
- 1网络安全简答题
- 2社交媒体数据治理:Facebook的隐私与透明度
- 3脉冲神经网络-基于IAF神经元的手写数字识别_脉冲神经网络 可视化
- 4用 Python 轻松实现机器学习_python做machine learning
- 5怎样用Excel搜索表格内的内容?_excel表格怎么查找内容
- 6机器学习-周志华-课后习题答案-决策树_试选择 4 个 uci 数据集,对上述 3 种算法所产生的未剪枝、预剪枝、后剪枝决策树进
- 7kibana 查询ES 的一些语法_kibana查询es基本语法
- 8解密目前主流的机器人导航方法
- 9LSTM神经网络详解
- 10复试专业前沿问题问答合集7-2——神经网络与强化学习_复试问及卷积神经网络
论文解读 | KDD2023:DCdetector: 用于时间序列异常检测的对比表征学习框架
赞
踩
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
内容简介
时间序列异常检测对各种应用都至关重要。其目的是从时间序列的正常样本分布中识别出异常样本。这项任务面临的最基本挑战是学习能有效区分异常的表征。基于重构的方法仍占主导地位,但异常情况下的表征学习可能会因较大的异常损失而影响性能。另一方面,对比学习的目的是找到一种能将任何实例与其他实例明确区分开来的表征,它能为时间序列异常检测带来更自然、更有前景的表征。在本文中,我们提出了一种多尺度双注意对比表示学习模型--DCdetector。DCdetector 利用新颖的双注意非对称设计来创建包络环境,并利用纯对比损失来指导学习过程,从而学习出具有卓越辨别能力的包络不变表示。广泛的实验表明,DCdetector 在多个时间序列异常检测基准数据集上取得了最先进的结果。
论文链接:https://arxiv.org/abs/2306.10347
代码链接:https://github.com/DAMO-DI-ML/KDD2023-DCDetector
背景介绍
时间序列数据的来源有很多应用场景,比如服务器、金融场景、外星探测器、AIOps以及物联网等。在时间序列数据中有很多异常或正常的特性,而时间序列异常检测即从原始的时间序列信号数据中挖掘有用的信息表征异常的特性,从而保护系统的安全,减少财产损失。它可以归结为一个数学问题:从单维度或多维度的时间序列信息中探究其中的点处于正常或异常的状态。
关于时间序列异常检测,存在诸多的问题。首先,异常点的种类和特征很多,典型的异常通常很复杂,比如风力涡轮机在不同的天气情况下以不同的模式工作;其次,异常情况通常比较罕见,因此需要花费大量时间和人力物力来获取标签;第三,异常检测模型应考虑时间序列数据的时间、多维和非稳态特征,充分考虑维度之间的依赖关系。
基于以上的难点,现有研究中常用的方法是基于无监督的异常检测。它的过程是对于无标签的时间序列数据,挖掘其中的特征,对每一个时间戳进行表征,最后再对表征进行异常检测,评估每一个时间戳的异常成分。
相关工作
基于重构误差的异常检测,构建一个表征的神经网络执行重构任务,目标是让模型能够重构好正常样本。那么在测试时,对于正常样本仍然能够正常重构,而异常样本由于分布的差异,导致重构效果较差,从而可以通过比较得到异常得分,判断一个样本是否为异常。
Anomaly Transformer,它有两个分支。左边的分支使用Transformer的架构挖掘时间序列中的全局信息,右边的分支使用Gaussian Kernel挖掘局部特性。它使用Minimize Discrepancy评判局部信息与全局信息的差异,以此判断对应的时间点是否正常。
DCdetector中完全摒弃了重构误差,输入的原始数据采用两个不同的表征模块,对同一个时间序列进行表征,损失函数用来评价对于同一个输入之间不同表征相似程度的差值。若表征一致,则说明为正常值;若相似程度较小,则说明为异常值。
DCdetector框架
下图为DCdetector的整体框架,共分为四部分,分别是前处理、表征学习框架、表征差异计算、异常评估。
前处理
前处理包括两部分:正则化与独立通道。由于不同维度之间的信息是不同的,所以我们对于每一个维度的信息独立分析。我们针对整个时间序列,对于每一个小的窗口提取特征,再将其切分成不同的patch,patch之间与patch内部分别做不同的处理。
对比学习架构
对比学习架构包括两部分:两种不同的表征方法、对于不同表征方法进行上采样使其能够作出相似度的评价。
表征差异计算与异常评估
如下图中粉色图框,表征差异计算即对比两个表征之间的相似程度。对于异常评估,若计算出的分数大于某一个预设的数值,则判断为异常;若小于预设值,则判断为正常值。
实验评估
我们使用了8个数据集进行评估,包括7个多维的时间序列信息和一个单维的时间序列信息。数据来源非常多样,包括MSL、SMAP、PSM、SWaT、SMD、NIPS-TS-SWAN、NIPSTS-GECCO、UCR。
多变量数据集的评估结果如下图所示,DCdetector在大多数基准数据集中广泛使用的评价指标下实现了SOTA结果。
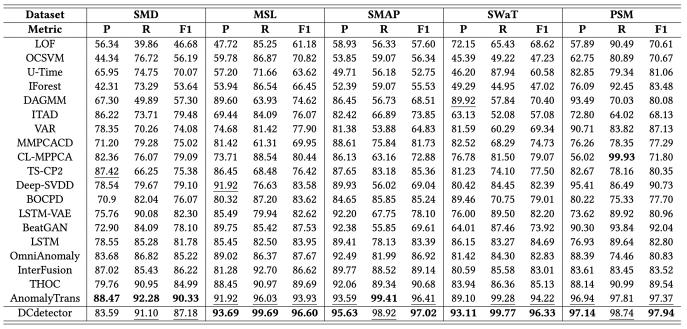
DCdetector和Anomaly Transformer之间的多指标比较如下图所示,DCdetector在大多数指标上仍然实现了更好的性能。

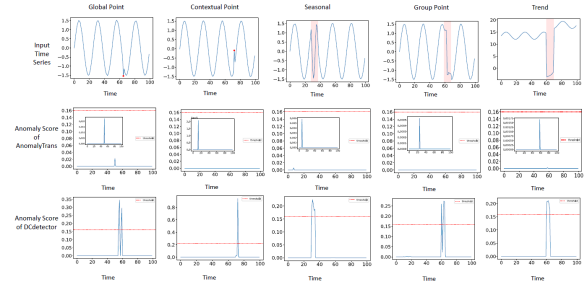
我们通过下图中的不同异常来展示DCdetector的工作原理。我们使用合成数据生成方法来生成具有不同类型异常的单变量时间序列,包括逐点异常(全局点和上下文点异常)和模式异常(季节性、群体和趋势异常)。由下图可以看出,DCdetector能够从异常分数相对较高的正常点更好地鲁棒地检测各种异常。
最后,我们也进行了充分的消融实验和参数敏感性分析,结果如下图。图(a)中的结果表明DCdetector在各种窗口大小(从30到210)下都具有鲁棒性。图(b)展示了在不同多尺度尺寸条件下的性能。多尺度设计有助于DC检测器的最终性能,不同的patch大小组合会导致不同的性能。图(c)显示了不同编码器层数下的性能,因为许多深度神经网络的性能受到层数的影响。图(d)和图(e)显示了不同头部数量或注意力大小的模型性能。

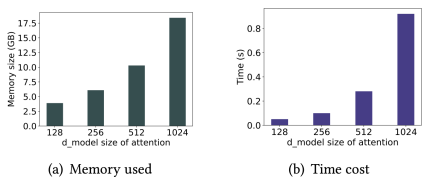
不同d(model)大小的内存和时间使用情况如图所示,可以看出DCdetector在d(model)=256下可以很好地工作,具有高效的运行时间和较小的内存消耗。
总结
DCdetector使用双通道对于同一个异常点进行不同的表征,然后计算不同表征之间的相似程度,从而对时间点进行异常的打分和判断。在本文提出的框架中,我们构建了对比学习框架评判正常与异常时间点的相似程度。此外,我们设计了多尺度和通道独立操作提高了检测性能。在优化方面,我们摒弃了重构误差,尽可能减少异常判断对整个方法的影响,设计了有效的鲁棒损失函数。最后,我们的方法适用于更多的应用场景,在工业设备状态监测、金融欺诈检测、故障诊断、汽车日常监控维护等领域都有较好的表现。
往期精彩文章推荐

关注我们 记得星标
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1400多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看!


