
- 1Flutter开发笔记18 - iOS通过FlutterEventChannel发送消息给Flutter_flutter ios fluttereventchannel
- 2【2024护网设备】椒图面试题
- 3src平台总结_cnvd src平台有哪些
- 4SpringBoot异步消息队列RabbitMQ的@EnableRabbit&@RabbitListener注解的使用
- 5自行记录uom轻型民用无人机合格证考试视频
- 6毕业设计:基于机器学习的垃圾短信不良短信息检测系统_信息管理垃圾短信控制系统毕业设计
- 7微信小程序开发中的用户授权和登录功能_小程序userinfo
- 8ubuntu如何限制系统日志大小?
- 9vue使用科大讯飞的语音识别(语音听写)_voice-input-button
- 10基于SpringBoot的健身房管理系统【附源码】
背诵不等于理解,深度解析大模型背后的知识储存与提取_大模型 存储知识 和 推理能力分离
赞
踩
自然语言模型的背诵 (memorization) 并不等于理解。即使模型能完整记住所有数据,也可能无法通过微调 (finetune) 提取这些知识,无法回答简单的问题。
随着模型规模的增大,人们开始探索大模型是如何掌握大量知识的。一种观点认为这归功于 “无损压缩”,即模型通过大量训练,记忆更多内容以提高预测精度。但 “无损压缩” 真的能让大模型理解这些知识吗?朱泽园 (MetaAI) 和李远志 (MBZUAI) 的最新研究《语言模型物理学 Part 3.1:知识的储存与提取》深入探讨了这个问题。

论文地址:https://arxiv.org/pdf/2309.14316.pdf
对于人类,有句话叫 “书读百遍,其意自现”。这句话虽不适用于所有知识,但对于简单知识,只要我们能记住相关书籍,就能轻松回答相关问题。例如,只要我们记住古诗 “静夜思”,就能轻松回答 “诗里把月光比作了什么?”;只要我们记住百度百科关于 “出师表 / 创作背景” 那一段,就能轻松回答 “出师表的创作时间是什么?”。那么,大模型是否也能做到这一点呢?

图 1:GPT-4 的一些知识提取的实例(左图为 ChatGPT,右图为 API)
GPT-4 虽然能理解并复述与问题相关的段落,但为何它无法像人类一样回答简单的问题呢?是因为模型不够大,记忆力不足,还是训练后的微调不够?都不是!文章指出,即使自然语言模型足够大,训练时间足够长,微调也足够充分,但它仍可能无法回答人类认为简单的问题。这其中的深层原因,与知识在预训练数据集 (pretrain data) 中的呈现方式有关。同一知识,需要在预训练数据集中多次出现,且具有足够的 “多样性”,微调后才更容易被提取出来。
为了证实这一点,两位作者创建了一个包含 100k 个人物传记的数据集,每个人物有一个传记条目,包含人名和六个固定属性:出生日期,出生地,大学专业,大学名称,工作地点,工作单位。他们设计了 BioS 和 BioR 两种数据集,BioS 的每个句子选自 50 种固定模板,BioR 则用 LLaMA-30B 进行改写,更逼真,多样性更大。两种数据集的结果一致,下面以 BioS 为例,展示一个样例条目:
Anya Briar Forger was born on October 2, 1996. She spent her early years in Princeton, NJ. She received mentorship and guidance from faculty members at MIT. She completed her education with a focus on Communications. She had a professional role at Meta Platforms. She was employed in Menlo Park, CA.

图 2
一个自然语言模型即使完美地预训练 (pretrain) 了 100k 个人的自传,也无法通过 QA 微调 (finetuning) 准确回答 “Anya 本科念了哪所学校” 这样的问题。如图 2 所示,即使使用 50k 的人作为 QA 微调训练数据,尝试各种微调方法,包括 LoRA,模型在剩下的 50k 人上的正确率也只有 10%。即使使用了 682M 的模型(比人数大 7000 倍),训练了 1350 遍,作者甚至加入了 WikiBook 等标准 NLP 预训练数据,正确率也没有提升。可见 “大力出奇迹” 并没有发生。
因此,大模型并不一定能掌握或提取 “无损压缩” 的知识。那么 GPT-4 是如何掌握知识的呢?为了研究这一问题,两位作者对预训练集进行改动 —— 作者称之为知识增强:
1、多样性 - multiM:为每个人创建 M 个传记条目,使用不同的叙述语言但保留相同的信息(每句话一共有 100 种叙述方法,每条传记的每句话从中选取一种)
2、随机排列 - permute:对传记句子进行随机排列
3、全名 - fullname:将传记里所有代词、姓、名替换全名
作者把原始数据集称为 bioS single,并试验了 15 种知识增强组合。例如,bioS multi5+permute 表示每人有 5 个传记,语序打乱。以下是 bioS multi5+permute 的一个示例:
Anya Briar Forger originated from Princeton, NJ. She dedicated her studies to Communications. She gained work experience in Menlo Park, CA. She developed her career at Meta Platforms. She came into this world on October 2, 1996. She pursued advanced coursework at MIT.
对于人和大模型,记住 bioS single 和 bioS multi5+permute 两个数据集的难度几乎相同(它们信息量相同,并且每句话都是选自 50 个模板)。那么,如果在这个新的知识增强数据集上进行预训练 (pretrain),然后 QA 微调,会有什么新的表现吗?

图 3
图 3 显示,bioS single 预训练模型的 QA 正确率仅为 9.7%,而 bioS multi5+permute 预训练模型的正确率高达 96.6%。这个显著的提升与模型的微调、大小或训练时间无关,而是与知识在预训练 (pretrain) 中的呈现方式有关,即知识如何被大模型 “背诵”。
研究还发现,将传记分为名人 (celebrity) 和少数群体 (minority),只要名人传记有知识增强,即使少数群体没有,模型对少数群体的知识提取正确率也会大幅提升 —— 当然,最好的效果还是需要对所有数据进行知识增强。
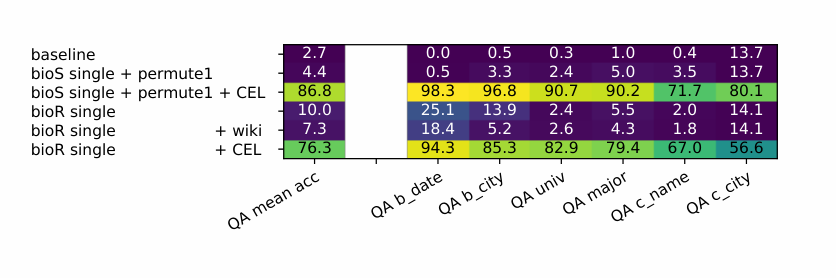
图 4:仅仅通过增加名人 (celebrity) 的训练数据多样性,少数群体的知识提取正确率猛增
那么为何背诵不同数据后,模型的问题回答能力差异大?为何反复背诵名人传记,可以让少数群体的知识提取能力也增强?原因是由于模型采取了不同的记忆方式。
作者通过两种线性探针 (linear probing) 深入探讨了模型的记忆知识的原理。我们来看其中一种叫 P 探针 (P-probing) 的方法。
在 P 探针中,我们输入传记条目到预训练模型,训练一个线性分类器预测六个目标属性(如大学、专业等)。我们想看模型是否能在早于属性的位置提取这些信息。如果分类器在人名后立即显示对 “工作单位” 有高准确率,说明模型直接学习了 “Anya 的雇主是 Meta”。如果只在传记结尾达到高准确率,可能模型用了有缺陷的记忆方法,例如 “某人生日是 1996 年 10 月 2 日,大学是 MIT,因此雇主是 Meta”。
P 探针的试验设计是这样的。找出每个传记中 6 个属性首次出现的位置,然后在这些位置的前一个位置,训练一个线性分类器来预测每个目标属性。这就产生了 36 个分类任务。
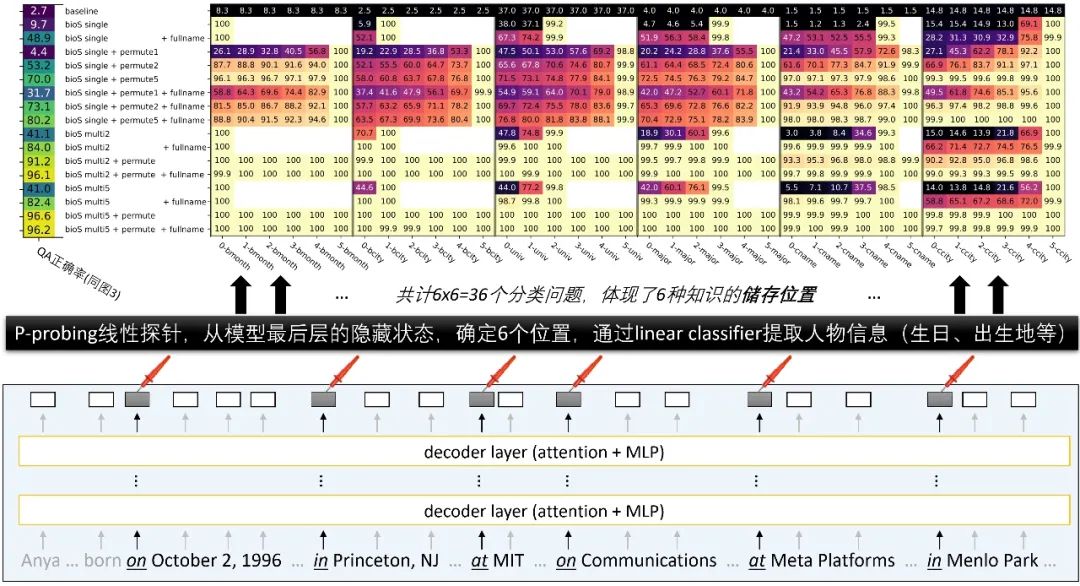
图 5:P 探针试验结果显示,预训练数据集的知识增强使知识被存在更早的位置,部分甚至直接存储在人名上。模型是否能通过微调回答问题,与预训练时是否将信息直接存储在人名上有关(对比图 3 和图 5)。
P 探针试验结果显示,自然语言模型在预训练时可以通过人名记住信息以实现压缩,也可以通过其他信息(如 “在 MIT 就读并且生日是 1996 年 10 月 2 日的人的工作单位是...”)记忆。虽然第二种记忆方式对人来说 “不自然”,但对模型来说两种方法的压缩比无异。如果模型采用第二种方式记住信息,训练结束后将无法通过微调回答问题。而通过知识增强,预训练模型会逐渐倾向于学会使用第一种记忆方式。
有人可能会争论,上述 “知识提取” 失败可能是由于自回归 (autoregressive) 语言模型如 GPT 的单向性。实际上,双向语言模型如 BERT 在知识提取上更差,对 “Meta Platform” 这类多词组知识只能存储,无法提取。有兴趣的读者可以参考论文第 6 章。
总的来说,语言模型是否能回答 “知识提取” 问题,不仅取决于 “无损压缩”,还与 “如何在模型中压缩” 有关。论文强调,预训练过程中对关键但少见的数据进行知识增强是必要的(如使用 ChatGPT 进行多次改写)。如果没有这一步,无论如何努力微调,已预训练完的模型虽然无损压缩了训练数据,但是还是可能再也无法提取那些知识了!
结语
如何理解自然语言模型的工作原理?大多数研究者通过与 GPT-4 等模型对话,推测其能力。然而,《语言模型物理学》系列论文的作者提出了一种更精确的方法,通过精细设计训练数据和可控实验,探究 Transformer 的内部机制,解释其处理 AI 任务的能力。
在《Part 3.1:知识的储存与提取》中,作者精确测试了模型对不同数据的反应,找到了模型学习知识和能力与训练数据的准确关系。
他们还发布了《Part 3.2:知识的操作》,进一步研究了模型如何在特定情况下操作知识。例如,如果大模型记住了《静夜思》,能否通过微调使其推理出《静夜思》的最后一句是 “低头思故乡”?我们很快讲为大家带来后续报道。

