
- 1Deep Q-learning from Demonstrations DQFD笔记
- 2如何申请到免费SSL证书
- 3你真的看懂Transformer了吗?小白学习笔记为你答疑解惑_机器翻译的时候transformer接受的是怎样的输入
- 4Python获取输入:sys.stdin与input()_python input 与sys.stdin
- 5【GPT科技系列】国内开发者调用openAI-API科技方法_如何在内网使用openai
- 6阿里云盘变本地硬盘-MAC版_苹果电脑如何把云盘改为硬盘
- 7BilSTM 实体识别_NLP实战-中文命名实体识别
- 8开源代码 | FMCW-MIMO雷达仿真MATLAB_matlab 分析 mimo雷达分辨率
- 9MATLAB拟合函数
- 10MATLAB和Python求解非线性方程组_matlab ode能解算非线性方程吗
word2vec介绍_word2vec 模型简介
赞
踩
word2vec:谷歌2013年提出
1.CBOW
2.skip-gram
3.负例采样(改变输出层)
4.霍夫曼树(改变输出层)
提出背景:当时没有那么大的数据量,也没有那么大的计算量。
word2vec和NNLM不同点
1.word2vec删除了中间的隐藏层
2.NNLM通过前向信息,word2vec使用上下文窗口信息。
3.RNN2层到3层已经算是深层网络
CBOW两边预测中间,(一个向量C对应一个代价)
skip-gram中间预测两边 (一个向量C对应四个代价)
skip-gram要稍微好于CBOW
负例采样:(改变输出层)
使用负例采样原因:因为预测结果有可能会出错,不是正确的预测结果被称谓负例,
例如共10000个预测结果(1个正确9999个错误),采用负例采样从9999个里边抽取99个
为什么要根据一个词出现的概率画线?
因为要对负例进行采样,经常出现的更应该被采做负例,不经常出现的,就应该更小负例被采到。
1.数据加载:(1)最简单的数据[[],[]]) (2)自带的LineSentence() (3)自定义加载数据
2.实例化模型
sentence:传的数据
min_count: 过滤最小词
hs:选霍夫曼树或负例采样
sg:选算法CBOW或skip-gram
alpha:学习率
size:向量大小
window:窗口大小
cbow_mean:
相似度:
欧氏距离
曼哈顿距离
一般用在模型上,计算两个向量点的距离
余弦相似度
杰卡德相似度
皮尔逊距离
通常用在向量相似度的计算,用户的相似度计算
汉明距离
编辑距离
word2Vec:
优点:编码出来的向量包含语义信息,简单快速;
缺点:没有办法解决一词多义问题。
Word2vec:https://arxiv.org/pdf/1301.3781.pdf
谷歌2013年提出来的NLP工具,它的特点就是可以将单词转化为向量表示,这样就可以通过向量与向量之间的距离来度量它们之间的相似度,从而发现他们之间存在的潜在关系。
虽然现在深度学习比较广泛,但是其实word2vec并不是深度学习,因为在这个word2vec中,只是使用到了浅层的神经网络,同时它是计算词向量的一种开源工具,当我们说word2vec模型的时候,其实指的使它背后的CBOW和skip-gram算法,而word2vec本身并不是模型或者算法。
它的提出有一个特点,就是在当时可以将文本表示出来,但是表示出来的单词和单词之间,没有相似性的概念,因为它们大多都是用索引表示出来的,在这通过实验证明了一个道理:
大量的数据训练简单的模型比少量的数据训练复杂的模型效果要好很多,例如n-gram,在机器翻译中只有几十万的数据,在语音翻译的文本当中,只有百万级别的字,因此在这些情况下n-gram模型可能就没什么用了,那么这个时候,就需要寻找更先进的技术,在大数据集上训练更加复杂的模型已经变的很现实了,而且这些再大数据集上训练复杂的模型,往往有优于大数据集上训练的简单模型,例如基于神经网络的语言模型要优于n-gram。
而word2vec是在nnlm这个模型结构的基础之上做了相应的拓展。
对比一下word2vec和nnlm的区别:
提出了两种新的模型:CBOW和skip-gram,和nnlm相比,word2vec删除了中间的隐层,这样使得模型显得更加的简单,但是这样可能会没有NNLM更加的精确,但是更好的追求了极限的速度。可以再大量的数据集上更快更高效的训练。最后想要得到的也是权重w。
这两种结构:CBOW和skip-gram,都是利用中心词和上下文的关系,互为输入和输出,上下文就是中心词前后的n个词,实验表明,提高上下文的范围n,可以提升单词向量化的质量,但是同时计算量也会增大。
CBOW:
结构: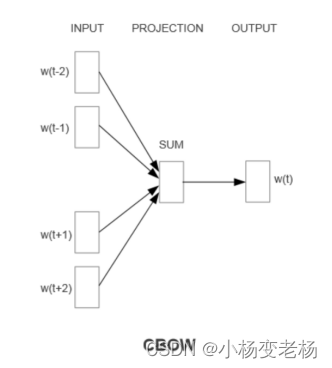
第一种模型CBOW它的思想就是,利用中间词的前n个词和后n个词来预测中间词,例如上图,n=2,就是利用当前词的前两个词和后两个词来预测中间的单词。输入层,直接求和变成投影层,其它没有任何操作,然后直接预测中心词。整体的公式表示如下: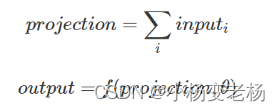
其中projection表示投影层,f表示投影层到输出层的一种映射关系,θ是参数。
skip-gram:
结构: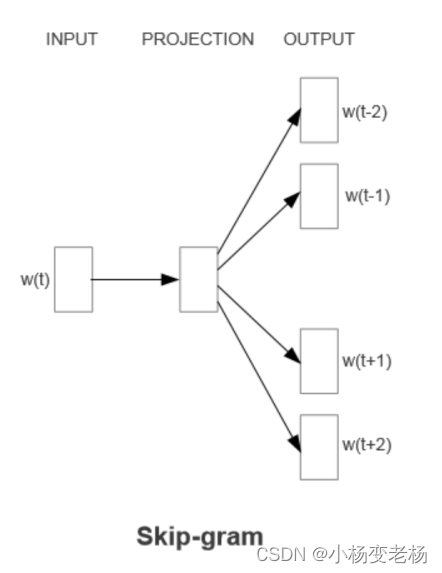
第二种模型就是skip-gram,它的思想正好和CBOW相反,它是通过中间的词来预测,上下文的N个词。如上图所示,通过中心词,来预测上文的前两个,和下文的两个词,输入层也是直接变换到投影层,然后预测上下文的单词,公式可以表达为如下:

同理:projection表示中间的投影层,f其实就是softmax激活函数,θ是权重,output是输出的预测的概率值,也就是说,此表中为每一个词的概率。
我们发现再skip-gram中最终的输出是多个输出,这个时候我们就可以看成多个多分类。
这两种算法的代价稍有不同。
再CBOW中的代价:

Output表示中心词的概率。
而在skip-gram中的代价:
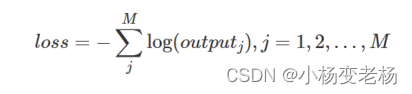
M代表上下文的数量。
Output(j)表示M个上下文中,第j个的词的概率。
这个时候我们发现,其实再最终的输出的时候和NNLM相同都是使用softmax做的输出,但是这样有一个很不好的地方,就是输出的维度太大。这个时候就涉及到了两种优化的方法:
负例采样和层次softmax---霍夫曼树:
- 霍夫曼树:
层次softmax是一种高效的计算softmax的方法,其中二叉树表示词表中的所有的词,每个词都是叶子节点,同时对于每一个节点,都有唯一的路径能从更节点走到该叶子节点上,该路径就用来估计这个词出现的概率,理论上来说可以使用任何类型的树,再word2vec中使用的是二叉的霍夫曼树,因为在霍夫曼树中,靠近根节点的节点权重都比较高,这样频率高的词,路径就短,同时计算的次数也就会更少,从而提升速度。
- 负例采样:
负例采样更加的直接,为了解决softmax要计算和更新的大量的参数,负例采样每次只计算或者更新几个参数,也就是说原来进行模型训练的时候,是从所有的词汇当中选取某个或者某些词,而现在变成了从小词集上选取,某个词或者某几个词,这个小的词集是远小于总的词汇表的。从而大大的提升训练的速度。
然后一个线段被分成V分,V代表词表的大小,每段代表一个词,同时,每条线段的长短是不同的,
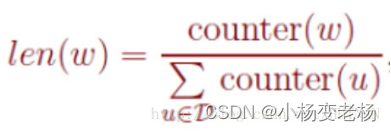
Counter就是词频,这样我们发现每个词所对应的线段的长短,是和词频是有关的,因此因为词频的不同,词所对应的线段也是各不相同的。

但是我们怎么通过小数去找区间呢?
因此,在word2vec中,是通过用一种查表得方式去实现的,将上述线段上对应M个刻度,那么每个刻度就是1/M。

这样我们就不需要生成0-1之间的小数了,只需要生成,0-M之间的整数即可,这样根据刻度上的M值去查一查对应的I值就可以取到相应的值了。
在word2vec中L上的刻度具体的实现是:
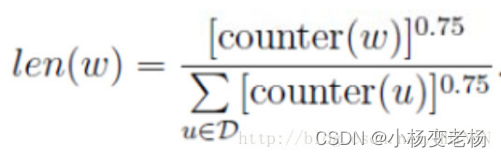
0.75就是一个经验值,是通过多次的学习得来的。具体它的作用是:它可以降低高频词的出现的概率,同时也能够增加低频词出现的概率。但是总体还不影响数据的分布。
0.5的0.75次方等于0.59。0.8的0.75次方等于0.84。
0.5/0.8 = 5/8=0.625 0.59/0.84=0.7
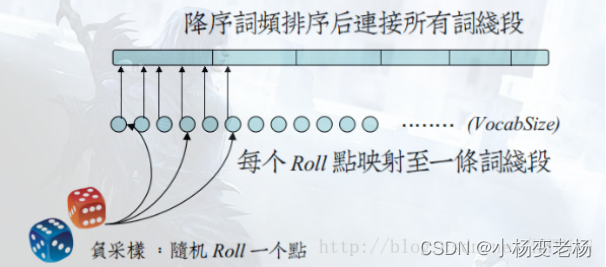
负采样这个点引入word2vec非常巧妙,两个作用,1.加速了模型计算,2.保证了模型训练的效果。一个是模型每次只需要更新采样的词的权重,不用更新所有的权重。第二,中心词其实只跟它周围的词有关系,位置离着很远的词没有关系,也没必要同时训练更新。
Word2vec和nnlm的对比:
- 1. 两者本质都是语言模型
- 2. 词向量只是nnlm的一个产物,虽说word2vec本质也是语言模型,但其更专注于 词向量本身,所以有一些优化算法来提高计算效率
- 3. 计算方面,在利用上下文词预测中心词时,nnlm是把上文词的向量进行拼接, word2vec是进行sum,并舍弃隐藏层(为了减少计算量)
- word2vec的两个加速算法:hierarchical softmax 和negative sampling
论文也对比了训练语料、向量维度以及训练轮次对结果的影响,实验结果表明,训练语料越多效果更好,600维的结果比300维的结果更优,3轮的训练结果比1轮的训练结果更好。
测试结果:
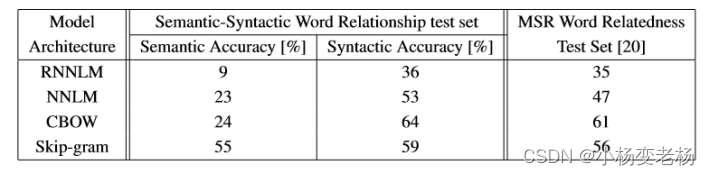
word2vec是2013年提出的模型,限于当时的算力,在大规模的语料上进行训练,确实需要更简单的模型以及一些加速训练方式;之后提出的fasttext在模型结构上可以说跟word2vec一样,主要区别在输入上,fasttext增加了词的形态特征;基于算力的提升,最近的预训练模型参数越来越大,比如BERT、XLNET,甚至有GPT3这种庞然大物。 再反过来看word2vec,是不是用现在的算力训练,就不需要层次softmax或者负采样的加速方式了呢?这还是要分情况讨论,虽然说像BERT这样的模型,都是直接用的softmax进行计算,这是因为训练BERT的人(机构、公司)具有远超普通情况下的算力,而且BERT这种输出维度也只有几万大小,词向量的输出维度则会有百万大小(可以想象下词跟字在数量上的差别),所以自己进行预训练的时候,需要根据拥有的算力和输出维度来判断是否要使用加速手段。

