
热门标签
当前位置: article > 正文
隐马尔可夫模型(HMM)实现命名实体识别(NER)_hmm方法 实体识别
作者:Cpp五条 | 2024-04-02 14:24:02
赞
踩
hmm方法 实体识别
隐马尔可夫模型(HMM)实现命名实体识别(NER)
一、命名实体识别(Named Entity Recognition,NER)
识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词等等
在使用的NER数据集中包含七个标签:
- “B-ORG” : 组织或公司(organization)
- “I-ORG” : 组织或公司
- “B-PER” : 人名(Person)
- “I-PER” : 人名
- “O” : 其他非实体(other)
- “B-LOC” : 地名(location)
- “I-LOC” : 地名
文本中以每一个字为单位,每一个字对应上面的任一种标签。
标签前面有分为B和I,"B"表示begin,实体开头的那个字,在实体中间或者结尾部分,,用”I“来标注。
例如:自(B-PER)贸(I-LOC)区(I-LOC),这是一个错误的标注,原因是我们以(B-PER)开头,那么后面的应该是I-PER类型,而不是其他类型。
由此,我们可以发现,仅仅采用语言模型(Bert 或者 LSTM)进行标注的话会产生很多的错误标注,我们需要在语言模型后加上概率图模型(条件随机场)由来约束模型的 输出,从而达到防止输出不合法的标注。
二、一个栗子
采用训练好的隐马尔可夫模型进行实体标注
from HMM_model import *
model = HMM_NER(char2idx_path="./dicts/char2idx.json",
tag2idx_path="./dicts/tag2idx.json")
model.fit("./corpus/train_data.txt")
model.predict("我在西区300318教室上清华大学的自然语言处理课程")
- 1
- 2
- 3
- 4
- 5
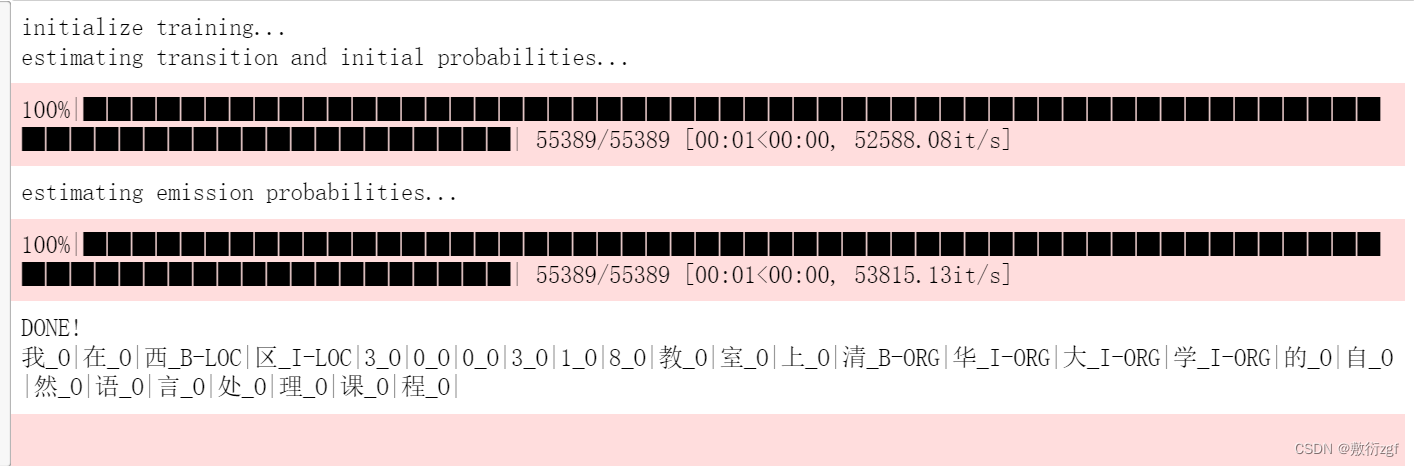
识别人名
text = "张吉惟、林国瑞、林玟书、林雅南、江奕云、刘柏宏、阮建安、林子帆"
model.predict(text)
- 1
- 2

三、什么是隐马尔可夫模型
隐马尔可夫模型又称隐马模型又称HMM,是概率图模型之一,我们常见的贝叶斯模型也是概率图模型之一。
HMM属于生成模型,上面描述的BIO实体标签就是一个不可观测的隐藏状态,而HMM模型描述的就是由这些隐藏状态序列(实体标记)生成可观测结果(可读文本)的过程。
例如
隐藏状态序列: B-ORG | I-ORG | I-ORG | I-ORG |
观测结果序列: 清 华 大 学
假设可观测状态序列是由所有汉字组成的集合,用 本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

