
- 1Hummingbird Exceed远程连接Solaris的网络及字体设置_exceed配置字体pcf
- 2Matlab DDPG
- 3容器中的⼤模型(一)| 三行命令,大模型让Excel直接回答问题
- 4pytorch学习(4)——图片变换Transforms使用_transform函数输入一个图像产生几个图像
- 5HarmonyOS实战 — HUAWEI DevEco Studio 鸿蒙应用开发自学第一课!冲,冲,冲
- 6Go IDE使用
- 7播放量查询_查询抖音视频播放量接口
- 8【C语言】if语句选择题
- 9spark通过connector的方式读写starrocks_starrocks spark connector
- 10空间谱估计matlab实现,相干信号空间谱估计测向Matlab仿真研究
深度学习---计算机视觉、自然语言处理、机器学习(笔记)_视觉处理与机器学习
赞
踩
一、计算机视觉
1、基本概念
计算机视觉的目的是让机器通过分析图像或视频来理解场景中的内容。这涉及到从像素数据中提取信息,识别物体,以及理解场景的三维结构等一系列复杂的任务。
2、关键技术
(1)图像分类:目的是识别图像中的主要物体或场景。
(2)物体检测:不仅要识别图像中的物体,还要确定其位置和大小。
(3)语义分割:将图像中的每个像素分配给一个物体类别,用于理解场景的详细布局。
(4)实例分割:与语义分割类似,但是区分同一类别的不同实例。
(5)姿态估计:识别物体(如人体)的姿态和关节位置。
3、方法
1、传统图像处理技术:这些技术包括边缘检测、特征匹配、光流计算等,通常依赖于手工设计的特征。
(1)边缘检测:
①目标是识别数字图像中亮度变化明显的点,通常用于提取物体的轮廓。
②常见的算法包括Roberts算子、Canny算子、Sobel算子和Laplace算子等。
③Roberts算子适用于处理低噪声且边缘接近于正负45度的图像。
④Canny算子是一种多阶段边缘检测算法,它使用两个阈值来检测强边缘和弱边缘,并且能连接边缘以形成连续的轮廓。
(2)特征匹配:
①特征匹配通常涉及到在两幅图像之间找到对应的特征点,这在图像识别和三维重建中非常重要。
②ORB-SLAM中使用的特征匹配方法包括词袋匹配和光流法匹配。
③词袋模型通过计算图像的词袋向量之间的距离来进行特征匹配。
(3)光流计算:
①光流是指在视频序列中,由于相机或物体的运动,图像中的像素点在连续帧之间的移动模式。
②光流计算的基本假设是对象的像素强度在连续帧之间不会改变,且相邻像素具有相似的运动。
③光流追踪可以用于目标跟踪、动作识别和三维场景重建等领域
2、深度学习方法:随着深度学习的发展,卷积神经网络(CNN)已成为计算机视觉的主流方法。CNN能够自动学习图像特征,极大地提高了图像识别和处理的性能。
(1)卷积神经网络(CNN)
卷积神经网络(CNN)是一种专门用来处理具有类似网格结构的数据的深度学习算法,在图像和视频识别等领域表现突出。
①基本概念:CNN通过模拟生物的视觉认知机制来进行图像分析,它能够有效地提取图像的局部特征,并通过多层网络结构组合这些特征以进行复杂的图像识别任务。
②架构与层级结构:CNN通常由多个卷积层、池化层以及全连接层组成。每一层都负责提取不同层次的特征,从简单的边缘到复杂的对象部分。
③卷积层:这是CNN的核心部分,利用卷积运算来提取图像的局部特征。卷积运算可以看作是一种特殊的线性变换,它通过滑动窗口(过滤器)的方式逐步扫描整张图片,从而提取特征。
④池化层:通常位于卷积层之后,用于降低特征图的空间维度,减少计算量,并增强模型对小的平移、旋转和缩放的鲁棒性。
⑤激活层:引入非线性激活函数,如ReLU或Sigmoid,使得网络能够捕捉和表示更复杂的模式。
⑥全连接层:在网络的末端,将特征图展开成一维向量后,通过全连接层进行高级推理和分类。
⑦特点:CNN具有局部连接和权值共享的特性,这使得网络能够有效地减少参数数量,同时增强模型泛化能力。
⑧训练方法:CNN通常使用反向传播算法进行训练,这是一种基于梯度下降的优化方法,用于调整网络中的权重参数以最小化损失函数。
⑨应用:CNN在图像分类、目标检测、语义分割等计算机视觉任务中取得了显著的成果,并且在语音识别、自然语言处理等领域也有所应用。
(2)卷积计算
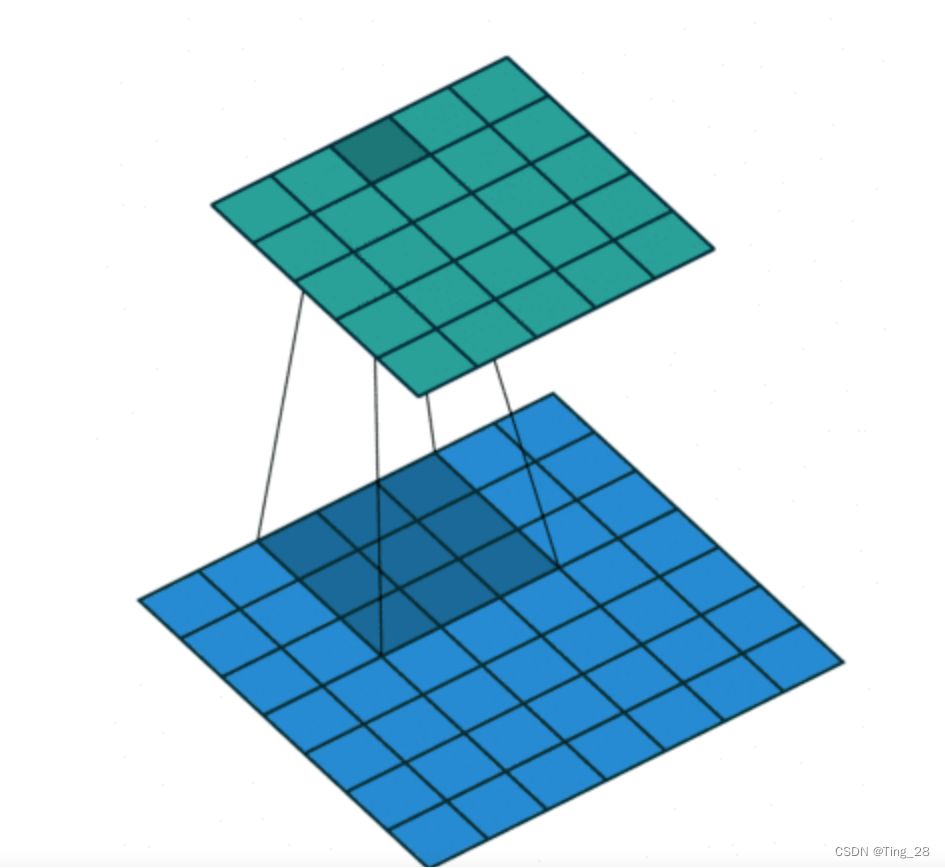
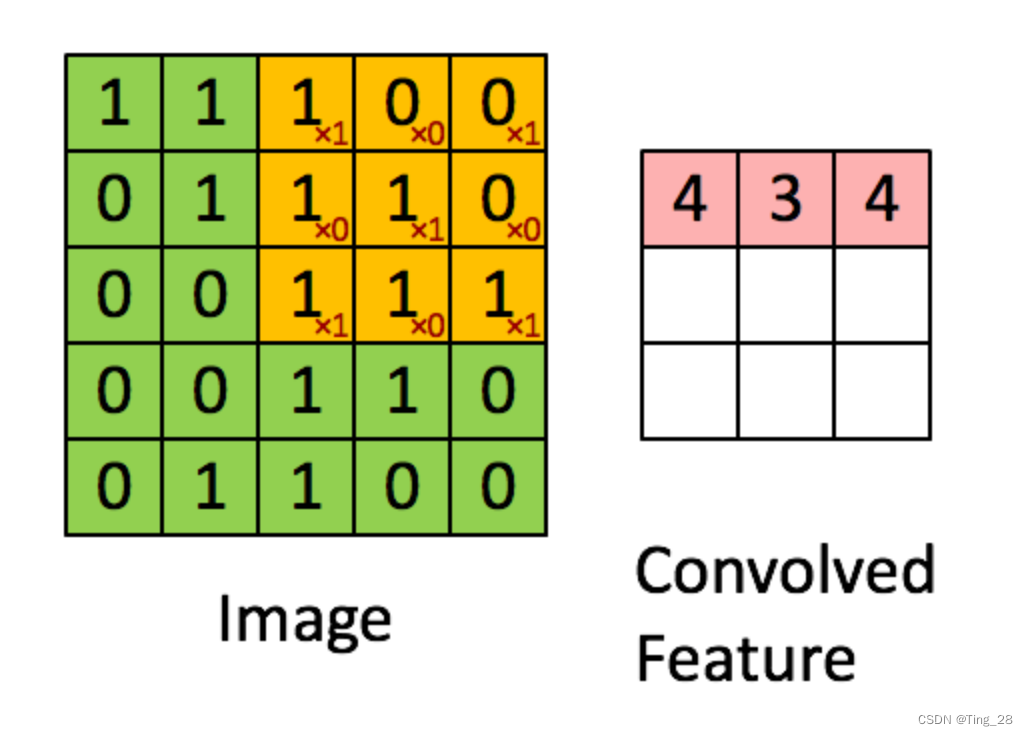
计算公式
输入图片的尺寸:一般用 n * n 表示输入的image大小。
卷积核的大小:一般用 f * f 表示卷积核的大小。
填充(Padding):一般用 p 来表示填充大小。
步长(Stride):一般用 s 来表示步长大小。
输出图片的尺寸:一般用 o 来表示。
当不为整数时,向下取整: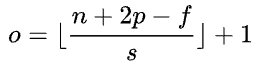
4、应用实例
计算机视觉技术已广泛应用于多个领域,如医疗图像分析、自动驾驶汽车、安防监控、零售业的商品识别等。
5、趋势
随着技术的不断进步,计算机视觉将继续扩展到新的应用领域,并与其他技术领域如自然语言处理、机器人技术等相结合,创造出更多智能化的解决方案。
二、自然语言处理
自然语言处理(Natural Language Processing,简称NLP)是计算机科学、人工智能和语言学交叉领域的一个分支,旨在使计算机能够理解、解释和生成人类语言。
1、基本概念
语言模型:用于表示和预测自然语言序列的概率分布。
词法分析:将文本分解成单词或标记(Tokenization),识别单词的词性(POS Tagging)。
句法分析:理解句子结构,如解析树(Parsing Trees)。
语义分析:确定语句的意义,涉及实体识别(NER)、关系抽取等。
情感分析:判断文本的情感倾向,如正面、负面或中性。
2、关键技术
机器学习:使用算法如决策树、支持向量机(SVM)等进行文本分类和模式识别。
深度学习:利用神经网络,特别是循环神经网络(RNN)和变压器(Transformer)架构,进行语言建模和翻译。
词嵌入:将单词转换为稠密向量表示,如Word2Vec、GloVe和BERT。
序列到序列模型:用于机器翻译、摘要生成等任务,典型代表为Seq2Seq模型。
3、应用
机器翻译:自动将一种语言翻译成另一种语言。
语音识别:将口语转换为书面文本。
文本摘要:创建文本的简短版本而保留主要信息。
聊天机器人:与人类用户进行交流和互动。
问答系统:对特定问题提供精确答案。
4、工具和框架
NLTK:Python中常用的自然语言处理工具包。
spaCy:另一个Python库,强调性能和易用性。
TensorFlow和PyTorch:通用的深度学习平台,包含NLP专用模块。
Hugging Face Transformers:提供预训练的Transformer模型,如BERT。
三、机器学习
机器学习是人工智能的一个分支,它使得计算机系统能够从数据中学习并改进其性能。
1、监督学习
利用带有标签的数据集来训练模型,使其能够识别或预测新的数据点的输出。
1、概念特点
(1)监督学习涉及到从标记的训练数据中学习一个函数,这个函数能够映射输入到输出。
(2)它包括两个主要过程:模型的训练和模型的预测。在训练阶段,算法会学习如何从输入数据映射到正确的输出标签。在预测阶段,模型会使用学到的映射来预测新数据的标签或输出。
(3)监督学习的特点是它依赖于标记准确的训练数据,这些数据必须由专家进行标注,以确保模型学习到正确的模式。
2、分类与算法
(1)监督学习可以分为分类和回归两大类问题。分类问题涉及到预测离散的标签,如垃圾邮件检测(是或不是)。回归问题则涉及到预测连续的值,如房价预测。
(2)常用的监督学习算法包括决策树、支持向量机(SVM)、随机森林、神经网络等。这些算法各有优势,适用于不同类型的问题和数据集。
2、无监督学习
无监督学习是一种数据驱动的机器学习范式,旨在从未标记的数据中发现隐藏的结构或模式。
1、特点
(1)没有明确的目的:与监督学习不同,无监督学习没有明确的输出标签,其目标是探索数据本身的结构。
(2)不需要打标签:无监督学习的数据集不包含任何标签,算法试图自行理解数据的组成和关系。
(3)无法量化效果:由于缺乏标签,无监督学习的效果通常难以像监督学习那样直接量化。
2、常用算法
(1)聚类分析:如K-means、层次聚类等,目的是将数据分组,每组内部的对象相似度较高,而不同组之间的相似度较低。
(2)降维技术:如主成分分析(PCA),用于减少数据集的维度,同时尽量保留原始数据的重要信息。
(3)关联规则学习:用于发现大数据集中变量之间的关系。
(4)异常检测:识别与大多数数据显著不同的特殊项、事件或观测值的方法。
3、半监督学习
半监督学习是介于监督学习和无监督学习之间的一种机器学习方法,它通过同时使用少量的标记数据和大量的未标记数据来训练模型。
1、基本假设:
半监督学习通常基于几个关键假设,包括平滑假设、聚类假设和低密度分离假设。这些假设认为数据点如果距离相近,则很可能属于同一类别。
2、常用方法:
半监督学习的方法可以分为三类:直推学习、基于图的方法和生成模型方法。直推学习专注于未标记数据的标签预测,而基于图的方法则是利用数据之间的关系图来帮助标签信息的传播。
3、算法与技巧:
半监督学习的一些常用算法包括自编码器、生成对抗网络(GANs)等。这些算法可以在有少量标签数据的情况下,通过学习未标记数据的结构和分布来提升模型的学习效果。
4、强化学习
强化学习是机器学习的一个分支,它允许机器或软件自动确定在特定环境中的行为方式,以最大化某种累计奖励。
1、基本原理
(1)强化学习涉及一个智能体(agent)与环境(environment)的交互。智能体根据当前的状态做出动作,并从环境中获得反馈,包括下一个状态和奖励信号。
(2)目标是学习一个策略(policy),即一个从状态到动作的映射,使得智能体在未来获得的累积奖励最大化
2、要素
(1)状态(State):描述智能体和环境在某一时间点的情况。
(2)动作(Action):智能体可以执行的操作。
(3)奖励(Reward):智能体执行动作后,环境提供的反馈信号。
(4)策略(Policy):从状态到动作的映射规则。
(5)价值函数(Value Function):预期在遵循特定策略的情况下,能够从状态中获得的未来奖励的总量。
3、算法与分类
(1)基于值函数的方法:如Q学习(Q-Learning)、状态价值函数等。这些方法侧重于学习每个状态的价值,从而推导出最佳策略。
(2)基于策略梯度的方法:直接参数化策略函数,并通过梯度上升来优化策略,如REINFORCE算法。
(3)Actor-Critic方法:结合了值函数和策略梯度的优点,使用两个模型:一个用于评估价值函数(Critic),另一个用于生成策略(Actor)
5、核心概念
特征提取:选择和转换数据的有关部分,使其适合用于机器学习模型。
损失函数:衡量模型预测与真实值之间的差异。
优化算法:调整模型参数以最小化损失函数,如梯度下降。
过拟合与欠拟合:模型在训练数据上表现过于完美(过拟合)或不够好(欠拟合)。
正则化:防止过拟合的技术,如L1和L2正则化。
6、评估指标
准确率:正确预测的比例。
精确率与召回率:分别衡量模型对正类的识别能力和覆盖率。
F1分数:精确率和召回率的调和平均,用于二分类任务。
均方误差(MSE):预测值与实际值差的平方的平均值,用于回归任务。
7、工具和库
Scikit-learn:提供简单有效的数据挖掘和数据分析工具。
TensorFlow和PyTorch:用于构建和训练深度学习模型的框架。
Pandas和Numpy:数据处理和数值计算的Python库。
Matplotlib和Seaborn:数据可视化工具。

