
- 1如何模拟微信小程序请求code_微信小程序code伪造
- 2前端面试题——实际遇到_dav面试题
- 3Android之android.os.DeadObjectException原因_system.err: android.os.deadobjectexception
- 4html5有向图连接,jquery使用echarts实现有向图可视化功能示例
- 5Chat GPT [Free]_freechatgpt
- 6随机森林如何评估特征重要性_随机森林 特征重要性
- 7HTTP性能压测工具wrk应用实战
- 8【实战】使用Bert微调完成文本二分类_bert+adapter二分类
- 9OCR表格识别(三)——文本检测与文本识别理论学习_ocr 检测和识别的区别
- 10LeetCode 刷题系列 -- 143. 重排链表_重新排序为:l0→ln→l1→ln-1→l2→ln-2→…
使用OpenVINO实现人体动作识别
赞
踩
Paula Ramos著 张晶 译
目录
1.1 人体动作识别背景简介
自从我在英特尔开始我的旅程以来已经有几个月了,我很高兴能与大家分享我一直在做的事情。今天,我将带你浏览我的第一个关于人体动作识别的OpenVINOTM Notebook。我希望你喜欢它,并且可以将它应用到你正在进行的开发中。
在本博客中,您将了解如何使用 OpenVINO™ 工具套件以同步的方式进行实时人体动作识别。
人体动作识别是一种 AI 功能,可以在录制或实时视频中查找和分类大量活动。例如:如果您有大量的家庭视频收藏,并且想要找到特定的记忆,如图1.1所示,那么人体动作识别是最简单、最快的方法。
传统方法需要您花费大量精力和时间手动查看您拥有的每个视频,直到找到合适的视频。使用人体动作识别,您可以训练 AI 模型根据录制的活动为您自动分类和组织您的视频,从而在几秒钟内更轻松地找到和访问您最珍贵的记忆。

图1.1 珍贵的家庭回忆
人体动作识别也可以应用于制造业等企业。例如:为工人提供一种保证他们工作安全的解决方案,该方案能够识别工人正在执行任务和工人手势,并提醒管理人员可能存在的潜在危险。
这只是人体动作识别的几个应用场景。在接下来的几年里,我希望在这个领域看到更多新的和令人兴奋的应用案例。在运行这个OpenVINOTM Notebook后,若能激发您想到还有其它领域可以从人体动作识别功能中受益,请告诉我们。现在,让我们开始吧。
1.2 OpenVINOTM Notebook简介
OpenVINOTM Notebook是开源免费的一系列Jupyter Notebook格式的OpenVINO TM范例程序。本文对应的OpenVINOTM Notebook范例是Live Action Recognition with OpenVINO™,如图1-2所示。

图1-2 Live Action Recognition with OpenVINO™
Live Action Recognition with OpenVINO™基于DeepMind Kinetics-400人体动作视频数据集,它总共包含 400 个动作,包括
- 人的动作(例如,写作、喝酒、大笑)
- 人与人的动作(例如,拥抱、握手、玩耍)扑克)
- 人与物体的动作(骑摩托车、洗衣服、吹气球)
您还可以区分一组亲子互动,例如:编辫子或梳头、萨尔萨舞或机器人跳舞,以及拉小提琴或吉他,如图1.2所示。

图1.2 人体动作识别
有关标签和数据集的更多信息,请参阅“The Kinetics Human Action Video Dataset”研究论文。
您可以使用普通计算机运行此OpenVINOTM Notebook范例程序,无需硬件加速器。使用 OpenVINOTM 工具套件的好处在于:它设计为在边缘工作,因此可以针对边缘运行,优化您的AI模型,以便在GPU、CPU 或VPU上高效运行。
您可以使用各种视频源,例如:来自 URL、本地存储的文件或网络摄像头源。
1.3 动作识别模型简介
本文使用Open Model Zoo的Action Recognition模型库,它提供了各种各样的预训练深度学习模型和演示应用程序。本文使用的模型 action-recognition-0001,这是一个基于 Video Transformer,具有 ResNet34 架构的模型,如图1.3所示。
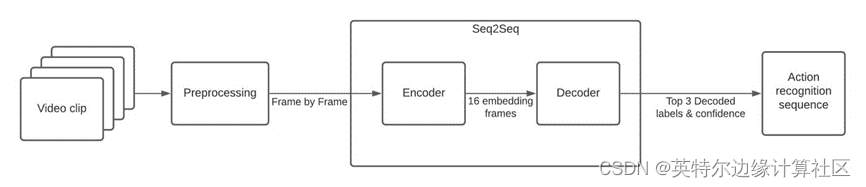
图1.3 人体行为识别模型流程图
action-recognition-0001模型含两个关键组件:
- 编码器,基于 PyTorch 框架,输入形状为 [1x3x224x224],表示批尺寸大小为1,颜色通道为3,图像尺寸为 224 x 224 像素;输出形状为 [1x512x1x1],表示内嵌的已处理帧。
- 解码器,同样基于 PyTorch 框架,输入形状为 [1x16x512],表示批尺寸大小为1,一秒内处理 16 帧,内嵌数据为 512。
我选择每秒 16 帧进行分析——因为这是Kinetics-400 作者找到类别分数的平均帧数。如图1.2中的 GIF 所示,对帧进行预处理以及分析中心裁剪的图像。
编码器和解码器都创建了一个序列到序列 (Seq2Seq) 系统来识别 Kinetics-400 数据集的人体动作。由于没有过量的标注信息,模型性能是最好的,它可以帮助我们理解处理工作流程
了解了上述基础信息后,您可以按照以下步骤开始识别您自己的视频:
- 准备OpenVINO Notebooks运行环境。
- 准备您的视频源、网络摄像头或视频文件以及您想要检测的常见活动。考虑通过检查数据集标签来检测动作名称。
- 在您的计算机上打开一个 Jupyter Notebook。该Notebook可以在 Windows、MacOS 和 Ubuntu 下通过不同的互联网浏览器运行。
1.4 实现实时动作识别
现在,我将向您展示如何使用 OpenVINO™ 实现实时动作识别。
1.4.1 下载模型
我们使用 Open Model Zoo 工具,例如:omz_downloader,来下载Open Model Zoo中的预训练模型。omz_downloader是一个命令行工具,可以自动创建目录结构并下载选定的模型。
使用omz_downloader工具下载 Open Model Zoo的“action-recognition-0001”模型,如图1.4所示。

图1.4 下载action-recognition-0001模型
1.4.2 初始化模型
在执行推理计算前,需要先初始化推理引擎,然后从模型文件中读取网络和权重,并将模型加载到所选设备(本文例子中是 CPU)上,最后获取模型的输入和输出节点,如图1.5所示。

图1.5 初始化模型
1.4.3 辅助函数
您需要一些辅助函数来帮您将执行结果可视化,例如:创建一个以裁剪为中心的 ROI,调整图像大小,并在每一帧中放置文本信息。
1.4.4 AI函数
这里将依次实现AI推理计算。
第一步: 在运行编码器之前对每帧图像进行预处理(预处理)。在将帧传入编码器之前,请先准备好图像:
- 将图像放缩到编码器输入尺寸,即[224,224]
- 将放缩后的图像进行中心裁剪,并使其长宽相等
- 将颜色通道从HWC变为CHW
具体代码实现,如图1.6所示。

图1.6 图像预处理
第二步,执行编码器模型推理计算。encoder()函数调用已编译模型(compiled_model),执行推理计算,然后从输出节点提取推理计算结果,并以列表形式以供解码器使用,如图1.7所示。

图1.7 执行编码器模型推理计算
第三步,执行解码器模型推理计算。decoder()函数将来自编码器输出的16帧的嵌入层连接在一起,然后转置数组以匹配解码器输入尺寸。它调用已编译好的解码器模型 (compiled_model_de),提取 logits,并将logits标准化以获得沿指定轴的置信度值。最后,它将最高概率解码为相应的标签名称,如图1.8所示。

图1.8 执行解码器模型推理计算
1.4.5 完整执行整个程序
现在,我们可以直接执行整个完整的人体动作识别程序。
Human Action Recognition with OpenVINO™程序链接:openvino_notebooks/403-action-recognition-webcam.ipynb at main · openvinotoolkit/openvino_notebooks · GitHub
首先,选择您要为其运行完整工作流程的视频。
- video_file = "https://archive.org/serve/ISSVideoResourceLifeOnStation720p/ISS%20Video%20Resource_LifeOnStation_720p.mp4"
- run_action_recognition(source=video_file, flip=False, use_popup=False, skip_first_frames=600)
然后,选择网络摄像头并再次运行完整的工作流程。
run_action_recognition(source=0, flip=False, use_popup=False, skip_first_frames=0) 恭喜!你已经做到了。我希望您发现这个主题对您的应用程序开发有趣和有用。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

