
- 1hdu6735 Escape(网络流)
- 2怎样使用AI模型_ai 训练出的模型 怎么用
- 3可能这是最容易理解Vuex概念的文章了(通俗易懂详细版 )_vuex": "^3.0.1" 表示什么
- 4小狐狸ChatGPT智能聊天系统源码v2.7.6全开源Vue前后端+后端PHP_chatgpt app源码
- 5数据可视化原理与实例_数据可视化原理与实例李春芳pdf
- 6uniapp实战 -- 个人信息维护(含选择图片 uni.chooseMedia,上传文件 uni.uploadFile,获取和更新表单数据)_uniapp uni.choosemedia
- 7HarmonyOS使用Tabs组件实现页面切换_harmonys tabs 一直切换
- 8【b站咸虾米】chapter1&2_uniapp介绍与uniapp基础_新课uniapp零基础入门到项目打包(微信小程序/H5/vue/安卓apk)全掌握_uniapp 打包微信app 配置
- 9react可视化编辑器 第五章 升级版 拖拽、缩放、转圈、移动
- 10远程入侵原装乘用车(中)
SSD(Single Shot MultiBox Detector)原理详解_ssd类别预测概率
赞
踩
在这篇文章中,我将讨论用于目标检测任务的 Single Shot Multi-box Detector。 该算法属于一次性分类器系列,因此它的速度很快,非常适合嵌入到实时应用程序中。 SSD的关键特征之一是它能够预测不同大小的目标,并且为现在很多算法提供了基本的思路。 我们从讨论算法的网络架构开始这篇文章,然后我们将深入研究数据增强、锚框和损失函数。
模型架构
SSD 算法已经在各种预训练算法上进行了训练,如 ResNet50、ResNet101、ResNet152、MobileNet、EfficientNet 和 VGG16。 但在本文中,我们将讨论在 SSD [1] 的原始实现过程中使用的 VGG-16。
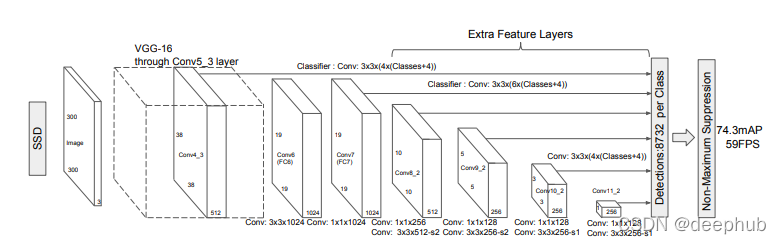
VGG-16 被用作 SSD 算法的基础网络来提取图像的特征。 VGG-16 在SSD出现时是图像分类任务中最准确的模型,所以 SSD 中使用它时几乎没有进行修改。只是最上面几层做了优化:
- pool5 从 2x2 (stride = 2) t改为 3x3 (stride = 1)
- fc6 和 fc7被转换为卷积层并进行下采样
- 在fc6中使用了Atrous 卷积
- 删除了fc8 和所有的dropout
Atrous 卷积包含一个rate参数控制元素之间的膨胀空间。在可训练参数的数量保持不变的情况下提高了感受野。
在网络的最上面几层,添加了一堆卷积层来预测边界框。我们从每个卷积层预测边界框。这使 SSD 能够预测不同大小的目标。架构中较前的层预测的边界框有助于网络预测小目标,而架构中使用较后的层预测的边界框有助于网络预测大目标。中间层有助于预测中等大小的目标。现在我们对SSD的架构有了一个完整的了解。那么让我们继续了解什么是默认框?他们如何帮助算法?
Anchor Boxes
注:Anchor Boxes这里我把它翻译成锚框。
锚框是用于帮助检测器预测默认边界框。与 YOLO 不同,在 SSD 中锚框的高度和宽度不是固定的,而是具有固定的纵横比。这是可以避免不同特征图的锚框大小相同的问题,因为随着特征图大小的变化,锚框的大小也会发生变化。这些纵横比用于根据其特征图缩放锚框,对于 conv4_3、conv10_2 和 conv11_2,我们只在每个特征图位置关联了 4 个默认框。对于所有其他层,我们有 6 个默认框(1、2、3、2/3、1/3)。特征图会被划分为网格,每个锚框被平铺到特征图中的每个网格上。在每个特征图网格和每个默认框中,我们预测相对于锚框中心的x和y偏移量、宽度和高度偏移量以及每个类别和背景的分数。因此,如果有k个检测器(锚框)和m x n个特征图和c个类别进行分类,那么我们预测每个网格和检测器的4个边界框参数和c+1个类别得分。因此,我们预测了一个特征图的kmn(c+1+4)值。在几个特征图中允许不同的默认框形状让我们有效地离散化可能的输出框形状的空间。
计算锚框尺寸的比例尺的方法是

网络预测的 4 个值不直接用于在目标周围绘制边界框。 这 4 个值是偏移量,因此它们是与锚框大小一起用于预测边界框的残差值。 这有助于模型的稳定训练和更好的收敛。
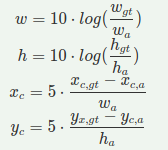
公式中的10和5值称为variance scale,是不可学习的超参数。
现在让我们看看最后输出是什么:
- num 个类别的置信度分数 和 1 个背景类别。
- 四个边界框属性:到匹配的默认框中心的x偏移量(cx),到匹配的默认框中心的y偏移量(cy),边界框宽度的对数尺度变换 (w) 和边界框高度的对数尺度变换 (h)。
- 四个默认框值:默认框距图像左侧的中心 x 偏移、默认框距图像顶部的中心 y 偏移、默认框的宽度和默认框的高度。
- 四个方差值:用于编码/解码边界框(Bounding-Box)的值。
匹配策略
本节我们将介绍如何为计算模型的损失解码真实的边界框。还有就是ssd 如何为其检测器做了一些特殊的操作。
上面的架构图中能够看到,SSD 为每个图像预测大约 8700 个框。但是一般图像中只有 6 个或更少的目标。所以我们是否应该在所有真实的边界框上惩罚所有预测框?如果我们这样做了那么将迫使每个检测器预测每个真实的边界框。检测器将尝试预测所有目标,最终预测则变成了它们之间某处的框。
为了避免这种情况,我们必须专门研究如何让我们的检测器一起工作,让他们成为一个团队而不是各自为战。为了实现这一点,我们将每个真实边界框与某个预测框匹配。该预测框负责预测特定的真实边界框,在反向传播时为该特定预测框添加了匹配的真实边界框的损失。
在这里将真实框与预测框匹配的策略称为匹配策略:我们首先将每个真实边界框与具有最高 jaccard 重叠的默认框匹配,将默认框与任何具有高于阈值的 jaccard 重叠的真实框匹配可以使许多预测框与特定的真实框相关联。上述过程是通过使用二分匹配算法实现的。这种策略有助于检测器专注于预测特定大小的目标。
Hard Negative Mining
由于框的数量很大,negative boxes(候选负样本集)的数量也很大。 这会造成正例数和负例数之间的不平衡。 负例增加的损失将是巨大的并且会覆盖掉正例的损失。 使得模型训练变得非常困难并且不会收敛。 因此按照最高置信度对负样本进行排序,然后以 1:3 的比例筛选正负样本, 这样更快和稳定的进行训练。 在 YOLO 中不使用这种方式,而是通过某种方法对负样本的损失进行加权,虽然方法不同但目的是相同的。
数据增强
对于Data Augmentation,每个训练图像随机选择以下的操作:
- 使用原始图像。
- 使与图像0.1,0.3,0.5,0.7或0.9的最小jaccard重叠,进行patch
- 随机一个patch
还可以使用光学增强。在目标检测中,这种增强技术会影响原始图像的亮度和颜色,但不会对图像中物体周围的边框产生影响。我们可以使用许多方法来变换图像以实现这种增强。比如:随机亮度,随机对比度,随机色调,随机照明噪声,随机饱和度等等。
以上就是SSD算从输入到输出的前向传播的整个过程以及边界框的编码和解码过程,接下来介绍损失函数。
损失函数
损失函数由两部分组成,分类损失和回归损失。

分类损失用于类别预测。SSD采用softmax 来预测类概率。所以我们使用的分类损失是交叉熵损失。有些算法使用sigmoid代替softmax。如果我们有重叠的类那么就需要使用sigmoid,因为softmax假设只有一个类可以分配给特定的对象。
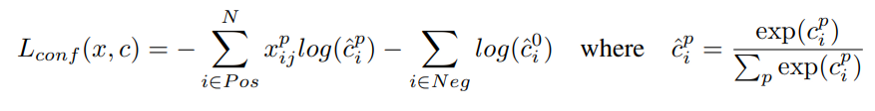
回归损失用于边界框坐标。使用平滑L1损失是因为它对异常值不那么敏感。

此外,SSD 还将这两种损失与比例因子 alpha 结合在一起。对于匹配的正例框,SSD 计算分类和回归损失。 对于负框,它只计算分类损失并忽略回归损失。 在结果中还有有一些预测框既不是背景也没有高 IOU 需要匹配。 这种框被称为中性框(neutral boxes)。SSD 也会忽略这些框的损失。
总结
以上就是对SSD原理的完整介绍,这个算法虽然是2016年发布的,但是现在很多的最新的目标检测算法都能看到他的影子,所以深入的了解他的工作原理对于我们现在学习最新的目标检测技术还是有很大的帮助的。
引用
- SSD: Single Shot MultiBox Detector. https://arxiv.org/pdf/1512.02325.pdf
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION. https://arxiv.org/pdf/1409.1556.pdf
- Lukasz Janyst’s web site . https://jany.st/post/2017-11-05-single-shot-detector-ssd-from-scratch-in-tensorflow.html
- Implementing Single Shot Detector (SSD) in Keras: Part I — Network Structure. https://towardsdatascience.com/implementing-ssd-in-keras-part-i-network-structure-da3323f11cff
- Implementing Single Shot Detector (SSD) in Keras: Part II — Network Structure. https://towardsdatascience.com/implementing-single-shot-detector-ssd-in-keras-part-ii-loss-functions-4f43c292ad2a
- Implementing Single Shot Detector (SSD) in Keras: Part III — Network Structure. https://towardsdatascience.com/implementing-single-shot-detector-ssd-in-keras-part-iii-data-preparation-624ba37f5924
- Implementing Single Shot Detector (SSD) in Keras: Part I V— Network Structure. https://towardsdatascience.com/implementing-single-shot-detector-ssd-in-keras-part-iv-data-augmentation-59c9f230a910
- Implementing Single Shot Detector (SSD) in Keras: Part V— Network Structure. https://towardsdatascience.com/implementing-single-shot-detector-ssd-in-keras-part-v-predictions-decoding-2305a6e4c7a1
- Implementing Single Shot Detector (SSD) in Keras: Part VI — Network Structure. https://towardsdatascience.com/implementing-single-shot-detector-ssd-in-keras-part-vi-model-evaluation-c519852588d1
作者:Akshay Shah

