
- 1深度学习数据集制作_一篇文章搞定人工智能之深度学习创建训练数据集的方法
- 2list转树形,亲测可用
- 3大模型从入门到应用——LangChain:提示(Prompts)-[提示模板:基础知识]_大模型有官方prompt吗,叫什么
- 4人工智能如何帮助项目经理做出更好的决策_ai项目经理
- 5自动化测试 java调用adb命令_java 可以调用adb指令吗
- 6MacOS代理设置(桌面应用代理设置&Terminal代理设置)
- 7Joint European Conference on Machine Learning and Knowledge Discovery in Databases(ECML-PKDD)会议怎么样?
- 8NLP学习(5) 语言模型_nlp 模型如何做判断
- 9Vision Transformer代码
- 10扩散模型基础(一):基于BasicUNet的扩散模型算法搭建_扩散模型 unet
NLP关系抽取和事件抽取_事件关系抽取
赞
踩
关系抽取
关系抽取又称实体关系抽取,以实体识别为前提,在实体识别之后,判断给定文本中的任意两个实体是否构成事先定义好的关系,是文本内容理解的重要支撑技术之一,对于问答系统,智能客服和语义搜索等应用都十分重要。

当前深度学习方法在关系抽取任务上取得了很好的效果,这是由于深度学习可以自动抽取文本特征。深度学习做关系抽取的方法有很多,诸如基于卷积神经网络的关系抽取和基于预训练模型的关系抽取等。其中基于卷积神经网络的方法是最典型的方法之一。
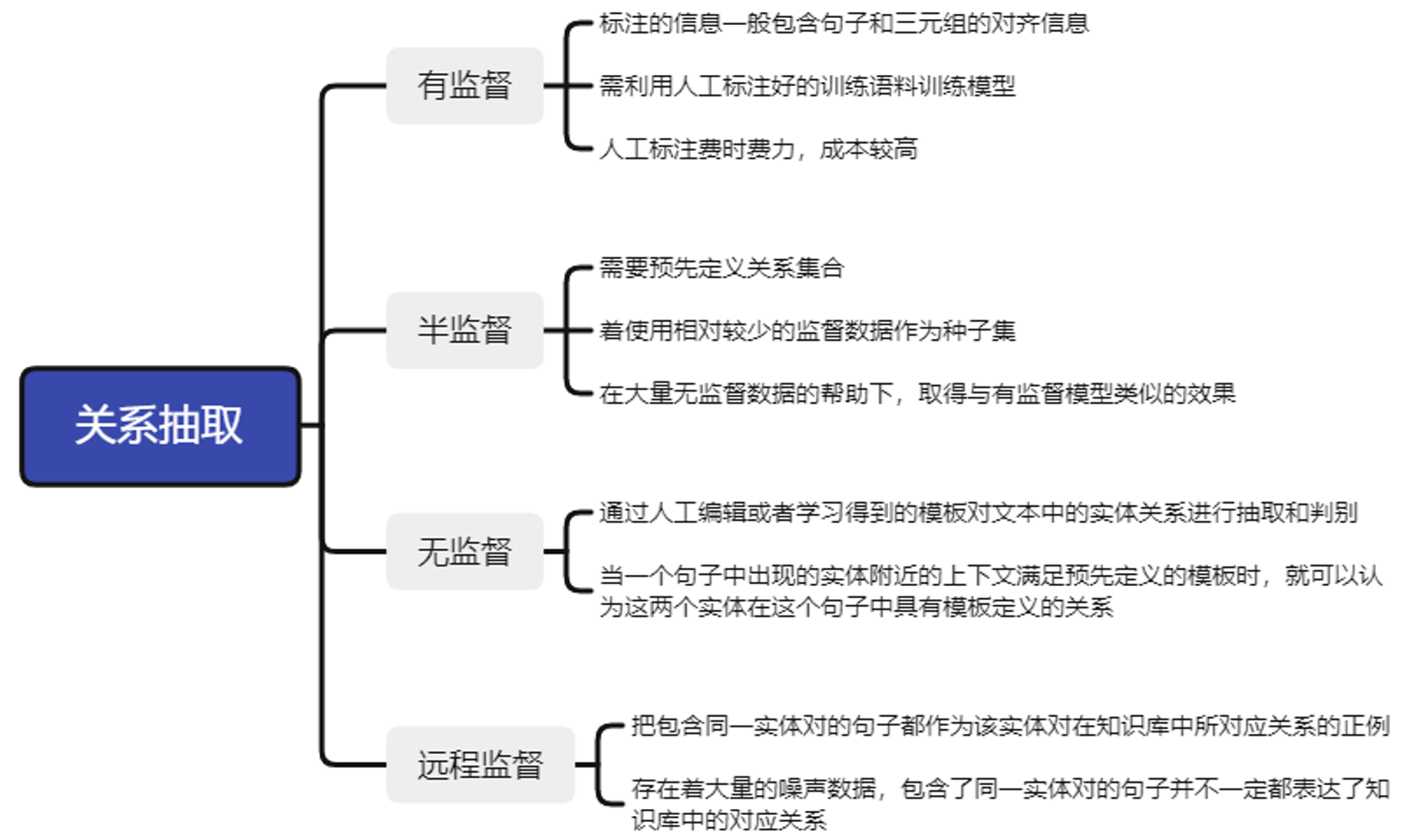
基于卷积神经网络的关系抽取算法
卷积神经网络应用到关系抽取领域中的一个核心算法是PCNN算法。首先通过单词的词嵌入和位置嵌入把句子转换成向量表示,然后通过卷积神经网络的卷积操作和池化操作提取句子向量的特征向量,最终进行关系预测。
PCNN算法由输入模块、卷积模块、池化模块和分类模块四个模块组成,模型结构如下:
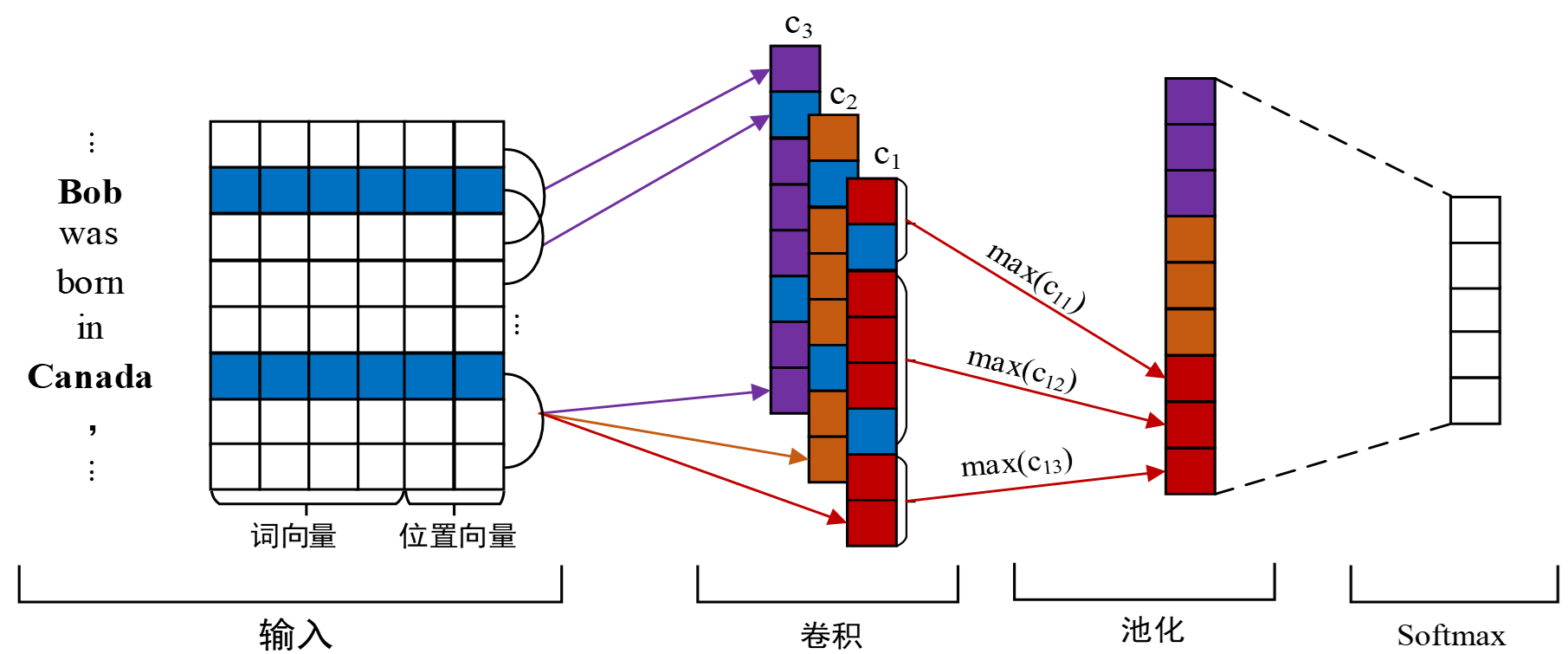
词向量:计算机无法识别人类文字,所以我们利用word2vec等词向量构建工具将句子中的每个词语转化成低维实值向量,使得计算机可以理解识别每个单词。
位置向量:位置向量代表句子中每个词语与实体对的相对位置,单词was到实体Bob和Canada的相对距离分别为1和-3。
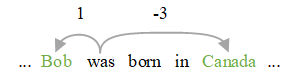
特征抽取:特征抽取是抽取句子中的主要特征来表示句子的语义信息。由于输入句子的长度不统一,头尾实体之间的关系信息可能分布在句子的任何地方,这就意味着必须要从句子中抽取不同的局部特征来预测目标实体对所属的关系类型。在卷积神经网络中,卷积操作是获取这些局部特征的常用方法。
分段池化:常用的池化操作有最大池化、平均池化和全局池化等,以最大池化为例,抓住每一个特征向量中最具有代表性的特征,而对于分段池化操作,根据两个给定的实体的位置,将卷积后的句子特征向量分成三个片段,进而对每个片段执行最大池化操作。
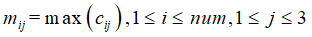
关系分类:将每条句子的特征向量输入到softmax分类器中进行关系分类。计算出该特征属于不同关系的概率,筛选出概率最高的关系即为该句子中实体对的关系。
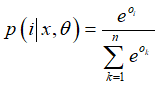
基于损失函数做反向传播优化:使用随机梯度下降(SGD)技术来最大化对数似然J(θ)。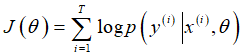
通过使用反向传播算法来优化神经网络中不同层神经元的参数。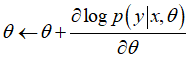
基于远程监督的关系抽取
起因:上面基于监督的关系抽取存在问题:很多领域都存在标注语料不足,人工标注成本过高、费时费力的问题。
策略:是否可以通过自动化的方法快速标注语料。
方法:远程监督。
远程监督基于的基本假设是:如果从知识图谱中可获取三元组R(E1,E2)(注:R代表关系,El、E2代表两个实体),且El和E2共现于句子S中,则S表达了E1和E2间的关系R,标注为训练正例。
远程监督存在的问题:远程监督假设一个实体对只对应一种关系,但实际上实体对间可以同时具有多种关系。
小样本关系抽取
起因:很多领域都存在标注语料不足,人工标注成本过高、费时费力的问题。
策略:是否能够在少量标注语料的情况下实现满足性能要求的关系抽取。
方法:小样本关系抽取。
小样本学习任务:小样本的训练集中包含了很多的类别,每个类别中有多个样本。在训练阶段,会在训练集中随机抽取C个类别,每个类别K个样本,构建一个task,作为模型的支撑集(support set)输入;再从这C个类中剩余的数据中抽取一批(batch)样本作为模 型的预测对象,查询集(Query set)。即要求模型从C*K个数据中学会如何区分这C个类别,这样的任务被称为C-way K-shot问题。
联合抽取
广义上讲,关系抽取任务分为了两个子任务 :实体抽取任务和关系抽取任务。实体抽取任务与命名实体识别的作用相似,关系抽取任务实质在于对抽取出的实体进行关系分类, 是一个分类任务,基于这种方式的关系抽取称为流水线(Pipeline)方法。
联合抽取,也称为端到端抽取,所谓端到端是指在不对输入文本进行改造的情况下,直接将原始文本送入模型进行训练,并输出最终结果。联合抽取是将 Pipeline 中的两个子任务模型合并为一个任务模型,在此模型中同时抽取出实体及其关系。
现有的联合抽取模型总体上分为两大类 : 共享参数的联合抽取模型、联合解码的联合抽取模型。
共享参数的联合抽取模型
通过两个子模型之间的参数共享实现联合,使用不同的解码方式得到实体或者关系。
共享参数可以加强子模型之间的交互,主要是共享词嵌入层、共享编码层,之后一般遵从两个子任务本身的特点而使用各自的模型,如对于实体抽取常使用 LSTM+CRF 获取序列标注结果 ;而对于关系抽取子任务多使用 CNN 进行特征提取,最后使用 Softmax 进行关系分类。

联合解码的联合抽取模型
使用一种解码方式同时得到实体及关系。联合解码能实现实体之间、实体与关系、关系之间的交互。
使用序列标注的方式来进行联合抽取, 即直接提取实体及其关系,而不是分别识别实体和关系。使用序列标注进行联合抽取的核心思想是将关系与实体同时标注,既实体是“带有关系的实体”,可将关系抽取任务转换成序列标注任务,常见的标注方式主要有总体 BIOES 标注、总体 BIES 标注、总体 BIO 标注等。
事件抽取
基本概念: 事件作为信息的一种表现形式,是指特定的人、物,在特定的时间、地点相互作用的客观事实。如什么人,在什么地方,做了什么事。事件抽取的目的是从非结构化的自然语言文本中抽取出能够准确表述述事件发生的结构化文本。
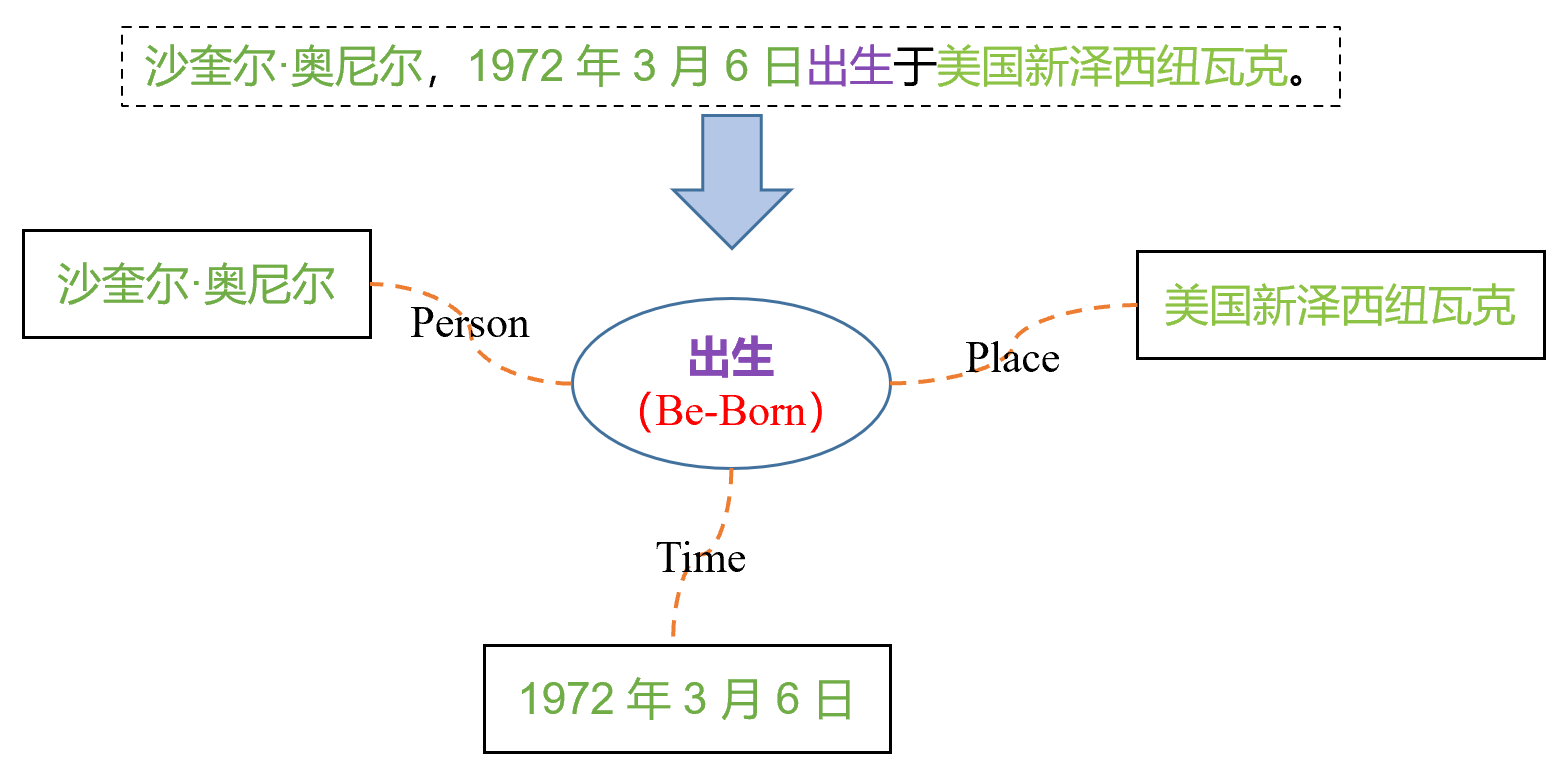
ACE 2005 是目前应用最广泛的事件抽取数据集,涉及英语、汉语和阿拉伯语三种语言的训练数据。 ACE 2005标注了句子中的事件触发词、事件类型、事件元素及对应的元素角色,并定义了8个事件类型,共33个子事件类型,不同的事件类型包含不同的事件元素角色。
子任务:
1.事件检测
检测文本中包含的事件并对其进行分类,传统的事件检测方法为识别文本中事件触发词,然后对触发词进行分类。
事件检测的主要研究方法有基于模板匹配和基于机器学习两大类。
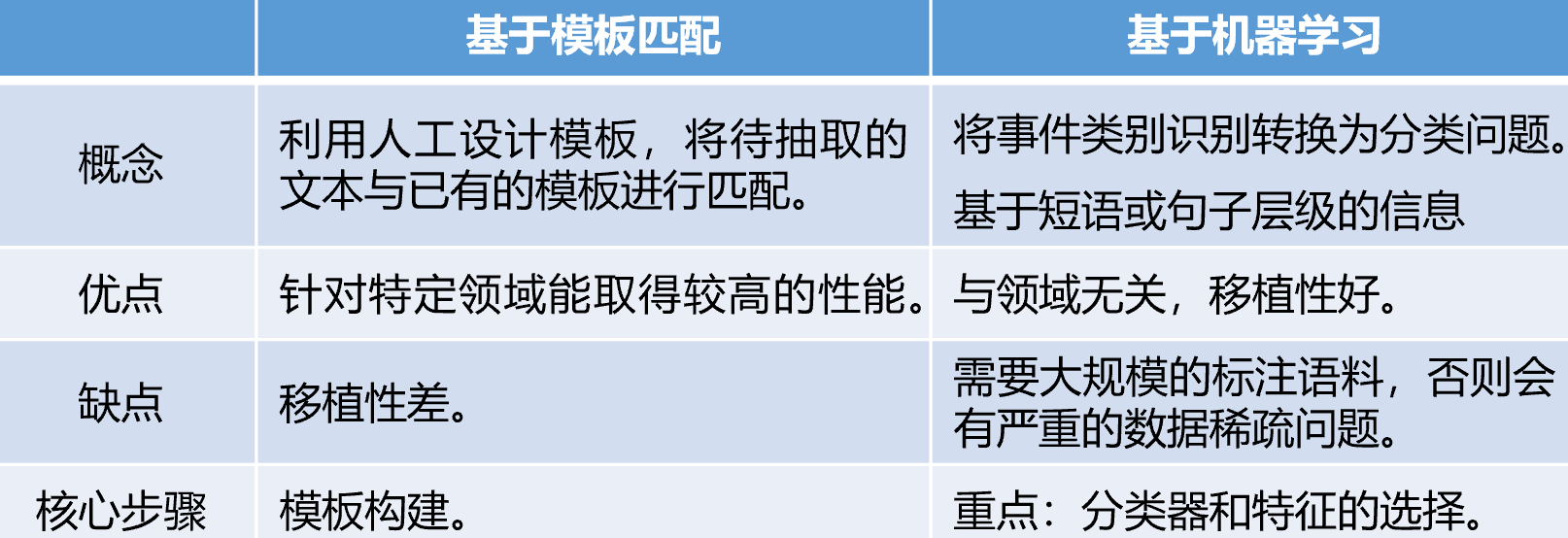
基于动态多池化卷积神经网络的事件检测模型包括词嵌入学习、词汇级特征提取、句子级特征提取和事件分类四个模块,模型结构如下:
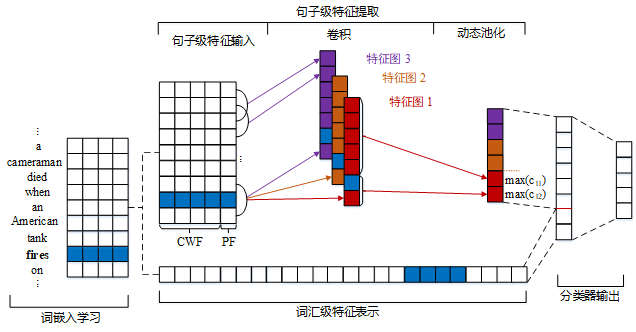
输入:词汇级特征和句子级特征。其中,词汇级特征表示是由词嵌入向量首尾逐个拼接形成的;句子级特征包括上下文词向量特征(CWF)和句子中各单词与候选触发词之间的相对距离构成的位置特征向量(PF)。
卷积操作:通过卷积核在句子级特征上进行卷积操作来获取整个句子的语义,并将其压缩到特征图中。
动态多池化:此操作以候选触发词为界,将卷积操作得到的特征图分割为两个部分,然后在每段特征图上分别进行最大池化,然后将所有的池化结果进行拼接得到特征向量。
分类:将动态多池化得到的特征向量和词汇级特征表示进行拼接,得到新的特征向量,然后利用全连接层和Softmax分类器得到事件的分类结果。
采用 DMCNN的方式实现事件检测:
下面是基于Pytorch的DMCNN事件检测的具体实现代码,整体结构是以词向量表示的句子上下文作为输入,然后通过卷积和动态多池化操作得到句子级特征,并与词汇级特征进行拼接输入到分类器,最后使用交叉熵损失函数计算损失,调整模型参数。
def forward(self): x = torch.cat((self.char_lookup(self.char_inputs), self.pf_lookup(self.pf_inputs)), dim=-1) #x: 句子级特征向量 y = self.char_lookup(self.lxl_inputs).view(self.config.batch_t, -1) #y 词汇级特征向量 x = torch.tanh(self.conv(x.permute(0, 2, 1))) # 经过卷积操作之后得到的特征向量 x = x.permute(0, 2, 1) x = self.pooling(x) # 动态多池化操作得到的特征向量 self.conv = nn.Conv1d(self.config.char_dim+self.config.pf_t, self.config.feature_t, self.config.window_t, bias=True) # 卷积 self.L = nn.Linear(2*self.confifig.feature_t + 3*self.confifig.char_dim, self.confifig.num_t, bias=True) # 全连接层 self.loss = nn.CrossEntropyLoss() # 交叉熵损失函数 def pooling(self, conv): #动态多池化 mask = np.array([[0, 0], [0, 1], [1, 0]]) mask_emb = nn.Embedding(3, 2).cuda() mask_emb.weight.data.copy_(torch.from_numpy(mask)) mask = mask_emb(self.masks) # conv [batch, sen-2, feature] mask [batch, sen-2, 2] pooled, _ = torch.max(torch.unsqueeze(mask*100, dim=2) + torch.unsqueeze(conv, dim=3), dim=1) pooled -= 100 pooled = pooled.view(self.config.batch_t, -1) #torch.Size([170, 400]) return pooled

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.事件元素抽取
从文本中发现事件触发词,并判断元素扮演的角色。事件元素抽取可以分为基于模式匹配和基于机器学习的方法。
事件触发词:表示事件发生的核心词,多为动词或者名词;
事件元素:事件的参与者,如人物、时间、地点等。
基于序列标注的事件元素抽取方法首先将句子中的每个字输入词嵌入模块得到字向量,然后输入到双向长短期记忆神经网络(Bi-LSTM)输出句子中的字在每个标签上的预测分值,最后通过条件随机场(CRF)得到最终的预测标签。模型结构如下:
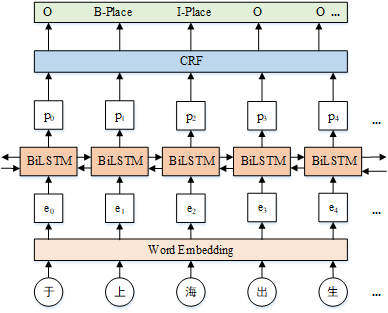
词嵌入向量:将句子中的每个字转化为字向量的形式,作为下一层的输入。
Bi-LSTM模块:将句子中每个字的字嵌入向量作为双向LSTM的输入,然后将正向和反向LSTM输出的隐藏状态进行拼接,得到完整的隐藏状态序列,作为句子的特征向量。
CRF模块:CRF层的作用是增加约束规则来降低预测结果错误的概率。例如,句子中的第一个字的标签总是以标签 B-X 或 O 开始,而不是 I-X,这是因为句子开始的第一个字不可能是扮演某个角色的词的中间部分 。


