
- 1第4.3章:StarRocks数据导出--Spark Connector_starrocks-spark-connector
- 2社区供稿 | RLHF 实践中的框架使用与一些坑 (TRL, LMFlow)
- 3FedRS: Federated Learning with Restricted Softmax for Label Distribution Non-IID Data, KDD 2021
- 4【开题报告】基于SpringBoot的电商平台的设计与实现_基于springboot电商系统的设计与实现开题报告
- 5一款兼容双系统、为代码而生的机械键盘--Keychron K3_keychron k3a1
- 6云账户自动提现封装(支付宝加银行卡)_云账户对接/api/payment/v1/order-realtime
- 7东汉唯物主义哲学家——王充
- 8Kstry流程编排框架_可视化流程编排框架
- 9[NLP] LLM---<训练中文LLama2(五)>对SFT后的LLama2进行DPO训练_为什么llm经过dpo训练后,输出格式对不齐了
- 10论文解读 ——TimesNet 模型
你真的看懂Transformer了吗?小白学习笔记为你答疑解惑_机器翻译的时候transformer接受的是怎样的输入
赞
踩
1.Transformer概述
Transformer是一种基于注意力机制的序列到序列模型,它在机器翻译任务中表现出色并逐渐成为自然语言处理领域的主流模型。Transformer模型的核心思想是使用自注意力机制(self-attention)来捕捉输入序列中各个位置的上下文关联。自注意力机制允许模型在编码和解码过程中对不同位置的信息进行加权,使得模型能够更好地理解上下文,并将重要的信息加权汇聚起来。通过多层的自注意力机制和前馈神经网络,Transformer模型能够学习到输入序列的表示,并生成与任务相关的输出。
相比于传统的循环神经网络(RNN)和卷积神经网络(CNN),Transformer模型具有以下优势:1)并行计算能力强,可以高效处理长序列;2)捕捉长距离依赖更加有效;3)模型结构简单且易于训练。注意力机制和Transformer模型的引入使得自然语言处理任务取得了重大进展,比如机器翻译、文本摘要、问答系统等,在这些任务中,Transformer模型已经成为了目前最优秀的模型之一。
2.Transformer结构
Transformer结构主要由序列输入、编码器(Encoder)、译码器(Decoder)、序列输出四个部分构成。如下图:
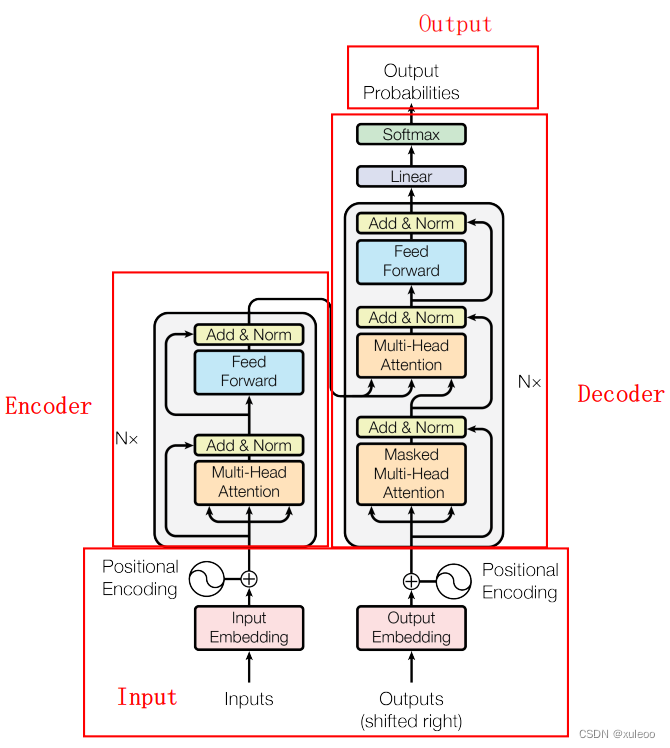
这结构初看觉得很复杂,其实细看更复杂,我也看了很多博客才逐渐弄懂。所以看不懂没关系,我们一起慢慢理解共同学习。
2.1输入部分
Transformer的输入是一系列序列,以机器翻译为例,输入都是一些长短不一的句子。那么问题来了,计算机怎么知道这些文字序列呢?聪明的你可能会想到图像识别,由于图像是个(h,w,c)形式在0~255之间的三维张量,因此计算机就能根据这些数组成功的识别到图像内容。但是文字序列计算机怎么识别呢?这就是我们即将介绍的词嵌入Embedding模块
2.1.1 Embedding 模块
看到这里你可能知道了Embedding模块的作用了。没错,就是和你想的一样,Embedding的作用就是用向量来表示文字序列,这样计算机就能根据这些向量从而知道我们的输入是什么。其实也可以看成图像识别,只是输入数据的维度不一样了,这样你是否理解了Embedding的作用了呢?不理解也没关系,我们将弄到你清楚为止。有这样用途的还有one-hot编码,咱们就用one-hot编码举例一下吧。
one-hot 编码就是对类别二进制化操作,然后用作模型的训练特征。比如有要编码的序列[中国,美国,日本]使用one-hot编码后就成这样
| 中国 | 1 | 0 | 0 |
| 美国 | 0 | 1 | 0 |
| 日本 | 0 | 0 | 1 |
这样,100就表示中国,010就表示美国,001就表示日本。这样输入计算机就能识别输入的文字了,有没有突然觉得很简单呢。现在你可能会问为什么不用one-hot编码而要用Embedding编码呢,让我再细细给你解释。
首先,这样表示稀疏性太大了,比如刚才上面的列子,世界上有200多个国家。这样就需要用两百多个0和1表示一个国家,这样太浪费资源,用在机器翻译上更是不敢想象需要多少个0和1才能表示一个字词。其次,one-hot不能表示分类特征之间的相关性,0的个数太多了,没有很好的表示分类对象的特征关系。而这些缺点Embedding都没有,所以当然是无二选择Embedding。
经过这么一说,你肯定对Embedding有了很好的理解,下面一起看看这部分的代码了:
- class Embeddings(nn.Module):
- def __init__(self, d_model, vocab):
- # d_model 向量维度,即一个词用多维向量表达,1*d_model维度
- # vocab 词表大小
- super(Embeddings, self).__init__()
- self.d_model = d_model
- self.vocab = vocab
-
- self.Embed = nn.Embedding(vocab, d_model)
-
- def forward(self, x):
- Emb = self.Embed(x)
- return Emb * math.sqrt(self.d_model)
代码段中,定义d_model和vocab两个参数。其中d_model表示我们要把字词用多少个特征表示,在Transformer中d_model=512,即一个字词用 的向量表示。vocab表示有多少个字词需要表示,这样,词嵌入后的输出就是
d_model大小。然后调用torch.nn模块下的Embedding嵌入函数,(具体原理没有看。最后定义了forward函数,将输入张量
x传递给Embed层进行映射,得到对应的词向量Emb,并对词向量进行缩放,
缩放操作有两个主要作用:
-
调整数值范围:将词向量进行缩放可以将其数值范围限制在一个较小的范围内,这有助于模型训练的稳定性和收敛性。较小的数值范围可以减少梯度爆炸和梯度消失等训练中的常见问题。
-
增强特征表示:通过缩放操作,可以增加词向量中的差异度,使不同词向量之间的距离更具有可比性。这有助于捕捉到更多的语义信息,并提高模型对词语之间关系的建模能力。
缩放因子math.sqrt(self.d_model)的选择是为了平衡词向量的数值范围和表示能力。它使用词向量的维度self.d_model的平方根作为缩放因子,可以使不同维度上的数值相对均匀分布,避免某些维度上的数值过大或过小。
下面两个图分别表示经过Embedding和one-hot的比较,从图中可以清楚的看到Embedding的特征表示能力更强,而且一定程度上能表示不同分类对象之间的相关性。
经过和我的一起学习,相信你不仅理解了Embedding的作用还掌握了one-hot编码的原理及缺点。有没有感觉到自己很厉害的样子 。
输入的序列经过编码后,又有新的问题等着我们去分析。我们都知道,不同的字词在不同的位置所表达的意思差别很大。就比如,我喜欢她,她喜欢我。只有两个字位置的变动句子表达的意义就发生了巨大变化。所以不同的位置所表达的意义一样吗?答案十分肯定——完全不一样。可见,不同的位置对所表达的意思具有天差地别,那么计算机是如何理解不同位置上所表达的不同意思呢?这就是Transformer中Positional Encoding 的作用了。下面让我们一起学习是如何对位置编码的。
2.1.2 Positional Encoding
位置编码的特点是,不同位置的词向量在不同维度上具有不同的数值,从而为模型提供位置信息。正弦和余弦函数的周期性质使得位置编码能够在序列的不同位置上生成不同的值,而这些值可以在模型中进行学习和利用。在Transformer模型中,位置编码与输入的词向量相加,以获得既包含词语信息又包含位置信息的输入表示。位置编码的添加可以在模型的输入层或嵌入层之后进行。位置编码使模型能够更好地理解序列中不同位置的关系,并帮助Transformer模型在处理序列数据时捕捉到位置信息的重要性。
到这里,估计你已经知道使用正弦和余弦函数对位置编码,在原论文<Attention Is All You Need >就是用这两个函数进行编码的。公式如下:
解释一下,代表字词的位置,
代表第
个维度,
代表词嵌入维度也就是512.至于为什么使用正余弦函数,我也不太清楚,感兴趣的可以去查查资料。下面一起看看位置编码代码。
- class PositionalEncoding(nn.Module):
- def __init__(self, d_model, dropout, max_len=5000):
- """
- d_model 单词的维度
- dropout 权重置领率, 防止过拟合
- max_len 语句的最大词长度
- """
- super(PositionalEncoding, self).__init__()
- self.d_model = d_model
- self.dropout = nn.Dropout(p=dropout)
- self.max_len = max_len
-
- # 设置零词表矩阵,将位置编码后的矩阵放入
- pe = torch.zeros(self.max_len, self.d_model)
- # 得到每个词的位置,
- position = torch.arange(0, self.max_len).unsqueeze(1)
- # 中间矩阵,将max_len*1 变化max_len* d_model
- div_term = torch.exp(torch.arange(0, self.d_model, 2) * - math.log(1000)/self.d_model)
- pe[:, 0::2] = torch.sin(position * div_term)
- pe[:, 1::2] = torch.cos(position * div_term)
- print(pe.shape)
- # 对pe扩充维度
- pe = pe.unsqueeze(0)
- print(pe.shape)
- self.register_buffer('pe', pe) # 申请缓存,不参与梯度更新
-
- def forward(self, x):
- x = x + Variable(self.pe[:, :x.size(1), :], requires_grad=False)
- print(self.pe[:, :x.size(1)].shape)
- return self. Dropout(x)

首先,我们先看一下几个参数,d_model 嵌入维度,droupout参数置零,降低模型复杂度,zhe'smax_len,句子最大长度。我们先看dropout的作用 。
- x = torch.randn(4, 5)
- print('input', x)
- drop = nn.Dropout(p=0.2)
- x = drop(x)
- print('output', x)
上述代码以概率为0.2对进行置零,下面是输入于输出,可以看到,一些值被设置成零。
pe = torch.zeros(self.max_len, self.d_model) 这行代码先定义一个max_lend_model的全零矩阵,这个矩阵便是编码后的的大小。为了更好的理解下一行代码,先看函数unsqueeze()的作用
- position = torch.arange(0, 20)
- print('no unsqueeze', position.shape)
- pos = torch.arange(0, 20).unsqueeze(0)
- print('unsqueeze(0)', pos.shape)
- pos = torch.arange(0, 20).unsqueeze(1)
- print('unsqueeze(1)', pos.shape)
上面代码输出:
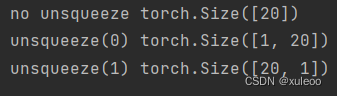
发现了吗,就是对指定维度进行扩充。那么下面代码就容易理解了
position = torch.arange(0, self.max_len).unsqueeze(1)通过上面代码,我们就能得到每个字词的位置,position的大小是[max_len,1],而我们输出数据大小是[max_lend_model]。就需要position和一个维度为[1
d_model]的矩阵 相乘就能得到大小为[max_len
d_model]的矩阵了。这行代码就是这个作用,但为什么要乘以一个数呢?这是因为希望得到一个较小的数,这样有助于更快的收敛。这也是为什么在许多深度神经网络中为什么要归一化的原因?
div_term = torch.exp(torch.arange(0, self.d_model, 2) * - (math.log(10000))/self.d_model) 想必细心的朋友发现这里并没有按照刚才所说的那样生成一个[1d_model]的矩阵,而生成[1
d_model/2]的矩阵。那是怎么回事呢,别着急,咋们慢慢分析。先继续看代码
- pe[:, 0::2] = torch.sin(position * div_term)
- pe[:, 1::2] = torch.cos(position * div_term)
看了这行代码,聪明的你有没有想到原因呢?第一行代码对刚才定义PE矩阵进行偶数列填充,第二行代码对PE矩阵中奇数列填充。一个填充偶数列,一个填充奇数列。两个填充后填充后就能得到大小[max_lend_model]的目标矩阵了。怎么样,有没有想说一声妙极了。这样,经过位置编码后的矩阵就能得到了。
pe = pe.unsqueeze(0)这行代码熟悉吧,就是刚刚的对指定维度进行填充。为什么要增加维度呢?个人理解是有个参数batch_size,就是一次处理需要处理几个这样的数据。
self.register_buffer('pe', pe) # 申请缓存,不参与梯度更新 代码的作用是位置编码不需要参加梯度更新,即通过使用 register_buffer 注册缓冲,我们可以将一些需要在模型中存储和传递的张量与模型的参数隔离开来,从而更好地管理和处理模型的状态。最后就是forward函数。
- def forward(self, x):
- x = x + Variable(self.pe[:, :x.size(1), :], requires_grad=False)
- print(self.pe[:, :x.size(1)].shape)
- return self. Dropout(x)
第一行代码就是经过词嵌入后的向量与位置编码后的向量相加。为什么是x.size(1),因为我们要编码的句子长度不一定是最大max_len长度,而要根据输入的x进行判断,而且这个参数是不参加梯度跟新的。最后通过对编码后的数据按一定比率置零。就这样,位置编码我们也基本搞定了,是不是觉得收获满满。下面这幅图就是词嵌入和位置编码后得到的数据可视化图。
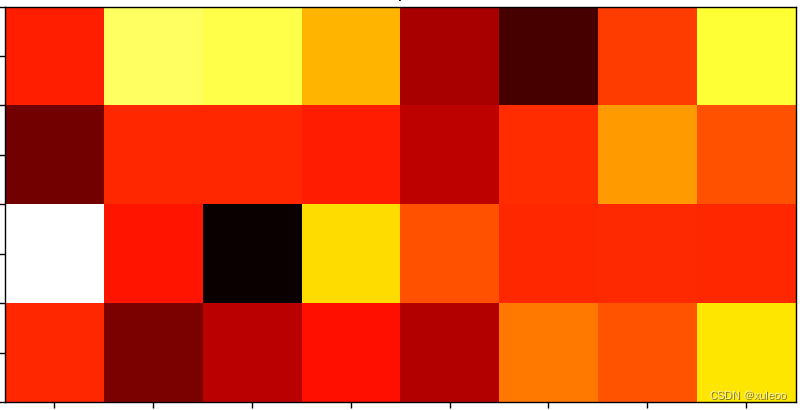
这样,输入部分就基本学完了,下面将开始Transformer中的重中之重,大家一定要打起十二分精神和我一起看看编码部分吧。
2.2 Encoder
我们先来看看编码部分,编码部分由N个编码器构成,Transformer中,所以我们只需要分析一个Encoder的原理就可以。Encoder的结构如下图。
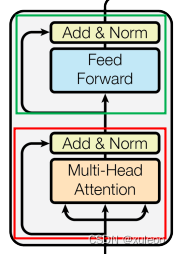
从图中可以看出,Encoder由两个子层连接构成,两个子层的区别是一个是Multi-Head Attention和Feed Forward。不用着急,这两个模块会在后面慢慢细说。咋们下来看Add和Norm分别代表什么。
2.2.1 残差模块
有基础的同学可能知道残差网络什么,在这里就是上图中Add模块。在传统的神经网络中,每个网络层的输入通过非线性的激活函数进行转换,然后传递给下一层。然而,随着网络层数的增加,传统神经网络容易出现梯度消失和梯度爆炸的问题,导致网络难以训练。

残差网络通过引入残差连接(residual connection)来解决这个问题。残差连接允许跳过某些层的转换,直接将输入传递给后续层。这样,网络可以通过逐层增加残差来学习剩余的映射,而不是从零开始学习整个映射。这种残差学习的方式使得网络更容易优化,同时也能够支持更深的网络结构。残差连接如下,这样连接后可以保证至少不比原来差,为什么,因为我们的输入分路走了,一条经过梯度更新,另外一条直接就是原输入数据。这就保证了如果经过梯度更新变好,那我们当然高兴,但如如果结果变差,但我们依然能保证原始数据的结果,这就为什么残差连接在深度学习中这么火爆。好了,残差网络就说这么多了,感兴趣的可以看原论文<Deep Residual Learning for Image Recognition >
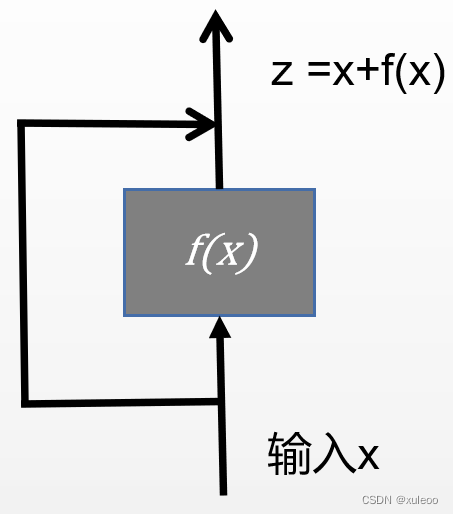
2.2.2 LayerNorm
如果你有深度学习基础,那么你应该听说过BatchNorm,也知道LayerNorm经常用在自然语言处理(NLP)中,而BatchNorm经常用在CV方向,他们都是对输入数据归一化,作用是在前向传播过程中通过规范化输入数据的分布来加速训练,并且有助于防止梯度消失或梯度爆炸的问题。但你知道两者的区别吗?在此之前我也是一头雾水,看得懵懵懂懂。下面一起分析这两者的区别吧,首先先分析BatchNorm原理。

假设我们输入数据是(3,3,3,3),(batchsize, c,h,w),分别表示一次处理样本数,通道数,宽高。这就是我们的一批处理数据。其中不同颜色代表不同特征,即三个样本中绿色都代表同一个特征,比如三个样本中绿色代表图片中人的特征。那么就能就到三个样本中同一特征的均值和方差。
=4.1, 方差为和均值都是4.1.这样,我们就可以利用公式得到标准化后的数据了。BatchNorm的公式为
gamma和beta参数都是可学习参数,mean表示平均值,var表示方差,这样可以得到样本1的经过归一化后的值。

同理,可以得到样本2和3经过归一化的数据,对于其它特征(红色、浅绿色)也是如此。这就是批量归一化的原理,那为什么BatchNorm不适用于自然语言处理呢。下面我们将来介绍LayerNorm的原理。
上面我们知道批量归一化是对所有样本的同一通道(特征)进行归一化操作。而在自然语言处理中,一个样本就是一句话,此时如果使用批量归一化,归一化后的数据意义就不大了,效果自然而然变差了。下面看看为什么。

发现问题了吗,上面就是使用BatchNorm对文字序列进行归一化处理,这样对每个样本进行归一化有什么意义?答案毫无意义。这就是为什么BatchNorm不适用于自然语言处理的原因了。
假设输入的样本是今天降温了,用词向量表示为下图
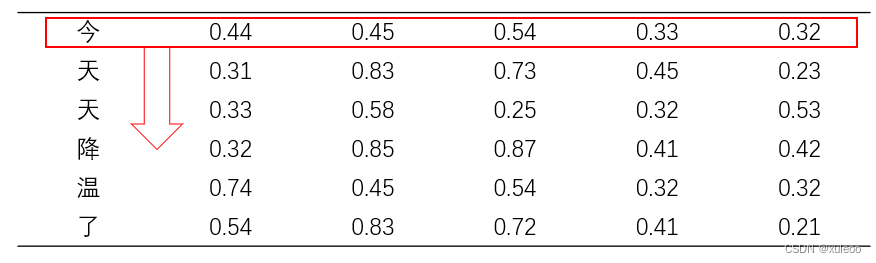
LayerNorm先计算出‘今’向量的平局值和方差,同样利用公式
进行归一化 。然后一次往下对一句话中字词逐个进行归一化操作。具体细节不再叙述。下面展示LayerNorm的代码。
- class LayerNorm(nn.Module):
- def __init__(self, feature_size, eps=1e-6):
- # feature 词嵌入维度
- super(LayerNorm, self).__init__()
- self.a_2 = nn.Parameter(torch.ones(feature_size))
- self.b_2 = nn.Parameter(torch.zeros(feature_size))
- self.eps = eps
-
- def forward(self, x):
- mean = x.mean(-1, keepdim=True)
- std = x.std(-1, keepdim=True)
-
- return self.a_2 *(x-mean)/(std+self.eps)+self.b_2
代码很简单,先定义两个需要学习的参数a_2,b_2.对最后一个维度取均值和方差。这是因为最后一个维度表示的是特征值。这样,我们就一起学完LayerNorm和BatchNorm的原理和区别了,相信你一定有很多收获吧。
2.2.3 Attention 模块
注意力机制(Attention mechanism)是其中一个重要的组成部分。注意力机制的目的是在输入序列中建立起不同位置之间的关联性,允许模型在进行编码和解码过程时,能够有效地关注到相关的部分。那么它是怎么注意到不同位置的相关性呢。首先先看结构图:
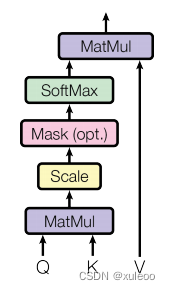
首先可以看到三个输入矩阵Q、K、V 。那么它们代表什么意思呢?看到一个很好的列子,假如有一段文本,需要回答问题。可能会先找到一些关键词,那么K就代表这些关键词,而Q就代表这段文本,V就代表根据文本和提示词所联想出的答案。也许第一次答案不是很准确,但经过多次联系文本Q和关键词K之间的关系和之前我们所想的答案V,不断完善答案,我们的答案也就越来越准确,这样是不是理解各个矩阵的意义了。transformer中就是不断更新这些矩阵值,从而使它的输出和标签的损失尽量小。下面我们一起看操作过程;
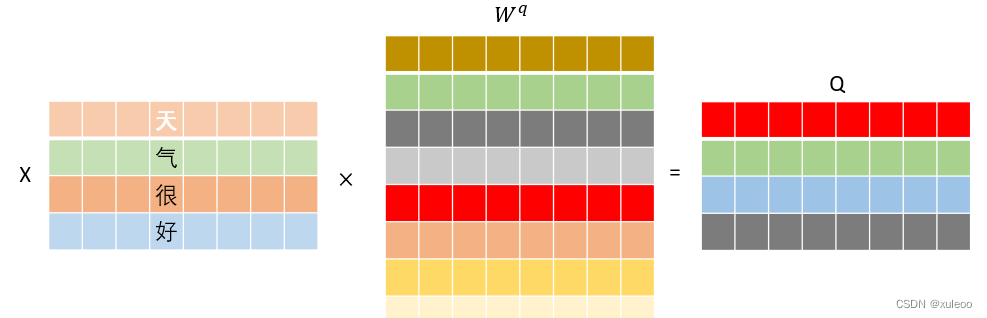
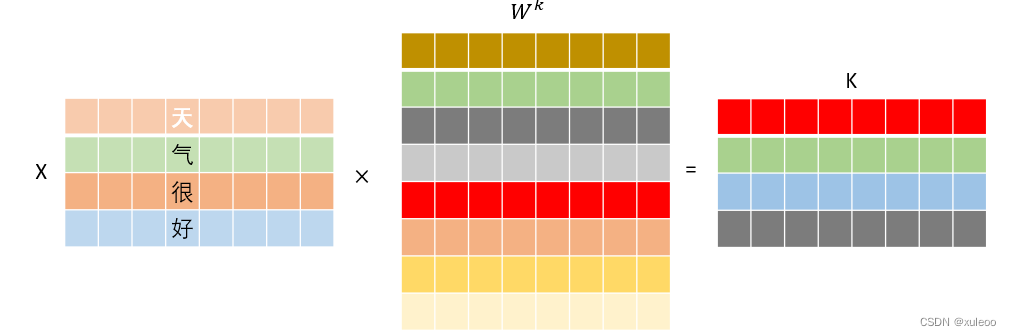
假设我们的输入"天气很好适合游玩"经过词嵌入和编码后的向量矩阵大小为,即共有4个字,每个字用8个特征表示。首先需要得到我们的三个输入矩阵QKV,这三个矩阵需要分别乘以
,即通过不断更新这些矩阵权值,得到更好表示特征的QKV矩阵。并且经过矩阵相乘后,不改变输入大小,因此这几个
矩阵大小都是d_model
d_model,这样,输出的矩阵大小没有改变。

得到注意力机制的三个矩阵后,利用公式
为什么要Q矩阵和K矩阵的转置相乘(点积),因为点积能计算出相关性,得到1个的矩阵。除以
是为了防止数值太大进而训练时数值不稳定,难以训练,就是结构图中Scale部分.下面来看具体点积操作。
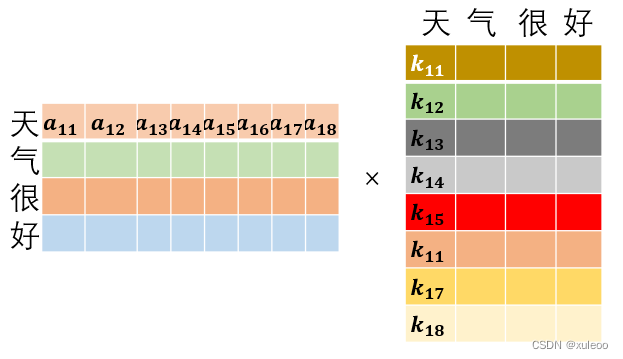
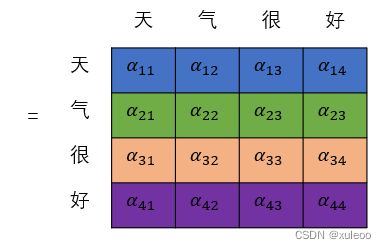
这样就能得到每个字词的相关大小,如"天"和”好“的相关大小是,将得到的矩阵经过softmax()函数归一化后就能得到每个字之间的相关大小。假设经过softmax()函数后,
大小分别是0.25,0.55,0.10,0.10。就可以 表示出"天"和句子本身中相关性最强的是
"气",其次是"天”本身,这样经过多次后,就能判断出哪些字词之间相关性最强。然后就是经过归一化后的矩阵与V矩阵的运算。
的矩阵和
的矩阵相乘。经过注意力机制后,输出矩阵的大小未改变。
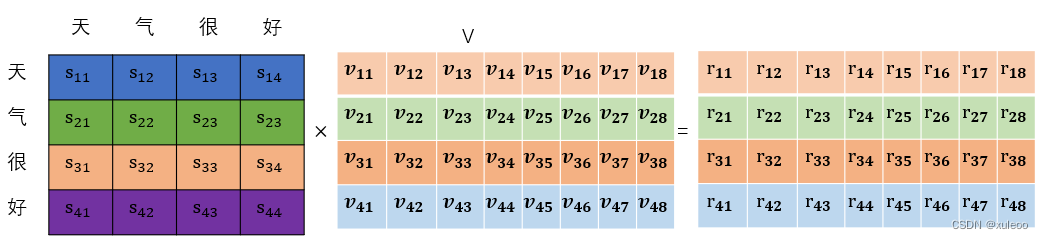
简单来说就是用字的权重和字词的特征依次从第一维到最后一个维度进行加权求和,得到一个和输入大小矩阵一致的矩阵。
模块中的mask的操作是由于输入序列有 长有短,为了使输入序列一致,需要使用0补充,而这些填充对句子完全没有任何意义,如果不使用mask,经过softmax函数后,会影响概率值,通常会使用一个负无穷的值代替。进而不影响输出概率值。如,输入向量是[0.5, 1.2, 0.8],经过softmax()的输出是:
![]()
而如果有零填充,输入[0.5, 1.2, 0.8, 0],则输出为:
![]()
由于0对句子毫无意义,而经过softmax()却输出一定概率,影响到全局概率,因此要用mask去掉。看经过mask后的输出,就是用一个负无穷值代替0.我们使用-10的9次方代替0.输入[0.5, 1.2, 0.8,-1e9],输出
![]()
这样经过mask,填充的值就不会对全局概率产生影响。接下来再看看代码:
- def attention(query, key, value, mask=None, dropout=None):
- # 得到词嵌入维度
- d_k = query.size(-1)
- # 计算Q矩阵与K矩阵装置,并进行缩放
- score = torch.matmul(query, key.transpose(-2, -1))/math.sqrt(d_k)
- # mask操作, 如果为零,就用-1e9填充
- if mask is not None:
- score = score.mask_fill(mask == 0, -1e9)
- # softmax操作,归一化
- p_atten = F.softmax(score, dim=-1)
-
- if dropout is not None:
- p_atten = dropout(p_atten)
-
- return torch.matmul(p_atten, value), p_atten
现在这些代码是不是看起来很简单了呢?
另外,在Transformer中,要注意self-attention和attention的区分。在编码器模块使用的是self-attention,而在解码模块中使用的主要是attention。self-attention是从句子本身提取特征,即可以理解成Q=K=V或者同源,即输入特征来自同一个x,而在译码块中,attention的输入并不是来自一个句子本身,来自编码器的输出和译码器的输出,它是来自两部分。

2.2.4 Multi-Head Attention
多头注意力机制(Multi-Head Attention)顾名思义,就是多个注意力机制的叠加。我曾看到一个说法,就是把多头注意力机制看成卷积操作中的多个卷积核,这是因为不同的卷积核提取不同的特征。这种说法个人觉得并不完全正确,有一点误导性。受到这个说法的影响,我一直认为多头注意机制就是用不同的矩阵生成不同的Q,K,V矩阵,这样就能提取到不同的特诊,看到代码后才觉得我的想法是完全错误的。当然多头注意力机制的确是关注到不同特征和关系,这一点是毫无疑问的,下面先看代码和结构图。

- class MultiHeadedAttention(nn.Module):
- def __init__(self, h, d_model, dropout=0.1):
- """
- h:多头个数
- d_model 词向量维数
- dropout 置零率
- """
- super(MultiHeadedAttention, self).__init__()
- # 判断向量维度是否被多头个数整除
- assert d_model % h == 0
-
- self.d_k = d_model // h
- self.h = h
-
- # 创建线性层
- self.linears = clones(nn.Linear(d_model, d_model), 4)
- self.attn = None
- self.dropout = nn.Dropout(dropout)
-
- def forward(self, query, key, value, mask=None):
- if mask is not None:
- mask = mask.unsqueeze(1)
- nbatches = query.size(0)
- query, key, value = \
- [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
- for l, x in zip(self.linears, (query, key, value))]
-
- x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
- x = x.transpose(1, 2).contiguous() \
- .view(nbatches, -1, self.h * self.d_k)
- # 最后使用线性层列表中的最后一个线性变换得到最终的多头注意力结构的输出
- return self.linears[-1](x)
从代码中可以看出,我们需要确保头的个数能够被词嵌入维度整除,从结构图中看到有四个线性连接层。对应代码
self.linears = clones(nn.Linear(d_model, d_model), 4)这句代码是多头注意力机制的关键
- query, key, value = \
- [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
- for l, x in zip(self.linears, (query, key, value))]
这段代码的意思是使用zip()han'sh将Q、K、V对应三个线性层,然后将Q、K、V经过这三个线性层,并将得到三个Q、K、V矩阵的维度变化成.
表示一次处理的序列数量,
表示头的个数,(-1)表示自适应维度计算。
。
是将得到的矩阵的第一维和第二维交换。先看我们的输入维度大小
。然后将得到的QKV经过注意力模块就能得到相应关系。最后将得到的矩阵恢复成
。即结构图中的concat操作。并经过最后一个线性层,即代码,(-1)就表示最后一个线性操作。
self.linears[-1](x)为什么要将输入序列划分为多个部分呢?对于每个头部,我们可以关注不同的特征和关系。例如,第一个头部可能更关注序列中位置较靠前的信息,第二个头部可能更关注序列中位置较中间的信息,第三个头部可能更关注序列中位置较后的信息。这个多头注意力表示能够同时关注序列中不同位置和语义信息的不同方面。通过这种方式,我们可以更细粒度地捕捉序列中的特征和关系。 那么你可能会疑惑,为什么这能关注到不同特征和关系呢,下面说说个人见解。
加入单头注意力机制的输入矩阵大小是
,那么
与
的转置相乘的大小为
。而用
=8划分后,就成为
,即8个100
64大小的矩阵。此时
与
的转置相乘的大小也为
,但是我们有8个这样的运算结果。这要一看,关注到到的特征不就更多了吗?到这里,恭喜你Transformer的结构框架学得差不多了,译码器中的各个框架和编码器的原理大同小异。
2.2.5 Feed forward
坚持以下,编码器的最后一个模块,这个模块很简单。结构如下图
原理很简单,两个线性操作,看公式
代码更简单,
- class PositionwiseFeedForward(nn.Module):
- def __init__(self, d_model, d_ff, dropout=0.1):
- # d_ff线性层的输出
- super(PositionwiseFeedForward).__init__()
- self.w_1 = nn.Linear(d_model, d_ff)
- self.w_2 = nn.Linear(d_ff, d_model)
- self.dropout = nn.Dropout(dropout)
-
- def forward(self, x):
- return self.w_2(self.dropout(F.relu(self.w_1(x))))
公式理解就是将第一个线性操作的结果放入激活函数relu中在经过一个线性层操作。这个线性层就是一堆神经元,用来不断更新权重大小直到与目标差异最小。哈哈,好了,到这里,编码器就完全结束了,transformer也差不多学完了。相信你一定从我的拙见中有点吧,看到这里的小伙伴请你点点赞。
2.3 Decoder
译码器部分的模块原理和编码器大同小异,无需多说。但有几点需要注意。译码器中Mask和attention与编码器中mask与attention有一定差异。编码器中attention的输入来自同一个,所以叫做self-attention,而译码器中attention的输入来自编码器的输出和目标句的输入。如下图
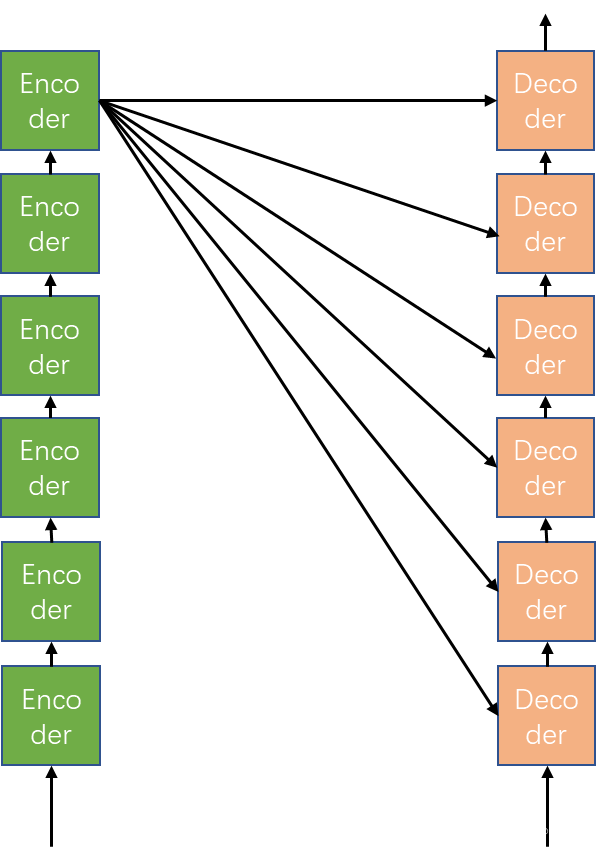
而在译码器中,Mask的作用不在是对填充的零进行操作,而是为了防止译码器的输入包含有未来是的信息。可看个列子:比如翻译 good morning。目标句子<start 早上好 end>使用Mask遮挡未来时刻的输入。
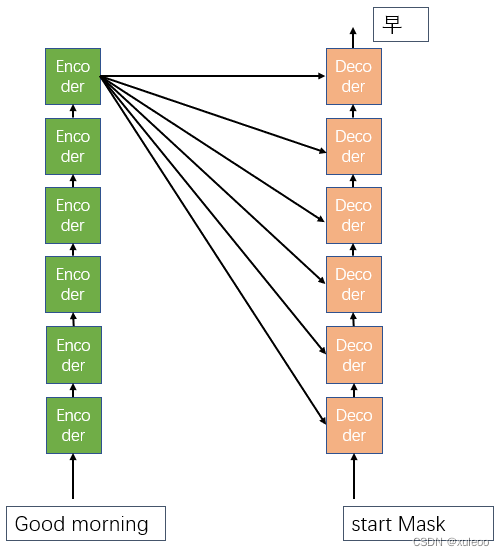
接着译码器的输入就变成了[start 早 mask],而不是[start早上]
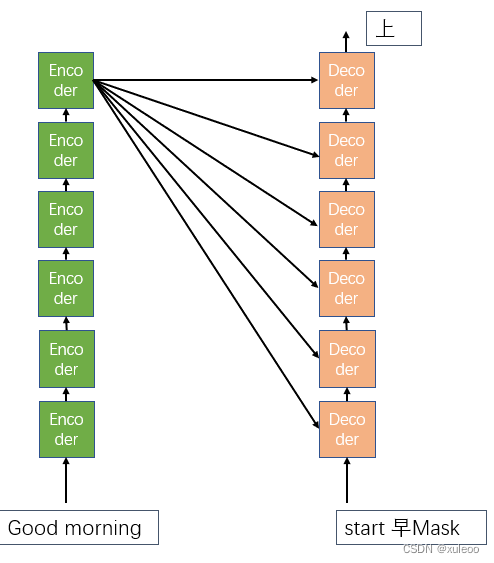
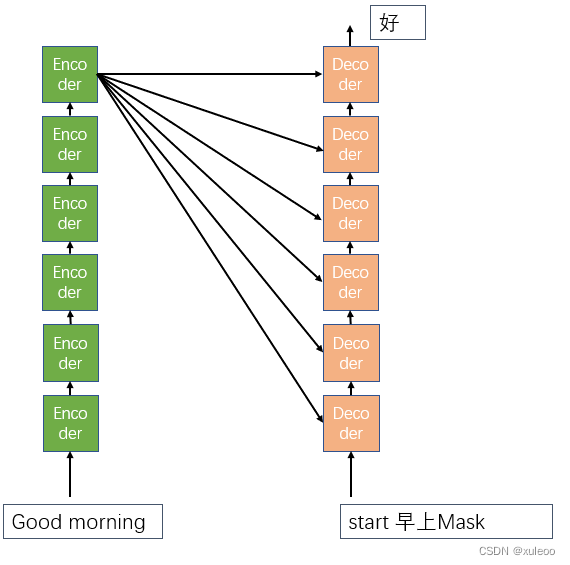
依次进行
直到输出句子标志结束符[end]输出,就代表这段序列处理结束了
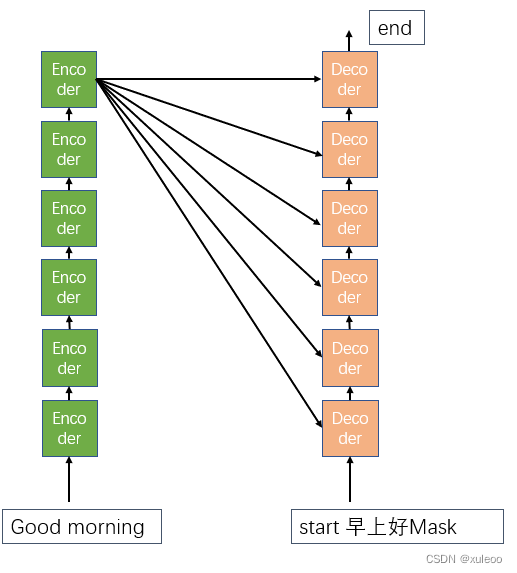
这里Mask的作用就是防止译码其中目标句的输入来自未来时刻,这样就无法直到你的输出是经过模型预测出的还是译码器直接的输出。总之,译码器的输入只能来自过去的时刻而不能来自未来的时刻。
到这里,基本解释完了各个模块的原理,也许你看完后任然觉得很懵,很正常的。估计是我解得不够清楚,你可以当作参考。毕竟我也是新手,而且也是第一次创作,有诸多不足或错误,欢迎指正。如果觉得对你有帮助的话,欢迎收藏加关注。

