
- 1nginx转发mysql请求_nginx转发mysql连接
- 2git checkout commit出现问题,出现no branch问题_commit to no branch
- 3GPT-4大爆炸:如何用AI技术革新软件测试开发领域_怎么用gpt做技术问题诊断
- 4关于使用Go语言创建WebSocket服务浅谈_gorilla/websocket文档
- 5燕山大学计算机科学与技术分数,燕山大学计算机科学与技术专业2016年在江苏理科高考录取最低分数线...
- 6机器学习主要类型(五):系列总结_思维导图(监督学习、无监督学习、半监督学习、强化学习)
- 7分析二手房房价影响因素的Python代码实现_python二手房房价影响因素分析
- 8文件压缩归档软件 ARJ.EXE 的基本用法
- 9YOLOv8改进算法之添加CA注意力机制_yolov8 加注意力机制
- 10Python与人工智能到底有什么关系呢?Python学习_python与人工智能的关系
使用 Elastic 作为全局数据网格:将数据访问与安全性、治理和策略统一起来
赞
踩
作者:来自 Elastic Woody Walton

“数据网格(data mesh)” 这个术语并不是特别新颖,但对它的定义及其功能的认知可能并不普遍一致,因此让我们稍微探讨一下。
数据网格 (data mesh) 与数据布局 (data fabric) 的区别
我们可能应该从它不是什么开始。 “数据网格” 并不等同于 “数据布局”。 数据布局允许来自企业各个部门(从边缘、网络、应用程序、设备等等……真正的各个方面)的数据流能够被可靠地接收并持久化,从而使其可以供任何可能想要摄取该数据的消费者使用。这确实是重要的部分:虽然一些数据布局工具提供执行低级数据操作和基于逻辑的路由的能力,但数据布局实际上不能对接收到的数据执行任何操作,除了将其传递。
相比之下,数据网格使得从整个网络收集的数据可供检索和分析,只要用户具有访问权限即可。 数据网格提供了一个统一而分布式的层,简化和标准化数据操作,如搜索和检索、聚合、相关性分析和交付。 数据网格创建了一个数据产品,其他服务和业务操作可以使用该产品来更快速、更全面地回答问题,从而作出决策。
因此,或许更简洁地定义区别的方式是在数据的可用性上:数据布局提供原始或半加工的数据;而数据网格让你实际上可以使用它。
如果数据网格有希望不仅仅成为一个概念或营销术语,它必须满足一系列明确定义的标准,以解决有效的业务需求并在此过程中提供可靠的价值。为此,让我们让 “数据网格” 这个时髦词汇变得更加真实和实用。
数据网格克服了数据孤岛 (silos)
也许你正在想,我的组织并不是那么大,为什么我需要类似数据网格这样的东西呢?做出良好的业务决策(在各种规模上)需要快速访问所有潜在相关信息,无论来源、格式或位置如何。 即使是执行最基本的操作,大多数组织今天不仅必须搜索内部数据存储库,而且还严重依赖于分布式的、通常是基于云的超大规模服务来存储他们的数据。 不幸的是,这通常意味着需要将服务粘合在一起,以在不同的、不连贯的数据平台之间创建点对点连接。这通常还涉及将近实时数据平台与为长期低成本存储而设计的存档数据存储系统相结合 —— 而不是快速、灵活的检索。
问题的复杂性在于,每个不同的存储库都提供完全不同的查询和检索方法(更不用说保护数据的方法了)。这些是臭名昭著的 “数据孤岛 (data silos)”,它们阻止了业务运营所需的准确、快速访问相关数据的能力。
数据网格的核心特征
通过对当今大多数组织的数据访问脱节状态的惨淡描述,让我们定义数据网格成功应具备哪些核心要求。。
1) 边缘数据收集 首先且最重要的是,
数据网格需要能够在边缘或接近边缘的地方收集数据。 从边缘到集中位置的收集对于实时分析来说太慢了,复制数据的成本太高了,而且对网络操作有害。 在复制数据在传输过程中也可能存在安全问题,以及数据同步问题(哪个版本是权威性的?)通过在边缘收集数据,保持它接近生成的位置,并通过数据网格访问它,你能够避免堵塞网络管道,仅检索查询命中。
2) 所有数据的近实时访问来自共同平台
收集的数据必须通过单一查询实时可访问 —— 不能存储在多个单一用途的数据孤岛中。 你需要一个专为速度、规模和灵活性而构建的搜索分析平台。 数据网格必须能够使用通用语法访问所有类型的数据。所谓的 “联合搜索(federated search)” 系统的主要问题在于,在不同的存储库之间进行查询和结果转换是在查询时完成的,而数据网格的分布式操作模式,所有数据都被索引并且可以在一个通用平台上查询(和排名)。
3) 灵活的故障转移、高可用性(HA)和连续运营(COOP)
数据存储需要能够自动从硬件或网络问题中恢复过来。 如果在面临中断时无法依赖数据可用,那么系统就不足以被称为分布式。 数据弹性和高可用性是复制数据的唯一可接受用途 —— 复制而不是重复。 数据网格需要能够在网络的关键部分遇到故障时加速广泛分布的操作,并在关键网络部分遭受故障时允许连续运营。
4) 真正的分布式——无需复制,非中心化
我们需要能够从任何一个位置查询,并且也能从所有远程站点获取结果。为了联合查询而跨网络复制数据既慢又低效,也不易扩展。此外,通过分布式数据平台,你可以获得并行计算资源的好处;与之相对,单体中心化仓库越大,响应就越慢。
5) 集成的安全性,集成的数据功能
最后,你需要一个通用平台,让你能够同时、统一地跨本地和远程集群运行完整的分析套件,同时也考虑到数据访问控制。为了可扩展性和安全性,数据访问控制必须在数据检索引擎内实现。依赖每个不同的仓库(再次强调,“联邦 - federated” 模型)来转换和平等地应用控制措施太慢了,也容易出错。过滤结果之后(即,获取所有匹配查询的结果,然后逐一决定哪些结果将被交付)既慢又麻烦,且可能导致数据泄露。数据访问控制需要在搜索引擎中应用,以便将用户的凭证(基于角色的访问控制和基于属性的访问控制)作为查询的一部分,并用作内部解析哪些内容是允许的过滤器,在返回结果之前。这种模型也适用于数据网格远程节点之间的安全性。
现在我们已经确定了运行分布式数据网格所需的基本要求,那么一旦我们拥有了它,我们能用它做什么呢?
关于复制 (replication) 与重复 (duplication) 的说明
在这里,我区分了 “重复 (duplication)” 和 “复制 (replication)” 的术语。大多数组织当前状态的一个核心问题是系统之间不必要的数据重复(以及相关的低效 “联邦 (federated)” 搜索解决方案),以支持扩展的用例。重复正如其名:将数据从一个系统复制到另一个系统,多个地方重用相同的数据。另一方面,复制 (replication) 用于完全不同的目的:为了高可用性、故障转移、安全保管(例如,作为证据或记录保持的目的),或者将数据带到将被访问的地方更近的位置(将最后一个想象成 CDN,即内容交付网络,它缓存数据的本地副本,以便更快地响应)。
在数据层的整合
将所有组织数据可用于一个统一的层中,提供互联网搜索的速度和规模,一次性解决了许多问题。在此之前,每个应用程序都被设计为只能访问其自己仓库的数据,现在所有数据都合并在一起,通过一个统一的访问点、一个统一的 API,使用规范化的查询和排名方法共同访问。
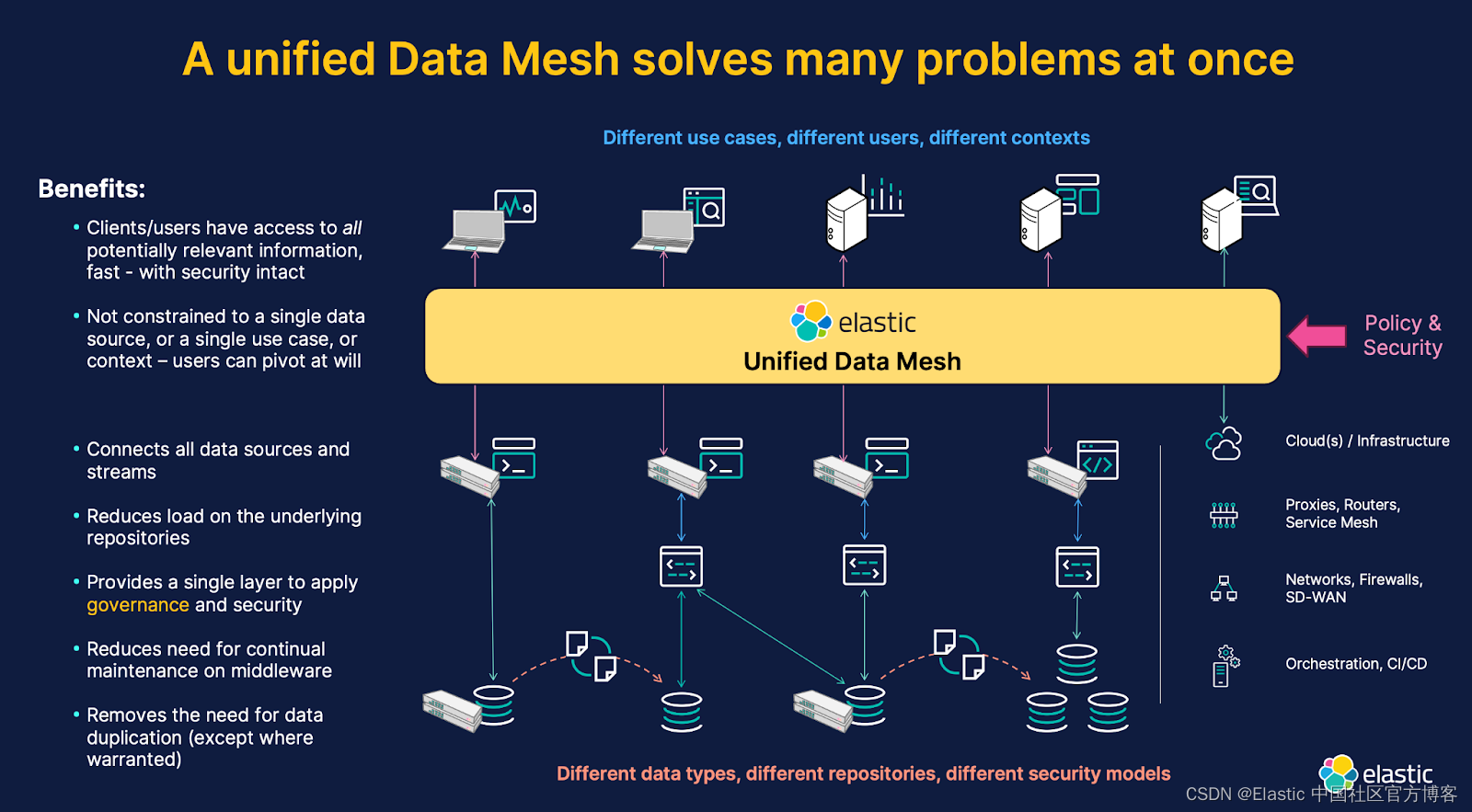
所有相关数据对所有用例都可用,无论其原始来源或格式如何。这意味着你不再需要面临选择数据将驻留在哪里(或在哪个解决方案中)的问题,也不会被迫为多个用例重复(duplicate)所需的数据。数据网格仍然允许在必要时进行数据复制 (replication) —— 例如,为了数据共位置和缓存,或为了确保为调查或证据目的保留记录 —— 但你不再需要为每个需要它的用例在多个地方维护同一数据的副本。
数据可以根据需要保留在原始仓库中,而数据网格提供了一个统一层,不仅加速并简化了对所有数据的访问,还减少了对底层仓库的非计划负载。大多数仓库被设计为只支持与其支持的应用程序相关的查询量;它们无法在不增加额外资源的情况下处理任何额外的意外或特设查询负载。
使用统一的数据网格而不是联邦搜索系统的另一个好处是,你可以利用数据网格提供的所有常见强大的查询语法和排名机制,在所有类型和来源的数据上;你不受限于你正在查询的数据仓库的 “最小公分母 (lowest common denoninator)” 能力。
统一的数据安全、治理和策略
统一数据网格的一个强大的附带好处是能够统一全球数据管理操作,例如数据安全、治理和策略应用程序。当试图将安全性或治理应用于不连贯的系统时,这些问题特别棘手,因为每个系统都有不同(且不等价)的安全控制机制、不同的访问协议和不同的策略控制。安全性和治理可以应用于数据网格层,并且通常可以简化为更普遍地应用于数据的性质,而不是数据支持的特定用例。
Elastic 作为全球数据网格
Elastic® 的搜索分析平台整合了数据网格的所有核心功能,并且在平台上所有输入的数据上启用了广泛的额外功能,例如机器学习、自然语言处理(NLP)和语义搜索、检测、警报、可视化、仪表板、报告等等,所有这些功能都集成在一个平台上。
实际上,有两个关键能力使得 Elastic 平台成为一个独特强大的全球数据网格:
- 跨集群搜索(Cross cluster search - CCS)使得 Elastic 能够作为一个分布式数据平台运行。CCS 能够连接远程数据集群,并跨越这些集群进行搜索,就好像它们都位于同一个分布式集群中一样,无论它们的物理位置如何,或它们部署到什么平台上。这意味着你可以将本地集群连接到全球各地的远程集群,无论是在公共或私有云/多云托管环境中,甚至如果需要的话,也可以连接到组织外部的合作伙伴集群。跨这些远程集群共享的数据仍然受到主机集群安全性的保护。

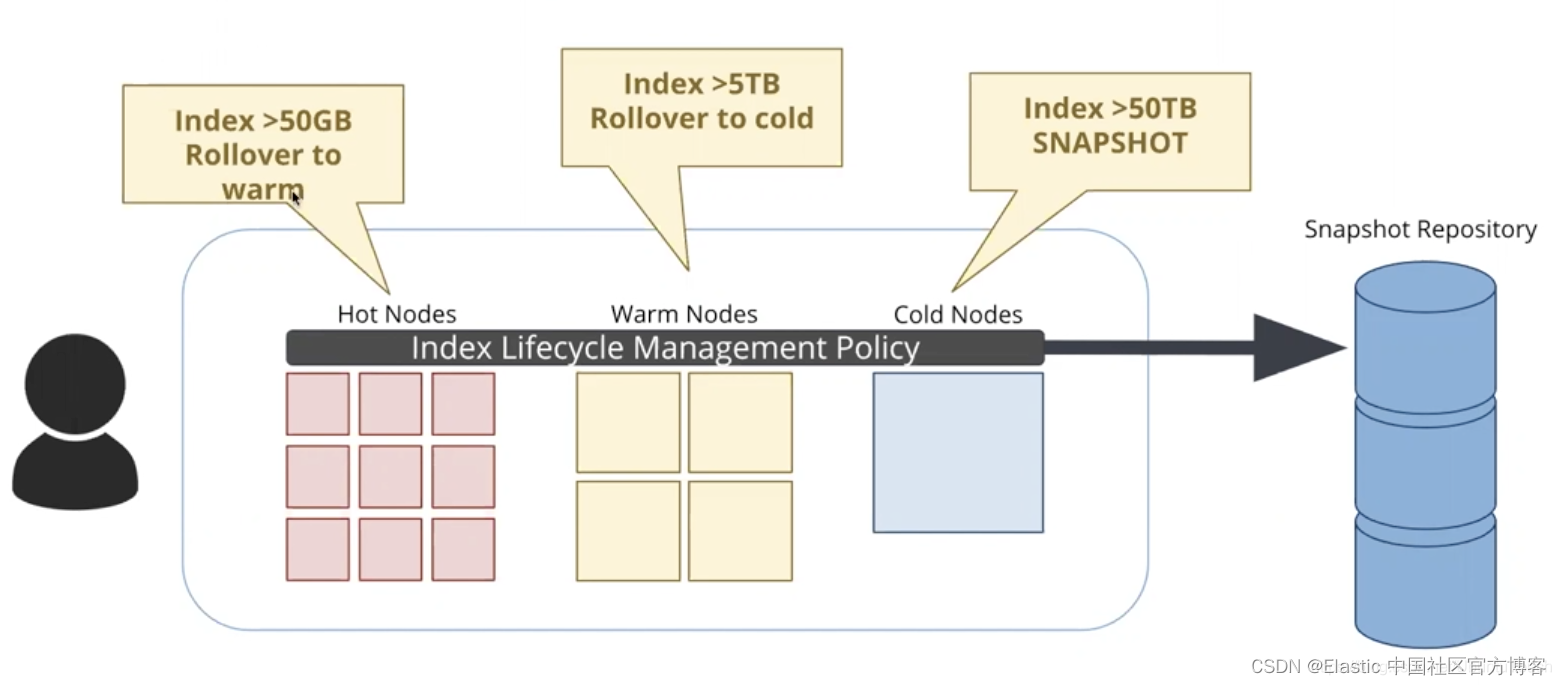
- Elastic 的可搜索快照功能使数据网格成本效益高,且可以将其覆盖范围潜在地扩展到数年之前。Elastic 有能力使用基于策略的数据管理来自动处理不同密度和访问模式的数据。我们称这个特性为索引生命周期管理(ILM)。可搜索快照在 ILM 的两个层级中使用 —— 在冷层级中,通过使用可搜索快照来存储副本,你可以将所需的 Elasticsearch® 数据节点减少一半;其次在冻结层级中,只有数据的索引保持在内存中,而数据本身存储在廉价的对象存储上(如Amazon S3、Azure Blob Storage或甚至本地文件共享)。这允许巨大的节省,并能够在其生命周期内保持更多数据的活跃和完全可搜索。权衡是响应时间:通常需要数小时或数天才能将数据 “重新水化(rehydrated)”(从存档中拉回到活动系统中),而冻结层级的数据仍然完全索引,并且通常在几秒到几分钟内响应。
拥有为你的组织提供动力的数据网格,使得数据几乎实时地在需要的地方可用的可能性无限。全球数据网格是许多业务操作的使能技术,实际上,许多最新的数据安全和分析设计(例如,零信任)绝对依赖于只有一个完全统一的数据层才能提供的能力。

