
- 1基于深度学习、机器学习,神经网络,OpenCV,图像处理,卷积神经网络计算机毕业设计题目大全_基于神经网络的毕设题目
- 2使用python计算RMSR、MRE和R方、MAE_python实现rmse
- 3关于QWidget里的Widget::paintEvent (QPaintEvent * event)显示图片的问题(即qpainter.drawPixmap)_widget中paintevent无效
- 420240326 每日AI必读资讯_gatekeep ai 网址
- 5微信小程序的N种页面跳转方式(2024最新)_微信小程序页面跳转
- 6YOLOv8-seg 分割代码详解(一)Predict
- 7MATLAB 线性拟合直线示例 + MATLAB线性拟合中文文档(决定系数R^2公式与解释 与 带惩罚项的修改R^2)_matlab拟合直线
- 8爬虫实战——中国天气网数据_爬取天气预报的目的
- 9paddleocr的基本使用_paddleocr zlibwapi.dll
- 10word2vec原理详解及实战_word2vec原理与实战详解(一)
通过 Elastic AI Assistant for Observability 进行警报管理,最大限度地提高 IT 效率
赞
踩
作者:来自 Elastic Felix Roessel
管理和关联 Elastic Observability 中的信号和警报
随着组织采用日益复杂和互连的 IT 系统,各种监控工具生成的大量警报带来了严峻的挑战 - 我们如何有效地筛选噪音以识别和响应最关键的问题?
事件管理和关联是 IT 服务管理领域两个不可或缺的支柱。 本技术博客深入探讨了为什么这些实践在维护数字基础设施和服务的健康、安全和性能方面不仅是可取的,而且是至关重要的。 它还分析了生成式人工智能如何支持这一学科。
驾驭警报海洋:现代 IT 监控的挑战
现代 IT 生态系统会生成源源不断的警报,每个警报都表明系统内存在潜在问题或异常情况。 从性能指标到安全事件,这些警报的多样性甚至可能让最熟练的 IT 团队不知所措。 因此,关键问题可能会被淹没在噪音中,导致响应延迟、停机时间增加,并对整个基础设施产生潜在的多米诺骨牌效应。
事件管理:让混乱变得有序
事件管理作为第一道防线介入。 此实践涉及对来自各种监控源的警报进行系统收集、分析和分类。 IT 专业人员可以获得警报环境的结构化视图,而不是淹没在无边无际的通知海洋中。 这使他们能够从噪音中辨别出关键信号,并将注意力集中在更高价值的活动上。
事件关联:揭示更大的图景
但是,当看似不同的事件实际上是一个更大的谜题的各个部分时,会发生什么呢? 这就是相关性占据中心舞台的地方。 相关性通过识别不同事件之间的关系和依赖关系,提供对根本问题的整体理解。 这不仅仅是对个别警报做出反应; 这是关于理解它们如何互连并影响整个系统。
主动优势:通过事件管理和关联进行预测洞察
除了单纯的事件响应之外,事件管理和关联还提供了主动优势。 分析历史数据的模式和趋势使 IT 团队能够在潜在问题升级为关键问题之前对其进行预测。 这种预测能力可以最大限度地减少停机时间并提高系统的整体可靠性。
自动化:加速和增强响应
在我们了解事件管理和关联的复杂性的过程中,我们将探索自动化的关键作用。 Elastic® 等智能工具可以自动分析、关联事件并确定事件优先级,从而缩短平均解决时间 (MTTR),并释放宝贵的人力资源来执行更具战略性的任务。
加入我们,我们将了解事件管理和关联的各个层次,检查它们的技术细微差别和实际应用。 从高效的事件检测到全面的问题解决,这些实践不仅仅是管理警报,还在于增强 IT 基础设施面对现代挑战的弹性和性能。
事件管理的层次
为了解决事件管理的复杂性,了解数据在整个过程中如何演变及其在管理和关联事件中的作用至关重要。
首先,我们从多个来源收集数据,Elastic 凭借其集成新数据流的强大功能擅长处理这项任务。 理想情况下,这些数据集之间应该存在一些共性,例如,一个事件(例如 CPU 使用率过高)如何与另一个数据集相关(可能是通过延迟响应时间)。 这种重叠使我们能够建立因果关系 —— 高 CPU 使用率可能是应用程序性能下降的罪魁祸首。
接下来,我们利用 Elastic 将这种精细的监控数据转换为可操作的警报,例如针对特定应用程序响应时间异常长或特定容器或虚拟机中 CPU 负载过高的通知。 最初,每个警报都是独立运行的。
事件管理和关联的下一阶段是为这些孤立的警报提供额外的上下文,试图发现它们之间的任何互连。 目标是使系统能够对可能源自相似来源的警报进行分组。 这项关键任务是在事件层处理的,我们采用弹性案例管理将相关警报合并到单个案例中,从而阐明潜在的关联性。
最后,在事件层,我们定义事件升级为事件状态的条件。 这涉及到考虑各种因素,例如计划的维护周期。 例如,如果警报对应于计划系统停机的时间段,我们可能会忽略该事件。 这种洞察力确保将资源有效分配给真正值得关注的事件。

Elastic 是一款全面的解决方案,擅长管理每一层警报管理,并具有一套专为支持整个范围而定制的功能。 在无缝操作中,某些功能使流程完全自动化。
以 Elastic 为例,它能够生成与特定服务或指标相关的所有可能的警报。 毫无疑问,这是一个强大的功能。 此外,借助其分布式跟踪功能,Elastic 可以了解 APM 监控的服务之间的互连情况。
有关服务依赖关系的知识非常宝贵,Elastic 充分利用了它。 它利用这些数据,利用其图形功能将其与其他相关信息相结合,以实现复杂的相关性分析。此外,Elastic 可以生成警报,并在事件或 Kibana 案例级别有效监控和管理这些警报。 这确保了警报的简化处理,将它们与更广泛的事件模式和总体案例管理框架联系起来,从而促进对整个事件管理管道的全面监督。
这一切是如何一起发挥作用的?
然而,根据依赖性数据有效地将相关警报与其各自的案例进行匹配和更新需要一层自动化逻辑。 在 Elastic Stack 中,这种自动化是由 Watcher 精心安排的。 作为中央控制器,Watcher 协调信息的整理,使其与我们预定义的标准保持一致。 当然,这项工作也可以通过在 Elastic 旁边运行并使用其 API 的 Python 脚本来完成。
图形(graph) API 在可视化连接方面的强大功能在其表示依赖关系的方式中显而易见。 例如,考虑一个封装 APM 服务之间依赖关系的可视化图表。 Graph API 汇集这些数据,将每个警报与其所属的服务相关联,并直观地反映这些关系。 在图中,与特定服务相关的警报被链接起来,形成一个集群。 如果元素之间没有视觉联系,则意味着受监控生态系统内的警报之间缺乏依赖性。
当 Elastic 不仅监控单个应用程序或服务,而且监控大量应用程序或服务时,这一点变得越来越重要。 直观地解析和理解这些依赖关系的能力使团队能够洞察在系统范围内管理和响应警报,确保在整个应用程序环境中采用一致的方法进行警报管理。
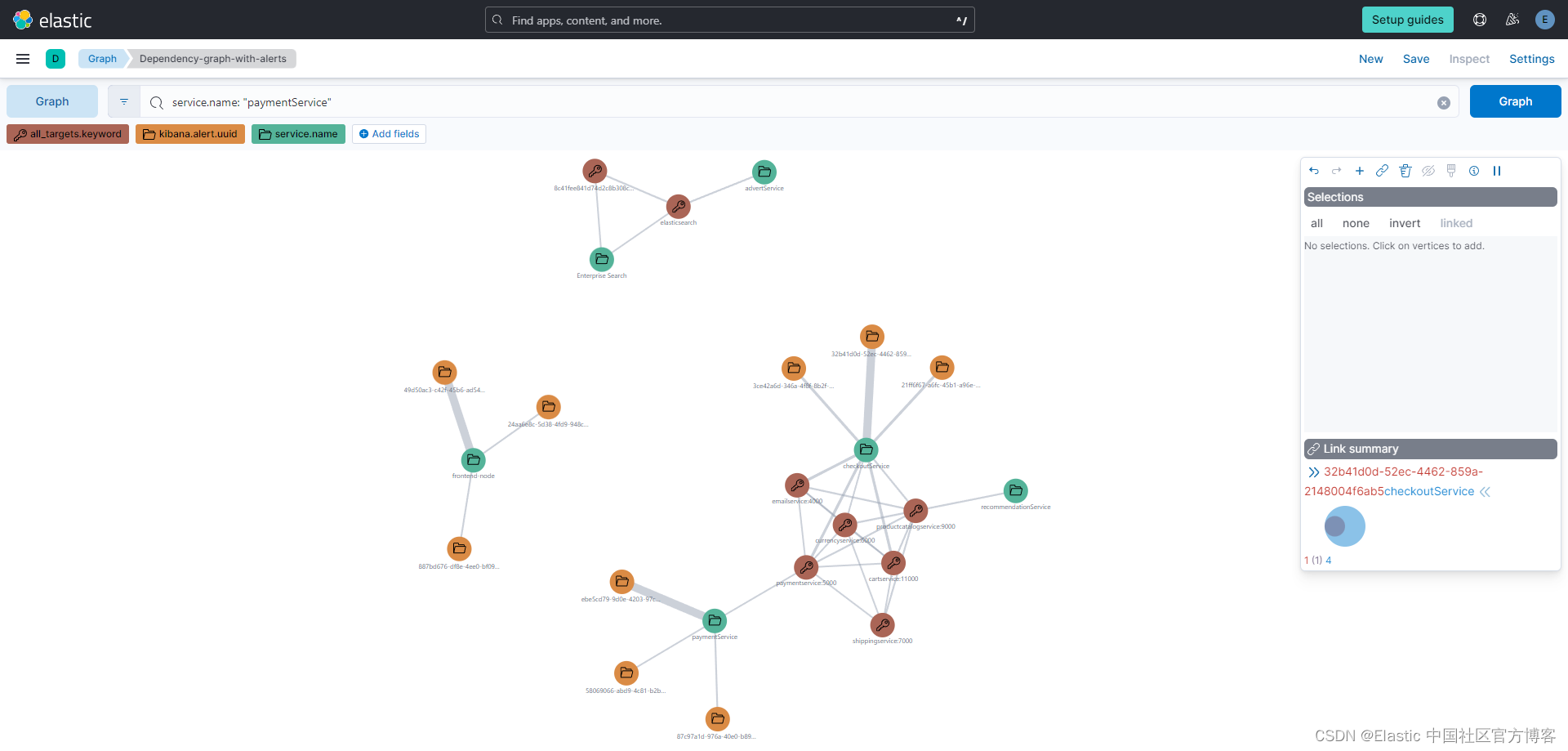
这种集成最终将相关警报聚合到 Kibana® 案例管理系统中的单个案例中。 由于这些警报与案例相关联,因此我们通过封装每个警报的主要详细信息的注释来增强案例。 此评论充当概要,提供对案例框架内警报核心信息的详细而简洁的理解。
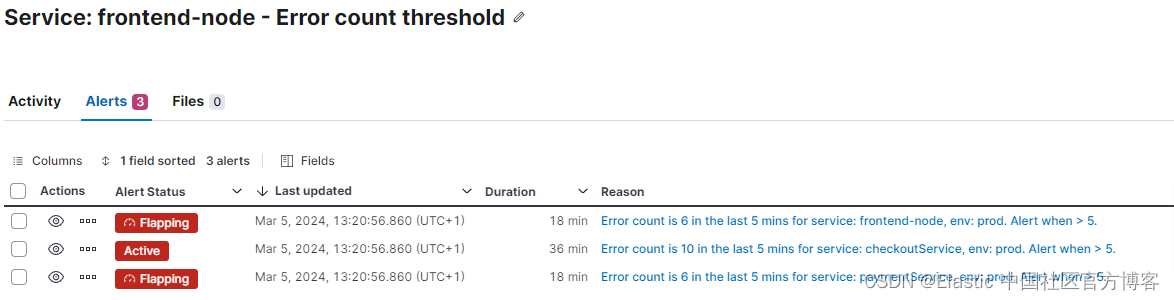
基于人工智能的自动管理案例的生成分析
一旦将所有相关警报合并到案例中,我们就拥有了丰富的数据集,可以进行更深入的分析。 该案例可能包含各种警报,每个警报看似不同。 此时此刻的关键任务是确定这些警报的根本原因 - 查明其他警报产生的主要问题。 凭直觉,人们可能会尝试确定第一个警报。 鉴于警报规则按不同的时间表运行并以不同的时间间隔触发,这种方法可能并不总是能产生准确的结果。
因此,我们需要的是一种精炼的情报形式,能够辨别哪个警报最有可能代表问题的根源。 这种能力可以识别模式和概率,以便进行更直接的分析。
这就是生成式人工智能成为强大盟友的地方。 它代表了这种场景的典型解决方案,借助 Elastic 的可观察性 AI 助手,我们拥有了一个可供使用的高级工具。 该助手采用生成式人工智能来筛选警报群,评估复杂性,并高精度地推断出根本原因,将一项艰巨的任务转变为易于管理的任务。 这可以帮助用户更快地将信息置于上下文中,帮助他们找到根本原因、解决问题并继续处理下一组警报。
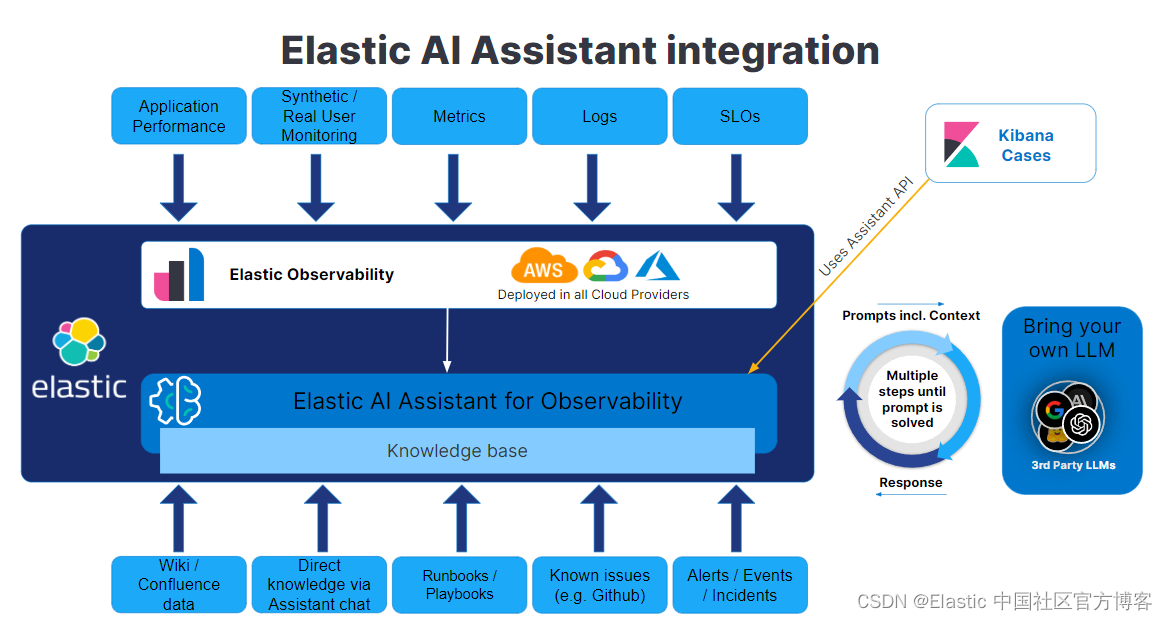
让我们揭开人工智能助手如何简化问题解决的神秘面纱。 将其想象为一名数字侦探,拥有 Elasticsearch® 数据库中每个房间的钥匙,能够访问任何数据。 但是,出于安全原因,可以通过 Elastic 的不同数据访问级别来定制其访问权限。
除了单纯的数据检索之外,助手还拥有一个知识库,其中可以包含手册或参考指南或仅包含有关观察到的服务的文档。 该知识库指导助手的响应,帮助其确定解决用户查询的最佳方法。 它评估是否存在可以为其分析提供信息的现有指南或值得纪念的方法。
该知识库不仅仅是一个静态存储库; 它是动态的。 它可以手动更新,也可以通过典型的 Elasticsearch 数据源(例如 Wiki、GitHub 或事件管理系统)自动更新。
一方面,助手随时准备自主地搜索 Elasticsearch 内的全部可观测数据。 另一方面,我们有一个充满高级问题数据渴望分析的案例。 将数据和助手这两者整合到一个单一的工作流程中,使可观测性工程师能够更快地追踪问题的根本原因,并努力有效地最小化 MTTR。 那么,让我们把这个计划付诸行动吧!
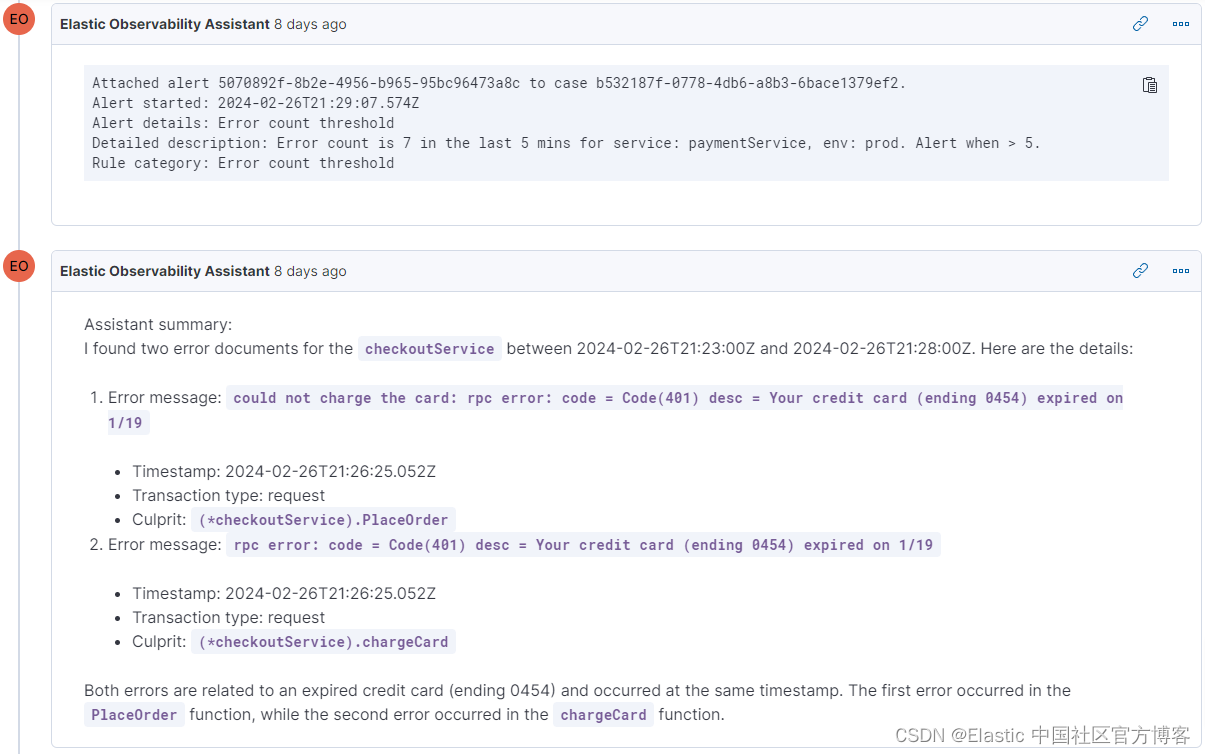
查看案例中的片段,你会注意到助手如何自动掌握案例的当前状态并生成发现概要。 在这种情况下,这种能力对于剖析警报非常有帮助。 虽然警报可能模糊地表明错误日志激增,但助手提供了关键的上下文。 这种丰富的洞察力迅速引导我们更接近根本原因,或为我们提供足够的信息来迅速确定解决案件的后续步骤。
超越噪音:克服警觉疲劳
为了概括本博客关于警报管理艺术的概念,让我们回顾一下该过程中的关键步骤。 这一切都始于 Kibana 生成警报,每个警报都固有地与特定服务、主机或其他基础设施相关联。 通过分析错综复杂的数据连接网络,我们发现了依赖关系,进而帮助我们制定全面的案例。 随着每个警报生命周期的进展(无论是已解决还是正在进行),此状态会反映在其相关案例中。 一旦所有关联的警报都被清除,案例甚至可能会自动关闭。
当活动案例包含特定标签(例如 NeedAIAssistance、NeedTeam 或 NeedSeverity)时,我们的助手会采取行动来推动定制行动。 根据存在的标签,Assistant 会动态地与 Elastic 内的数据进行交互,查阅知识库并根据需要应用不同的提示来为其分析提供信息。
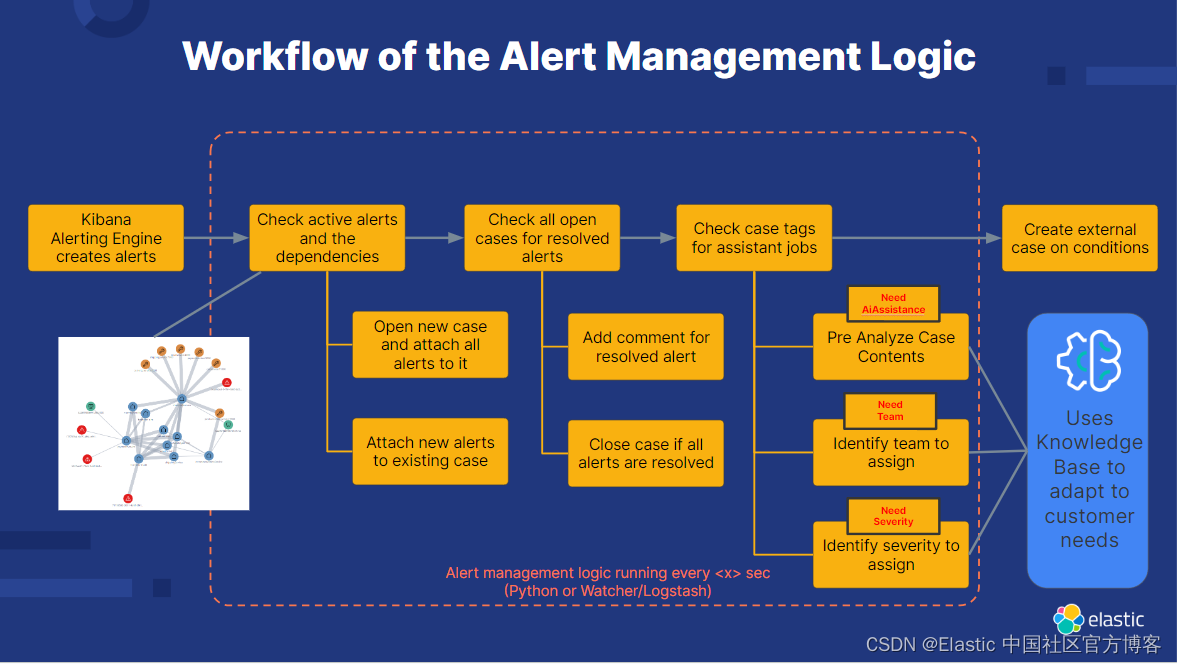
通过采用这种模型,我们在故障管理实践中实现了高度自动化和可重复性,并为用户保持了显着的灵活性。
让我们在一张幻灯片上画出整个想法。 我们已经了解了什么是事件管理和关联,并且 Elastic 可以通过其内置功能帮助遍历各层中可能出现的问题。 我们还了解到,助手能够总结单个案例的信息,并在无需人工交互的情况下提供深入的见解。 甚至可以利用 LLMs 的总体知识来分配案例并确定正确的严重程度。
综上所述,我们可以看到,Elastic 能够充分准备事件工单,以尽可能减少 MTTR。 随着人工智能助手的发展,我们甚至能够在任何人发现问题之前执行补救步骤。
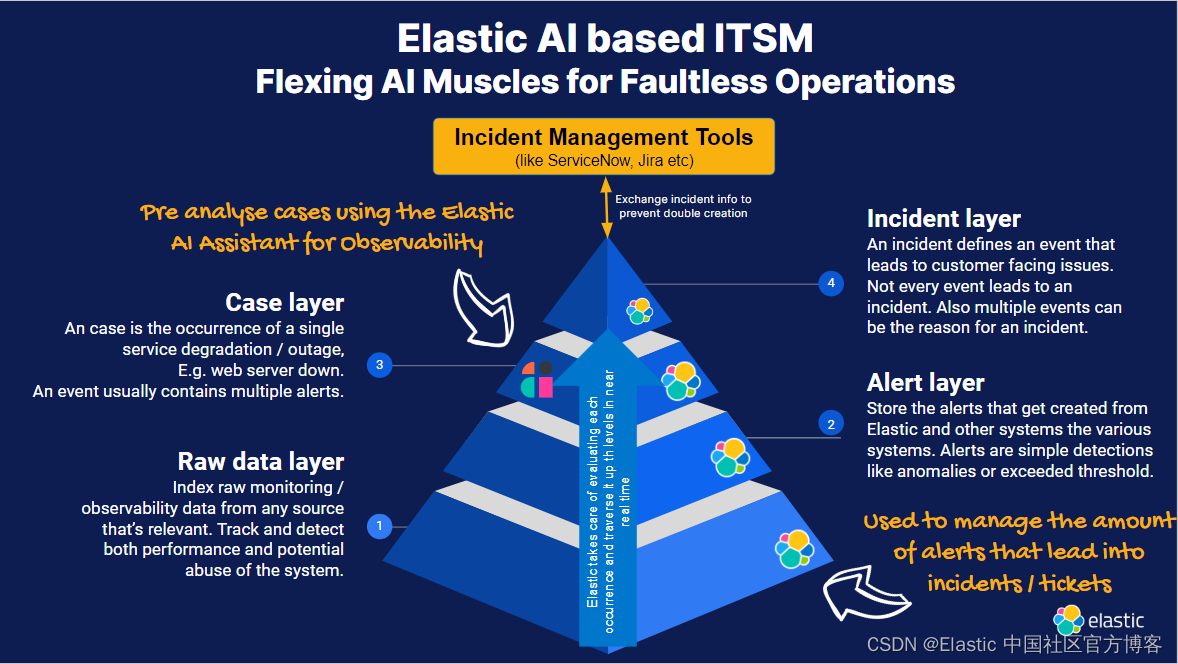
要在警报管理例程中体验这种创新方法,请探索 Kibana 和 Elastic AI Assistant for Observability 如何彻底改变你的工作流程。 与我们联系,引导你的运营走向更智能、高效、无疲劳的故障管理。
使用 Elastic AI Assistant for Observability 查看生成式 AI 的用例。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
在这篇博文中,我们可能使用或引用了第三方生成人工智能工具,这些工具由其各自所有者拥有和运营。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害负责。 使用人工智能工具处理个人、敏感或机密信息时请务必谨慎。 你提交的任何数据都可能用于人工智能培训或其他目的。 无法保证你提供的信息将得到安全或保密。 在使用之前,你应该熟悉任何生成式人工智能工具的隐私惯例和使用条款。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine 和相关标记是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。

