
热门标签
热门文章
- 1解决Ajax/Axios请求下载无效的问题_axios请求文件不下载
- 2【HarmonyOS】鸿蒙开发之Button组件——第3.4章_harmonyos button icon
- 3unity 协程(IEnumerator)开启与关闭_unity 取消协程 ienumerator
- 4mybatis-动态sql语句-if用法_mybatis if函数
- 5梅科尔工作室——HarmonyOS应用开发培训一_device manager remote emulator
- 6备份和还原ubuntu开发环境【方法一:直接复制整个系统文件】_unbuntu copy 整个文件
- 7深度学习中的epochs,batch_size,iterations详解_深度学习 epochs
- 8Unity-shader学习笔记(五)_shader saturate归一化 uv坐标
- 9LINUX 内存与I/O访问
- 10微信早安,利用uniCloud阿里云的云函数实现定时推送_unicloud公众号推送天气
当前位置: article > 正文
主流大语言模型的技术原理细节
作者:Cpp五条 | 2024-03-22 15:05:10
赞
踩
主流大语言模型的技术原理细节
1.比较 LLaMA、ChatGLM、Falcon 等大语言模型的细节:tokenizer、位置编码、Layer Normalization、激活函数等。2. 大语言模型的分布式训练技术:数据并行、张量模型并行、流水线并行、3D 并行、零冗余优化器 ZeRO、CPU 卸载技术 ZeRo-offload、混合精度训练、激活重计算技术、Flash Attention、Paged Attention。3. 大语言模型的参数高效微调技术:prompt tuning、prefix tuning、adapter、LLaMA-adapter、 LoRA。
0. 大纲

1. 大语言模型的细节
1.0 transformer 与 LLM
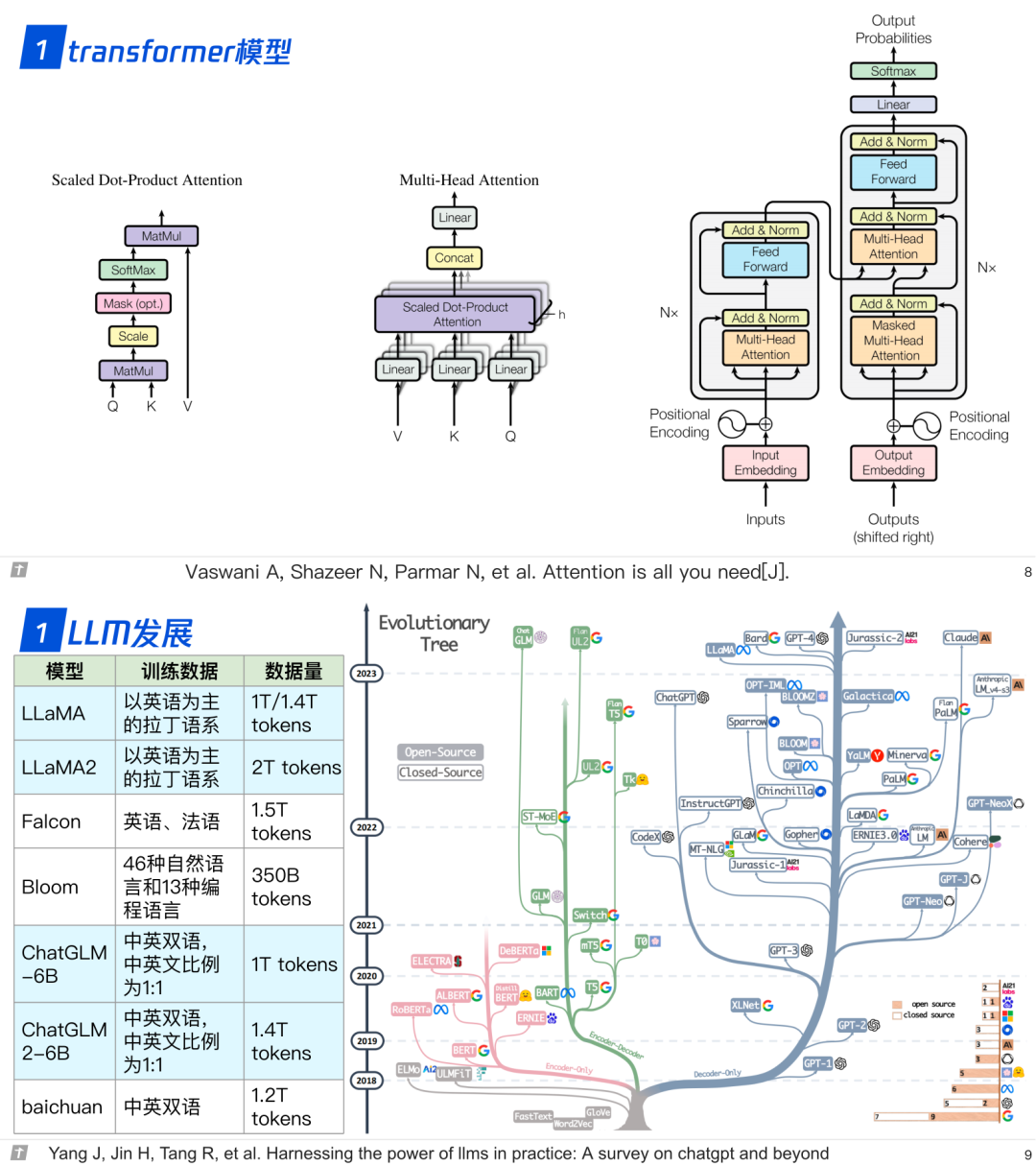
1.1 模型结构

1.2 训练目标

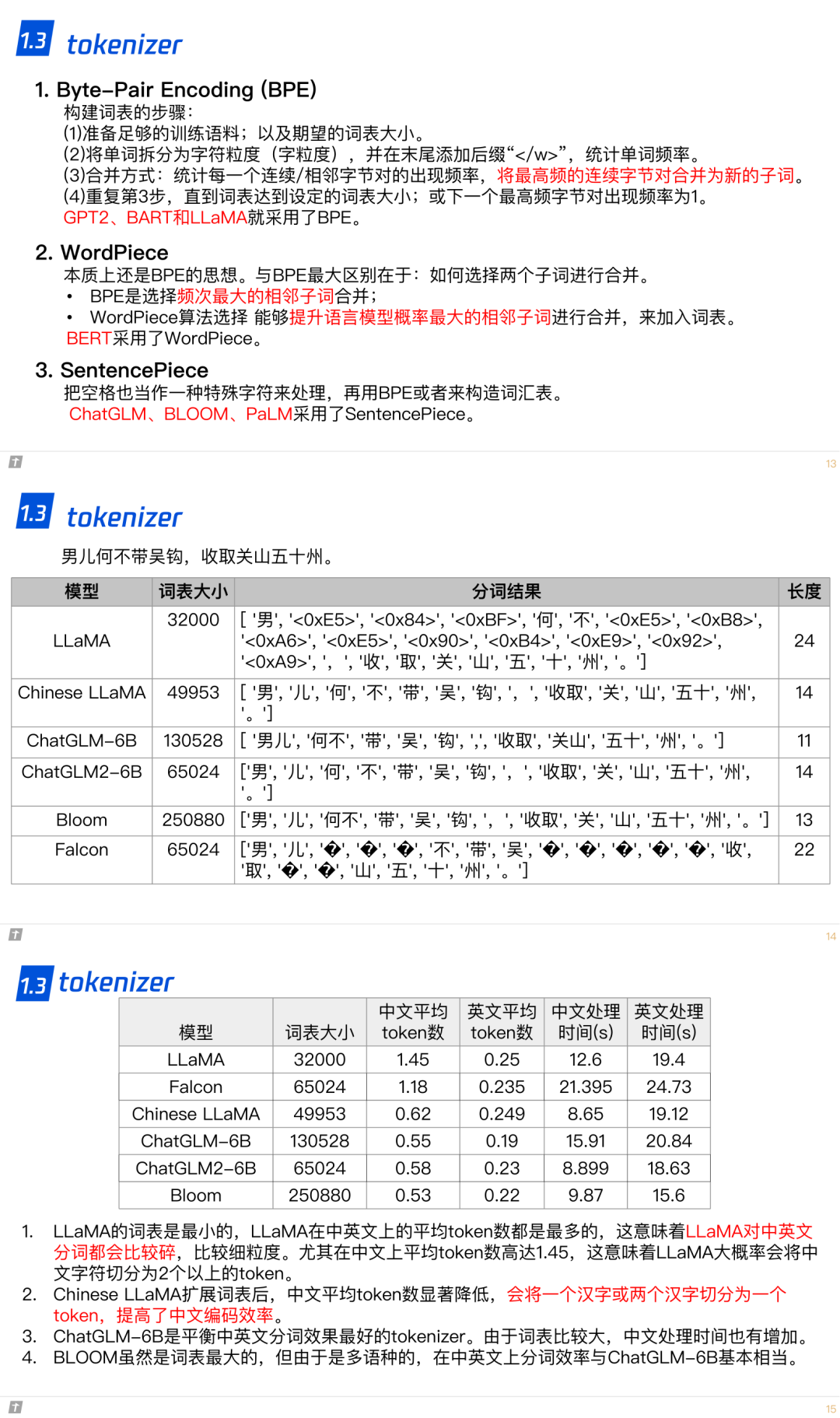
1.3 tokenizer
1.4 位置编码

1.5 层归一化

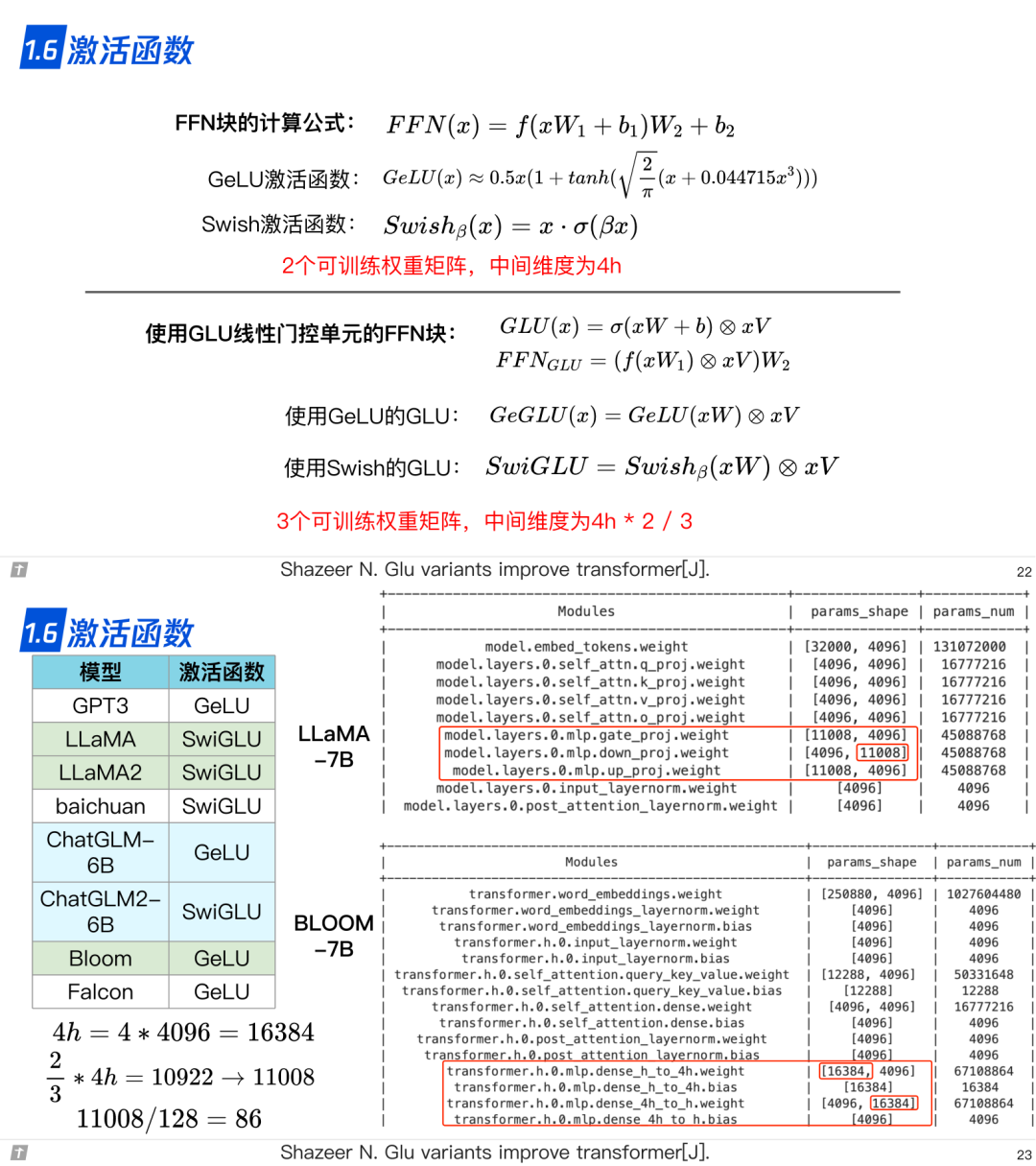
1.6 激活函数
1.7 Multi-query Attention 与 Grouped-query Attention

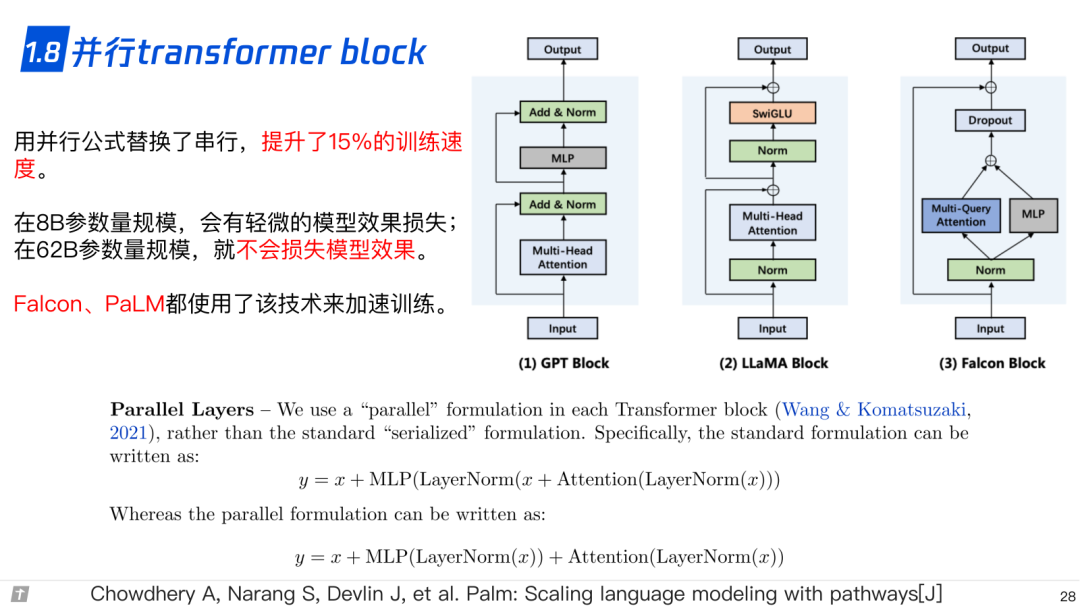
1.8 并行 transformer block
1.9 总结-训练稳定性

2. LLM 的分布式预训练

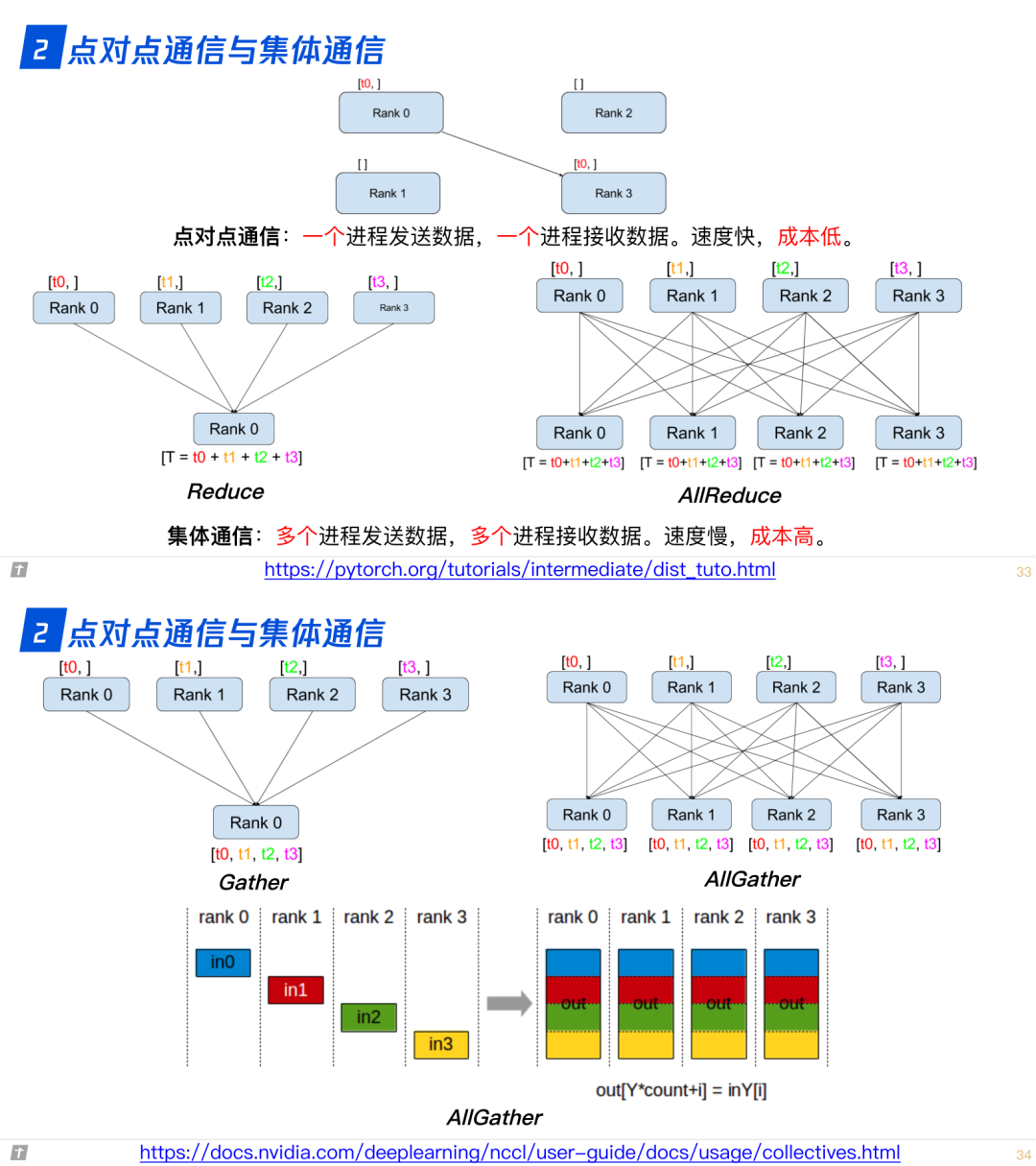
2.0 点对点通信与集体通信
2.1 数据并行

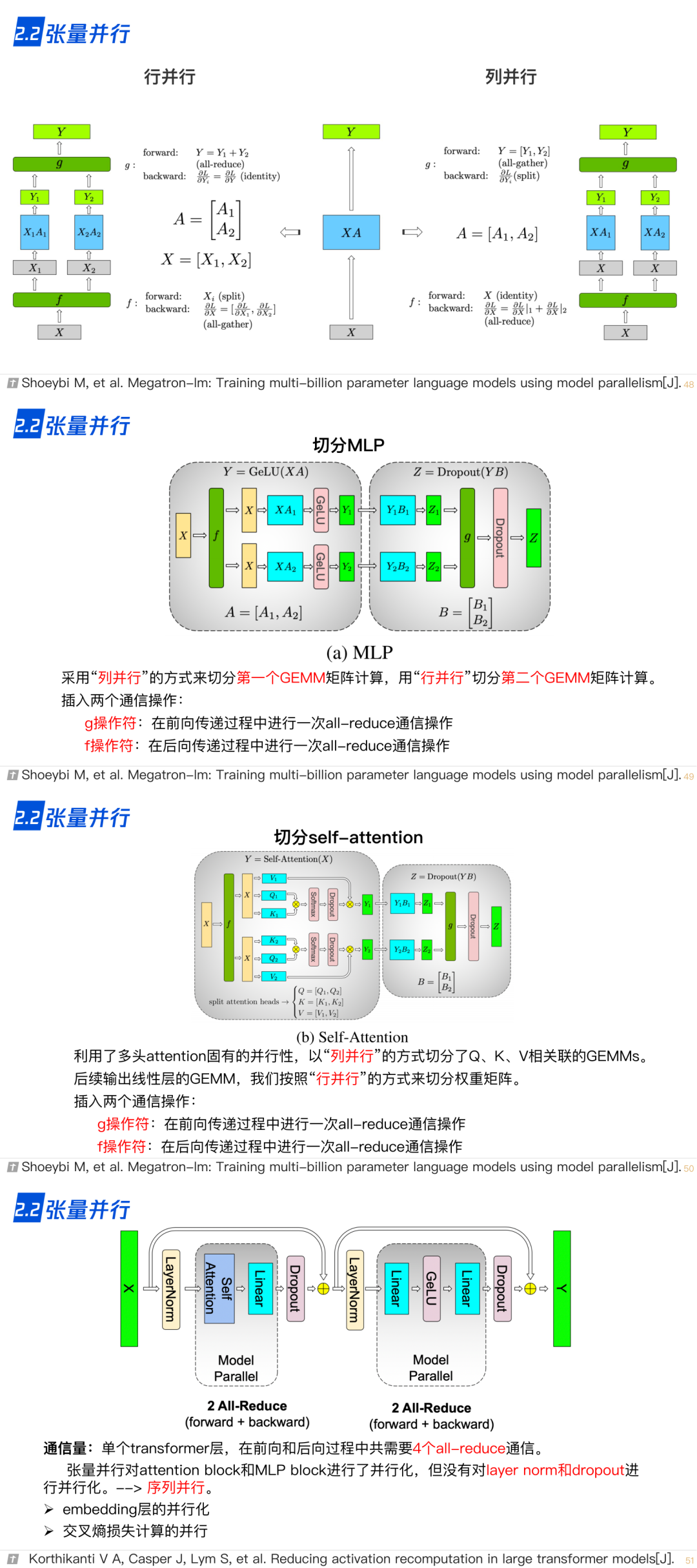
2.2 张量并行

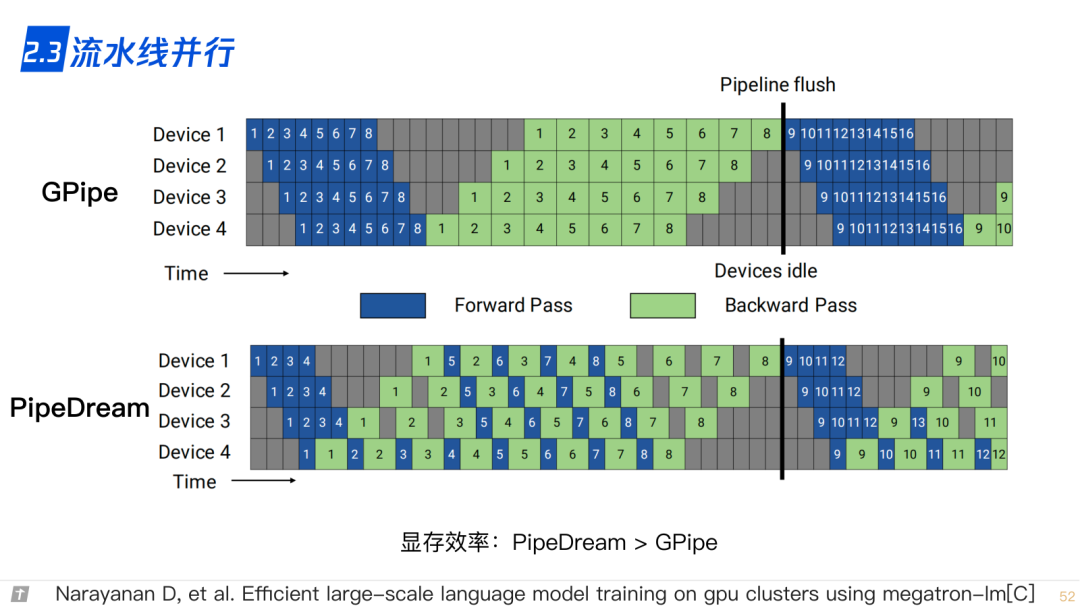
2.3 流水线并行
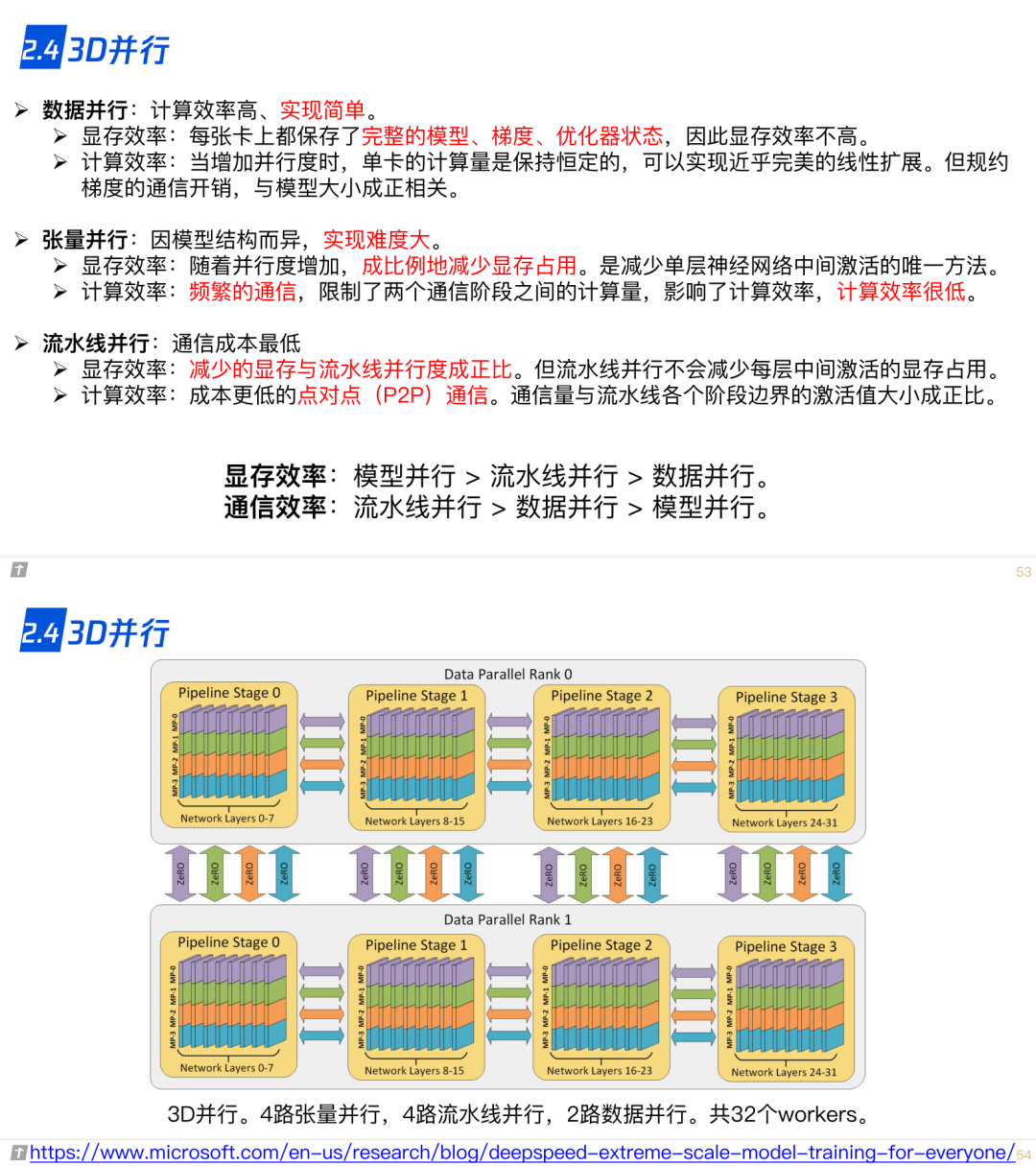
2.4 3D 并行
2.5 混合精度训练
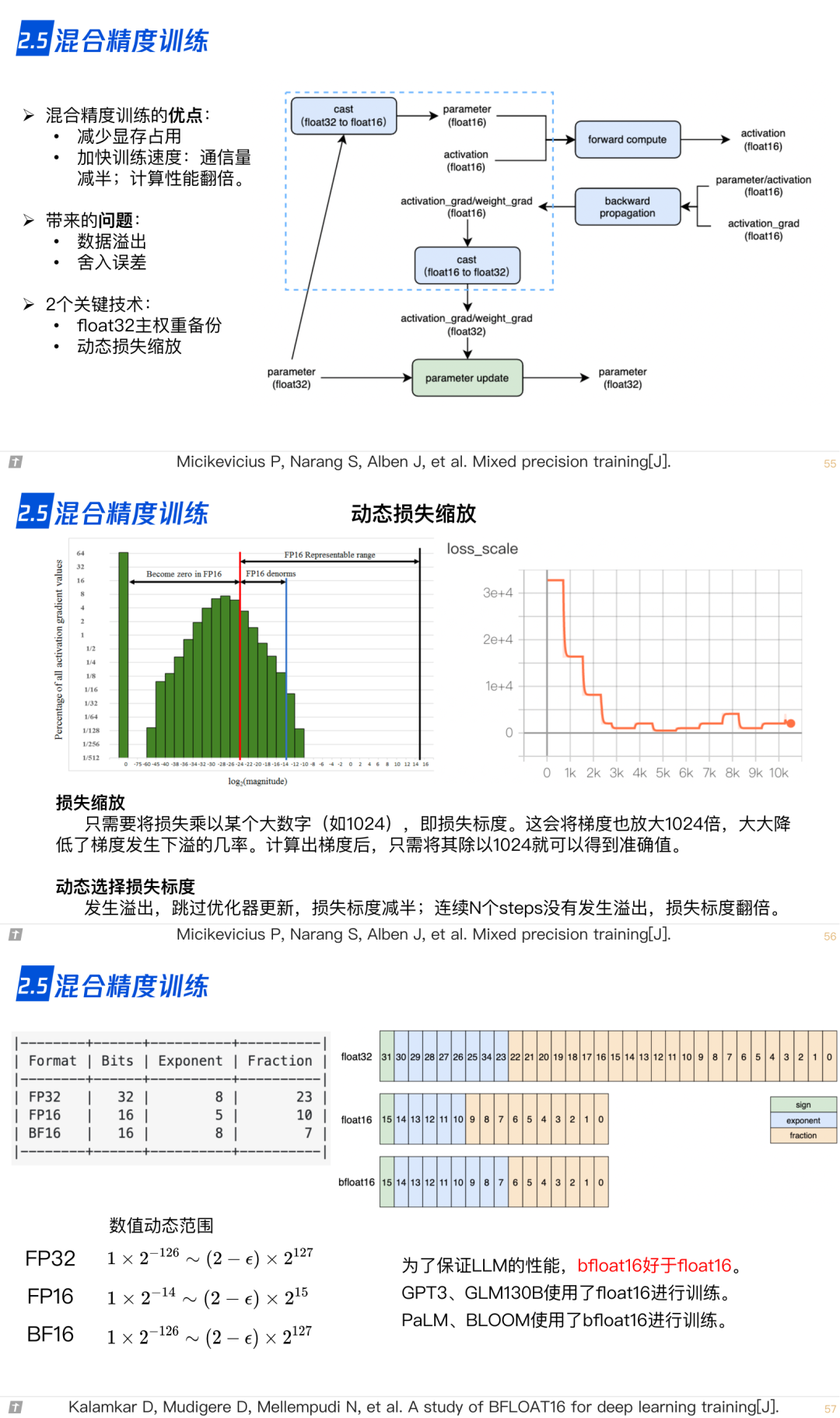
2.6 激活重计算
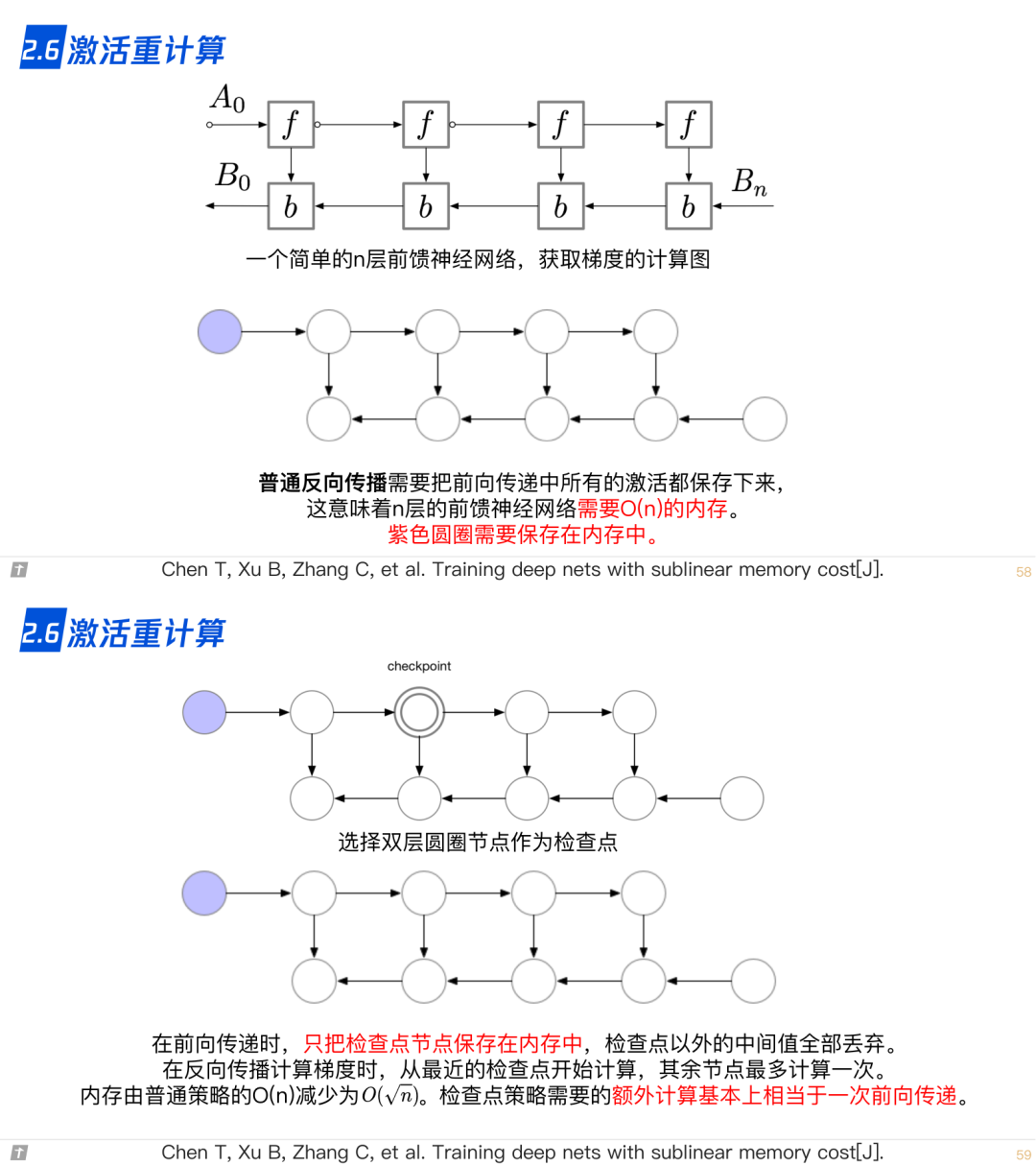
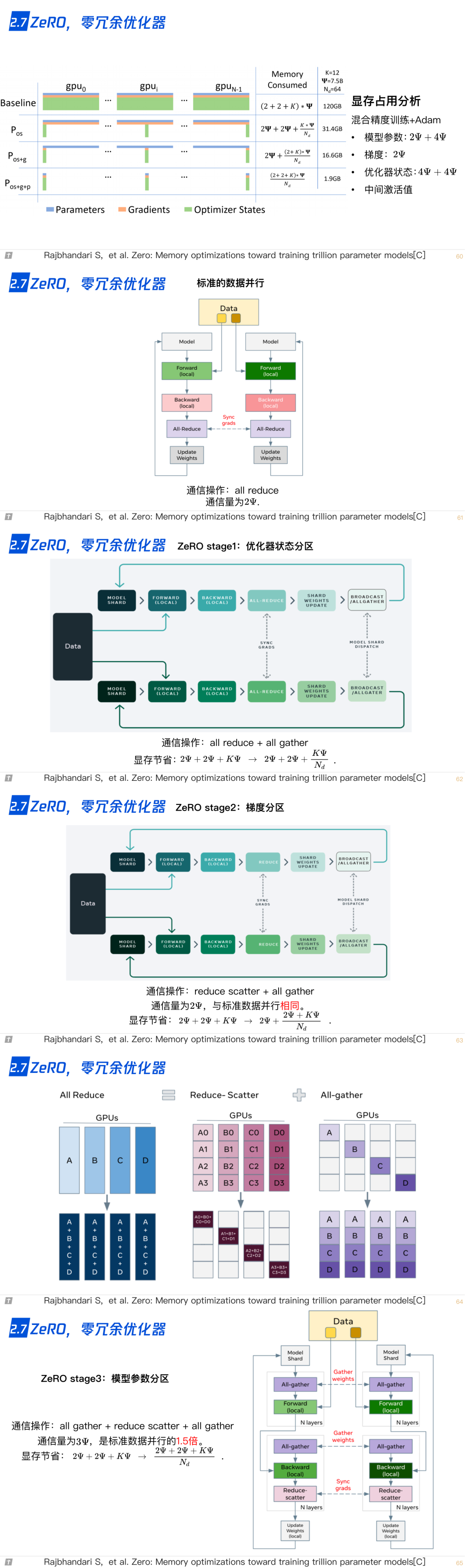
2.7 ZeRO,零冗余优化器
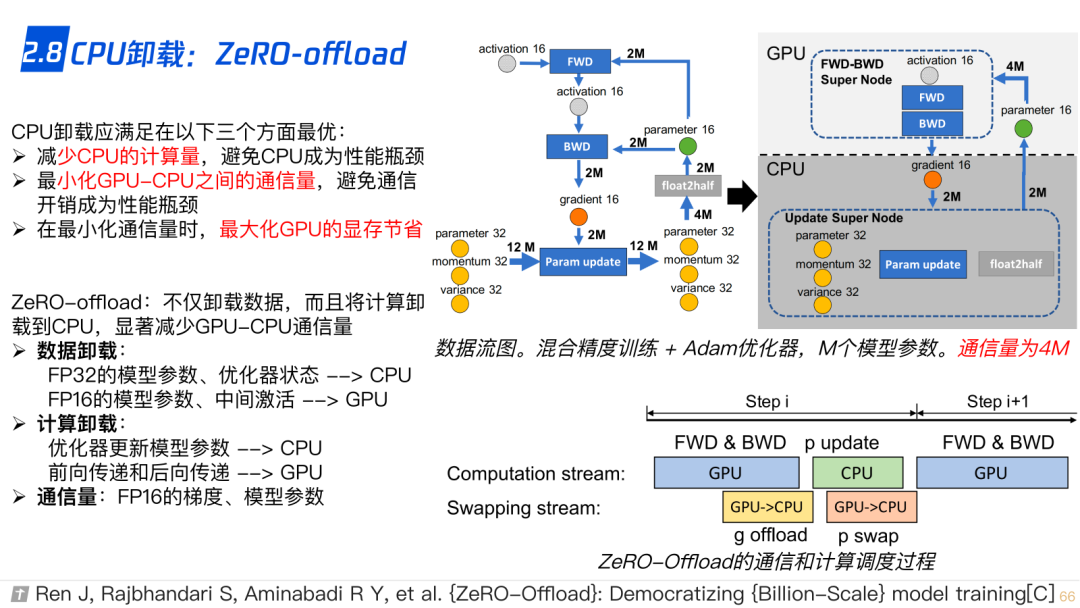
2.8 CPU-offload,ZeRO-offload
2.9 Flash Attention

2.10 vLLM: Paged Attention

3. LLM 的参数高效微调
3.0 为什么进行参数高效微调?

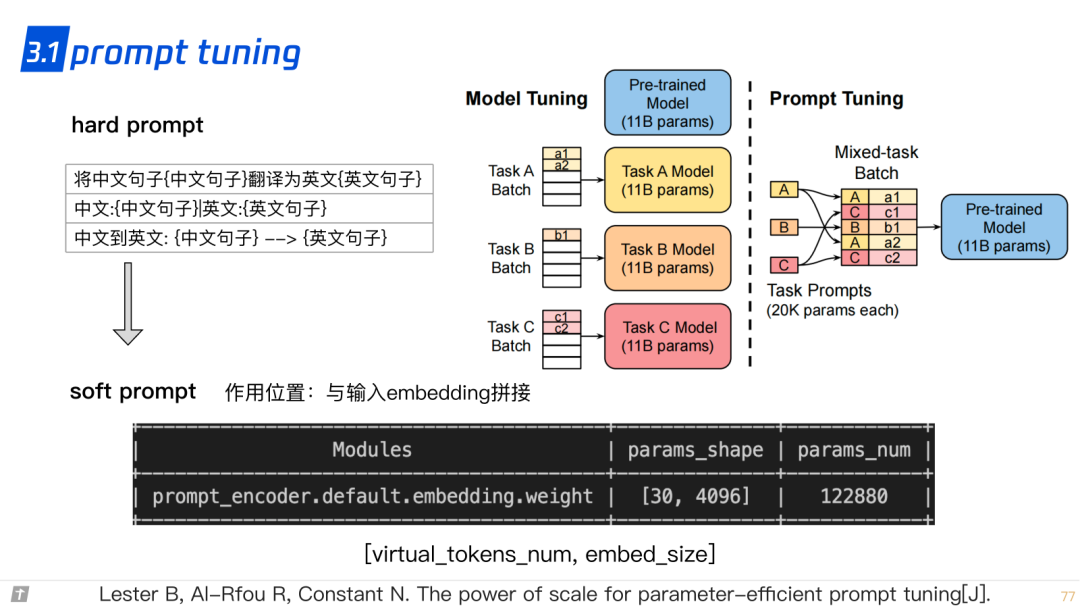
3.1 prompt tuning
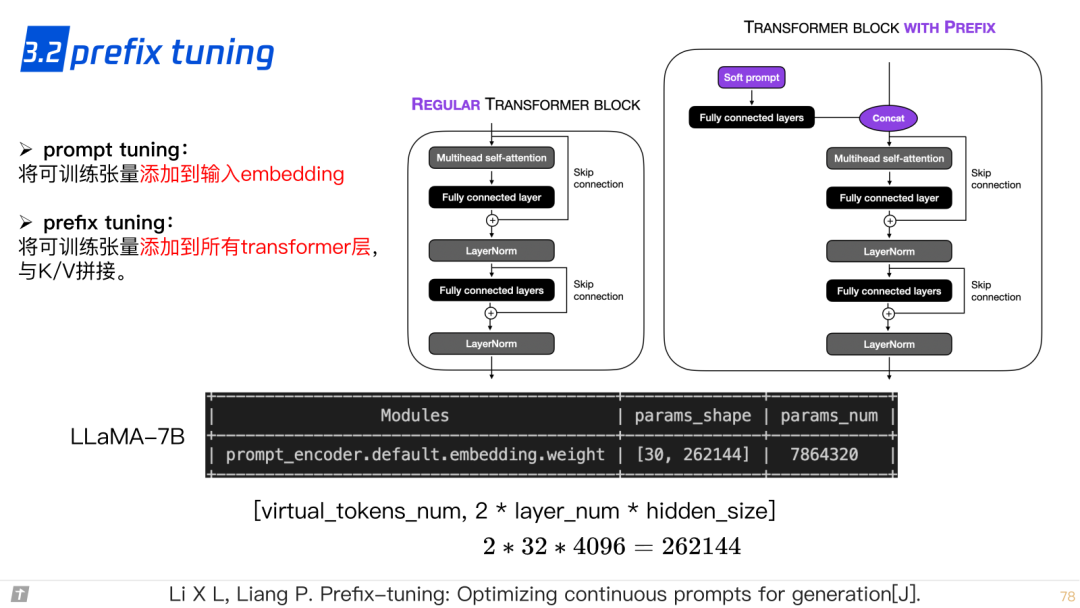
3.2 prefix tuning
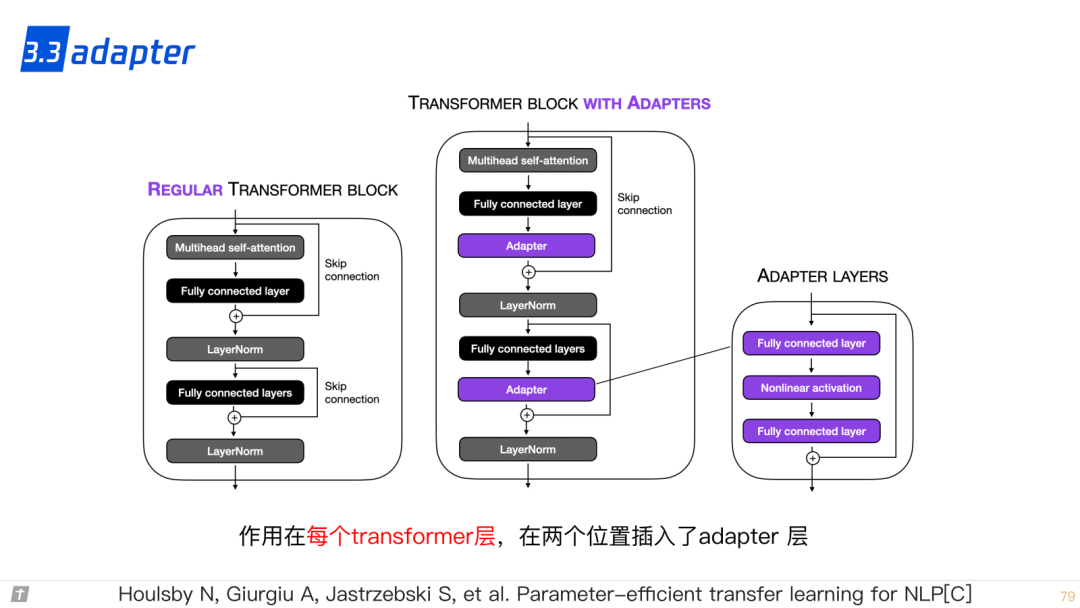
3.3 adapter
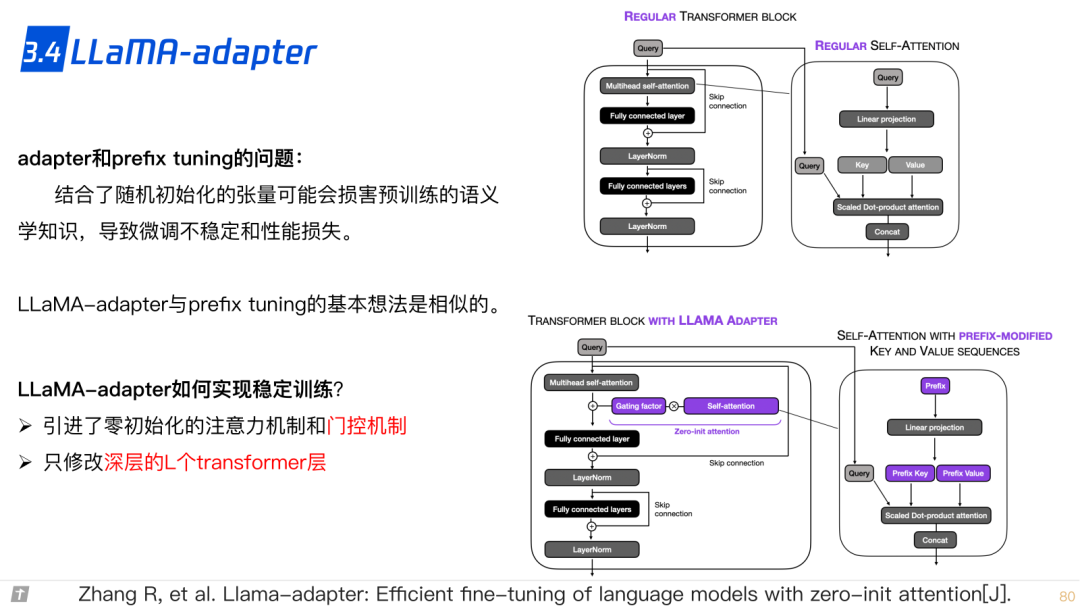
3.4 LLaMA adapter
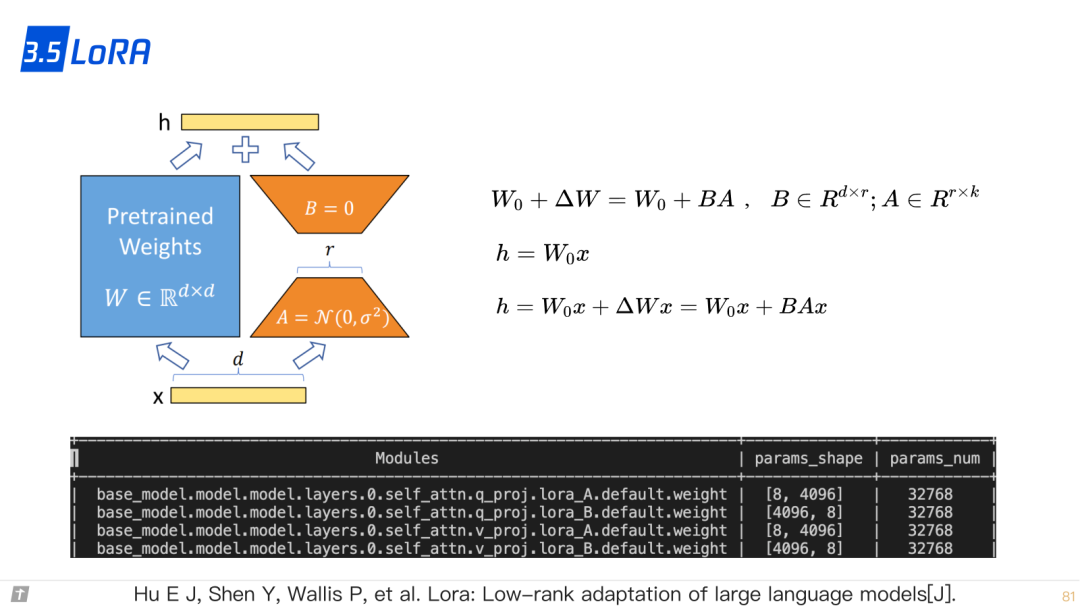
3.5 LoRA
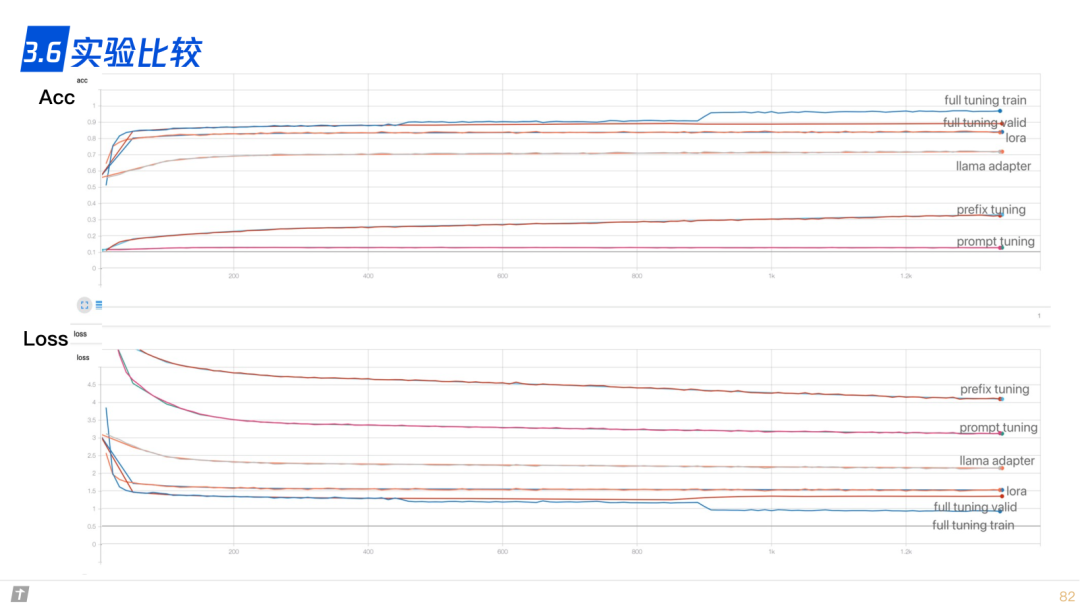
3.6 实验比较
4. 参考文献

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/288938
推荐阅读
相关标签

