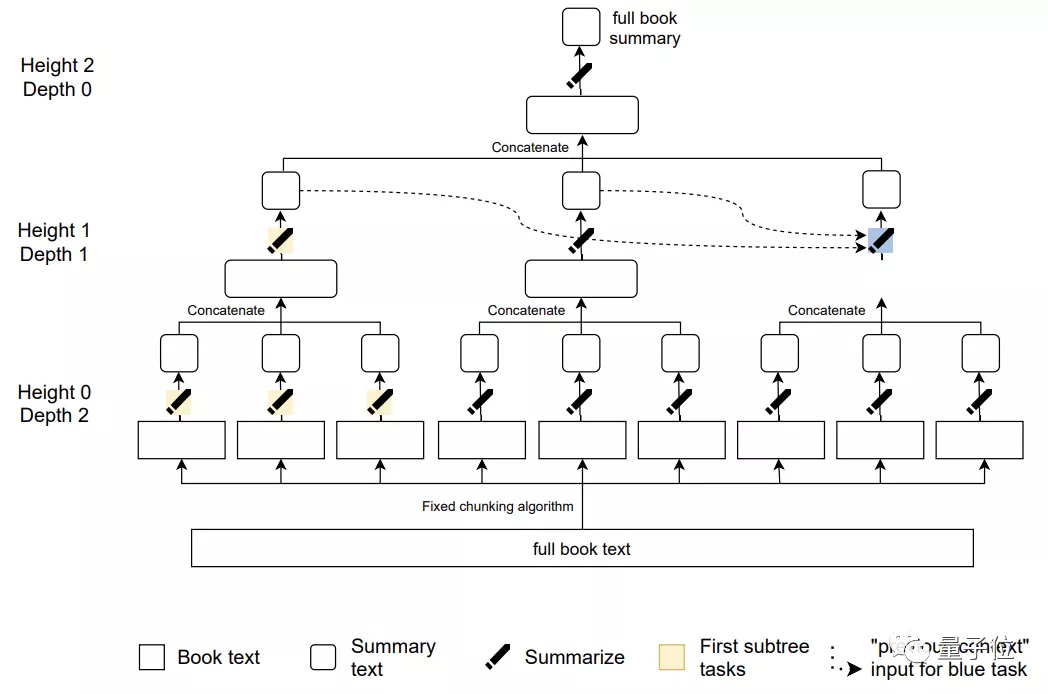
其中只有叶子任务会对书籍中的原始文本进行操作。
并且,已生成的摘要应该放在同一深度,并按照顺序串联起来。
比如上图中的蓝色任务的先前总结输出就用虚线来表示,这样,每一个摘要都是自然地从上一层任务(前文)流出,以保证那些相距较远的段落能够真正地“联系上下文”。
接下来开始训练:
- 根据上述的任务树将书籍和其子摘要递归为任务;
- 从树上抽出一个节点,对应一个带训练的总结任务;
- 获得训练数据,给该节点以输入;
- 使用训练数据对模型进行微调。
其中,所有训练数据都来自GPT-3中的书籍部分。
研究人员会跳过非叙事性书籍,尽量选择小说类(平均包含超过10万个单词),因为这些上下文关联性更强的文本对总结任务来说更难。
这一训练过程可以使用新的模型、不同的节点采样策略、不同的训练数据类型(演示和比较)来迭代。
对于演示用的数据,使用标准的交叉熵损失函数进行行为克隆(BC)。
对于比较数据,则通过强化学习(RL)来对抗一个专为人类偏好而训练的奖励模型。
强化学习也有三种变体的抽样任务:
- 全树
- 第一棵子树
- 第一片叶子
训练完成后进行总结,任务的最终目的是追溯出叙述的时间线和整体主题。
每个摘要子任务的目标是将文本压缩5到10倍,长度上限为128到384个符号。
优于现有同类模型
实验阶段,研究人员使用了Goodreads 2020榜单上的40本最受欢迎的书籍,其中囊括了幻想、恐怖、爱情、推理等近20个类型。
然后让两名人类研究员和模型同时进行总结,要求双方的摘要质量的一致性接近于80%。
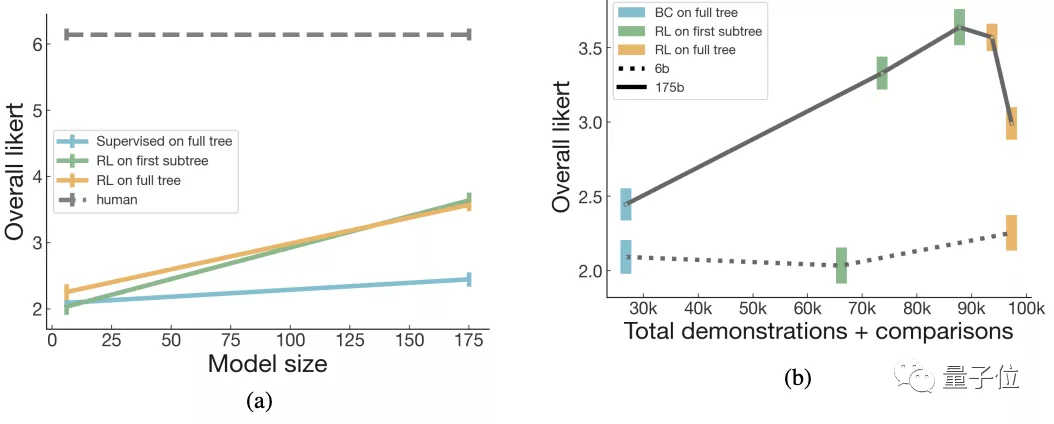
模型规模分为175B和6B两种,且训练模式也分为上述的强化学习的三种变体任务。
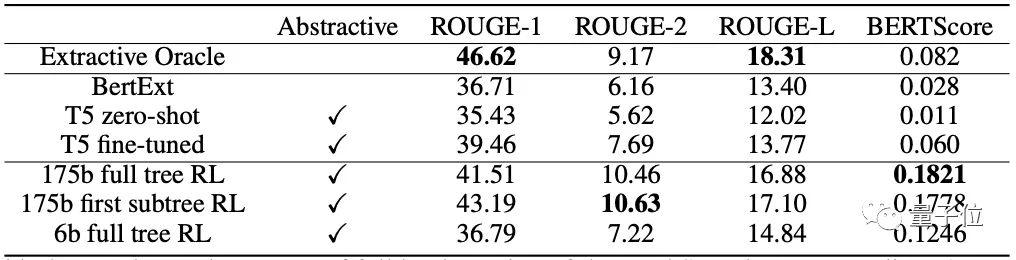
最后结果中,可以看到第一棵子树RL和全树RL的总结任务最接近于人类的水平:
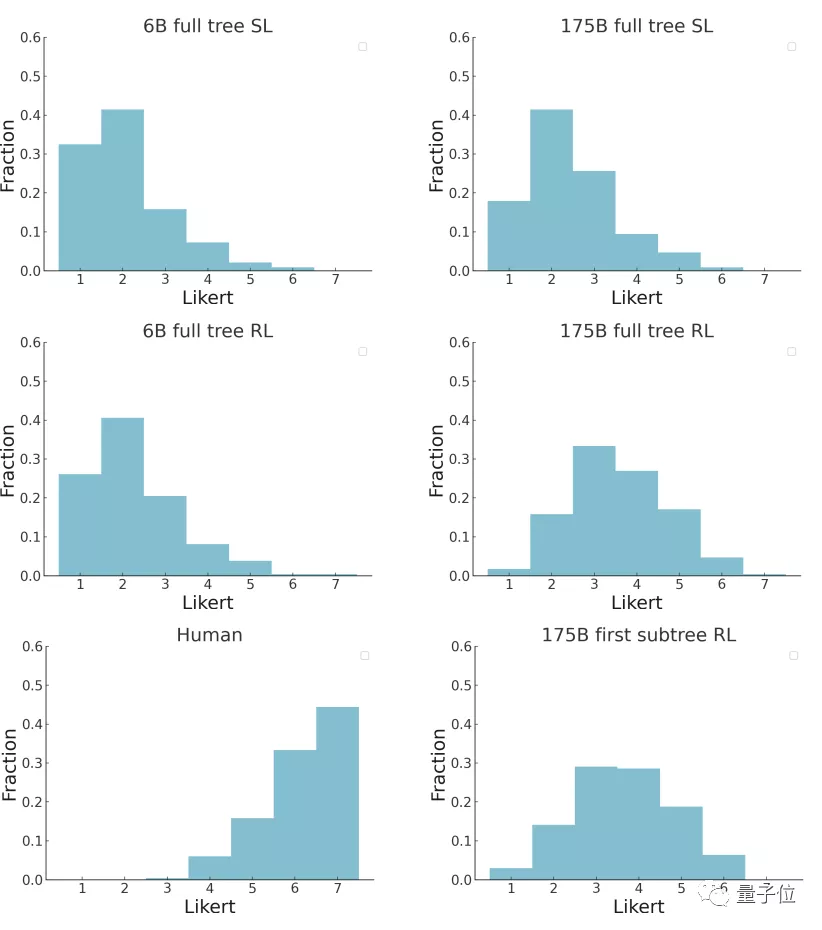
并且,也有超过5%的175B模型的摘要被打到了6分(满分7分),超过15%的摘要被打到5分:
研究团队也在最近提出的BookSum数据集上进行了测试,结果比现有的长文本总结模型更好:
除此之外,摘要是否能用来回答关于原文的问题也是评估方法之一。
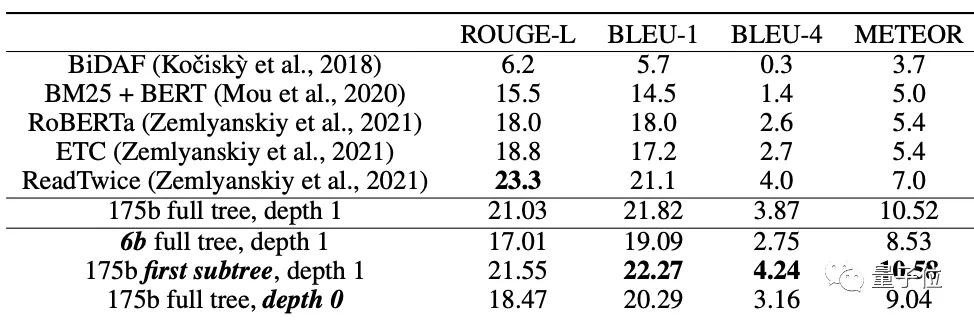
因此,团队将他们的总结模型应用于NarrativeQA问题回答数据集,可以看到,虽然没有经过明确的问题回答训练,但在所有的指标上都获得了最好的结果:
作者介绍
这篇研究出自OpenAI的 OpenAI Alignment team,他们表示,目前没有开源此模型的计划。
论文一作Jeff Wu本硕都毕业于麻省理工大学,在加入OpenAI之前有过在谷歌工作的经历。

共同一作Long Ouyang本科毕业于哈佛大学,博士则毕业于斯坦福大学的认知心理学专业,主要研究领域为认知科学与概率规划研究。

论文:
https://arxiv.org/abs/2109.10862
OpenAI官网介绍:
https://openai.com/blog/summarizing-books/
参考链接:
https://venturebeat.com/2021/09/23/openai-unveils-model-that-can-summarize-books-of-any-length/
— 完 —

