
热门标签
热门文章
- 1VisualStudioCode上传到Gitee教程_visual studio 推送到gittee
- 2紫光同创FPGA实现PCIE测速试验,提供PDS工程和Linux QT上位机源码和技术支持_qt pcie高速采集
- 3Python中字符串的常用操作_python常见操作字符串方法
- 4idea上拉取gitee上的项目提示master has no tracked branch解决方案_master 没有跟踪的分支
- 5Java并发系列 | 一文进入多线程的奥秘_java restcontroller 多线程
- 6一文彻底搞懂MySQL基础:B树和B+树的区别(简洁版)_mysql b树和b+树
- 7第二个机器学习算法:基于SVM的猫咪图片识别器_svm进度条展示
- 8Spring框架的优点,和IoC、AOP_spring 的 ioc 和 aop 是什么,有哪些优点?
- 9主机安全是什么以及主机安全的功能和价值分析_企业主机安全和个人主机安全的区别
- 10CUDA、CUDNN 、tensorflow、tensorflow-addons、scipy、numpy、keras、python版本对应_numpy和python版本对应关系
当前位置: article > 正文
can‘t find model ‘zh_core_web_sm‘. It doesn‘t seem to be a python package or a valid path to a data_can't find model 'zh_core_web_sm'. it doesn't seem
作者:Cpp五条 | 2024-04-02 05:26:02
赞
踩
can't find model 'zh_core_web_sm'. it doesn't seem to be a python package or
成功解决[E050] Can’t find model ‘en_core_web_sm’. It doesn’t seem to be a Python package or a valid path to a data directory.
直接上解决方案
步骤一:
豆瓣源安装spacy包
pip install spacy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
- 1
步骤二:下载en_core_web_sm或者zh_core_web_sm包,缺哪个下载哪个
zh_core_web_sm
en_core_web_sm
spacy中文模型官网
spacy官网
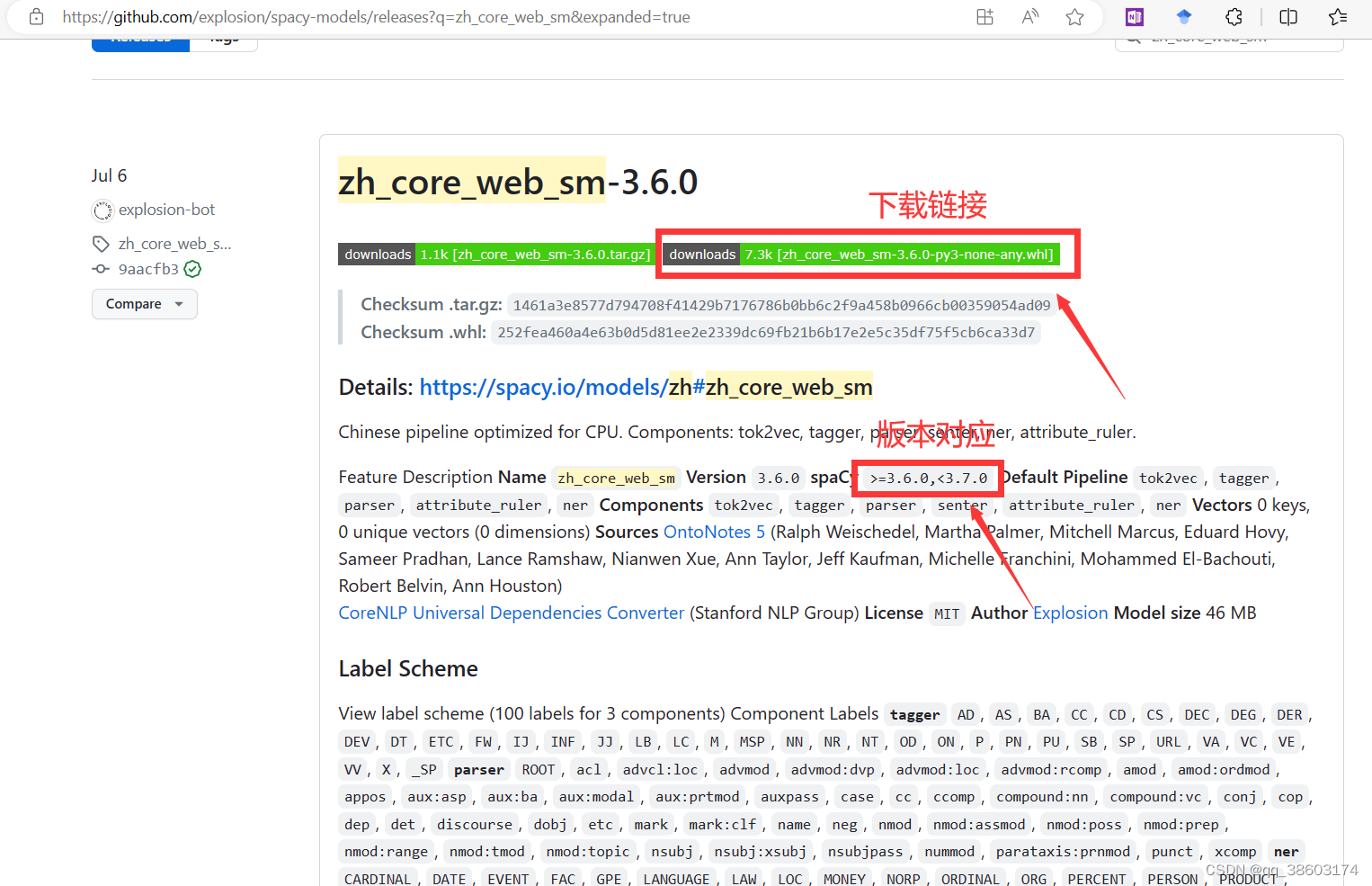
注意根据对应版本下载
步骤三:终端pip安装whl
pip install + whl文件地址
pip install C:\Users\Zz\zh_core_web_sm-3.6.0-py3-none-any.whl
- 1
接下来就可以使用啦,给出两个小栗子
import spacy # 加载英文模型 nlp = spacy.load("en_core_web_sm") # 示例文本 text = "Apple is planning to build a new factory in China." # 定义句式 pattern = [{"POS": "PROPN"}, {"LEMMA": "be"}, {"POS": "VERB"}] # 处理文本 doc = nlp(text) # 匹配句式 matcher = spacy.matcher.Matcher(nlp.vocab) matcher.add("CustomPattern", None, pattern) matches = matcher(doc) # 提取匹配的数据并进行标注 for match_id, start, end in matches: span = doc[start:end] print("Matched:", span.text) span.merge() # 打印标注后的文本 print("Tagged Text:", doc.text)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
import spacy # 加载中文模型 nlp = spacy.load("zh_core_web_sm") text = "写入历史了:苹果是美国第一家市值超过一万亿美元的上市公司。" # 处理文本 doc = nlp(text) for token in doc: # 获取词符文本、词性标注及依存关系标签 token_text = token.text token_pos = token.pos_ token_dep = token.dep_ # 规范化打印的格式 print(f"{token_text:<12}{token_pos:<10}{token_dep:<10}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/350982
推荐阅读
相关标签

